1.特征选择
1.1.低方差过滤
- 删除方差低于阈值的列- sklearn.feature_selection.VarianceThreshold(threshold=0)
1.2.相关系数
- 皮尔逊相关系数- 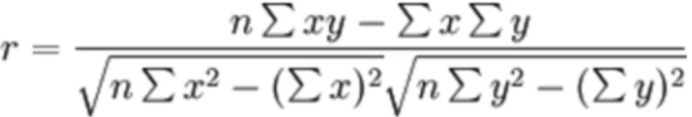- [-1,1],绝对值越大相关性越强,正值正相关,负值负相关- scipy.stats.pearsonr(x1,x2)- 斯皮尔曼相关系数- 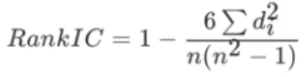- [-1,1],绝对值越大相关性越强,正值正相关,负值负相关- scipy.stats.spearmanr(x1,x2)
2.主成分分析PCA
- sklearn.decomposition.PCA(n_components=None)
- n_components为整数n时,保留n列
- n_components为小数f时,保留100f%的信息

若有收获,就点个赞吧
0 人点赞
