Pod 是 Kubernetes 中最小的可互动单元。一个 Pod 可以由多个容器组成,这些容器共同部署在单个节点上形成一个单元。一个 Pod 具有一个 IP,该 IP 在其容器之间共享。
Pod基本概念
- 最小部署单元
- 一组容器的集合
- 一个Pod中的容器共享命名空间
- Pod是短暂的
Pod存在的意义
Pod为亲密性应用而存在
- 两个应用之间发生文件交互
- 两个应用需要通过127.0.0.1或者socket通信(典型组合:nginx+php)
- 两个应用需要发生频繁的调用
Pod实现机制与设计模式
- 共享网路(Pause)
- 共享存储(Volume)
Pod的状态
| 状态值 | 描述 |
|---|---|
| Pending | API Server 已经创建该Pod,但在Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程 |
| Running | Pod 内所有容器均已创建,且至少有一个容器处于运行状态,正在启动状态或正在重启状态 |
| Succeeded | Pod 内所有容器均已成功执行后退出,且不会再重启 |
| Failed | Pod 内所有容器均已退出,但至少有一种容器退出为失败状态 |
| Unknown | 由于某种原因无法获该Pod的状态,可能由于网路通信不畅导致 |
镜像拉取策略(imagePullPolicy)
- IfNotPresent:默认值,镜像在宿主机上不存在时才拉取
- Always:每次创建Pod都会重新拉取一次镜像
- Nerver:Pod永远不会主动拉取这个镜像
注:K8S通过命令行部署的应用,默认值是Always。通过yaml创建的默认为IfNotPresent。
资源限制
容器资源限制(K8S目前支持):
1、内存限制
2、CPU限制
Pod和Container的资源请求和限制:
limits:实际最大使用的配额,当前最大用量
requests:申请的配额,主要用于k8s做资源调度分配时参考值。
资源限制的好处:避免某个容器资源利用率异常,造成突发影响其他容器,可能会产生雪崩效应
例: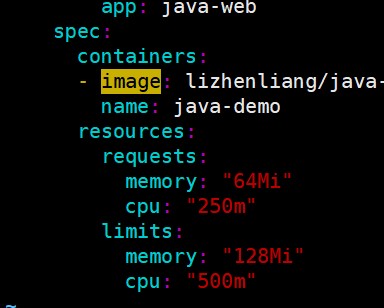
单位(CPU写法):1000m = 1cpu
500m = 0.5cpu
250m = 0.25cpu
生命周期和重启策略
Pod重启策略(restartPolicy)
Pod的重启策略(RestartPolicy)应用于pod里的所有容器,并且仅在Pod所在的Node。由pod所在node上的kubelet判断和操作,当某个容器异常退出或健康检查时,kubelet根据设置的RestartPolicy来设置相应的操作。
重启策略:当Pod有异常时,k8s会拉起Pod
- Always:当容器终止退出或失效时,有kubelet自动重启该容器。默认策略
- OnFailure:当容器异常退出或终止运行且(退出状态码非0)时,由kubelet重启该容器
- Nerver:当容器终止退出,或者不管容器是任何状态,kubelet均不会重启容器
Always使用场景:守护进程式,要求持续性运行,例如nginx、mysql、redis
Pod的重启策略与控制器的关系
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)
- ReplicationController和daemonSet:必须设置为Always,需要保持该容器一直运行
- Job:OnFailure或never,确保容器执行完之后不再重启
- kubelet:在pod失效时重启它,不论RestartPolicy设置什么,不会对pod进行健康检查
健康检查(Probe)
Probe有以下两种类型:
- livenessProbe(存活检查)
如果检查失败,将杀死容器,根据Pod的restartPolicy来操作。
- readinessProbe(就绪检查)
如果检查失败,Kubernetes会把Pod从service endpoints中剔除。
Probe支持以下三种检查方法:
- httpGet
发送HTTP请求,返回200-400范围状态码为成功。
