2 基本概念
2.1 DataStream和DataSet
Flink使用DataStream、DataSet在程序中表示数据,我们可以将它们视为可以包含重复项的不可变数
据集合。
DataSet是有限数据集(比如某个数据文件),而DataStream的数据可以是无限的(比如kafka队列中
的消息)。
这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法
添加或删除元素。你也不能简单地检查里面的元素。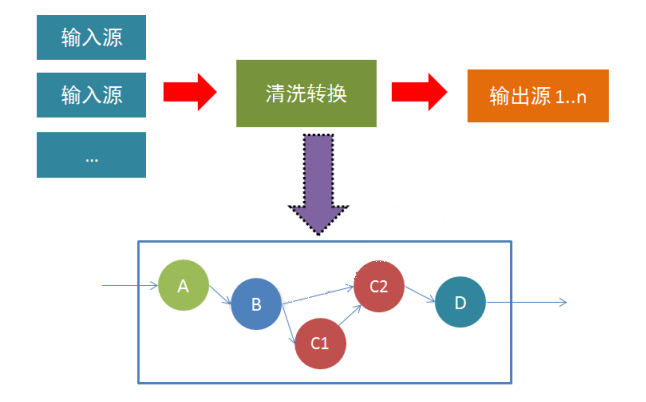
数据流通过fifilter/map等各种方法,执行过滤、转换、合并、拆分等操作,达到数据计算的目的。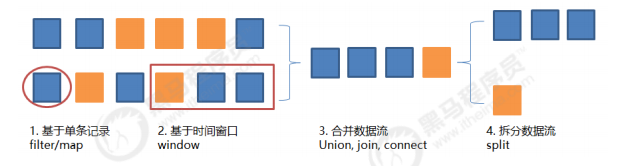
2.2 数据类型
Flink对DataSet或DataStream中可以包含的元素类型设置了一些限制,以便于更有效的执行策略。
有六种不同类别的数据类型:
1. Java元组和Scala案例类
2. Java POJO
3. 原始类型
4. 常规类
5. 值
6. Hadoop Writables
2.2.1 元组
元组是包含固定数量的具有各种类型的字段的复合类型。Java API提供了 Tuple1 到 Tuple25 。元组的
每个字段都可以是包含更多元组的任意Flink类型,从而产生嵌套元组。可以使用字段名称直接访问元组
的字段 tuple.f4 ,或使用通用getter方法 tuple.getField(int position) 。字段索引从0开始。请
注意,这与Scala元组形成对比,但它与Java的一般索引更为一致。
DataStream<Tuple2<String, Integer>> wordCounts = env.fromElements(new Tuple2<String, Integer>("hello", 1),new Tuple2<String, Integer>("world", 2));wordCounts.map(new MapFunction<Tuple2<String, Integer>, Integer>() {@Overridepublic Integer map(Tuple2<String, Integer> value) throws Exception {return value.f1;}});wordCounts.keyBy(0); // also valid .keyBy("f0")
2.2.2 POJOs
如果满足以下要求,则Flink将Java和Scala类视为特殊的POJO数据类型:
- 类必须公开类
- 它必须有一个没有参数的公共构造函数(默认构造函数)。
所有字段都是公共的,或者必须通过getter和setter函数访问。对于一个名为 foo 的属性的getter
和setter方法的字段必须命名 getFoo() 和 setFoo() 。
注册的序列化程序必须支持字段的类型。
序列化:
POJO通常使用PojoTypeInfo和PojoSerializer(使用Kryo作为可配置的回退)序列化。例外情况是
POJO实际上是Avro类型(Avro特定记录)或生成为“Avro反射类型”。在这种情况下,POJO使用
