一.HsahMap底层原理(p39-p55)
1.hash表结构的优点是什么?
hash表的结构帮助我们快速查找,先计算元素hashcode值,然后二次hash,对容量取余操作获得下标(一次比较)
如果计算出来桶下标一样,则需要多次比较(以链表的形式)
2.如果很多元素桶下标都一样,如何提升性能?
假设有八个元素(二次hash为97和49)以链表的形式挂在某一下标下,查询效率会变慢,通过以下方法提升效率:
扩容:当数组中 元素>容量负载因子(160.75=12),会扩容两倍重新计算下标;97%16=1,49%16=1;97%32=1, 49%32=17
但是如果他们的原始hash值都一样则无法优化效率
树化:当链表变为红黑树,第一次与根节点比(左边小,右边大)==>二叉查找提高效率
①链表长度大于8
②数组长度大于64(如果不大于64,会先尝试扩容)
注意:
链表(Node)短的时候性能高于红黑树(treeNode,内存占有变多)
红黑树出现是一偶然,一般不会出现(大于8)
3.红黑树何时会退化为链表?
①扩容时由于原始hash值不同,重新计算下标,拆分树时,树的个数小于等于6会退化为链表
②remove树节点时,移除之前若 左孩子/左孙子/右孙子节点 有一个不存在个会变为链表
4.索引是如何计算的?数组容量为何是2的n次方?
每个对象都有hashcode的方法==>hashmap中的二次hash()===>对容量取模(优化:当前容量-1 按位与二次hash值97&(16-1))
除数必须是2的n次方 即数组容量,否则无法实现等价兑换
当扩容时链表长度大时,二次hash值对容量做按位与运算,如果为0不改变位置;如果不为0,位置=原始位置+旧的容量
实现数据批量转移
5.为何还要二次hash()方法?

6.put方法流程,1.7与1.8有何不同?
①hashmap是懒惰创建数组的,首次使用才会创建
②计算索引(桶下标)==>没有被占用,创建node占用返回
如果被占用了:
已经是Treenode走红黑树添加/更新
是普通的node,走链表的添加或更新,链表长度超过树化阈值,走树化逻辑
③返回前检查容量是否超过阈值,一旦超过进行扩容(在添加完后再扩容)
不同点:
①1.7链表插入是头插法,1.8是尾插法
②1.7扩容要大于等于阈值并且没有空位;1.8大于阈值就扩容
③1.8在扩容计算node索引时会优化(如果为0不改变位置;如果不为0,位置=原始位置+旧的容量
实现数据批量转移)
7.加载因子为何默认是0.75?
①加载因子影响的是扩容的阈值,元素在hash表中按泊松分布,负载因子为0.75,长度超过8的链表出现的概率是亿分之6,均衡了查询和空间占用的问题
②大于这个值,空间节省了,但是链表的长度较长,查询性能变低
③小于这个值,冲突减少了,但是扩容就会更频繁,浪费空间
8.在多线程情况下,会存在什么问题?