- exec
执行Shell命令返回状态码是0为成功。
- tcpSocket
发起TCP Socket建立成功。
调度策略
【十期/六章】
创建Pod的流程:
kubectl -> create pod -> api server -> etcd
scheduler -> api server -> bound pod to node
kubectl -> api server -> bound self pod -> docker run container -> api server update pod status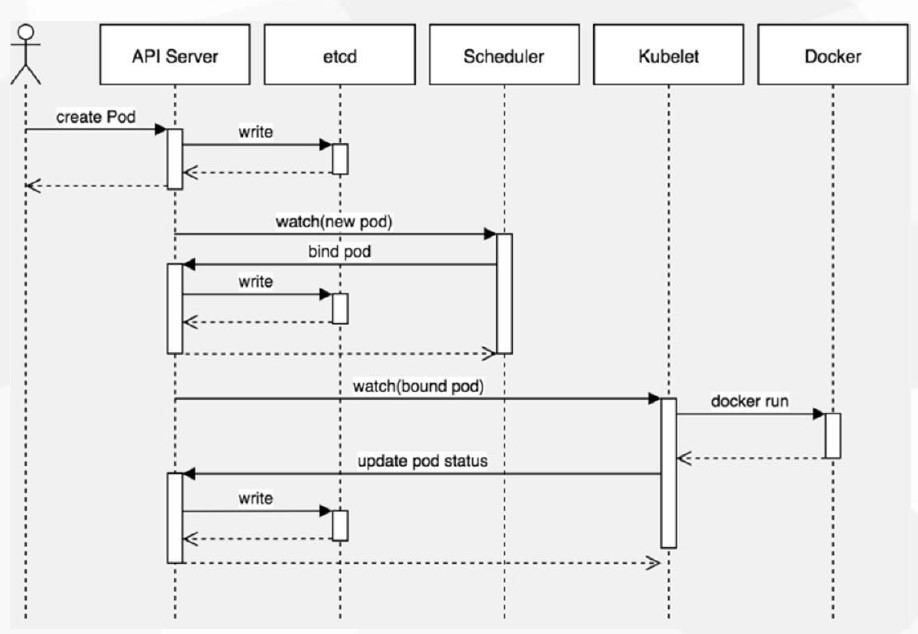
调度策略(Taints)
- nodeName
- nodeSelector
- 污点与容忍
nodeName:用于将Pod调度到指定的Node名称上
nodeSelector:用于将Pod调度到匹配的Label的Node上
nodeSelector场景:
场景一:根据团队对机器进行分组,不同业务资源池
场景二:根据环境分组,例如测试、开发、预生产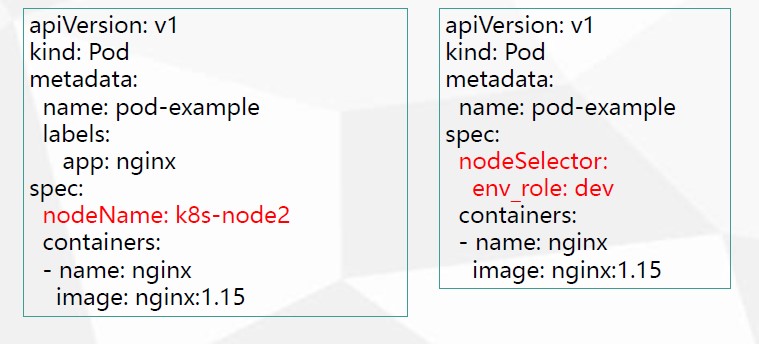
事例:nodeSelector的调度策略
1、给节点打个标签
kubectl label nodes k8s-node1 team=1
kubectl label nodes k8s-node2 team=2
###(删除标签)###
kubectl label nodes k8s-node1 team-
kubectl label nodes k8s-node2 team-
2、查看标签
kubectl get node —show-labels
3、vim nodeSelector.yaml
apiVersion: v1kind: Podmetadata:name: pod-examplelabels:app: nginxspec:nodeSelector:team: "1"containers:- name: nginximage: nginx:1.15
4、创建并查看Pod
kubectl apply -f nodeSelector.yaml
kubectl get pods -o wide
污点应用场景
- 节点独占
- 具有特殊硬件设备的节点
设置污点:
kubectl taint node [node] key=value:effect
例:kubectl taint node k8s-node1 test=123:NoSchedule
其中 [effect] 可取值:
NoSchedule :一定不能被调度
PreferNoSchedule:尽量不要调度(非强制性)
NoExecute:不仅不会调度,还会驱逐Node上已有的Pod(对现有的Pod会有印象,现有Pod没有容忍,将会被驱逐)
查看有无打上污点:
例:kubectl describe node | grep Taint
删除污点:
kubectl taint node [node] key:[effect]-
例:kubectl taint node k8s-node1 test:NoSchedule-
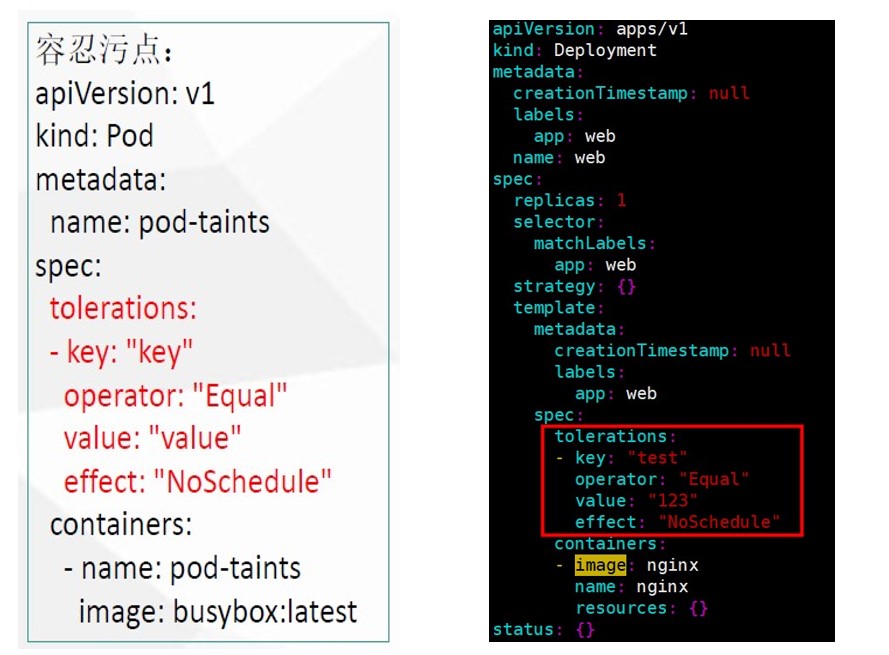
添加容忍污点(容忍污点:例如设有节点打了污点,还希望将Pod调度到带有污点的机器)
重新创建个yaml并修改yaml配置
例:
# kubectl create deployment web --image=nginx -o yaml --dry-run > web.yaml
# vim web.yaml
故障排查
kubectl describe TYPE/NAME (容器没起来,要查看什么原因没起来,查看event事件)
kubectl logs TYPE/NAME [-c CONTAINER] (容器已经起来才可以使用,例如容器起来了但不能正常使用)
kubectl exec POD [-c CONTAINER] —COMMAND [args…] (进入容器,若有多个容器使用-c指定)

若有收获,就点个赞吧
0 人点赞
