4. 规模化驱动下的机器学习发展
很多深度学习相关的想法已经存在了数十年,为什么它们现在突然又火了起来?
近期的两个最大的驱动因素是:
- 海量可供使用的数据。人们在数字设备上所花费的时间大大提高,借此产生的海量数据,能够用于训练机器学习算法。
- 大规模的计算。从前几年开始,我们才敢设计足够大的网络来充分利用我们拥有的海量数据。
具体来说,如果使用那些传统的学习算法,比如逻辑回归,即使我们拥有再多的数据,算法的“学习曲线”会变得平坦(高原效应(Flattens Out))。这意味着,即使提供再多的数据,算法也会停止改进。
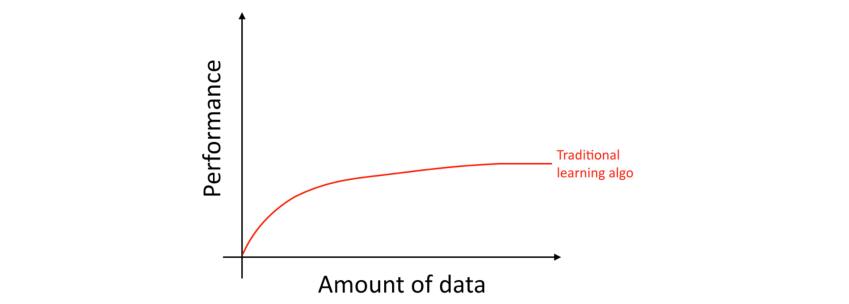
这看起来传统的算法并不知道怎么利用我们提供的海量数据。
对于同样的一个“监督学习”任务,如果你训练一个小型的神经网络,那么你可能会获得稍微好一点的性能表现。
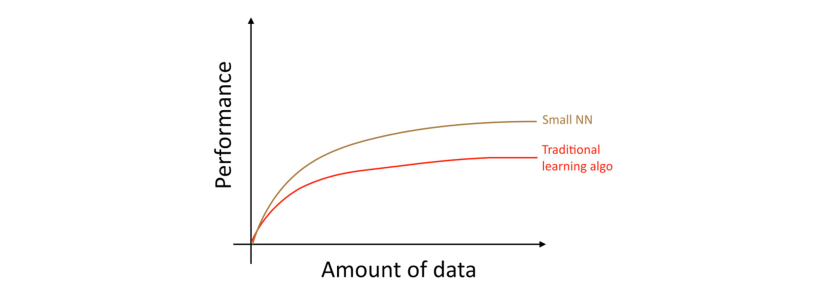
在这里,所谓的小型神经网络指的是该网络只有少数的隐藏单元/层/参数。最后,逐渐增大你网络的规模,网络的性能表现也会同步提高 [1]。
[1].该图显示了神经网络在小数据集上也能做的很好,这个效果与神经网络在大型数据集上表现出的良好效果并不一致。在小型数据集中,更多的取决于如何对特征进行手工设计,传统算法可能表现的更好也可能表现更差。比如,你有20个训练样本,那么是否使用逻辑回归或者神经网络可能无关紧要,对特征的手工设计比选择何种学习算法会对性能表现产生更大的影响。但是如果你有100万的训练样本,使用神经网络将会是一个明智的选择。
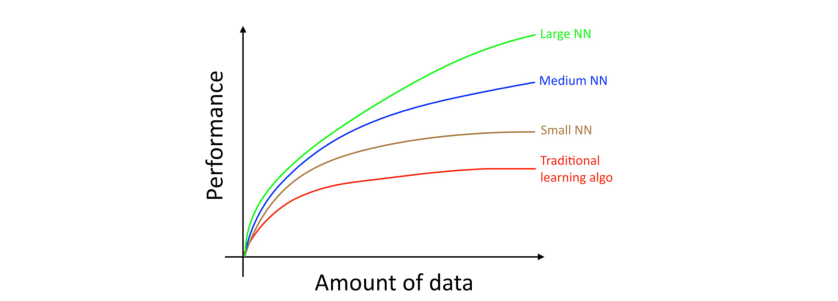
很多其他的细节,比如神经网络架构,也是非常重要的,这里边也有很多可以创新的地方。但,在今天来看,提高算法性能更有效的方法依然是:(i)规模更大的网络;(ii)更多的数据。
如何实现(i)和(ii)的过程非常复杂,本书将会详细讨论这些细节。我们将从对传统的学习算法和神经网络都有效的一般策略入手,为构建现代深度学习系统提出更加现代化的策略。

若有收获,就点个赞吧
0 人点赞