①扩容死链(1.7)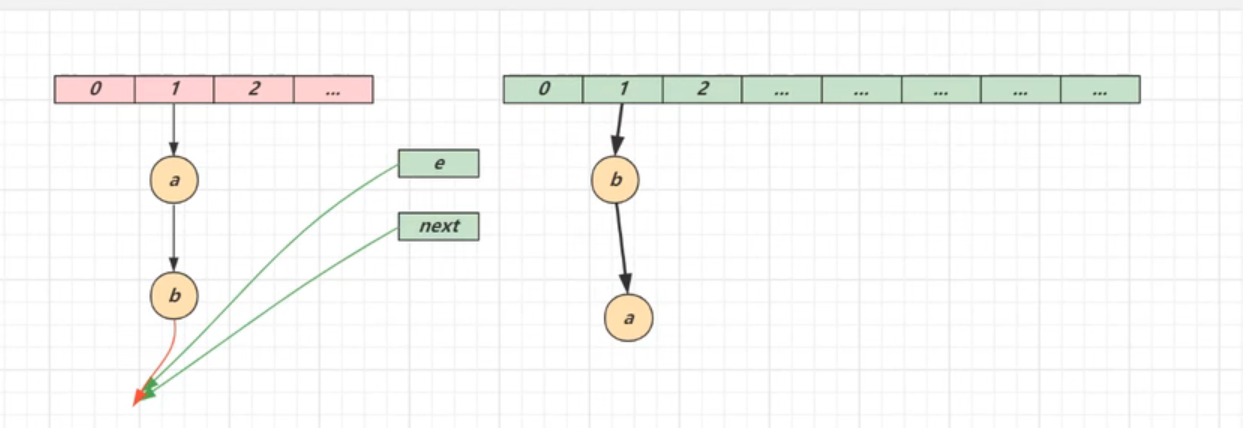
单线程元素迁移:
e:指向的是当前迁移的对象 next:指向的是下一个迁移的对象
由于使用的是头插法,迁移后的顺序会被改变
迁移只是改变元素指向的地址,并不是创建了新的元素
多线程扩容情况:此时e指向a,next指向b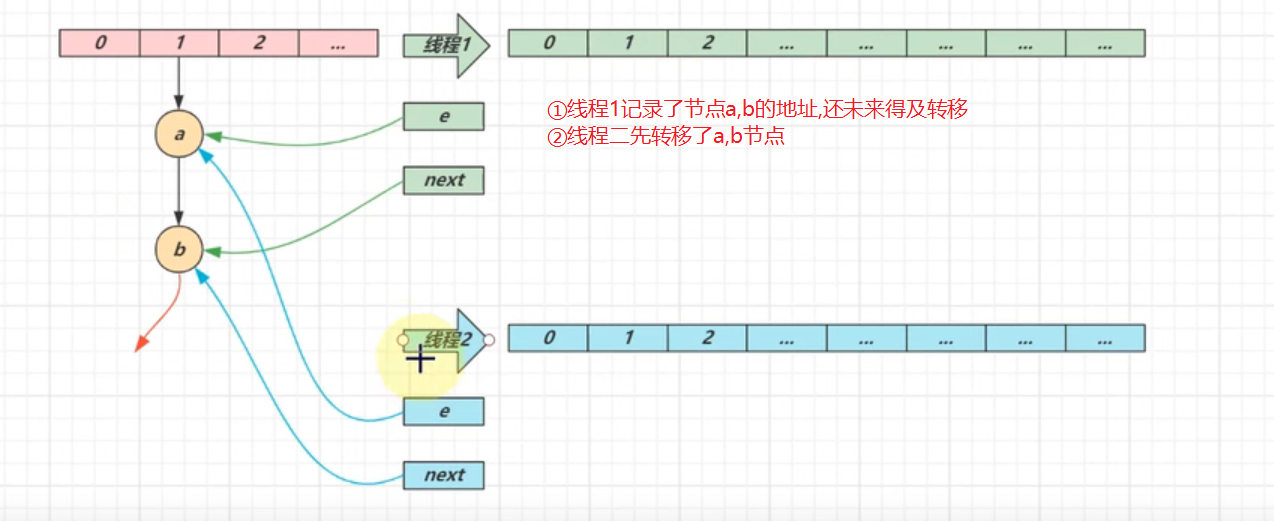
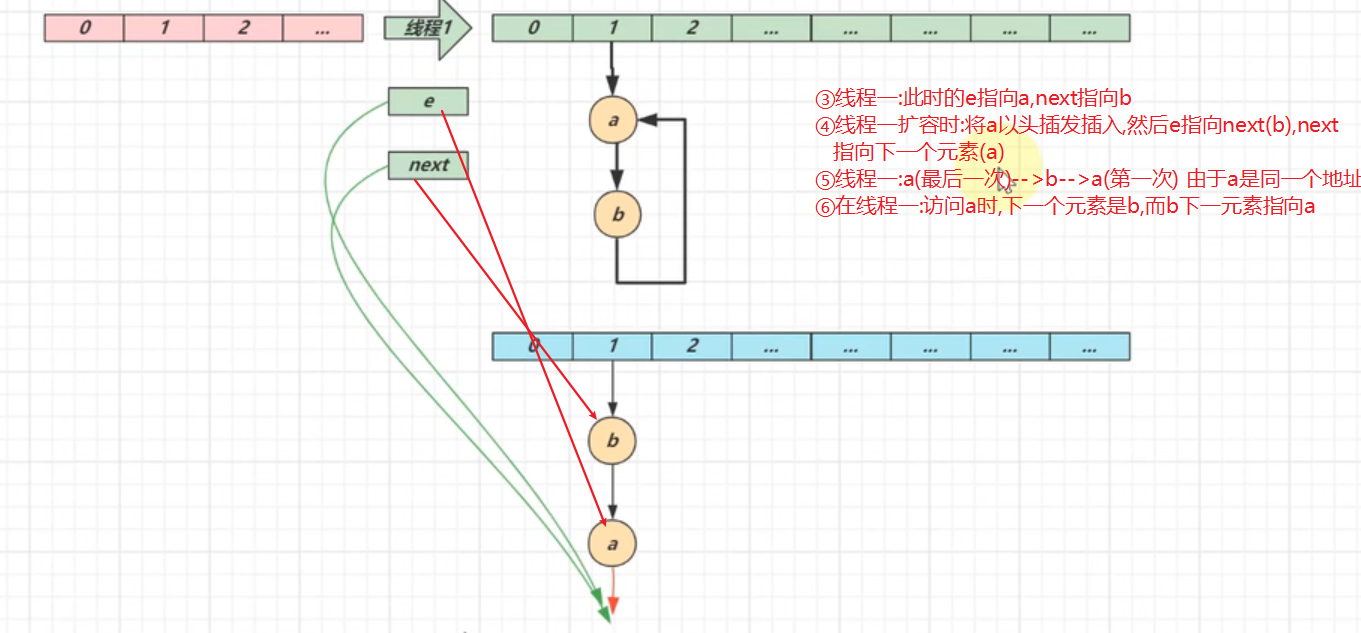
②数据错乱(1.7,1.8)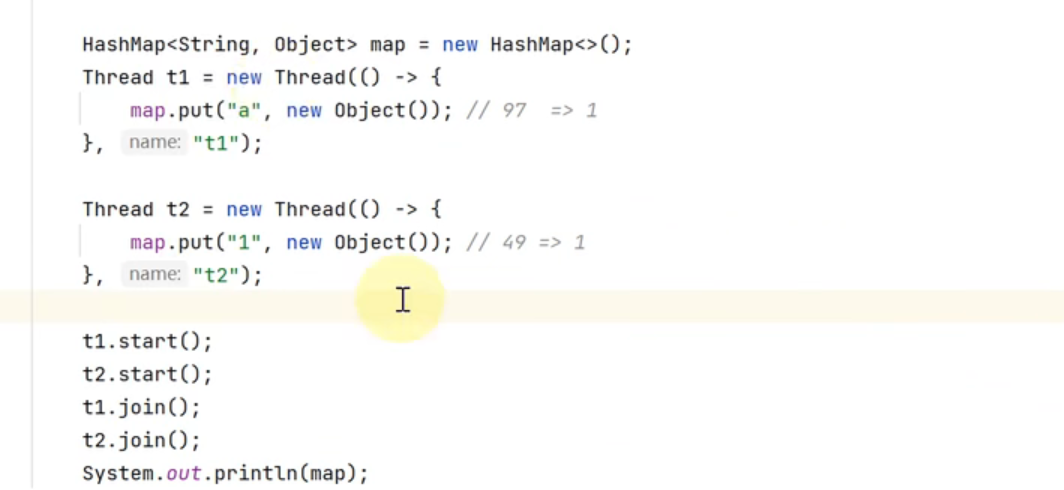
当多线程向hashmap中添加元素时
a先进入计算 97&(16-1) 索引为1 当前tab[1]=null==>创建一个新的node节点填充
若在创建node节点之前,其他线程t2(key为1)进入==>判断也为null==>则创建节点将key为1的填充
此时线程t1再运行会把key为1的元素覆盖==>a
9.hashmap的key能否为null?作为key的对象有什么要求?
①可以为null,其他的Map实现不一定:Treemap,Hashtable,currentHashMap(会出现空指针)
②作为key对象,必须实现hashCode和equals,并且key的内容不能修改(否则get结果为null,比如,student对象的属性改变)
hashCode:为了key有更好的分布性,提高查询性能
equals:万一两个元素的hashCode的值相等,通过equals判断是否为相同的元素
注意:如果hashCode值相等,不一定是同一个元素;如果两个元素equals相等,那么是同一个元素
10.String对象的hashCode()如何设计的,为啥每次*31?

