1 Flink概述
1.1 数据流与流计算
数据流是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的
另一端看到的是一股连续不断的水流。类似于人们对河流的理解本质上也就是流的概念,但是这条河没
有开始也没有结束,数据流非常适合于离散的、没有开头或结尾的数据。例如,交通信号灯的数据是连
续的,没有“开始”或“结束”,是连续的过程而不是分批发送的数据记录。通常情况下,数据流对于在生
成连续数据流中以小尺寸(通常以KB字节为单位)发送数据的数据源类型是有用的。这包括各种各样的
数据源,例如来自连接设备的遥测,客户访问的Web应用时生成的日志文件、电子商务交易或来自社交
网络或地理LBS服务的信息等。
传统上,数据是分批移动的,批处理通常同时处理大量数据,具有较长时间的延迟。例如,该复制过程
每24小时运行一次。虽然这可以是处理大量数据的有效方法,但它不适用于流式传输的数据,因为数据
在处理时已经是旧的内容。
采用数据流是时间序列和随时间检测模式的最佳选择。例如,跟踪Web会话的时间。大多数物联网产生
的数据非常适合数据流处理,包括交通传感器,健康传感器,交易日志和活动日志等都是数据流的理想
选择。
流数据通常用于实时聚合和关联、过滤或采样。通过数据流,我们可以实时分析数据,并深入了解各种
行为,例如统计,服务器活动,设备地理位置或网站点击量等。
无界数据流
顾名思义,无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理。
有界数据流
相对而言,有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理。
数据流整合技术的解决方案
金融机构跟踪市场变化,并可根据配置约束(例如达到特定股票价格时出售)调整客户组合的配
置。
电网监控吞吐量并在达到某些阈值时生成警报。
新闻资讯APP从各种平台进行流式传输时,产生的点击记录,实时统计信息数据,以便它可以提供
与受众人口相关的文章推荐。
电子商务站点以数据流传输点击记录,可以检查数据流中的异常行为,并在点击流显示异常行为时
发出安全警报。
数据流带给我们的挑战
数据流是一种功能强大的工具,但在使用流数据源时,有一些常见的挑战。以下的列表显示了要规划数
据流的一些事项:可扩展性规划
- 数据持久性规划
-
数据流的管理工具
随着数据流的不断增长,出现了许多合适的大数据流解决方案。我们总结了一个列表,这些都是用于处
理流数据的常用工具: Apache Kafka
Apache Kafka是一个分布式发布/订阅消息传递系统,它集成了应用程序和数据流处理。
- Apache Storm
Apache Storm是一个分布式实时计算系统。Storm用于分布式机器学习、实时分析处理,尤其是其具
有超高数据处理的能力。
- Apache Flink
Apache Flink是一种数据流引擎,为数据流上的分布式计算提供了诸多便利。
1.2 Flink简介
Apache Flink 是一个开源的分布式流式处理框架,是新的流数据计算引擎,用java实现。Flink可以:
- 提供准确的结果,甚至在出现无序或者延迟加载的数据的情况下。
- 它是状态化的容错的,同时在维护一次完整的的应用状态时,能无缝修复错误。
- 大规模运行,在上千个节点运行时有很好的吞吐量和低延迟。
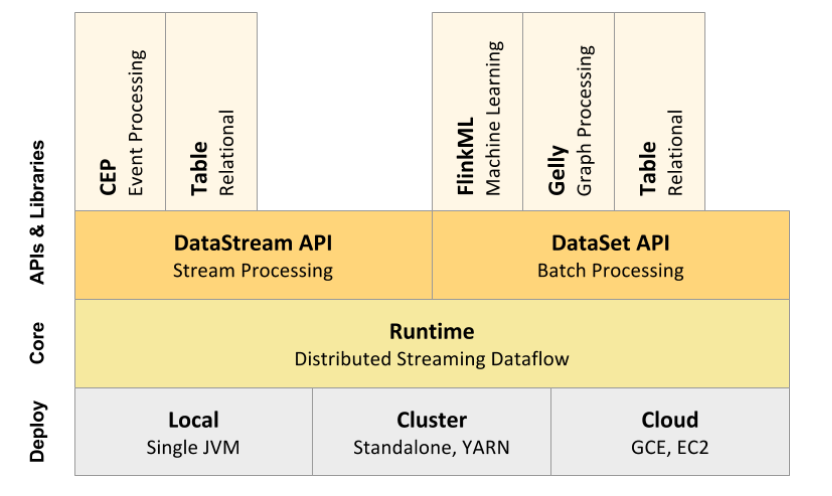
1.3 应用场景
Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:
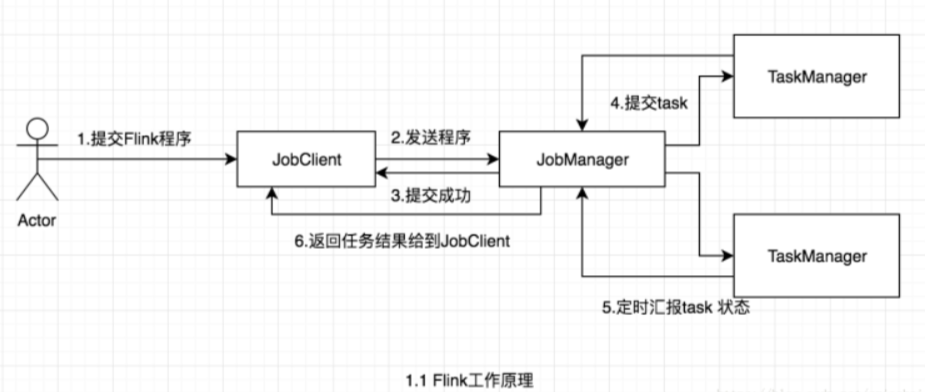
作业提交流程如下:
Program Code:我们编写的 Flink 应用程序代码。
Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责
接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完<br /> 成后,Job Client 将结果返回给用户。
Job Manager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任
务,管理checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,<br /> 协调 checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是<br /> standby; Job Manager 包含 Actor system、Scheduler、Check pointing 三个重要的组件。
Task Manager:从 Job Manager 处接收需要部署的 Task。Task Manager 是在 JVM 中的一个或
多个线程中执行任务的工作节点。 任务执行的并行性由每个 Task Manager 上可用的任务槽决<br /> 定。 每个任务代表分配给任务槽的一组资源。 例如,如果 Task Manager 有四个插槽,那么它将<br /> 为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相<br /> 同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可<br /> 用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink<br /> 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可<br /> 以有更好的资源利用率。
1.5 安装配置
Flink的运行一般分为三种模式,即local、Standalone、On Yarn。
下载程序
``` [root@node2-vm06 opt]# cd /opt [root@node2-vm06 opt]# wget -c http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.1/flink-1.9.1-bin- scala_2.12.tgz
[root@node2-vm06 opt]# tar xzf flink-1.9.1-bin-scala_2.12.tgz
