1 Flink概述
1.1 数据流与流计算
数据流是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的
另一端看到的是一股连续不断的水流。类似于人们对河流的理解本质上也就是流的概念,但是这条河没
有开始也没有结束,数据流非常适合于离散的、没有开头或结尾的数据。例如,交通信号灯的数据是连
续的,没有“开始”或“结束”,是连续的过程而不是分批发送的数据记录。通常情况下,数据流对于在生
成连续数据流中以小尺寸(通常以KB字节为单位)发送数据的数据源类型是有用的。这包括各种各样的
数据源,例如来自连接设备的遥测,客户访问的Web应用时生成的日志文件、电子商务交易或来自社交
网络或地理LBS服务的信息等。
传统上,数据是分批移动的,批处理通常同时处理大量数据,具有较长时间的延迟。例如,该复制过程
每24小时运行一次。虽然这可以是处理大量数据的有效方法,但它不适用于流式传输的数据,因为数据
在处理时已经是旧的内容。
采用数据流是时间序列和随时间检测模式的最佳选择。例如,跟踪Web会话的时间。大多数物联网产生
的数据非常适合数据流处理,包括交通传感器,健康传感器,交易日志和活动日志等都是数据流的理想
选择。
流数据通常用于实时聚合和关联、过滤或采样。通过数据流,我们可以实时分析数据,并深入了解各种
行为,例如统计,服务器活动,设备地理位置或网站点击量等。
无界数据流
顾名思义,无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理。
有界数据流
相对而言,有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理。
数据流整合技术的解决方案
金融机构跟踪市场变化,并可根据配置约束(例如达到特定股票价格时出售)调整客户组合的配
置。
电网监控吞吐量并在达到某些阈值时生成警报。
新闻资讯APP从各种平台进行流式传输时,产生的点击记录,实时统计信息数据,以便它可以提供
与受众人口相关的文章推荐。
电子商务站点以数据流传输点击记录,可以检查数据流中的异常行为,并在点击流显示异常行为时
发出安全警报。
数据流带给我们的挑战
数据流是一种功能强大的工具,但在使用流数据源时,有一些常见的挑战。以下的列表显示了要规划数
据流的一些事项:可扩展性规划
- 数据持久性规划
-
数据流的管理工具
随着数据流的不断增长,出现了许多合适的大数据流解决方案。我们总结了一个列表,这些都是用于处
理流数据的常用工具: Apache Kafka
Apache Kafka是一个分布式发布/订阅消息传递系统,它集成了应用程序和数据流处理。
- Apache Storm
Apache Storm是一个分布式实时计算系统。Storm用于分布式机器学习、实时分析处理,尤其是其具
有超高数据处理的能力。
- Apache Flink
Apache Flink是一种数据流引擎,为数据流上的分布式计算提供了诸多便利。
1.2 Flink简介
Apache Flink 是一个开源的分布式流式处理框架,是新的流数据计算引擎,用java实现。Flink可以:
- 提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
- 它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
- 大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
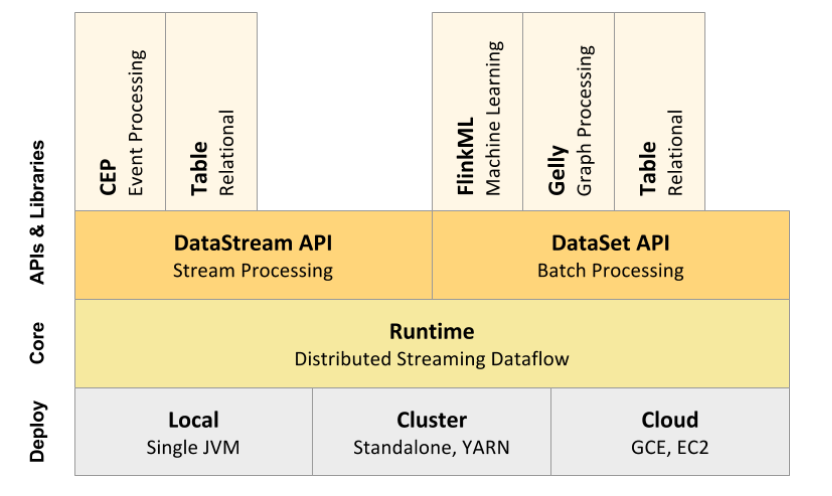
1.3 应用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括: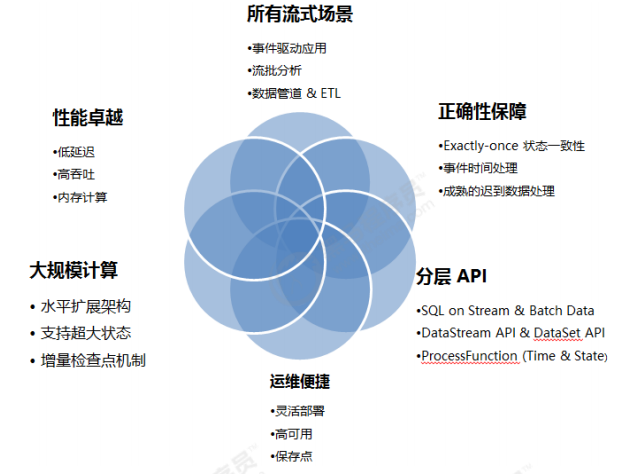
Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集
群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展
到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛
的流处理应用都运行在 Flink 之上。
Flink适用的应用场景包括:
1. 事件驱动型应用
- 反欺诈
- 异常检测
- 基于规则的报警
- 业务流程监控
- (社交网络)Web 应用
- 数据分析应用
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
- 数据管道应用
- 电商中的实时查询索引构建
-
1.4 Flink架构
Flink在运行中主要有三个组件组成,JobClient,JobManager 和 TaskManager。
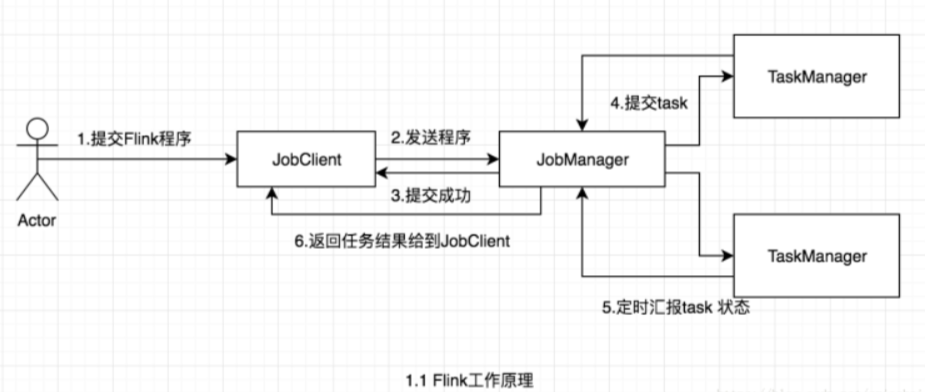
作业提交流程如下:
Program Code:我们编写的 Flink 应用程序代码。
Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责
接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完<br /> 成后,Job Client 将结果返回给用户。
Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任
务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,<br /> 协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是<br /> standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件。
Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或
多个线程中执行任务的工作节点。 任务执行的并行性由每个 Task Manager 上可用的任务槽决<br /> 定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将<br /> 为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相<br /> 同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可<br /> 用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink<br /> 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可<br /> 以有更好的资源利用率。
1.5 安装配置
Flink的运行一般分为三种模式,即local、Standalone、On Yarn。
下载程序
``` [root@node2-vm06 opt]# cd /opt [root@node2-vm06 opt]# wget -c http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.1/flink-1.9.1-bin- scala_2.12.tgz
[root@node2-vm06 opt]# tar xzf flink-1.9.1-bin-scala_2.12.tgz
<a name="ekXXR"></a>#### 1. Local模式Local模式比较简单,用于本地测试,安装过程也比较简单,只需在主节点上解压安装包就代表成功安<br />装了,在flflink安装目录下使用./bin/start-cluster.sh(windows环境下是.bat)命令,就可以通过<br />master:8081监控集群状态,关闭集群命令:./bin/stop-cluster.sh(windows环境下是.bat)。<a name="yKk14"></a>#### 2. Standalone模式Standalone模式顾名思义,是在本地集群上调度执行,不依赖于外部调度机制例如YARN。此时需要对<br />配置文件进行一些简单的修改,我们预计使用当前服务器充当Job manager和Task Manager,一般情<br />况下需要多台机器。<br />在安装Flink之前,需要对安装环境进行检查,对于Standalone模式,需要提前安装好zookeeper。<br />1) 修改环境变量,vim /etc/profifile,添加以下内容
export FLINK_HOME=/opt/flink-1.9.1/ export PATH=$FLINK_HOME/bin:$PATH
2) 更改配置文件flflink-conf.yaml,<br />cd /opt/flflink-1.9.1/conf<br />vim flflink-conf.yaml
主要更改的位置有:
jobmanager.rpc.address: 172.17.0.143 taskmanager.numberOfTaskSlots: 2 parallelism.default: 4
取消下面两行的注释
rest.port: 8081 rest.address: 0.0.0.0
上述我们只列出了一些常用需要修改的文件内容,下面我们再简单介绍一些
jobManager 的IP地址
jobmanager.rpc.address: 172.17.0.143
JobManager 的端口号
jobmanager.rpc.port: 6123
JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
每个 TaskManager 提供的任务 slots 数量大小,默认为1
taskmanager.numberOfTaskSlots: 2
程序默认并行计算的个数,默认为1
parallelism.default: 4
2) 配置masters文件<br />该文件用于指定主节点及其web访问端口,表示集群的Jobmanager,vim masters,添加<br />**localhost:8081**<br />3) 配置slaves文件,该文件用于指定从节点,表示集群的taskManager。添加以下内容
localhost localhost localhost