二.设计模式:单例(p56-62)
1.单例模式常见的五种方式
①饿汉式
饿汉式给静态变量赋值,放入到静态代码块中执行,静态代码块中的线程安全java虚拟机保证
破坏单例的几种方法:
反射破坏:获得Class对象,获得构造方法==>可以创建多个实例 ==>判断此单例如果!=null抛异常
反序列化破坏:先把对象变为字节流再还原成对象,该对象地址与原对象不同==>在单例中重写readResolve返回单例对象
Unsafe破坏单例:工具类UnSafeUtils.getUnsafe().allowcreateInstance(clazz)
②枚举饿汉单例

③懒汉单例

④懒汉单例DCL(双检索)优化

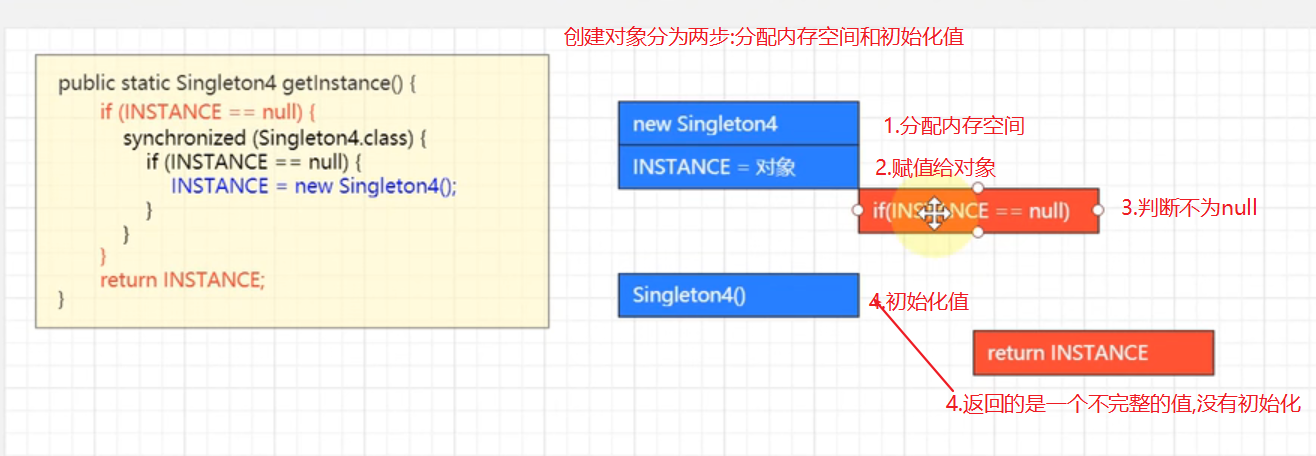
④懒汉单例-静态内部类
2.了解jdk中有哪些地方体现了单例模式
Runtime类:饿汉单例
System.exit(状态码)方法==>调用了Runtime.getRuntime.exit(status) 退出虚拟机
System.gc()==>Runtime.getRuntime().gc() 垃圾回收
Console对象:懒汉式单例双检索创建
System中的console对象创建
Collections中的EmptyNavigableSet,EmptyIterator,Enumeration集合创建:内部类懒汉单例
EmptySet,EmptyList,EmptyMap饿汉单例
Comparator比较器中的ReverseComparator.REVERSE_ORDER(反向比较器)内部类懒汉式
Compatator中的反序reserve()方法(正序)==>natualOrder()==>INSTANCE 枚举实现饿汉式单例
三.线程池相关概念(p63-67)
1.线程有哪些状态?