<a name="ekXXR"></a>#### 1. Local模式Local模式比较简单,用于本地测试,安装过程也比较简单,只需在主节点上解压安装包就代表成功安<br />装了,在flflink安装目录下使用./bin/start-cluster.sh(windows环境下是.bat)命令,就可以通过<br />master:8081监控集群状态,关闭集群命令:./bin/stop-cluster.sh(windows环境下是.bat)。<a name="yKk14"></a>#### 2. Standalone模式Standalone模式顾名思义,是在本地集群上调度执行,不依赖于外部调度机制例如YARN。此时需要对<br />配置文件进行一些简单的修改,我们预计使用当前服务器充当Job manager和Task Manager,一般情<br />况下需要多台机器。<br />在安装Flink之前,需要对安装环境进行检查,对于Standalone模式,需要提前安装好zookeeper。<br />1) 修改环境变量,vim /etc/profifile,添加以下内容
export FLINK_HOME=/opt/flink-1.9.1/ export PATH=$FLINK_HOME/bin:$PATH
2) 更改配置文件flflink-conf.yaml,<br />cd /opt/flflink-1.9.1/conf<br />vim flflink-conf.yaml
主要更改的位置有:
jobmanager.rpc.address: 172.17.0.143 taskmanager.numberOfTaskSlots: 2 parallelism.default: 4
取消下面两行的注释
rest.port: 8081 rest.address: 0.0.0.0
上述我们只列出了一些常用需要修改的文件内容,下面我们再简单介绍一些
jobManager 的IP地址
jobmanager.rpc.address: 172.17.0.143
JobManager 的端口号
jobmanager.rpc.port: 6123
JobManager JVM heap 内存大小
jobmanager.heap.size: 1024m
TaskManager JVM heap 内存大小
taskmanager.heap.size: 1024m
每个 TaskManager 提供的任务 slots 数量大小,默认为1
taskmanager.numberOfTaskSlots: 2
程序默认并行计算的个数,默认为1
parallelism.default: 4
2) 配置masters文件<br />该文件用于指定主节点及其web访问端口,表示集群的Jobmanager,vim masters,添加<br />**localhost:8081**<br />3) 配置slaves文件,该文件用于指定从节点,表示集群的taskManager。添加以下内容
localhost localhost localhost
4) 启动flflink集群 (因为在环境变量中已经指定了flflink的bin位置,因此可以直接输入start-cluster.sh)<br />5) 验证flflink进程,登录web界面,查看Web界面是否正常。至此,standalone模式已成功安装。<a name="5XlmI"></a># <a name="VyhRM"></a>## 1.6创建Maven工程
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.11.0
<a name="NDZnI"></a>#### 这里以单词统计程序为例,演示Flink自带示例WordCount程序的开发过程:```javapublic class WordCountExample {public static void main(String[] args) throws Exception {final ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();DataSet<String> text = env.fromElements("Who's there?","I think I hear them. Stand, ho! Who's there?");DataSet<Tuple2<String, Integer>> wordCounts = text.flatMap(new LineSplitter()).groupBy(0).sum(1);wordCounts.print();}public static class LineSplitter implements FlatMapFunction<String,Tuple2<String, Integer>> {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) {for (String word : line.split(" ")) {out.collect(new Tuple2<String, Integer>(word, 1));}}}}
1.7 Flink状态管理与CheckPoint
Flink的失败恢复依赖于 检查点机制 + 可部分重发的数据源。
检查点机制机制:checkpoint定期触发,产生快照,快照中记录了:
- 当前检查点开始时数据源(例如Kafka)中消息的offset。
- 记录了所有有状态的operator当前的状态信息(例如sum中的数值)。
- Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。快照的核心概念之一是barrier。 这些barrier被注入数据流并与记录一起作为数据流的一部分向下流动。 barriers永远不会超过记录,数据流严格有序,barrier将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。
- 每个barrier都带有快照的ID,并且barrier之前的记录都进入了该快照。 barriers不会中断流处理,非常轻量级。 来自不同快照的多个barrier可以同时在流中出现,这意味着多个快照可能并发地发生。
Checkpoint设置值:
- exactly-once:即使producer重试发送消息,消息也会保证最多一次地传递给最终consumer。
- at-least-once:此重试将导致该消息被写入两次,因此消息会被不止一次地传递给最终consumer,这种策略可能导致重复的工作和不正确的结果。
本节介绍Flink一些基本应用场景和原理,下一节将开始系统讲解DataStream编程。

若有收获,就点个赞吧
0 人点赞

{kind=link}