4) 启动flflink集群 (因为在环境变量中已经指定了flflink的bin位置,因此可以直接输入start-cluster.sh)<br />5) 验证flflink进程,登录web界面,查看Web界面是否正常。至此,standalone模式已成功安装。<a name="5XlmI"></a># <a name="VyhRM"></a>## 1.6创建Maven工程
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.11.0
<a name="0u5Iw"></a>## 1.7 Flink状态管理与CheckPointFlink的失败恢复依赖于 _**检查点机制**_ + _**可部分重发的数据源**_。<br />**检查点机制机制**:checkpoint定期触发,产生快照,快照中记录了:1. 当前检查点开始时数据源(例如Kafka)中消息的offset。1. 记录了所有有状态的operator当前的状态信息(例如sum中的数值)。- Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。快照的核心概念之一是barrier。 这些barrier被注入数据流并与记录一起作为数据流的一部分向下流动。 barriers永远不会超过记录,数据流严格有序,barrier将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。- 每个barrier都带有快照的ID,并且barrier之前的记录都进入了该快照。 barriers不会中断流处理,非常轻量级。 来自不同快照的多个barrier可以同时在流中出现,这意味着多个快照可能并发地发生。**Checkpoint设置值**:- **exactly-once**:即使producer重试发送消息,消息也会保证最多一次地传递给最终consumer。- **at-least-once**:此重试将导致该消息被写入两次,因此消息会被不止一次地传递给最终consumer,这种策略可能导致重复的工作和不正确的结果。<a name="9fE59"></a># 2 基本概念<a name="LCVmM"></a>## 2.1 DataStream和DataSetFlink使用DataStream、DataSet在程序中表示数据,我们可以将它们视为可以包含重复项的不可变数<br />据集合。<br />DataSet是有限数据集(比如某个数据文件),而DataStream的数据可以是无限的(比如kafka队列中<br />的消息)。<br />这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法<br />添加或删除元素。你也不能简单地检查里面的元素。<br />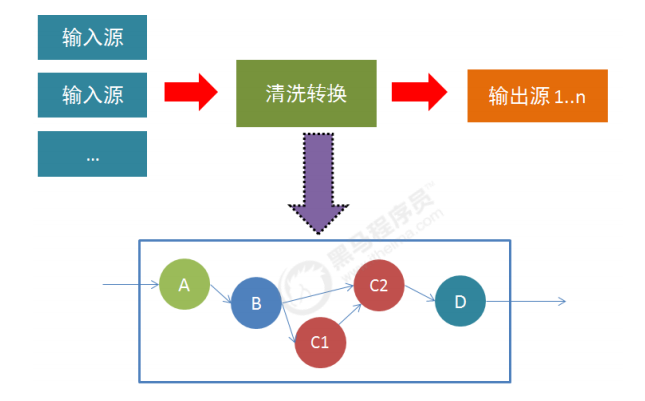<br />数据流通过fifilter/map等各种方法,执行过滤、转换、合并、拆分等操作,达到数据计算的目的。<br />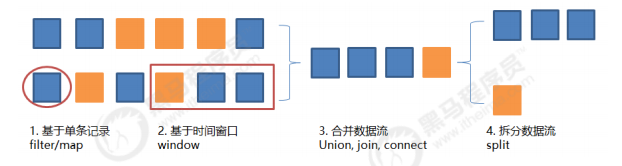<a name="dLlQZ"></a>## 2.2 数据类型Flink对DataSet或DataStream中可以包含的元素类型设置了一些限制,以便于更有效的执行策略。<br />有六种不同类别的数据类型:<br />**1. Java元组和Scala案例类**<br />**2. Java POJO**<br />**3. 原始类型**<br />**4. 常规类**<br />**5. 值**<br />**6. Hadoop Writables**<a name="mWISa"></a>### 2.2.1 元组元组是包含固定数量的具有各种类型的字段的复合类型。Java API提供了 Tuple1 到 Tuple25 。元组的<br />每个字段都可以是包含更多元组的任意Flink类型,从而产生嵌套元组。可以使用字段名称直接访问元组<br />的字段 tuple.f4 ,或使用通用getter方法 tuple.getField(int position) 。字段索引从0开始。请<br />注意,这与Scala元组形成对比,但它与Java的一般索引更为一致。```javaDataStream<Tuple2<String, Integer>> wordCounts = env.fromElements(new Tuple2<String, Integer>("hello", 1),new Tuple2<String, Integer>("world", 2));wordCounts.map(new MapFunction<Tuple2<String, Integer>, Integer>() {@Overridepublic Integer map(Tuple2<String, Integer> value) throws Exception {return value.f1;}});wordCounts.keyBy(0); // also valid .keyBy("f0")
2.2.2 POJOs
如果满足以下要求,则Flink将Java和Scala类视为特殊的POJO数据类型:
- 类必须公开类
- 它必须有一个没有参数的公共构造函数(默认构造函数)。
所有字段都是公共的,或者必须通过getter和setter函数访问。对于一个名为 foo 的属性的getter
和setter方法的字段必须命名 getFoo() 和 setFoo() 。
注册的序列化程序必须支持字段的类型。
序列化:
POJO通常使用PojoTypeInfo和PojoSerializer(使用Kryo作为可配置的回退)序列化。例外情况是
POJO实际上是Avro类型(Avro特定记录)或生成为“Avro反射类型”。在这种情况下,POJO使用
AvroTypeInfo和AvroSerializer序列化。如果需要,还可以注册自己的自定义序列化程序
public class WordWithCount {public String word;public int count;public WordWithCount() {}public WordWithCount(String word, int count) {this.word = word;this.count = count;}}DataStream<WordWithCount> wordCounts = env.fromElements(new WordWithCount("hello", 1),new WordWithCount("world", 2));wordCounts.keyBy("word"); // key by field expression "word"
2.2.3 基础数据类型
Flink支持所有Java和Scala的原始类型,如 Integer , String 和 Double 。
2.2.4 常规类
Flink支持大多数Java和Scala类(API和自定义)。限制适用于包含无法序列化的字段的类,如文件指
针,I / O流或其他本机资源。遵循Java Beans约定的类通常可以很好地工作。
所有未标识为POJO类型的类都由Flink作为常规类类型处理。Flink将这些数据类型视为黑盒子,并且无
法访问其内容(例如,用于有效排序)。使用序列化框架Kryo对常规类型进行反序列化。
2.2.5 值
值类型手动描述其序列化和反序列化。它们不是通过通用序列化框架,而是通过
org.apache.flinktypes.Value 使用方法 read 和实现接口为这些操作提供自定义代码 write 。当通
用序列化效率非常低时,使用值类型是合理的。一个示例是将元素的稀疏向量实现为数组的数据类型。
知道数组大部分为零,可以对非零元素使用特殊编码,而通用序列化只需编写所有数组元素。
该 org.apache.flinktypes.CopyableValue 接口以类似的方式支持手动内部克隆逻辑。
Flink带有与基本数据类型对应的预定义值类型。( ByteValue , ShortValue , IntValue ,
LongValue , FloatValue , DoubleValue , StringValue , CharValue , BooleanValue )。这
些值类型充当基本数据类型的可变变体:它们的值可以被更改,允许程序员重用对象并从垃圾收集器中
消除压力。
2.2.6. Hadoop Writables
使用实现 org.apache.hadoop.Writable 接口的类型。
write() 和 readFields() 方法中定义的序列化逻辑将用于序列化。
2.3 数据的操作
数据转换,即通过从一个或多个 DataStream 生成新的DataStream 的过程,是主要的数据处理的手
段。Flink 提供了多种数据转换操作,基本可以满足所有的日常使用场景。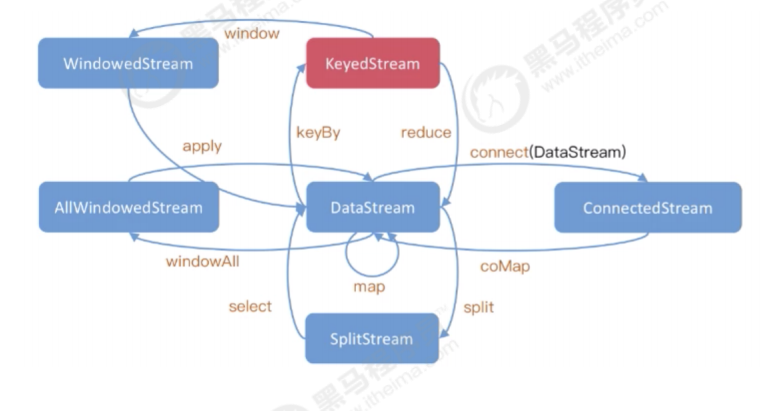
2.4 窗口的含义
Flink计算引擎中,时间是一个非常重要的概念,Flink的时间分为三种时间:
- EventTime: 事件发生的时间
- IngestionTime:事件进入 Flink 的时间
- ProcessingTime:事件被处理时的时间
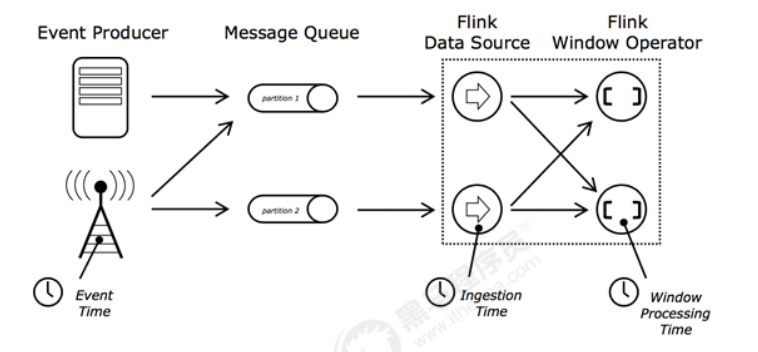
窗口是Flink流计算的一个核心概念,Flink窗口主要包括:
- 时间窗口
- 翻滚时间窗口
- 滑动时间窗口
- 数量窗口
- 翻滚数量窗口
- 滑动数量窗口
按照形式来划分,窗口又分为:
- 翻滚窗口
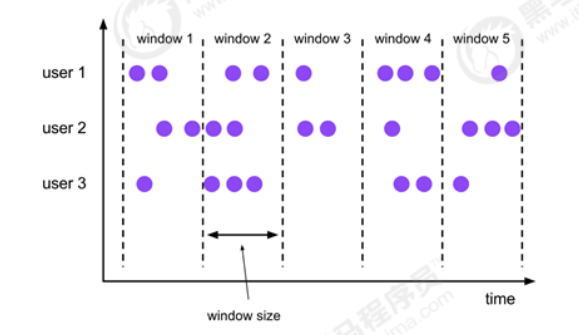
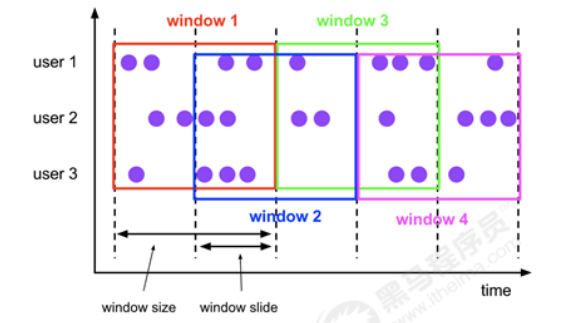
- 滑动窗口
2.5 有状态的流式处理
在很多场景下,数据都是以持续不断的流事件创建。例如网站的交互、或手机传输的信息、服务器日
志、传感器信息等。有状态的流处理(stateful stream processing)是一种应用设计模式,用于处理无
边界的流事件。
对于任何处理流事件的应用来说,并不会仅仅简单的一次处理一个记录就完事了。在对数据进行处理或
转换时,操作应该是有状态的。也就是说,需要有能力做到对处理记录过程中生成的中间数据进行存储
及访问。当一个应用收到一个 事件,在对其做处理时,它可以从状态信息(state)中读取数据进行协
助处理。或是将数据写入state。在这种准则下,状态信息(state)可以被存储(及访问)在很多不同
的地方,例如程序变量,本地文件,或是内置的(或外部的)数据库中。
Apache Flink 存储应用状态信息在本地内存或是一个外部数据库中。因为Flink 是一个分布式系统,本
