一.索引概述
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。
通过构建索引树提高查询效率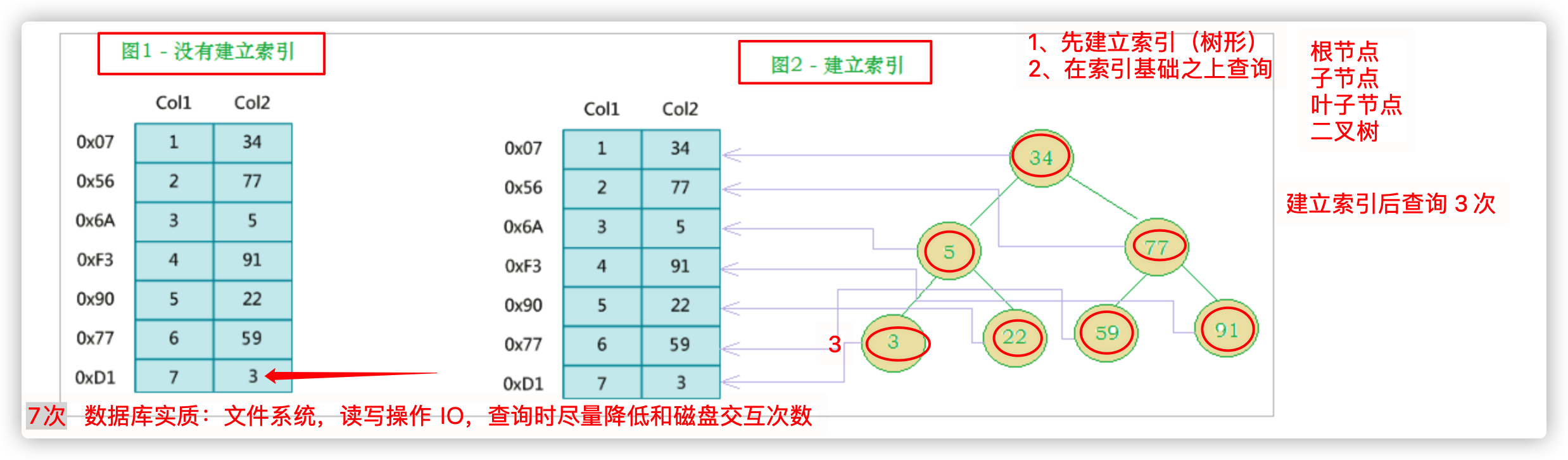
1.索引优势劣势
优势
1) 类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
2) 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势
1) 实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的。
2) 虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
2.索引结构
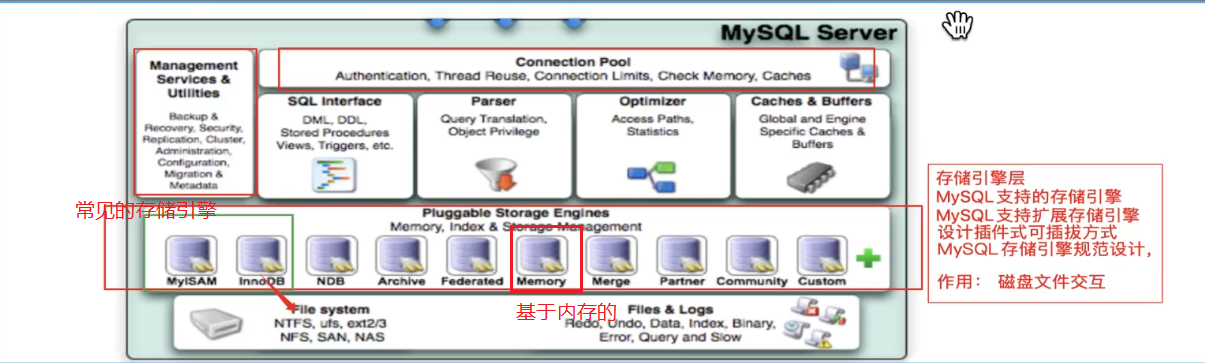
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
- BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
- HASH 索引:只有Memory引擎支持 , 使用场景简单 。
- R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引。
1.BTREE 结构
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
树中每个节点最多包含m个孩子。
- 除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。
- 若根节点不是叶子节点,则至少有两个孩子。
- 所有的叶子节点都在同一层。
- 每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以 2 <= n <=4 。当n>4时,中间节点分裂到父节点,两边节点分裂。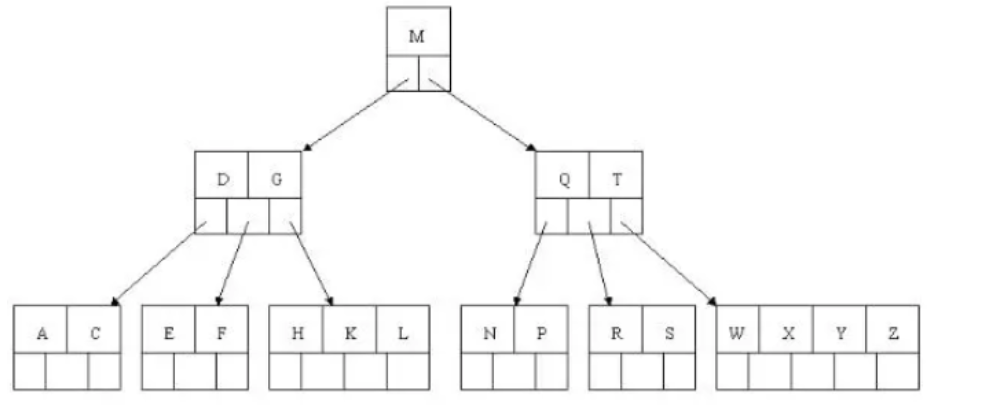
到此,该BTREE树就已经构建完成了, BTREE树 和 二叉树 相比, 查询数据的效率更高, 因为对于相同的数据量来说,BTREE的层级结构比二叉树小,因此搜索速度快。
2.BTREE+Tree 结构
B+Tree为BTree的变种,B+Tree与BTree的区别为:
1). n叉B+Tree最多含有n个key,而BTree最多含有n-1个key。
