- Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8S
- Kubernetes用于容器化应用程序的部署,扩展和管理。目标是让部署容器化应用简单高效
在 v1.18 版本中, Kubernetes 支持的最大节点数为 5000,舒适区为 100~1000
- 节点数不超过 5000
- Pod 总数不超过 150000
- 容器总数不超过 300000
- 每个节点的 pod 数量不超过 100
Kubernetes
又称K8S(首字母是K与为字母S之间有8个字符,所以简称K8S),是一种可自动实施Linux容器操作的开源平台,它可以帮助用户省去应用容器化过程的许多手动部署和扩展操作。可以理解为将运行在Linux容器的多组主机聚集在一起,由Kubernetes帮助轻松搞笑的管理这些集群。也就是说,可以将运行 Linux 容器的多组主机聚集在一起,由 Kubernetes 帮助轻松高效地管理这些集群。而且,这些集群可跨公共云、私有云或混合云部署主机。Kubernetes 是理想的托管平台。
Kubernetes最初由Google工程师开发和设计。Google是最早研发Linux容器技术的企业之一(组建了cgroups),曾公开分享介绍Google如何将一切都运行于容器之中(这是Google云服务背后的技术)。Google每周会启用超过20亿个容器,全都由内部平台Borg支撑。Borg是Kubernetes的前身,多年开发Borg的经验成了Kubernetes中许多技术的主要因素。
红帽是第一批与 Google 合作研发 Kubernetes 的公司之一,2015 年,Google 将 Kubernetes 项目捐赠给新成立的云原生计算基金会。
Kubernetes是谷歌使用了将近20年的一个云产品,是Borg的一个开源版本。Borg是谷歌的一个久负盛名的内部使用的大规模集群管理系统,它基于容器技术,目的是实现资源管理的自动化,以及跨多个数中心的资源利用率的最大化。十几年来,谷歌一直通过 Borg 系统管理着数量庞大的应用程序集群。由于谷歌员工都签署了保密协议,即便离职也不能泄露Borg的内部设计,所以外界一直无法了解关于它的更多信息。直到2015年4月,传闻许久的 Borg 论文伴随 Kuberneters 的高调宣传被谷歌首次公开,大家才得以了解它的更多内幕。正是由于站在 Borg 这个前辈的肩膀上,吸取了 Borg 过去十年间的经验与教训,所以 Kubernetes 一经开源就一鸣惊人,并迅速称霸了容器技术领域。