地状态信息需要被有效的保护,以防止在应用或是硬件挂掉之后,造成数据丢失。Flink对此采取的机制
是:定期为应用状态(application state)生成一个一致(consistent)的checkpoint,并写入到一个
远端持久性的存储中。下面是一个有状态的流处理Flink application的示例图: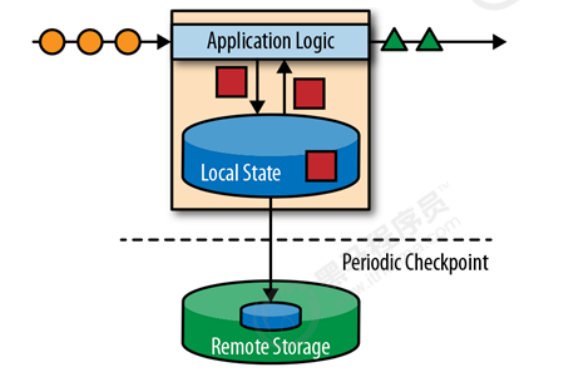
Stateful stream processing 应用的输入一般为:事件日志(event log)的持续事件。Event log 存储
并且分发事件流。事件被写入一个持久性的,仅可追加的(append-only)日志中。也就是说,被写入
的事件的顺序始终是不变的。所以事件在发布给多个不同用户时,均是以完全一样的顺序发布的。在开
源的event log 系统中,最著名的当属 Kafka。
使用flflink流处理程序连接event log的理由有多种。在这个架构下,event log 持久化输入的 events,并
且可以以既定的顺序重现这些事件。万一应用发生了某个错误,Flink会通过前一个checkpoint 恢复应
用的状态,并重置在event log 中的读取位置,并据此对events做重现,直到它抵达stream 的末端。这
个技术不仅被用于错误恢复,并且也可以用于更新应用,修复bugs,以及修复之前遗漏结果等场景中。
3 DataStream编程
3.1 输入流
源是程序从中读取输入的位置,可以使用以下方法将源附加到您的程序:
StreamExecutionEnvironment.addSource(sourceFunction) 。
Flink附带了许多预先实现的源函数,但您可以通过实现 SourceFunction 非并行源,或通过实现
ParallelSourceFunction 接口或扩展 RichParallelSourceFunction for parallel源来编写自己的自
定义源。
有几个预定义的流源可从以下位置访问 StreamExecutionEnvironment :
基于文件:
readTextFile(path) - TextInputFormat 逐行读取文本文件,即符合规范的文件,并将它们作
为字符串返回。
readFile(fileInputFormat, path) - 按指定的文件输入格式指定读取(一次)文件。
readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这
是前两个内部调用的方法。它 path 根据给定的内容读取文件 fileInputFormat 。根据提供的内
容 watchType ,此源可以定期监视(每 interval ms)新数据
( FileProcessingMode.PROCESS_CONTINUOUSLY )的路径,或者处理当前在路径中的数据并退
出( FileProcessingMode.PROCESS_ONCE )。使用 pathFilter ,用户可以进一步排除正在处
理的文件。
实现:
Flink将文件读取过程分为两个子任务,即目录监控和数据读取。这些子任务中的每一个都由单独
的实体实现。监视由单个非并行(并行性= 1)任务实现,而读取由并行运行的多个任务执行。后
者的并行性等于工作并行性。单个监视任务的作用是扫描目录(定期或仅一次,具体取决于
watchType ),找到要处理的文件,将它们分成分割,并将这些拆分分配给下游读者。读者是那
些将阅读实际数据的人。每个分割仅由一个读取器读取,而读取器可以逐个读取多个分割。
重要笔记:
1. 如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY ,则在修改文件
时,将完全重新处理其内容。这可以打破“完全一次”的语义,因为在文件末尾附加数据将导
致其所有内容被重新处理。
2. 如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE ,则源扫描路径一次并退出,
而不等待读者完成读取文件内容。当然读者将继续阅读,直到读取所有文件内容。在该点之
后关闭源将导致不再有检查点。这可能会导致节点故障后恢复速度变慢,因为作业将从上一
个检查点恢复读取。
基于Socket:
- socketTextStream - 从Socket中读取,元素可以用分隔符分隔。
基于集合:
fromCollection(Collection) - 从Java Java.util.Collection创建数据流。集合中的所有元素必须
属于同一类型。
fromCollection(Iterator, Class) - 从迭代器创建数据流。该类指定迭代器返回的元素的数
据类型。<br />fromElements(T ...) - 从给定的对象序列创建数据流。所有对象必须属于同一类型。
fromParallelCollection(SplittableIterator, Class) - 并行地从迭代器创建数据流。该类
指定迭代器返回的元素的数据类型。
generateSequence(from, to) - 并行生成给定间隔中的数字序列。
自定义:
addSource - 附加新的源功能。例如,要从Apache Kafka读取,可以使用 addSource(new
FlinkKafkaConsumer08<>(...)) 。
3.2 数据流转换
此时再将中间的转换算子
Transformation,即通过从一个或多个 DataStream 生成新的 DataStream 的过程被称为 Transformation 操作。在转换过程中,每种操作类型被定义为不同的 Operator,Flink 程序能够将多个 Transformation 组成一个 DataFlow 的拓扑。
1. Map
DataStream → DataStream
调用用户定义的MapFunction对DataStream[T]数据进行处理,形成新的DataStream[T],其中数
据格式可能会发生变化,常用作对数据集内数据的清洗和转换。
如以下示例:它将输入流的元素数值增加一倍:DataStream<Integer> dataStream = //...dataStream.map(new MapFunction<Integer, Integer>() {@Overridepublic Integer map(Integer value) throws Exception {return 2 * value;}});
2. FlatMap
DataStream → DataStream
主要对输入的元素处理之后生成一个或者多个元素,如下示例:将句子拆分成单词:dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {for(String word: value.split(" ")){out.collect(word);}}});
3. Filter
DataStream → DataStream
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条件的数据过
滤掉。
如下所示:返回不为0的数据dataStream.filter(new FilterFunction<Integer>() {@Overridepublic boolean filter(Integer value) throws Exception {return value != 0;}});
4. KeyBy
DataStream → KeyedStream
该算子根据指定的key将输入的DataStream[T]数据格式转换为KeyedStream[T],也就是在数据集
中执行Partition操作,将相同的key值的数据放置在相同的分区中。简单来说,就是sql里面的
group bydataStream.keyBy("someKey") // Key by field "someKey"dataStream.keyBy(0) // Key by the first element of a Tuple
注意 如果出现以下情况,则类型不能成为Key:
1. 它是POJO类型,但不覆盖hashCode()方法并依赖于Object.hashCode()实现。
2. 它是任何类型的数组。5. Reduce
KeyedStream → DataStream
该算子和MapReduce的Reduce原理基本一致,主要目的是将输入的KeyedStream通过传入的用
户自定义的ReduceFunction滚动的进行数据聚合处理,其中定义的ReduceFunction必须满足运算
结合律和交换律:keyedStream.reduce(new ReduceFunction<Integer>() {@Override public Integer reduce(Integer value1, Integer value2) throws Exception {return value1 + value2;}});
6. Fold
KeyedStream → DataStream
具有初始值的键控数据流上的“滚动”折叠。将当前元素与最后折叠的值组合并发出新值。
折叠函数,当应用于序列(1,2,3,4,5)时,发出序列“start-1”,“start-1-2”,“start-1-2-3”,. ..DataStream<String> result =keyedStream.fold("start", new FoldFunction<Integer, String>() {@Overridepublic String fold(String current, Integer value) {return current + "-" + value;}});
7. Aggregations
KeyedStream → DataStream
Aggregations 是 KeyedDataStream 接口提供的聚合算子,根据指定的字段进行聚合操 作,滚动地产生一系列数据聚合结果。其实是将 Reduce 算子中的函数进行了封装,封装的 聚合操作有 sum、min、minBy、max、maxBy等,这样就不需要用户自己定义 Reduce 函数。
滚动聚合数据流上的聚合。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具