2). B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。
3). 所有的非叶子节点都可以看作是key的索引部分。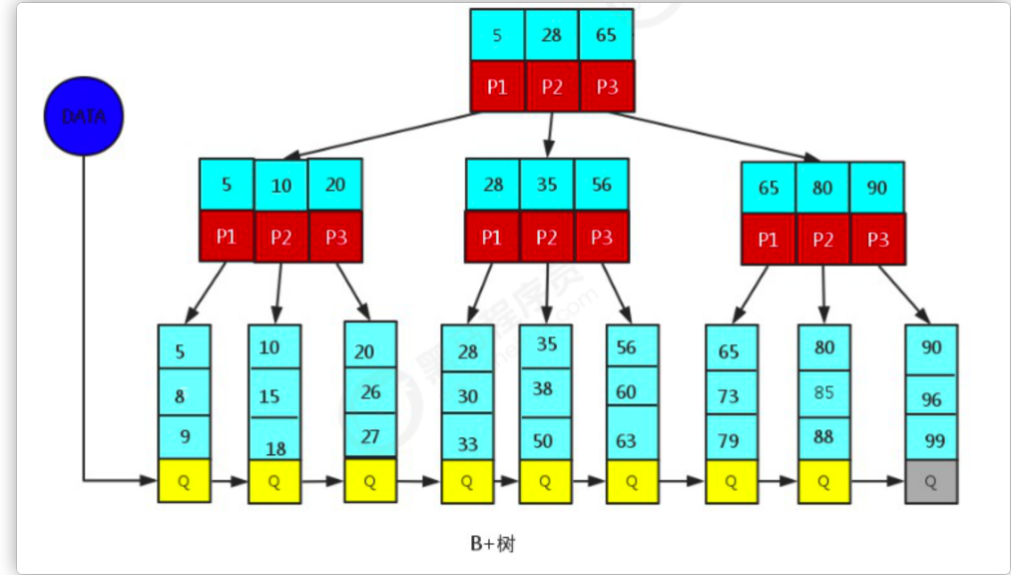
由于B+Tree只有叶子节点保存key信息,查询任何key都要从root走到叶子。所以B+Tree的查询效率更加稳定。
3. MySQL中的B+Tree
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。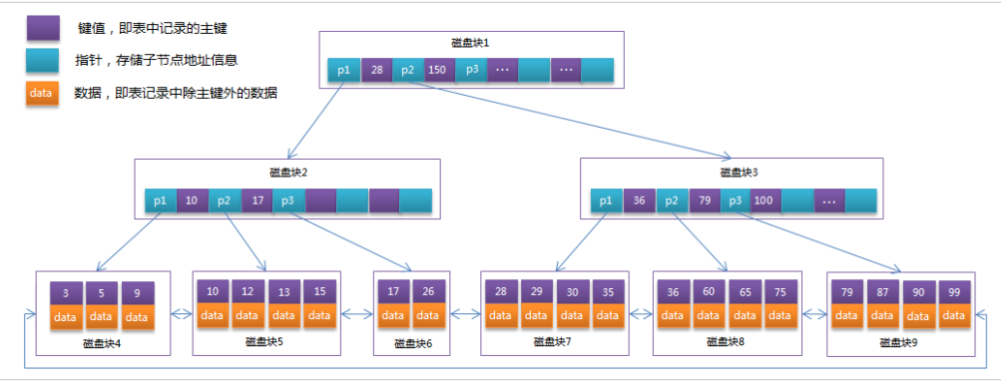
3.索引分类
按字段划分:
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值(主键索引是一种特殊的索引)
复合索引:即一个索引包含多个列,由多个列组成一个索引
按数据是否存在数据表中划分:
1.聚簇索引
即索引结构和数据一起存放的索引。主键索引属于聚簇索引。
在 MySQL 中,InnoDB 引擎的表的 .ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
- 优点
聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
缺点
优点
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
- 缺点
- 跟聚簇索引一样,非聚簇索引也依赖于有序的数据
- 可能会二次查询(回表) :这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
覆盖索引:查找的列刚好建立了索引;
如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。 再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引, 那么直接根据这个索引就可以查到数据,也无需回表。
4.索引创建和设计原则
索引常用命令
创建:create index idx_xxx on 表名(字段名);
查看:show index from table_name;
删除索引:show index from table_name;
修改:使用ALTER命令 alter table 表名 add 索引类型(列名)
索引设计原则
- 对查询频次较高,且数据量比较大的表建立索引。
- 索引字段的选择,最佳候选列应当从where子句的条件中提取,选择最常用的
- 使用唯一索引,区分度越高,使用索引的效率越高。