Kubernetes 拥有一个庞大且快速增长的生态系统。因为它是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。Kubernetes 的服务、支持和工具广泛可用。
Kubernetes 源于希腊语,意为 “舵手” 或 “飞行员”。Google 在 2014 年开源了 Kubernetes 项目。Kubernetes 建立在 Google 在大规模运行生产工作负载方面拥有十几年的经验的基础上,结合了社区中最好的想法和实践。
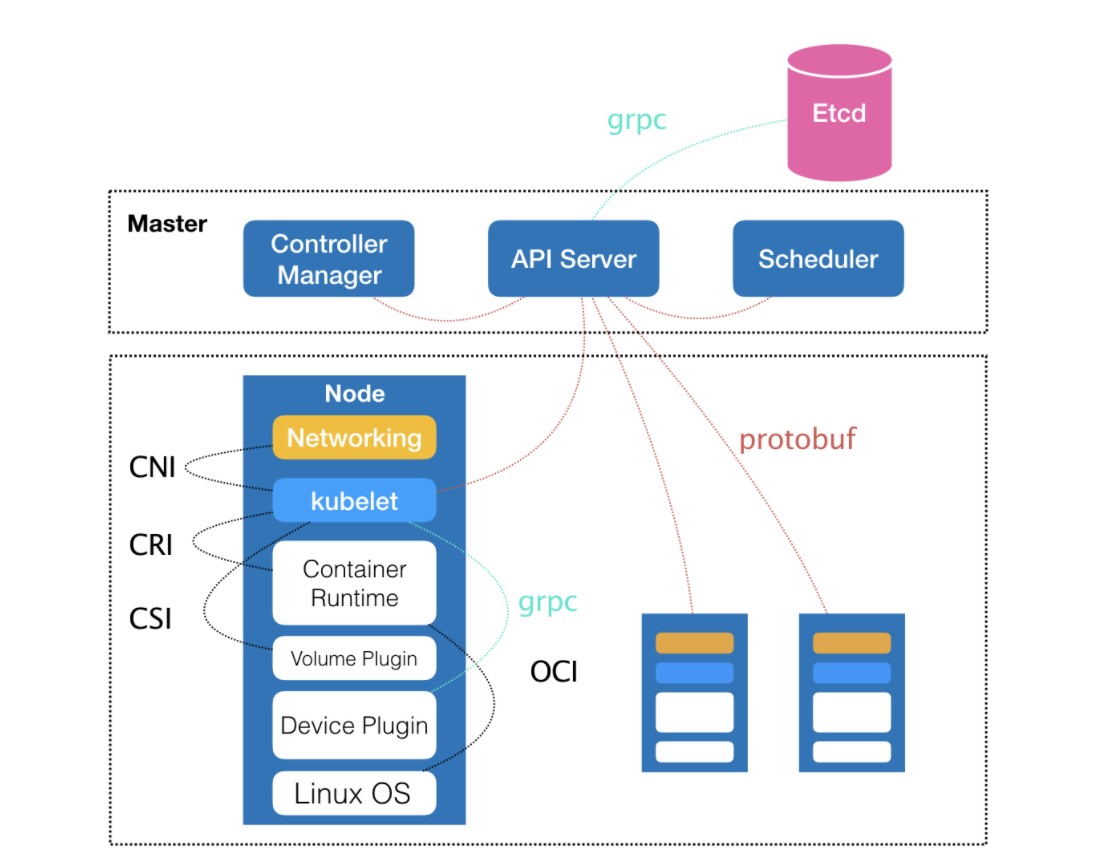
Kubernetes项目的架构,由Master和Node两种节点组成,分别对应控制节点(Master)和计算节点(Node)。其中,控制节点(Master),由三个紧密协作的独立组件组合而成,它们分别是负责API服务的kube-apiserver,负责调度的kube-scheduler,以及负责容器编排的kube-controller-manager。整个集群的持久化数据,则由kube-apiserver处理后保存在Etcd中。
为什么需要Kubernetes
真正的生产型应用会涉及多个容器。这些容器必须跨多个服务器主机进行部署。容器安全性需要多层部署,因此会比较复杂。但Kubernetes有助于解决这一问题。Kubernetes可以提供所需的编排和管理功能,以便针对这些工作负载大规模部署容器。借助Kubernetes编排功能,可以构建跨多个容器的应用服务、跨集群调度、扩展这些容器,并长期持续管理这些容器的健康状态。
Pod、节点、容器和集群都是什么?
节点(Node)
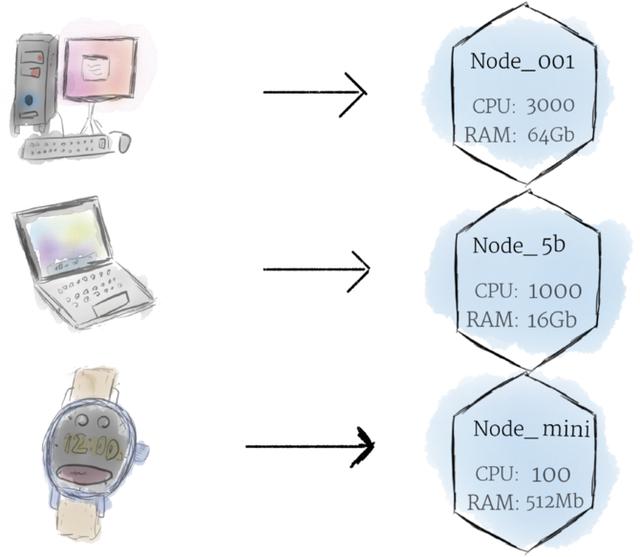
Node 是机器。它们是 Kubernetes 用于部署 Pod 的“裸机”(或虚拟机)。Node 为 Kubernetes 提供可用的集群资源用于以保持数据、运行作业、维护工作负载、创建网络路由等。
节点是Kubernetes中最小的计算硬件单元。它是集群中单个机器的表示。在大多数生产系统中,节点很可能是数据中心中的物理机器,或者是托管在像谷歌云平台这样的云供应商上的虚拟机。