有最小值的元素(max和maxBy相同)。keyedStream.sum(0);keyedStream.sum("key");keyedStream.min(0);keyedStream.min("key");keyedStream.max(0);keyedStream.max("key");keyedStream.minBy(0);keyedStream.minBy("key");keyedStream.maxBy(0);keyedStream.maxBy("key");
8. Window
KeyedStream → WindowedStream
可以在已经分区的KeyedStream上定义时间窗口。
时间窗口根据某些特征(例如,在最后5秒内到达的数据)对每个Key中的数据进行分组。// 最后5秒的数据dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
9. WindowAll
DataStream → AllWindowedStream
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数
据)对所有流事件进行分组。
警告:在许多情况下,这是非并行转换。所有记录将收集在windowAll运算符的一个任务中。// 最后5秒的数据dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
10. Window Apply
WindowedStream → DataStream AllWindowedStream → DataStream
将一般功能应用于整个窗口。下面是一个手动求和窗口元素的函数。
注意:如果正在使用windowAll转换,则需要使用AllWindowFunction。windowedStream.apply (new WindowFunction<Tuple2<String,Integer>, Integer,Tuple, Window>() {public void apply (Tuple tuple,Window window,Iterable<Tuple2<String, Integer>> values,Collector<Integer> out) throws Exception {int sum = 0;for (value t: values) { sum += t.f1; }out.collect (new Integer(sum)); } });// applying an AllWindowFunction on non-keyed window streamallWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>,Integer, Window>() {public void apply (Window window,Iterable<Tuple2<String, Integer>> values,Collector<Integer> out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}});
11. Window Reduce
WindowedStream → DataStream
将减少功能应用于窗口并返回减少的值。windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1,Tuple2<String, Integer> value2) throws Exception {return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);}});
12. Window Fold
WindowedStream → DataStream
将折叠功能应用于窗口并返回折叠值。
示例函数应用于序列(1,2,3,4,5)时,将序列折叠为字符串“start-1-2-3-4-5”:windowedStream.fold("start", new FoldFunction<Integer, String>() {public String fold(String current, Integer value) {return current + "-" + value;}});
13. Windows上的聚合
WindowedStream → DataStream
聚合窗口的内容。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值
的元素(max和maxBy相同)。windowedStream.sum(0);windowedStream.sum("key");windowedStream.min(0);windowedStream.min("key");windowedStream.max(0);windowedStream.max("key");windowedStream.minBy(0);windowedStream.minBy("key");windowedStream.maxBy(0);windowedStream.maxBy("key");
14. Union
DataStream → DataStream
将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据集的格式一致,输出的数据集
的格式和输入的数据集格式保持一致
注意:如果将数据流与其自身联合,则会在结果流中获取两次元素。dataStream.union(otherStream1, otherStream2, ...);
15. Window Join
DataStream,DataStream → DataStream
根据主键和公共时间窗口,连接数据流dataStream.join(otherStream).where(<keyselector>).equalTo(<key selector>).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (new JoinFunction () {...});
16. Interval Join
KeyedStream,KeyedStream → DataStream
在给定的时间间隔内使用公共Key连接两个键控流的两个元素e1和e2,以便e1.timestamp +
lowerBound <= e2.timestamp <= e1.timestamp + upperBound// this will join the two streams so that// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2keyedStream.intervalJoin(otherKeyedStream).between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper bound.upperBoundExclusive(true) // optional.lowerBoundExclusive(true) // optional.process(new IntervalJoinFunction() {...});
17. Window CoGroup
DataStream,DataStream → DataStream
在给定Key和公共时间窗口上对两个数据流进行coGroup操作。dataStream.coGroup(otherStream).where(0).equalTo(1).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (new CoGroupFunction () {...});
18. Connect
DataStream,DataStream → ConnectedStreams
Connect算子主要是为了合并两种或者多种不同数据类型的数据集,合并后会保留原来的数据集的
数据类型。连接操作允许共享状态数据,也就是说在多个数据集之间可以操作和查看对方数据集的
状态。
注意:Union 之前两个流的类型
必须是一样,Connect可以不一样,在之后的 coMap 中再去调 整成为一样的。- Connect
只能操作两个流,Union可以操作多个。 ```java DataStreamsomeStream = //… DataStream otherStream = //…
ConnectedStreams
<a name="xy5VJ"></a>### 19. CoMap,CoFlatMapConnectedStreams → DataStream<br />类似于连接数据流上的map和flflatMap。**```javaconnectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {@Overridepublic Boolean map1(Integer value) {return true;}@Override public Boolean map2(String value) {return false;}});connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {@Overridepublic void flatMap1(Integer value, Collector<String> out) {out.collect(value.toString());}@Overridepublic void flatMap2(String value, Collector<String> out) {for (String word: value.split(" ")) {out.collect(word);}}});
20. Split
DataStream → SplitStream
Split 算子是将一个 DataStream 数据集按照条件进行拆分,形成两个数据集的过程, 也是 union 算子的逆向实现。每个接入的数据都会被路由到一个或者多个输出数据集中。
SplitStream<Integer> split = someDataStream.split(newOutputSelector<Integer>() {@Overridepublic Iterable<String> select(Integer value) {List<String> output = new ArrayList<String>();if (value % 2 == 0) {output.add("even");}else {output.add("odd");}return output;}});
