29. 绘制训练误差曲线
随着训练集大小的增加,你的开发集(和测试集)的误差应该会减少;但是随着训练集大小的增加,你的训练集的误差应该是会增加的。
让我们以例子来说明这种情况,假设你的训练集只有两个样本:一个猫图和一个非猫图。然后学习算法很容易的就学习到了训练集中的这两个样本,并达到了0%的训练集误差。即使其中一个或者两个训练样本的标签都被标记错误了,对于学习算法来说,仍然能够轻松的记住这两个标签。
现在假设你的训练集有100个样本,也许有一些例子时被错误标记的,或者是模棱两可——图片模糊到即使是人类也无法分辨图片中有无猫。也许学习算法仍然能够“记忆”大部分或全部训练集样本,但也很难取得100%的准确率了。通过将训练集样本量从2个增加到100个,你会发现训练集准确率会稍微下降。
最后,假设你的训练集有10000个样本,在这种情况下,算法更加难以去拟合这10000个样本了,特别是还存在模糊图片或者时标记错误图片的情况下。因此你的算法表现在训练集上会变得更差。
让我们将训练误差曲线绘制到之前的那张图上:
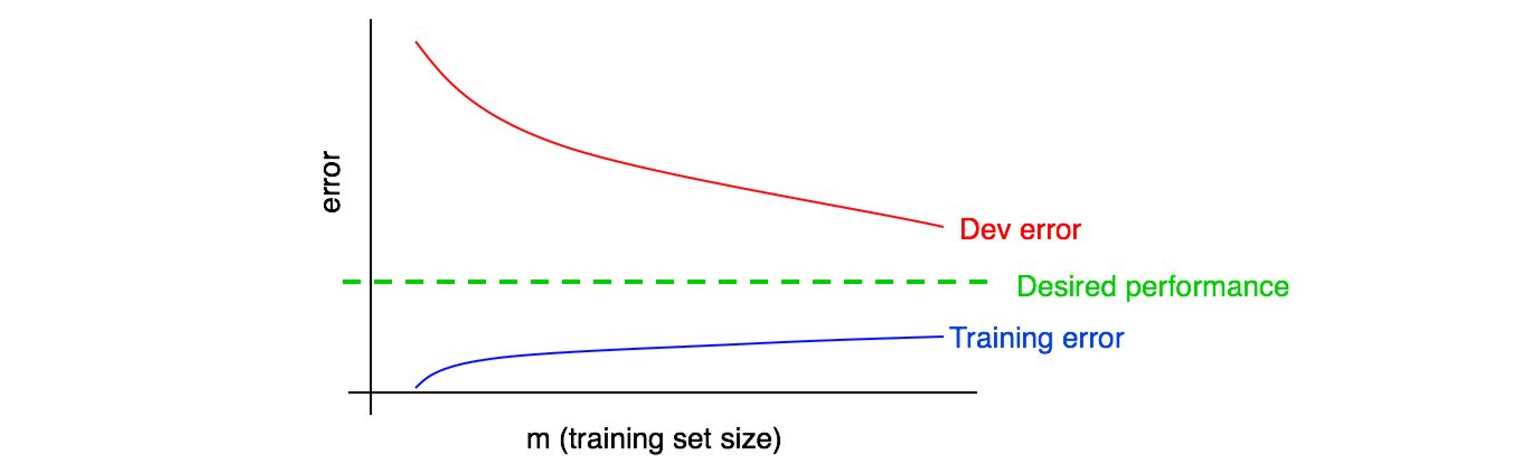
你可以看到蓝色的“训练误差曲线”是随着训练集样本量的增大而增大的。此外,你的算法的在训练集上的表现通常要好于开发集,因此,红色的开发及误差曲线一般来说会严格地高于训练误差曲线。
接下来,让我们讨论如何解读这些曲线图。

若有收获,就点个赞吧
0 人点赞