AvroTypeInfo和AvroSerializer序列化。如果需要,还可以注册自己的自定义序列化程序
public class WordWithCount {public String word;public int count;public WordWithCount() {}public WordWithCount(String word, int count) {this.word = word;this.count = count;}}DataStream<WordWithCount> wordCounts = env.fromElements(new WordWithCount("hello", 1),new WordWithCount("world", 2));wordCounts.keyBy("word"); // key by field expression "word"
2.2.3 基础数据类型
Flink支持所有Java和Scala的原始类型,如 Integer , String 和 Double 。
2.2.4 常规类
Flink支持大多数Java和Scala类(API和自定义)。限制适用于包含无法序列化的字段的类,如文件指
针,I / O流或其他本机资源。遵循Java Beans约定的类通常可以很好地工作。
所有未标识为POJO类型的类都由Flink作为常规类类型处理。Flink将这些数据类型视为黑盒子,并且无
法访问其内容(例如,用于有效排序)。使用序列化框架Kryo对常规类型进行反序列化。
2.2.5 值
值类型手动描述其序列化和反序列化。它们不是通过通用序列化框架,而是通过
org.apache.flinktypes.Value 使用方法 read 和实现接口为这些操作提供自定义代码 write 。当通
用序列化效率非常低时,使用值类型是合理的。一个示例是将元素的稀疏向量实现为数组的数据类型。
知道数组大部分为零,可以对非零元素使用特殊编码,而通用序列化只需编写所有数组元素。
该 org.apache.flinktypes.CopyableValue 接口以类似的方式支持手动内部克隆逻辑。
Flink带有与基本数据类型对应的预定义值类型。( ByteValue , ShortValue , IntValue ,
LongValue , FloatValue , DoubleValue , StringValue , CharValue , BooleanValue )。这
些值类型充当基本数据类型的可变变体:它们的值可以被更改,允许程序员重用对象并从垃圾收集器中
消除压力。
2.2.6. Hadoop Writables
使用实现 org.apache.hadoop.Writable 接口的类型。
write() 和 readFields() 方法中定义的序列化逻辑将用于序列化。
2.3 数据的操作
数据转换,即通过从一个或多个 DataStream 生成新的DataStream 的过程,是主要的数据处理的手
段。Flink 提供了多种数据转换操作,基本可以满足所有的日常使用场景。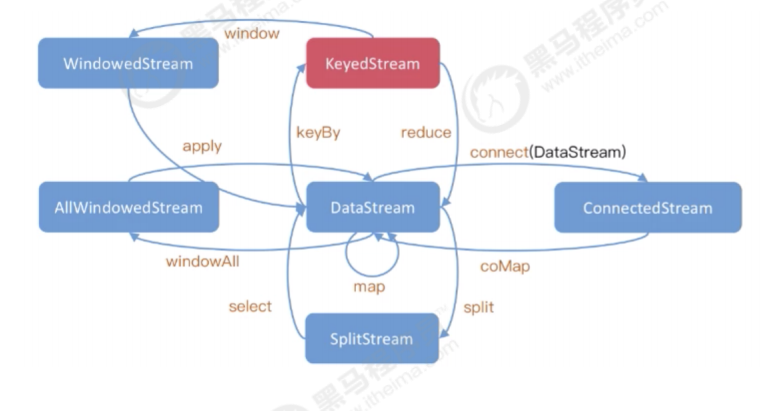
2.4 窗口的含义