21. Select
SplitStream → DataStream
从拆分流中选择一个或多个流。
SplitStream<Integer> split;DataStream<Integer> even = split.select("even");DataStream<Integer> odd = split.select("odd");DataStream<Integer> all = split.select("even","odd");
22. Iterate
DataStream → IterativeStream → DataStream
通过将一个运算符的输出重定向到某个先前的运算符,在流中创建“反馈”循环。这对于定义不断更
新模型的算法特别有用。以下代码以流开头并连续应用迭代体。大于0的元素将被发送回反馈通
道,其余元素将向下游转发。
IterativeStream<Long> iteration = initialStream.iterate();DataStream<Long> iterationBody = iteration.map (/*do something*/);DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){@Overridepublic boolean filter(Long value) throws Exception {return value > 0;}});iteration.closeWith(feedback);DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){@Override public boolean filter(Long value) throws Exception {return value <= 0;}});
23. 提取时间戳
DataStream → DataStream
从记录中提取时间戳,以便使用事件时间语义的窗口。
stream.assignTimestamps (new TimeStampExtractor() {...});
24. 元组数据流转换 Project
DataStream→DataStream
从元组中选择字段的子集
DataStream<Tuple3<Integer, Double, String>> in = // [...]DataStream<Tuple2<String, Integer>> out = in.project(2,0);
3.3 输出流
数据接收器使用DataStream并将它们转发到文件,套接字,外部系统或打印它们。Flink带有各种内置
输出格式,这些格式封装在DataStreams上的操作后面:
- writeAsText() / TextOutputFormat - 按字符串顺序写入元素。通过调用每个元素的
toString()方法获得字符串。
writeAsCsv(…) / CsvOutputFormat- 将元组写为逗号分隔值文件。行和字段分隔符是可配置
的。每个字段的值来自对象的_toString_()方法。
print() / printToErr() - 在标准输出/标准错误流上打印每个元素的toString()值。可选地,
可以提供前缀(msg),其前缀为输出。这有助于区分不同的打印调用。如果并行度大于1,则输<br /> 出也将以生成输出的任务的标识符为前缀。
writeUsingOutputFormat() / FileOutputFormat - 自定义文件输出的方法和基类。支持自定义
对象到字节的转换。
writeToSocket - 根据a将元素写入套接字 SerializationSchema
addSink - 调用自定义接收器功能。Flink捆绑了其他系统(如Apache Kafka)的连接器,这些系
统实现为接收器功能。<br />请注意, write*()方法 DataStream 主要用于调试目的。他们没有参与Flink的检查点,这意味着这些<br />函数通常具有至少一次的语义。刷新到目标系统的数据取决于OutputFormat的实现。这意味着并非所<br />有发送到OutputFormat的元素都会立即显示在目标系统中。此外,在失败的情况下,这些记录可能会<br />丢失。<br />为了可靠,准确地将流传送到文件系统,请使用 flink-connector-filesystem 。此外,通过<br />该 .addSink(...) 方法的自定义实现可以参与Flink的精确一次语义检查点。
4 Flink DataSet编程
Flink中的DataSet程序是实现数据集转换的常规程序(例如,过滤,映射,连接,分组)。数据集最初
是从某些来源创建的(例如,通过读取文件或从本地集合创建)。结果通过接收器返回,接收器可以例
如将数据写入(分布式)文件或标准输出(例如命令行终端)。Flink程序可以在各种环境中运行,独立
运行或嵌入其他程序中。执行可以在本地JVM中执行,也可以在许多计算机的集群上执行。
4.1 DataSet示例
通过maven命令创建Flink工程:
mvn archetype:generate-DarchetypeGroupId=org.apache.flink-DarchetypeArtifactId=flink-quickstart-java-DarchetypeVersion=1.11.0
这里以单词统计程序为例,演示Flink DataSet程序的开发过程:
public class WordCountExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();DataSet<String> text = env.fromElements("Who's there?","I think I hear them. Stand, ho! Who's there?");DataSet<Tuple2<String, Integer>> wordCounts = text.flatMap(new LineSplitter()).groupBy(0).sum(1);wordCounts.print();}public static class LineSplitter implements FlatMapFunction<String,Tuple2<String, Integer>> {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) {for (String word : line.split(" ")) {out.collect(new Tuple2<String, Integer>(word, 1));}}}}
4.2 输入源
数据源创建初始数据集,例如来自文件或Java集合。创建数据集的一般机制是在InputFormat后面抽象
的 。Flink附带了几种内置格式,可以从通用文件格式创建数据集。其中许多都在ExecutionEnvironment
上有快捷方法。
基于文件:
- readTextFile(path)/ TextInputFormat- 按行读取文件并将其作为字符串返回。
readTextFileWithValue(path)/ TextValueInputFormat- 按行读取文件并将它们作为StringValues
返回。StringValues是可变字符串。
readCsvFile(path)/ CsvInputFormat- 解析逗号(或其他字符)分隔字段的文件。返回元组或
POJO的DataSet。支持基本的java类型及其Value对应的字段类型。
readFileOfPrimitives(path, Class)/ PrimitiveInputFormat- 解析新行(或其他字符序列)分隔的
原始数据类型(如String或)的文件Integer。
readFileOfPrimitives(path, delimiter, Class)/ PrimitiveInputFormat- 解析新行(或其他字符序
列)分隔的原始数据类型的文件,例如String或Integer使用给定的分隔符。<br />**基于集合**:
fromCollection(Collection) - 从Java.util.Collection创建数据集。集合中的所有元素必须属于同一类型。
- fromCollection(Iterator, Class) - 从迭代器创建数据集。该类指定迭代器返回的元素的数据类型。
- fromElements(T …) - 根据给定的对象序列创建数据集。所有对象必须属于同一类型。
- fromParallelCollection(SplittableIterator, Class) - 并行地从迭代器创建数据集。该类指定迭代器返回的元素的数据类型。
- generateSequence(from, to) - 并行生成给定间隔中的数字序列。
通用:
- readFile(inputFormat, path) / FileInputFormat - 接受文件输入格式。
- createInput(inputFormat) / InputFormat - 接受通用输入格式。