把机器看作一个“节点”,可以让我们插入一个抽象层。不必担心任何单个机器的独特特性,而是可以简单地将每台机器看作一组可以使用的CPU和RAM资源。这样,任何机器都可以替代Kubernetes集群中的任何其他机器。
集群(Cluster)
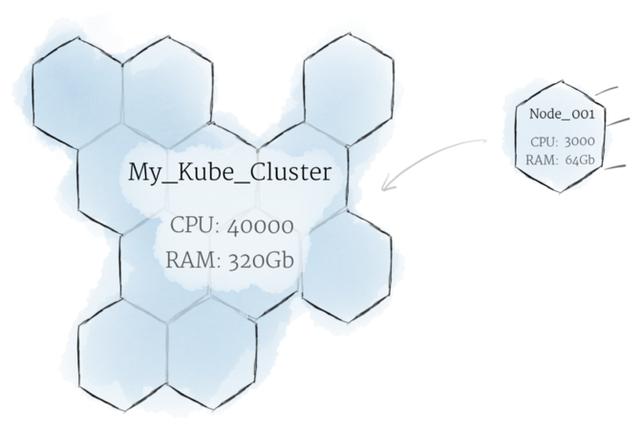
虽然使用单个节点是有用的,但它与Kubernetes理念不同。一般来说,应该将集群看作一个整体,而无需担心单个节点的状态。
在Kubernetes中,节点汇聚资源,形成更强大的机器。当将程序部署到集群中时,它将智能地处理将工作分配给各个节点。如果添加或删除了任何节点,集群将根据需要在工作中进行转换。这对程序或程序员来说都不重要,因为机器实际上是在运行代码。
持久卷(Persistent Volumes)
因为在集群上运行的程序不能保证在特定的节点上运行,所以无法将数据保存到文件系统中的任意位置。如果一个程序试图将数据保存到一个文件中,但随后又被转移到一个新的节点上,那么该文件将不再是程序期望的位置。由于这个原因,与每个节点相关的传统本地存储被当作临时缓存来保存程序,但本地保存的任何数据都不能持久。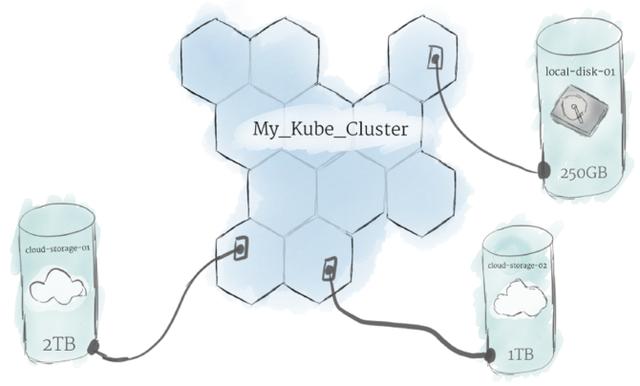
为了永久存储数据,Kubernetes使用持久卷(PersistentVolumes)。虽然所有节点的CPU和RAM资源都被集群有效地汇集和管理,但持久的文件存储却不是。相反,本地或云驱动器可以作为持久卷附加到集群上。这可以看作是将外部硬盘插入到集群中。持久卷提供了可以挂载到集群的文件系统,而不与任何特定节点相关联。
容器(Container)
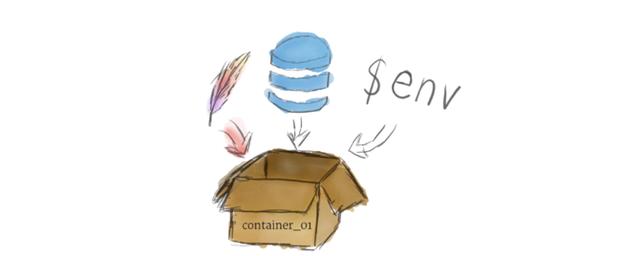
在Kubernetes上运行的程序被打包成Linux容器。容器是一个被广泛接受的标准,因此已经有许多预先构建的映像可以部署在Kubernetes上。
容器化允许创建自足式的Linux执行环境。任何程序和它的所有依赖项都可以打包成一个文件,然后在网络上共享。任何人都可以下载该容器并在其基础设施上部署它,所需的设置非常少。创建一个容器可以通过编程方式完成,从而形成强大的CI和CD管道。
