48. 更多的端到端学习的例子
假设你想建立一个语音识别系统。那么你可以构建一个包含三个组件的系统:
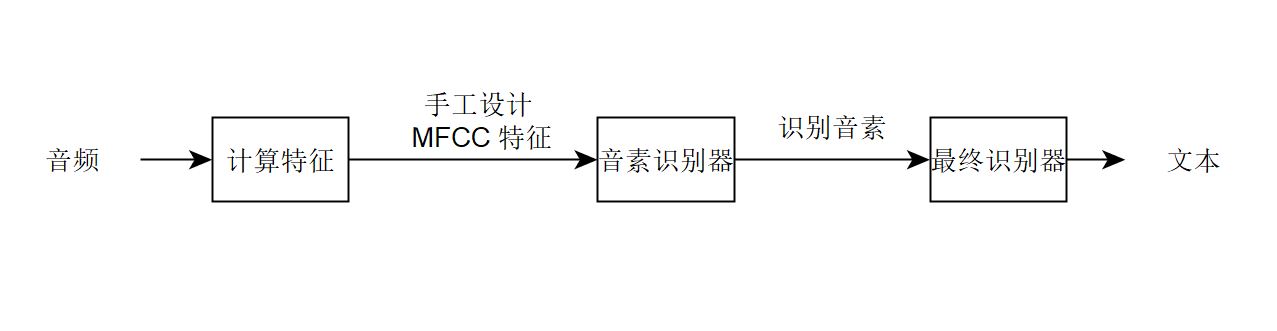
这些组件的职能如下:
- 计算特征:提取手工设计的特征,例如 MFCC 特征(梅尔频率倒谱系数),它尝试捕捉话语的内容,同时忽略不太相关的属性,例如说话者的音调;
- 音素识别器:一些语言学家认为声音的基本单位是“音素”。例如,“keep”中最初的“k”音与“cake”中的“c”音相同。这个识别器试图识别音频片段中的音素;
- 最终识别器:取出识别的音素序列,并尝试将它们串成一个输出抄本。
相反,端到端的系统可能会输入一个音频剪辑,并尝试直接输出文本:

到目前为止,我们只描述了完全线性的机器学习“管道”——输出顺序从一个阶段传递到下一个阶段。然而,管道可能更复杂,例如,这里有一个自动驾驶汽车的简单架构:
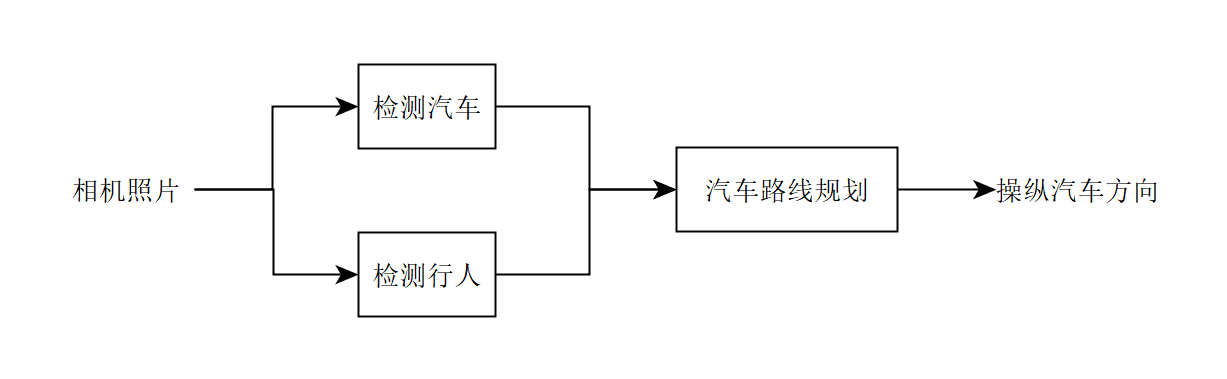
它有三个组成部分:一个负责使用相机图像检测其他车辆; 一个负责检测行人; 最终的组件则为我们的汽车出规划一条避开汽车和行人的道路来。
然而,并不是说管道中的每个组件都需要训练和学习。例如,有关“机器人运动规划”的文献中就有大量关于汽车最终路径规划步骤的算法。这里边的许多算法都不涉及学习。
相反,端到端的方法可能尝试接受传感器输入并直接输出转向方向。
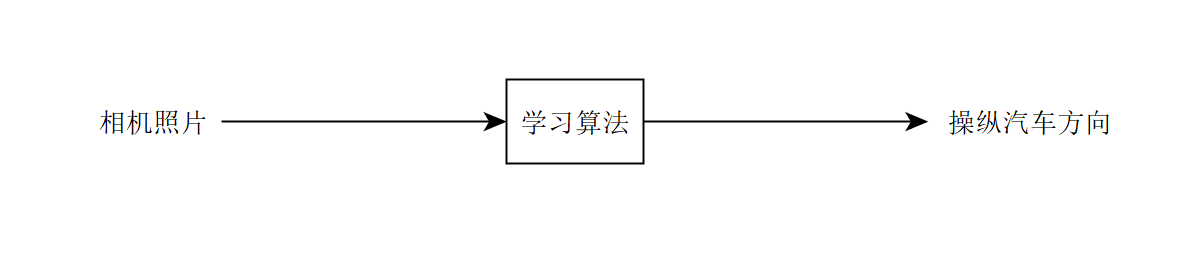
尽管端到端学习已经取得了许多成功,但它并不总是最好的方法。例如,我们认为端到端的语音识别效果很好,但对自主驾驶的端到端学习则持怀疑态度。接下来的几章我会解释原因。

若有收获,就点个赞吧
0 人点赞