- 索引可以有效的提升查询数据的效率,但索引数量不是多多益善;对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,另外索引过多的话,MySQL也会犯选择困难病,虽然最终仍然会找到一个可用的索引,但无疑提高了选择的代价。
- 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率(字段值短,不是名称)
- 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
二.存储引擎
| 特点 | InnoDB | MyISAM | MEMORY | MERGE | NDB |
|---|---|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 | 没有 | 有 |
| 事务安全 | 支持 | ||||
| 锁机制 | 行锁(适合高并发) | 表锁 | 表锁 | 表锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 哈希索引 | 支持 | ||||
| 全文索引 | 支持(5.6版本之后) | 支持 | |||
| 集群索引 | 支持 | ||||
| 数据索引 | 支持 | 支持 | 支持 | ||
| 索引缓存 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 数据可压缩 | 支持 | ||||
| 空间使用 | 高 | 低 | N/A | 低 | 低 |
| 内存使用 | 高 | 低 | 中等 | 低 | 高 |
| 批量插入速度 | 低 | 高 | 高 | 高 | 高 |
| 支持外键 | 支持 |
存储方式:
InnoDB
存储表和索引有以下两种方式 :
①. 使用共享表空间存储, 这种方式创建的表的表结构保存在.frm文件中, 数据和索引保存在 innodb_data_home_dir 和 innodb_data_file_path定义的表空间中,可以是多个文件。
②. 使用多表空间存储, 这种方式创建的表的表结构仍然存在 .frm 文件中,但是每个表的数据和索引单独保存在 .ibd 中。
MyISAM
每个MyISAM在磁盘上存储成3个文件,其文件名都和表名相同,但拓展名分别是 :
.frm (存储表定义);
.MYD(MYData , 存储数据);
.MYI(MYIndex , 存储索引);
三.优化SQL
场景面试题: 一个页面在查询时,发现页面一直在等待,问应该怎么处理?