可以将多个程序添加到单个容器中,但是如果可能的话,应该将自己限制为每个容器的一个进程。拥有很多小容器比一个大容器好。如果每个容器都有一个紧密的焦点,那么更新更容易部署,并且问题更容易诊断。
Pod
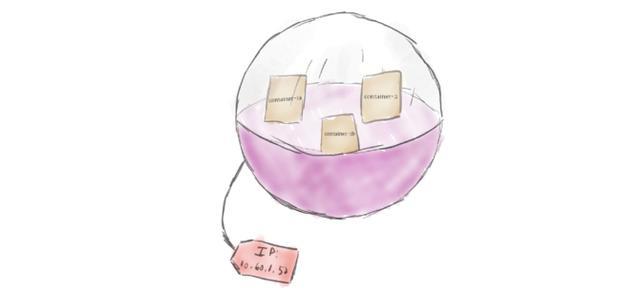
与过去使用的其他系统不同,Kubernetes不直接运行容器。相反,它将一个或多个容器封装到一个称为Pod的高级结构中。相同Pod中的任何容器都将共享相同的名称空间和本地网络。容器可以很容易地与其他容器在相同的容器中进行通信,就像它们在同一台机器上同时保持一定程度的隔离。
Pod被用作Kubernetes的复制单元。如果应用程序太受欢迎,单个的Pod实例无法承载负载,那么可以配置Kubernetes以在必要时将Pod的新副本部署到集群。即使在没有重载的情况下,在生产系统中任何时候都要有多个副本,以保证负载均衡和故障抵抗。
Pod可以容纳多个容器,但在可能的情况下应该限制自己。因为Pod作为一个单位被放大和缩小时,所有在一个Pod里的容器都必须在一起缩放,不管它们是否需要。这将导致资源的浪费和成本增加。为了解决这个问题,Pod应该保持尽可能小的大小。
部署(Deployment)
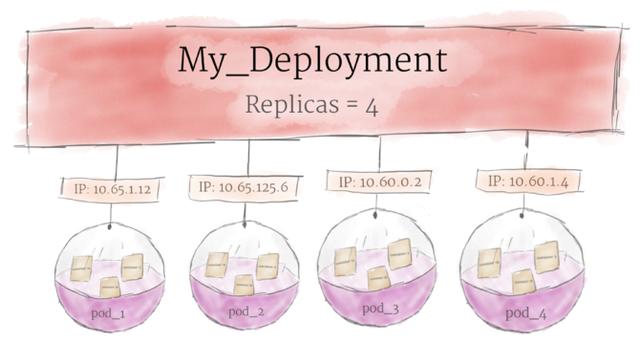
虽然Pod是Kubernetes的基本计算单元,但它们通常不是直接在集群上启动的。相反,Pod通常由一个抽象层来管理:部署。
部署的主要目的是声明一个Pod应该同时运行多少个副本。当将部署添加到集群中时,它将自动地旋转加速所需的Pod数量,然后监视它们。如果一个Pod消失,部署将自动重新创建它。使用部署,不必手动处理Pod。只需声明系统的期望状态,它将自动管理。
入口(Ingress)
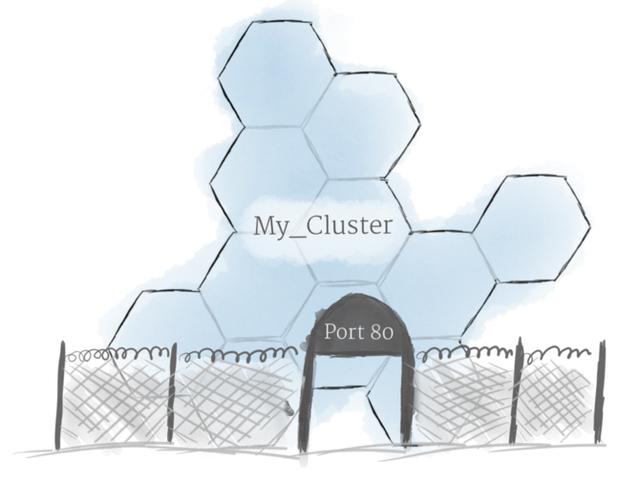
使用上面描述的概念,可以创建一个节点集群,并将Pod部署到集群上。不过,还有一个问题需要解决:允许外部通信流进入你的应用程序。
默认情况下,Kubernetes提供隔离舱和外部世界。如果想要与运行在Pod中的服务通信,就必须打开一个通信通道。称作入口(ingress)。
有多种方法可以将入口添加到集群中。最常见的方法是添加入口控制器或负载均衡器。这两个选项之间的精确权衡超出了本文的范围,但是必须知道,在可以与Kubernetes进行实验之前,需要处理的是入口。

若有收获,就点个赞吧
0 人点赞
