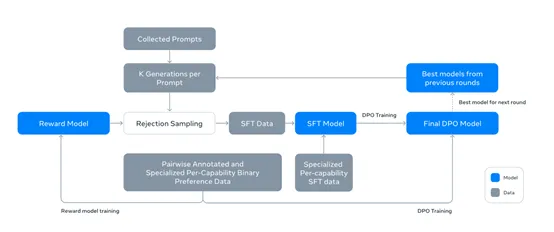
在预训练过程中,Llama 3.1 405B使用了超过1.6万块H100。为了充分发挥405B模型的潜力,训练过程中还采用了一些特殊的技术和策略,例如,在预训练阶段,采用了初始预训练和长上下文预训练相结合的方式。 初始预训练使用了大量的数据来学习语言的基本模式和规律,而长上下文预训练则专注于处理更长的文本序列,以提高模型对上下文的理解能力。 在语言模型后训练阶段,405B通过监督微调和直接偏好优化等,进一步提升了模型的性能和适应性。监督微调使用大量的人工标注数据来微调模型,使其能够更好地遵循人类的指令和偏好;直接偏好优化则通过学习人类的偏好来优化模型的输出,使其更加符合人类的期望。 原文链接