前端是否存在问题 —- 前端
网络环境是否存在问题
后端
业务代码: 多层for循环、递归….
JVM 内存使用不合理, 内存设置不合理(频繁触发 GC)
监控服务 CPU 内存消耗 (就业指导视频)
java进程
mysql 慢查询问题
1.定位问题
①查看SQL执行频率
show status like ‘Com_‘;
show status like ‘Innodbrows%’;查看当前数据库增删改查统计次数
②定位低效率执行SQL
慢查询日志 : 通过慢查询日志定位那些执行效率较低的 SQL 语句,设置long_query_time,超时的记录—log-slow-queries[=file_name]中
show processlist :实时的展示SQL执行的状态
1) id列,用户登录mysql时,系统分配的"connection_id",可以使用函数connection_id()查看2) user列,显示当前用户。如果不是root,这个命令就只显示用户权限范围的sql语句3) host列,显示这个语句是从哪个ip的哪个端口上发的,可以用来跟踪出现问题语句的用户4) db列,显示这个进程目前连接的是哪个数据库5) command列,显示当前连接的执行的命令,一般取值为休眠(sleep),查询(query),连接(connect)等6) time列,显示这个状态持续的时间,单位是秒7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行中的某一个状态。一个sql语句,以查询为例,可能需要经过copying to tmp table、sorting result、sending data等状态才可以完成8) info列,显示这个sql语句,是判断问题语句的一个重要依据
2.分析问题:explain
explain 帮助我们分析 定位慢查询的 SQL,找原因
能力:判断SQL执行快慢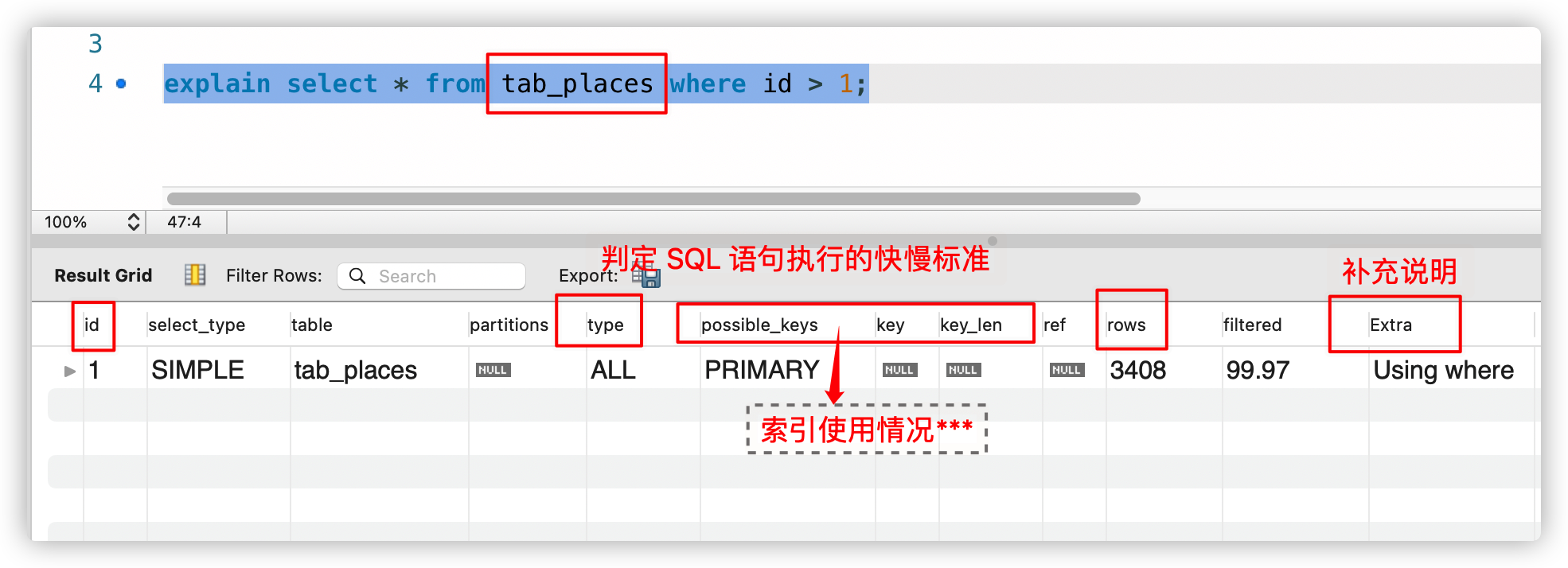
explain 之 id:
1) id 相同表示加载表的顺序是从上到下。
2) id 不同id值越大,优先级越高,越先被执行。
explain 之 select_type:
explain 之 type:

一般来说, 我们需要保证查询至少达到 range 级别, 最好达到ref 。
explain 之 key:
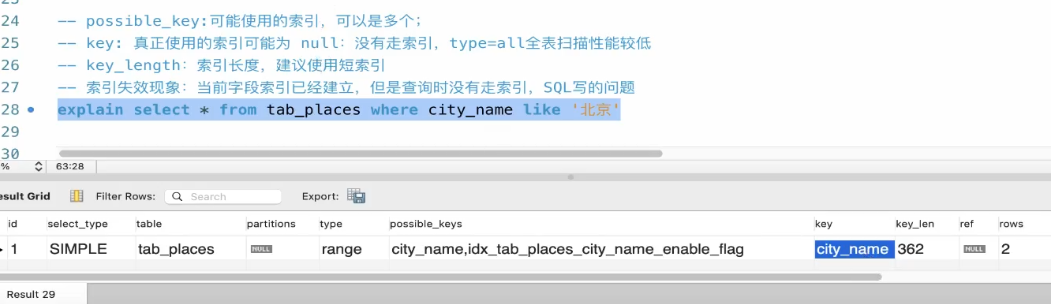
explain 之 extra:
查看执行计划
| extra | 含义 |
|---|---|