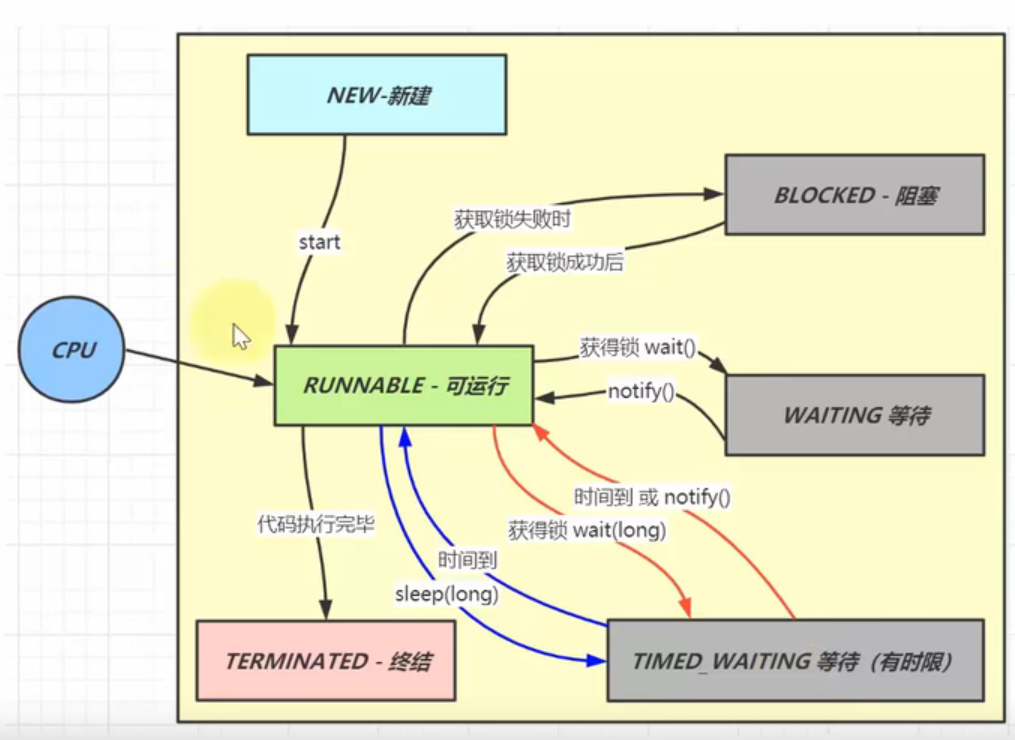
2.掌握Java线程状态之间的转换?
①NEW-新建状态:新建状态线程被创建没有和操作系统底层关联被分配cpu执行代码,调用start()关联
②Runtime-可运行:执行完毕了进入TERMINATD-终结状态,底层关联的真正线程相关资源得到释放
③BLOCKED-阻塞:多个线程争抢锁失败就回变为阻塞状态,当持锁线程释放锁,抢锁成功之后变为可运行
④WAITING等待:当持锁线程向下完成代码需要满足条件时,调用wait()进入等待状态释放锁,条件满足后再获得锁
条件满足时:另外一个线程调用notify(),唤醒此线程重新争抢锁,成功后变为可运行状态
⑤TIMED_WAITING有时限等待:wait(long)有参,可以设置时间自动唤醒或者其他线程唤醒
sleep(long),不需要和锁,是否满足条件有关联
注意:①②流程不可逆,③④⑤不会让cpu执行其中的代码
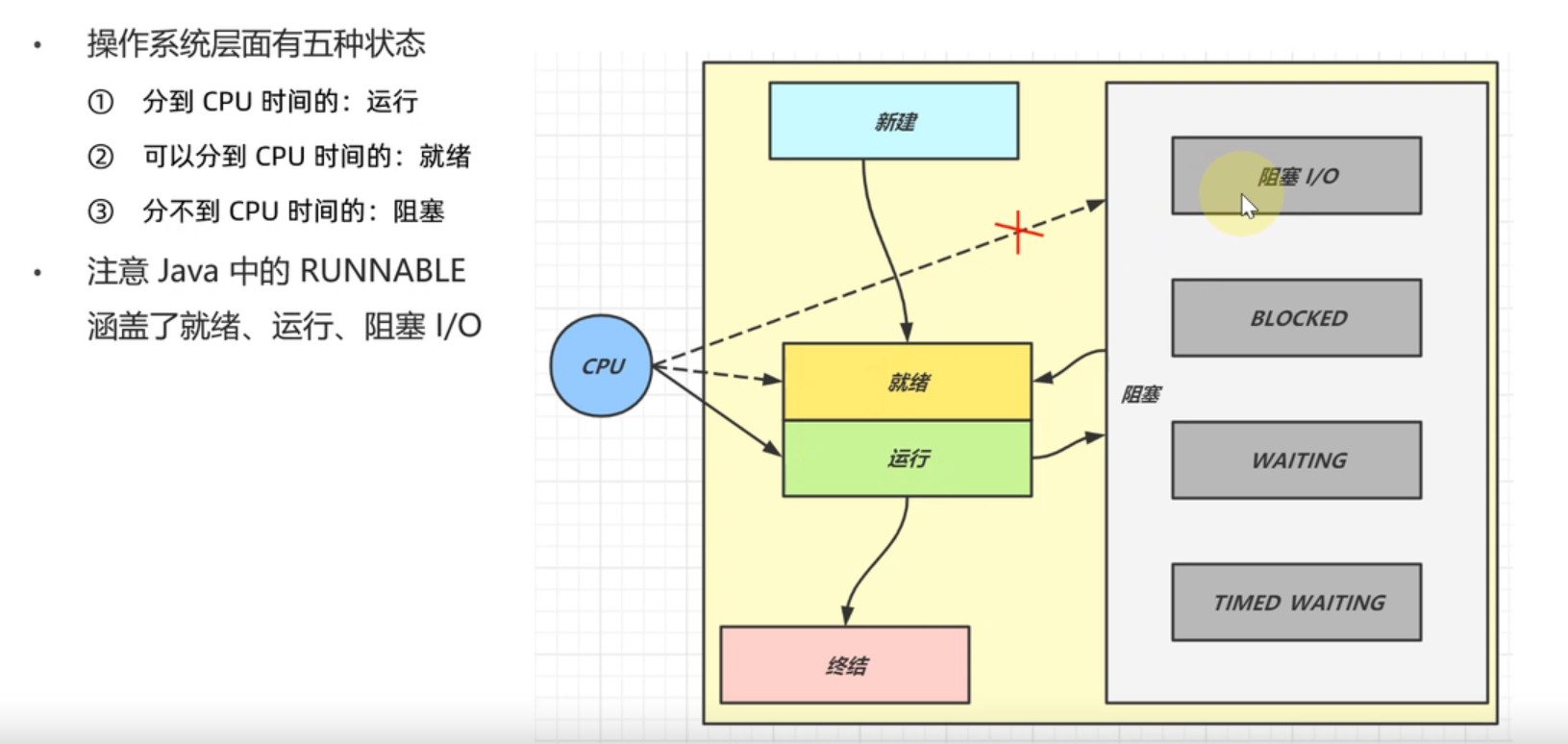
2.辨析六种状态vs五种状态?
3.线程池核心参数(7种)?
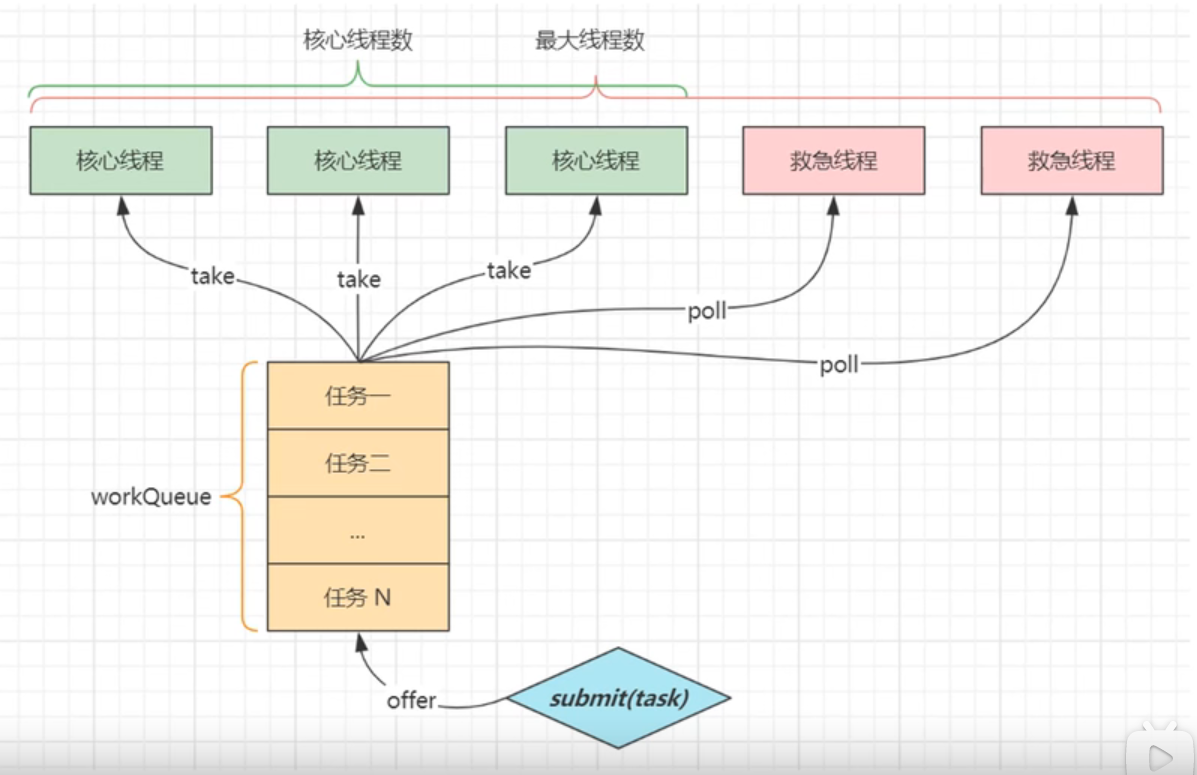