例子:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 根据给定的元素创建一个DataSetDataSet<String> value = env.fromElements("Foo", "bar", "foobar", "fubar");// 生成一个数字型序列号 DataSet<Long> numbers = env.generateSequence(1, 10000000);// 从CSV文件中读取三个字段DataSet<Tuple3<Integer, String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file").types(Integer.class, String.class, Double.class);// 读取CSV文件中的三个字段,并初始化赋值Person对象 DataSet<Person>> csvInput = env.readCsvFile("hdfs:///the/CSV/file").pojoType(Person.class, "name", "age", "zipcode");// 从本地系统中读取文本文件 DataSet<String> localLines = env.readTextFile("file:///path/to/my/textfile");// 从HDFS中读取文件 DataSet<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");// 从HDFS的CSV文件中读取5个字段,使用其中的两个DataSet<Tuple2<String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file").includeFields("10010") // 使用第一个和第四个.types(String.class, Double.class);// 顺序读取HDFS文件中的字段 DataSet<Tuple2<IntWritable, Text>> tuples = env.createInput(HadoopInputs.readSequenceFile(IntWritable.class, Text.class, "hdfs://nnHost:nnPort/path/to/file"));// 通过JDBC读取关系型数据库 DataSet<Tuple2<String, Integer> dbData =env.createInput(JDBCInputFormat.buildJDBCInputFormat().setDrivername("org.apache.derby.jdbc.EmbeddedDriver").setDBUrl("jdbc:derby:memory:persons").setQuery("select name, age from persons").setRowTypeInfo(new RowTypeInfo(BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.INT_TYPE_INFO)).finish());// 注意:// Flink的程序编译器需要推断由InputFormat返回的数据项的数据类型,// 如果此信息无法自动推断,则需要手动提供类型信息。
4.3 转换操作
数据转换将一个或多个DataSet转换为新的DataSet。程序可以将多个转换组合成复杂的程序集。
1. Map
采用一个元素并生成一个元素。
data.map(new MapFunction<String, Integer>() {public Integer map(String value) { return Integer.parseInt(value); }});
2. FlatMap
采用一个元素并生成零个,一个或多个元素。
data.flatMap(new FlatMapFunction<String, String>() {public void flatMap(String value, Collector<String> out) {for (String s : value.split(" ")) {out.collect(s);}}});
3. MapPartition
在单个函数调用中转换并行分区。该函数将分区作为 Iterable 流来获取,并且可以生成任意数量
的结果值。每个分区中的元素数量取决于并行度和先前的操作。
data.mapPartition(new MapPartitionFunction<String, Long>() {public void mapPartition(Iterable<String> values, Collector<Long> out) {long c = 0; for (String s : values) {c++;}out.collect(c);}});
4. Filter
计算每个元素的布尔函数,并保留函数返回true的元素。 重要信息:系统假定该函数不会修改元
素,否则可能会导致错误的结果。
data.filter(new FilterFunction<Integer>() {public boolean filter(Integer value) {return value > 1000;}});
5. Reduce
通过将两个元素重复组合成一个元素,将一组元素组合成一个元素。Reduce可以应用于完整数据
集或分组数据集。
data.reduce(new ReduceFunction<Integer> {public Integer reduce(Integer a, Integer b) {return a + b;}});
如果将reduce应用于分组数据集,则可以通过提供 CombineHintto 来指定运行时执行reduce的
组合阶段的方式 setCombineHint 。在大多数情况下,基于散列的策略应该更快,特别是如果不
同键的数量与输入元素的数量相比较小(例如1/10)。
6. ReduceGroup
将一组元素组合成一个或多个元素。ReduceGroup可以应用于完整数据集或分组数据集。
data.reduceGroup(new GroupReduceFunction<Integer, Integer> {public void reduce(Iterable<Integer> values, Collector<Integer> out) {int prefixSum = 0; for (Integer i : values) {prefixSum += i; out.collect(prefixSum);}}});
7. Aggregate
将一组值聚合为单个值。聚合函数可以被认为是内置的reduce函数。聚合可以应用于完整数据集
或分组数据集。
Dataset<Tuple3<Integer, String, Double>> input = // [...]DataSet<Tuple3<Integer, String, Double>> output = input.aggregate(SUM, 0).and(MIN, 2);
还可以使用简写语法进行最小,最大和总和聚合。
Dataset<Tuple3<Integer, String, Double>> input = // [...]DataSet<Tuple3<Integer, String, Double>> output = input.sum(0).andMin(2);
8. Distinct
返回数据集的不同元素。它相对于元素的所有字段或字段子集从输入DataSet中删除重复条目。
data.distinct();
使用reduce函数实现Distinct。可以通过提供 CombineHint to 来指定运行时执行reduce的组合
阶段的方式 setCombineHint 。在大多数情况下,基于散列的策略应该更快,特别是如果不同键
的数量与输入元素的数量相比较小(例如1/10)。
9. Join
通过创建在其Key上相等的所有元素对来连接两个数据集。可选地使用JoinFunction将元素对转换
为单个元素,或使用FlatJoinFunction将元素对转换为任意多个(包括无)元素。
result = input1.join(input2).where(0) // key of the first input (tuple field 0).equalTo(1); // key of the second input (tuple field 1)
可以通过 Join Hints 指定运行时执行连接的方式。提示描述了通过分区或广播进行连接,以及它
是使用基于排序还是基于散列的算法。
如果未指定提示,系统将尝试估算输入大小,并根据这些估计选择最佳策略。
// This executes a join by broadcasting the first data set// using a hash table for the broadcast dataresult = input1.join(input2, JoinHint.BROADCAST_HASH_FIRST).where(0).equalTo(1);
请注意,连接转换仅适用于等连接。其他连接类型需要使用OuterJoin或CoGroup表示。
10. OuterJoin
在两个数据集上执行左,右或全外连接。外连接类似于常规(内部)连接,并创建在其键上相等的
所有元素对。
input1.leftOuterJoin(input2) // rightOuterJoin or fullOuterJoin for right orfull outer joins.where(0) // key of the first input (tuple field 0).equalTo(1) // key of the second input (tuple field 1).with(new JoinFunction<String, String, String>() {public String join(String v1, String v2) {// NOTE:// - v2 might be null for leftOuterJoin// - v1 might be null for rightOuterJoin// - v1 OR v2 might be null for fullOuterJoin}});
11. CoGroup
reduce操作的二维变体。将一个或多个字段上的每个输入分组,然后加入组。每对组调用转换函
数。
data1.coGroup(data2).where(0).equalTo(1).with(new CoGroupFunction<String, String, String>() {public void coGroup(Iterable<String> in1, Iterable<String> in2,Collector<String> out) {out.collect(...);}});
12. Cross
构建两个输入的笛卡尔积(交叉乘积),创建所有元素对。可选择使用CrossFunction将元素对转
换为单个元素
DataSet<Integer> data1 = // [...]DataSet<String> data2 = // [...]DataSet<Tuple2<Integer, String>> result = data1.cross(data2);
13. Union
生成两个数据集的并集。
DataSet<String> data1 = // [...]DataSet<String> data2 = // [...]DataSet<String> result = data1.union(data2);
14. Rebalance
均匀地重新平衡数据集的并行分区以消除数据偏差。只有类似Map的转换可能会使用重新平衡转
换。