| using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取, 称为 “文件排序”, 效率低。 |
| using temporary | 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于 order by 和 group by; 效率低 |
| using index | 表示相应的select操作使用了覆盖索引, 避免访问表的数据行, 效率不错。 |

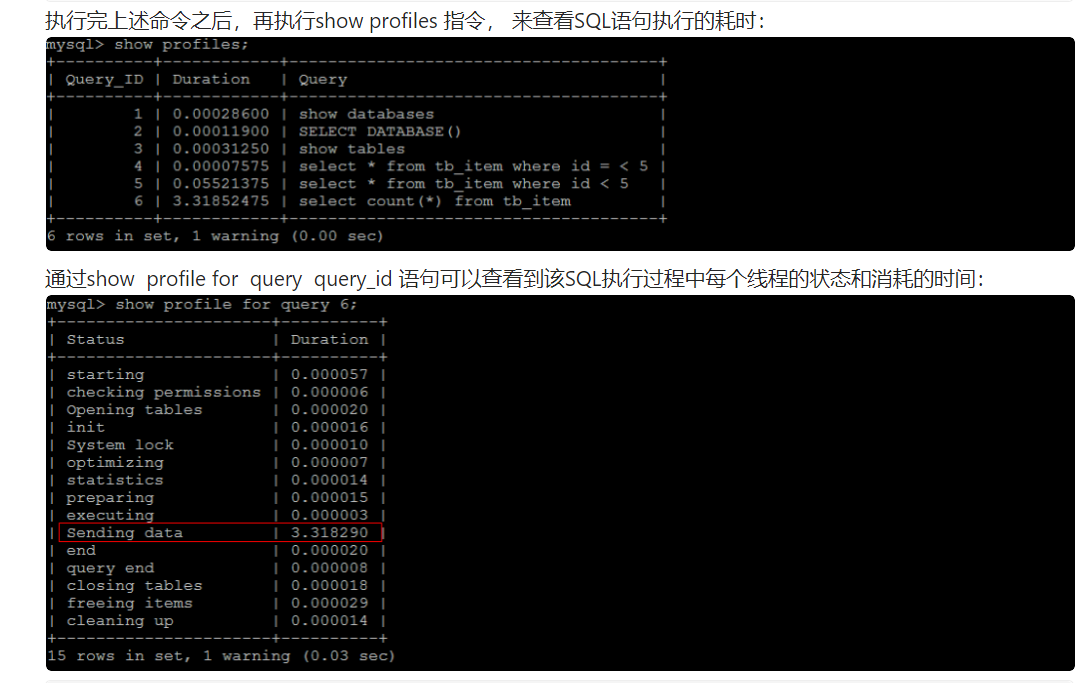
3.show profile分析SQL
四.索引的使用
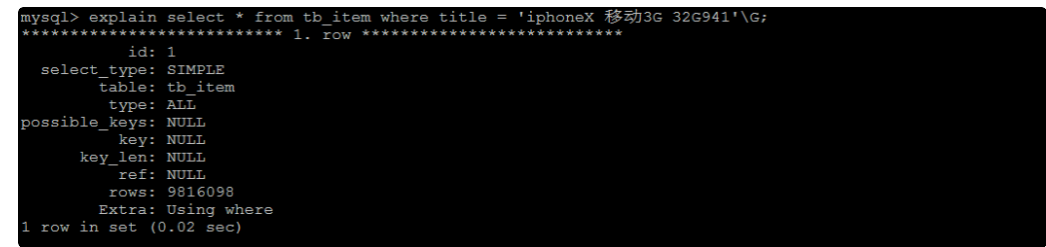
索引:
1、explain分析 type=ALL 直接对当前字段添加索引,验证即可
2、explain分析 type=index, 想办法提升type类型为 range ref 以上,可以提升查询效率
1.避免索引失效
①建立复合索引
— create index idx_seller_name_sta_addr on tb_seller(name,status,address);
— 复合索引 name status address
— 一个复合索引 相当于 建立三个索引, 建议你使用复合索引代替单列索引
— 1、 name
— 2、 name status
— 3、 name status address
— 符合最左匹配法则
— 3、 name status address len=813
explain select from tb_seller where name=’小米科技’ and status=’1’ and address=’北京市’;
— 2、 name status len=410
explain select from tb_seller where name=’小米科技’ and status=’1’;
— 1、 name len=403
explain select from tb_seller where name=’小米科技’;
— 1、 name len=403
explain select from tb_seller where name=’小米科技’ and address=’北京市’;
— 3、 name status address len=813 mysql 5.6 对当前最左匹配法则做优化