Flink计算引擎中,时间是一个非常重要的概念,Flink的时间分为三种时间:
- EventTime: 事件发生的时间
- IngestionTime:事件进入 Flink 的时间
- ProcessingTime:事件被处理时的时间
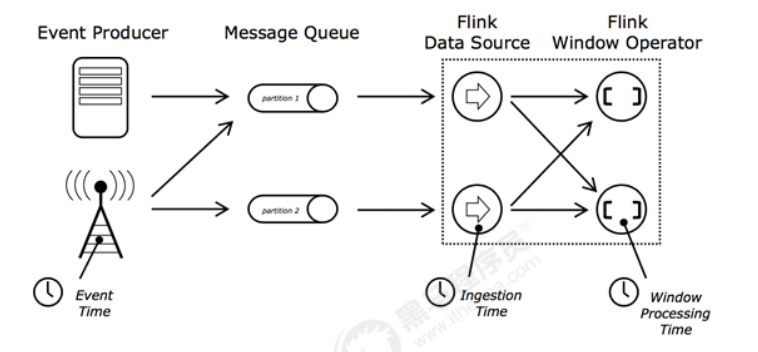
窗口是Flink流计算的一个核心概念,Flink窗口主要包括:
- 时间窗口
- 翻滚时间窗口
- 滑动时间窗口
- 数量窗口
- 翻滚数量窗口
- 滑动数量窗口
按照形式来划分,窗口又分为:
- 翻滚窗口
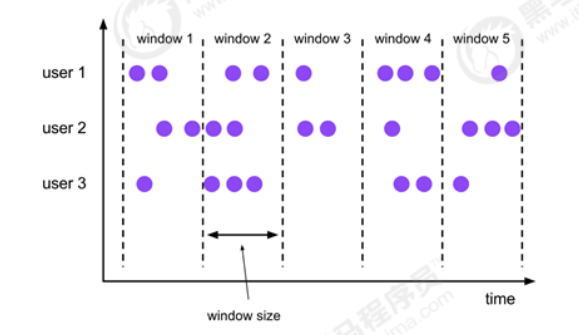
- 滑动窗口
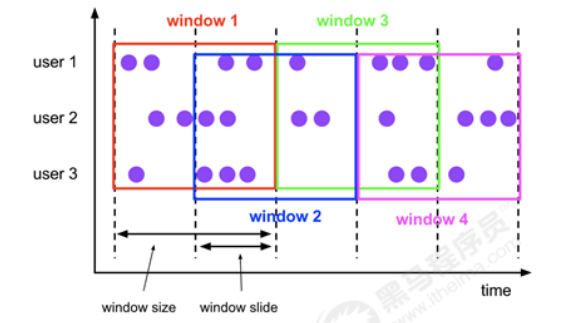
2.5 有状态的流式处理
在很多场景下,数据都是以持续不断的流事件创建。例如网站的交互、或手机传输的信息、服务器日
志、传感器信息等。有状态的流处理(stateful stream processing)是一种应用设计模式,用于处理无
边界的流事件。
对于任何处理流事件的应用来说,并不会仅仅简单的一次处理一个记录就完事了。在对数据进行处理或
转换时,操作应该是有状态的。也就是说,需要有能力做到对处理记录过程中生成的中间数据进行存储
及访问。当一个应用收到一个 事件,在对其做处理时,它可以从状态信息(state)中读取数据进行协
助处理。或是将数据写入state。在这种准则下,状态信息(state)可以被存储(及访问)在很多不同
的地方,例如程序变量,本地文件,或是内置的(或外部的)数据库中。
Apache Flink 存储应用状态信息在本地内存或是一个外部数据库中。因为Flink 是一个分布式系统,本
地状态信息需要被有效的保护,以防止在应用或是硬件挂掉之后,造成数据丢失。Flink对此采取的机制
是:定期为应用状态(application state)生成一个一致(consistent)的checkpoint,并写入到一个
远端持久性的存储中。下面是一个有状态的流处理Flink application的示例图: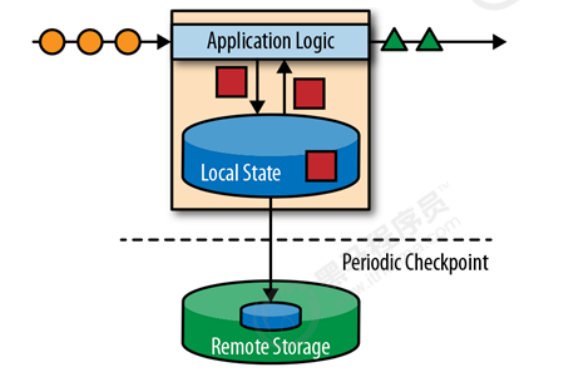
Stateful stream processing 应用的输入一般为:事件日志(event log)的持续事件。Event log 存储
并且分发事件流。事件被写入一个持久性的,仅可追加的(append-only)日志中。也就是说,被写入
的事件的顺序始终是不变的。所以事件在发布给多个不同用户时,均是以完全一样的顺序发布的。在开
源的event log 系统中,最著名的当属 Kafka。
使用flflink流处理程序连接event log的理由有多种。在这个架构下,event log 持久化输入的 events,并
且可以以既定的顺序重现这些事件。万一应用发生了某个错误,Flink会通过前一个checkpoint 恢复应
用的状态,并重置在event log 中的读取位置,并据此对events做重现,直到它抵达stream 的末端。这
个技术不仅被用于错误恢复,并且也可以用于更新应用,修复bugs,以及修复之前遗漏结果等场景中。

若有收获,就点个赞吧
0 人点赞