DataSet<String> in = // [...]DataSet<String> result = in.rebalance() .map(new Mapper());
15. Hash-Partition
散列分区给定键上的数据集。键可以指定为位置键,表达键和键选择器功能。
DataSet<Tuple2<String,Integer>> in = // [...]DataSet<Integer> result = in.partitionByHash(0).mapPartition(new PartitionMapper());
16. Range-Partition
范围分区给定键上的数据集。键可以指定为位置键,表达键和键选择器功能。
DataSet<Tuple2<String,Integer>> in = // [...]DataSet<Integer> result = in.partitionByRange(0).mapPartition(new PartitionMapper());
17. 自定义分区
使用自定义分区程序功能基于特定分区的键分配记录。密钥可以指定为位置键,表达式键和键选择
器功能。 注意:此方法仅适用于单个字段键。
DataSet<Tuple2<String,Integer>> in = // [...]DataSet<Integer> result = in.partitionCustom(partitioner, key).mapPartition(new PartitionMapper());
18. 排序分区
本地按指定顺序对指定字段上的数据集的所有分区进行排序。可以将字段指定为元组位置或字段表
达式。通过链接sortPartition()调用来完成对多个字段的排序。
DataSet<Tuple2<String,Integer>> in = // [...]DataSet<Integer> result = in.sortPartition(1, Order.ASCENDING).mapPartition(new PartitionMapper());
4.4 输出源
数据接收器(sink)使用DataSet并用于存储或返回它们。使用OutputFormat描述数据接收器操作 。
Flink带有各种内置输出格式,这些格式封装在DataSet上的操作后面:
- writeAsText() / TextOutputFormat - 按字符串顺序写入元素。通过调用每个元素的
toString()方法获得字符串。
- writeAsFormattedText() / TextOutputFormat - 按字符串顺序编写元素。通过为每个元素调用
用户定义的format()方法来获取字符串。
- writeAsCsv(…) / CsvOutputFormat - 将元组写为逗号分隔值文件。行和字段分隔符是可配置
的。每个字段的值来自对象的toString()方法。
- print() / printToErr() / print(String msg) / printToErr(String msg) - 在标准输出/标准错误流上打印每个元素的toString()值。可选地,可以提供前缀(msg),其前缀为输出。这有助于区分不同的打印调用。如果并行度大于1,则输出也将以生成输出的任务的标识符为前缀。
- write() / FileOutputFormat - 自定义文件输出的方法和基类。支持自定义对象到字节的转换。
- output() / OutputFormat - 大多数通用输出方法,用于非基于文件的数据接收器(例如将结果存储在数据库中)。
可以将DataSet输入到多个操作。程序可以编写或打印数据集,同时对它们执行其他转换。
例子
标准数据接收方法:
// 文本类型的数据集DataSet<String> textData = // [...]// 将数据集保存到本地文件textData.writeAsText("file:///my/result/on/localFS");// 将数据集保存到HDFS系统中textData.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFS");// 将数据集保存成文件,如果该文件存在,则覆盖该文件 textData.writeAsText("file:///my/result/on/localFS", WriteMode.OVERWRITE);// 将数据集保存到本地csv文件,数据集各字段用|分割DataSet<Tuple3<String, Integer, Double>> values = // [...] values.writeAsCsv("file:///path/to/the/result/file", "\n", "|");// 按照用户自定义的形式将字符型数据集保存到文本文件 values.writeAsFormattedText("file:///path/to/the/result/file",new TextFormatter<Tuple2<Integer, Integer>>() {public String format (Tuple2<Integer, Integer> value) {return value.f1 + " - " + value.f0;}});
使用自定义输出格式:
DataSet<Tuple3<String, Integer, Double>> myResult = [...]// 将Tuple类型的数据集保存到关系型数据库中myResult.output(// 创建JDBC配置JDBCOutputFormat.buildJDBCOutputFormat().setDrivername("org.apache.derby.jdbc.EmbeddedDriver").setDBUrl("jdbc:derby:memory:persons").setQuery("insert into persons (name, age, height) values (?,?,?)").finish());
5 Flink Table API和SQL编程
Flink针对标准的流处理和批处理提供了两种相关的API,Table API和sql。Table API允许用户以一种很
直观的方式进行select 、fifilter和join操作。Flink SQL支持基于 Apache Calcite实现的标准SQL。针对批
处理和流处理可以提供相同的处理语义和结果。Flink Table API、SQL接口和Flink的DataStream API、
DataSet API是紧密联系在一起的。
架构原理: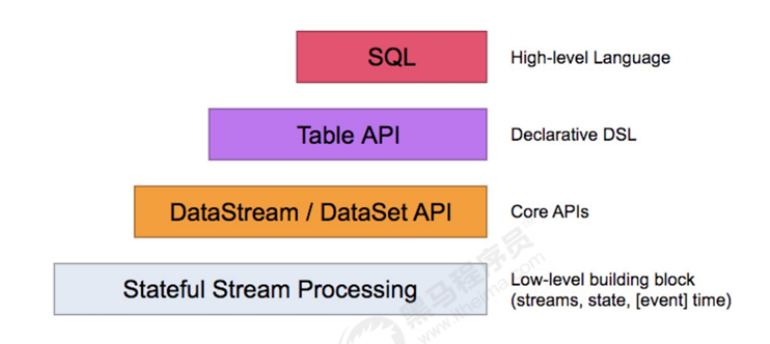
添加依赖:
<properties><scala.binary.version>2.11</scala.binary.version><!-- 其他依赖包的版本... --></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_${scala.binary.version} </artifactId> <version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_${scala.binary.version}</artifactId> <version>${flink.version}</version></dependency><!-- 其他依赖包 --></dependencies>
TableEnvironment 是 Table API 和SQL集成的核心概念,它负责:
- 在内部目录中注册表
- 注册外部目录
- 执行SQL查询
- 注册用户定义的函数
- DataStream 或 DataSet 转换为 Table
持有 BatchExecutionEnvironment 或 StreamExecutionEnvironment 的引用
5.1 程序示例
5.2 TableEnvironment
TableEnvironment是Table API和SQL集成的核心概念,是用来创建 Table API 和 SQL 程序的上下文执
行环境 ,也是 Table & SQL 程序的入口,Table & SQL 程序的所有功能都是围绕 TableEnvironment 这
个核心类展开的。它负责:在内部目录中注册表
- 注册外部目录
- 执行SQL查询
- 注册用户定义的(指标,表或聚合)函数
- 转换: DataStream 或 DataSet 转换为 Table
- 持有对 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
在 Flink 1.8 中,一共有 7 个 TableEnvironment ,在最新的 Flink 1.9 中,社区进行了重构和优化,只
保留了 5 个TableEnvironment 。在实现上是 5 个面向用户的接口,在接口底层进行了不同的实现。5
个接口包括一个 TableEnvironment 接口,两个 BatchTableEnvironment 接口,两个
StreamTableEnvironment 接口,5 个接口文件完整路径如下:
- org/apache/flflink/table/api/TableEnvironment.java
- org/apache/flflink/table/api/java/BatchTableEnvironment.java
- org/apache/flflink/table/api/scala/BatchTableEnvironment.scala
- org/apache/flflink/table/api/java/StreamTableEnvironment.java
- org/apache/flflink/table/api/scala/StreamTableEnvironment.scala
其中TableEnvironment 是顶级接口,是所有 TableEnvironment 的基类 ,BatchTableEnvironment 和
StreamTableEnvironment 都提供了 Java 实现和 Scala 实现 ,分别有两个接口。
另一方面,TableEnvironment 作为统一的接口,其统一性体现在两个方面,一是对于所有基于JVM的
语言(即 Scala API 和 Java API 之间没有区别)是统一的;二是对于 unbounded data (无界数据,即流