explain select from tb_seller where address=’北京市’ and name=’小米科技’ and status=’1’ ;
explain select from tb_seller where address=’北京市’ and name=’小米科技’ ;
— 不满足最左匹配法则,会导致索引失效
explain select from tb_seller where status=’1’ and address=’北京市’;
explain select from tb_seller where address=’北京市’;
explain select from tb_seller where address=’北京市’ and status=’1’ ;
*— 总结:建立符合索引第一个列是所有查询中使用频率最高的列,索引利用率很高,5.6之后只要包含最左边的字段就可以走索引
② or会导致索引失效
explain select from tb_seller where name=’黑马程序员’ or createtime = ‘2088-01-01 12:00:00’;
— 优化: union替代 or查询
explain select from tb_seller where name=’黑马程序员’
union
select from tb_seller where createtime = ‘2088-01-01 12:00:00’;
— 总结:建立索引对应的列对应值要区分度高,mysql底层评估走索引快还是全表快
— 原则:不要为了优化而优化,索引不是越多越好,*一个表中不要超过5个索引
③不要在索引列上进行运算操作, 索引将失效
④字符串不加单引号,造成索引失效。
⑤ 尽量使用覆盖索引,避免select *
⑥用or分割开的条件
如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到
⑦以%开头的Like模糊查询,索引失效。
⑧ 如果MySQL评估使用索引比全表更慢,则不使用索引
⑨ is NULL , is NOT NULL 有时索引失效。
⑩ in 走索引, not in 索引失效。
11). 单列索引和复合索引。
五.SQL优化
1) 大批量插入数据
①主键有序插入比无序快
②关闭唯一性校验
在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
③ 手动提交事务
如果应用使用自动提交的方式,建议在导入前执行 SET AUTOCOMMIT=0,关闭自动提交,导入结束后再执行 SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