数据) 和 bounded data (有界数据,即批数据)的处理是统一的。TableEnvironment 提供的是一个
纯 Table 生态的上下文环境,适用于整个作业都使用 Table API & SQL 编写程序的场景。
- 两个 StreamTableEnvironment 分别用于 Java 的流计算和 Scala 的流计算场景,流计算的对象分别是 Java 的 DataStream 和 Scala 的 DataStream。相比 TableEnvironment, StreamTableEnvironment 提供了 DataStream 和 Table 之间相互转换的接口,如果用户的程序除了使用 Table API & SQL 编写外,还需要使用到 DataStream API,则需要使用StreamTableEnvironment。
- 两个 BatchTableEnvironment 分别用于 Java 的批处理场景和 Scala 的批处理场景,批处理的对象分别是 Java 的 DataSet 和 Scala 的 DataSet。相比 TableEnvironment,BatchTableEnvironment 提供了 DataSet 和 Table 之间相互转换的接口,如果用户的程序除了使用 Table API & SQL 编写外,还需要使用到 DataSet API,则需要使用 BatchTableEnvironment。 ```java // 流处理 import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.java.StreamTableEnvironment;
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建流查询的TableEnvironment StreamTableEnvironment sTableEnv = StreamTableEnvironment.create(sEnv);
// 批处理 import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.table.api.java.BatchTableEnvironment;
ExecutionEnvironment bEnv = ExecutionEnvironment.getExecutionEnvironment(); // 创建批查询的TableEnvironment BatchTableEnvironment bTableEnv = BatchTableEnvironment.create(bEnv);
<a name="8ZJTv"></a>## 5.3 在表空间中注册表TableEnvironment 是维护按名称注册的表的目录。有两种类型的表,输入表和输出表。输入表可以在<br />表API和SQL查询中引用,并提供输入参数。输出表可用于将Table API或SQL查询的结果发送到外部系<br />统。<br />1. 可以从各种来源注册输入表:- Table API或SQL查询的结果转换成 Table 对象。- TableSource ,访问外部数据,例如文件,数据库或消息中间件。- DataStream或DataSet程序创建的 DataStream 或 DataSet 。2. 可以使用 TableSink 注册输出表。<a name="66sCg"></a>### 5.3.1 注册表```java//获得StreamTableEnvironment(BatchTableEnvironment的用法类似)StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//从表空间中查找表,并执行select操作Table projTable = tableEnv.scan("tableName").select(...);// 用一个表注册成另外一个表tableEnv.registerTable("projectedTable", projTable);
5.3.2 注册TableSource
TableSource 提供对外部数据的访问,存储在存储系统中,例如数据库(MySQL,HBase,…),具
有特定编码的文件(CSV,Apache [Parquet,Avro,ORC] ……)或消息系统(Apache Kafka,
RabbitMQ,……)。
// 创建StreamTableEnvironment(BatchTableEnvironment类似)StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 创建TableSourceTableSource csvSource = new CsvTableSource("/path/to/file", ...);// 将TableSource注册成表:CsvTabletableEnv.registerTableSource("CsvTable", csvSource);
5.3.3 注册TableSink
已注册 TableSink 可用于将表API或SQL查询的结果发送到外部存储系统,例如数据库,键值存储,消
息队列或文件系统(在不同的编码中,例如,CSV,Apache [Parquet] ,Avro,ORC],……)。
// 创建StreamTableEnvironment(BatchTableEnvironment类似)StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 创建TableSinkTableSink csvSink = new CsvTableSink("/path/to/file", ...);// 定义字段名称和类型String[] fieldNames = {"a", "b", "c"};TypeInformation[] fieldTypes = {Types.INT, Types.STRING, Types.LONG};// 将TableSink注册成表:CsvSinkTabletableEnv.registerTableSink("CsvSinkTable", fieldNames, fieldTypes, csvSink);
5.4 Table执行过程分析
Flink Table API&SQL 利用了Apache Calcite的查询优化框架,为流式数据和批数据的关系查询保留统一
的接口。使用Calcite作为SQL解析与处理引擎有Hive、Drill、Flink、Phoenix和Storm等平台。
5.4.1 Flink Sql 执行流程
一条stream sql从提交到calcite解析、优化最后到flflink引擎执行,一般分为以下几个阶段:
1. Sql Parser: 将sql语句通过java cc解析成AST(语法树),在calcite中用SqlNode表示AST;
2. Sql Validator: 结合数字字典去验证sql语法;
3. 生成Logical Plan: 将sqlNode表示的AST转换成LogicalPlan, 用relNode表示;
4. 生成 optimized Logical Plan: 先基于calcite rules 去优化logical Plan, 再基于flflink定制的一些优
化rules去优化logical Plan;
5. 生成Flink Physica lPlan: 这里也是基于flflink里头的rules,将optimized LogicalPlan转成成Flink
的物理执行计划;
6. 将物理执行计划转成Flink Execution Plan: 就是调用相应的tanslateToPlan方法转换和利用
CodeGen元编程成Flink的各种算子
5.5 执行计划
Flink会根据客户端提交程序的一些参数,以及集群中机器(TaskManager)的数量去自动优化选取一
个它认为合适的执行策略(使数据在DAG中流动计算);了解flflink为job选取的执行计划对我们理解
flflink是如何执行客户端任务是非常有帮助的。
flflink提供了最少两种执行计划的可视化的方式,方便我们了解自己编码客户端的执行计划,从而针对性
的进行调试
- 提交Flink工程,在管理页面上查看执行计划
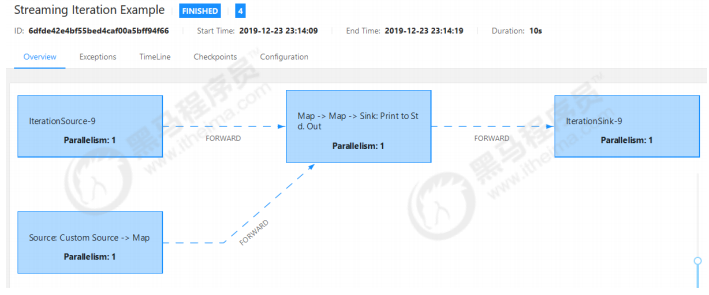
- Plan Visualization Tool
- 通过flflink上下文环境的getExecutionPlan()API输出一段描述执行计划的JSON数据
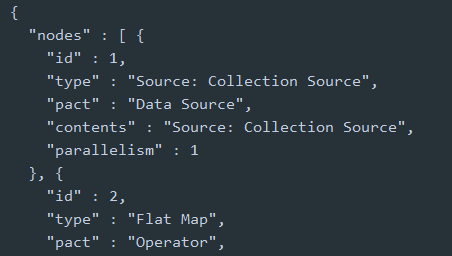
- 将输出的信息贴到flflink提供的在线可视化工具(https://flflink.apache.org/visualizer)
- 点击Draw效果如下:
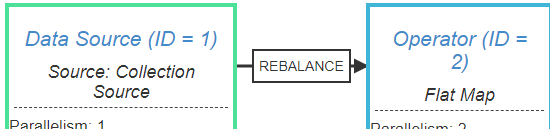
5.6 流和批与Table集成编程
表API和SQL查询可以轻松集成并嵌入到DataStream和DataSet程序中。例如,可以查询外部表(例如
来自RDBMS),进行一些预处理,例如过滤,投影,聚合或与元数据连接,然后使用DataStream或
DataSet API进一步处理数据。 相反,Table API或SQL查询也可以应用于DataStream或DataSet程序的
结果。
这种相互作用可以通过转换 DataStream 或 DataSet 转换来实现, Table 反之亦然。
6. 总结
目前,官网社区说到:正在推进 DataStream 的批处理能力,以实现流批技术栈的统一,届时 DataSet API 会退出历史的舞台,两个 BatchTableEnvironment 也将退出历史的舞台。同时社区也在努力推动 Java 和 Scala TableEnvironment 的统一。可以预见的是,Flink TableEnvironment 的未来架构会更加简洁。TableEnvironment 会是 Flink 推荐使用的入口类,同时能支持 Java API 和 Scala API,还能同时支持流计算作业和批处理作业。只有当需要与 DataStream 做转换时,才需要用到 StreamTableEnvironment。
在Flink 1.11中,BatchTableEnvironment已经没有实现类,如果继续使用则会报class not found,建议使用TableEnvironment。
大概率是DataStream会是以后的主流,流批处理一体,DataSet渐渐的已经减少内容了。

若有收获,就点个赞吧
0 人点赞