2)优化insert语句
如果需要同时对一张表插入很多行数据时,应该尽量使用多个值表的insert语句,这种方式将大大的缩减客户端与数据库之间的连接、关闭等消耗。使得效率比分开执行的单个insert语句快。
执行后,手动commit
保证插入的顺序
3)优化order by语句
了解了MySQL的排序方式,优化目标就清晰了:尽量减少额外的排序,通过索引直接返回有序数据。where 条件和Order by 使用相同的索引,并且Order By 的顺序和索引顺序相同, 并且Order by 的字段都是升序,或者都是降序。否则肯定需要额外的操作,这样就会出现FileSort。
无法避免FileSort时:ort_buffer_size 和 max_length_for_sort_data 系统变量,来增大排序区的大小,提高排序的效率。
4) 优化group by 语句
GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引
如果查询包含 group by 但是用户想要避免排序结果的消耗, 则可以执行order by null 禁止排序
5) 优化嵌套查询
6)优化OR条件
如果要利用索引,则OR之间的每个条件列都必须用到索引 , 而且不能使用到复合索引; 如果没有索引,则应该考虑增加索引。
7) 优化分页查询
深度分页问题:如果一个表数据量千万级,分页查询最后一页的数据,应该怎么查?
解决:通覆盖索引查询最后一页的数据的id主键和原表进行关联查询,命中索引,所以执行性能较高,解决内存OOM问题
六.面试问题
数据库专题
今日内容:
1、索引
为什么需要索引?
索引是怎么建立的? 为什么这么快?
索引分类
BTree和B+Tree 建立过程和区别
2、SQL优化步骤
1、先定位慢查询的sql(慢查询日志、spl、spf)
2、分析sql慢的原因(explain type key extra….)
type 级别提高(级别记住)
3、优化sql(加索引、改sql)
4、验证是否优化生效
3、避免索引失效现象**
最左匹配法则
使用复合索引代替单值索引
不要为了优化还写sql
4、其它优化(了解)
SQL优化
海量数据的分页优化
模糊查询索引失效现象
硬件优化(了解)— 03
mysql内置函数(了解)
5、自己看部分:
1、阿里巴巴开发手册 第5部分 数据库
2、03-MySQL高级 — 5. Mysql锁问题 间隙锁危害
3、04-MySQL高级 — 日志相关

若有收获,就点个赞吧
0 人点赞