把一个实现了Runnable或Callable接口任务对象,线程池调用submit(task)
①corePoolSize 核心线程数目:执行完任务之后任然要保存(可以为0,执行完之后都不保留,都为救急线程)
②maximumPoolSize最大线程数目:核心线程+救急线程(执行完任务后不需要保留,当核心线程和任务队列满时会创建)
③keepAliveTime:针对救急线程,不会保留
④unit 时间单位:针对救急线程
⑤workQueue 工作队列:当核心线程满的时候,不会先创建救急线程,先添加到工作队列中,当核心线程空闲时处理(先进先出)
⑥threadFactory 线程工厂:起名字
⑦hander拒绝策略:核心线程,任务队列,救急线程都满了
4.线程池的四种拒绝策略?
①默认AbortPolicy:直接抛异常
②CallerRunsPolicy:交给调用者线程执行
③DiscardPolicy:直接丢弃
④DiscardOldestPolicy:把队列中等待最久的丢弃,新的加入到队列中
5.线程池优点?
1、不用重复创建销毁线程
2、由于没有线程创建和销毁时的消耗,可以提高系统响应速度
3、可以对线程进行合理的管理,根据系统的承受能力调整可运行线程数量的大小
四.Mysql专题(p35-57)
1.mysql的隔离级别
Read uncommit 读未提交:安全性能最低,能读取到未提交的数据==>脏读;不用,不安全
问题:脏读,幻读,不可重复读
Read commited 读已提交(大多数据库默认)等到commit后才能看到,解决了脏读问题,不可重复度(修改后就变了)
问题:幻读,不可重复读
Repeatable read 可重复读(mysql默认隔离级别):解决了不可重复读问题,在select和update并发执行时,查询的结果一致,但是会出现幻读(还是读取修改之前的数据)
问题:幻读(通过InnoDB和Falcon存储引擎通过多版本并发控制机制可以解决)
Serializable 可串行化:最高安全级别,一个事务在进行的时候,其他事务无法执行,效率低
脏读:一个事务操作多次修改数据,还未提交时,另一个并发事务读取了非持久化后的数据
不可重复读:某个数据在一个事务查询中反回了不同结果,事务执行过程中,数据被其他事务提交修改了
幻读(虚读):事务T1批量对一个表中一列值为1的数据修改为2是,事务T2对这表插入了一条列值为1的数据,并提交;
T1发现新加的一条值为1的没有进行修改,应该读不到(T2刚插入的)
2.mysql复制原理?(单台mysql已经达到瓶颈,保证多台数据一致)
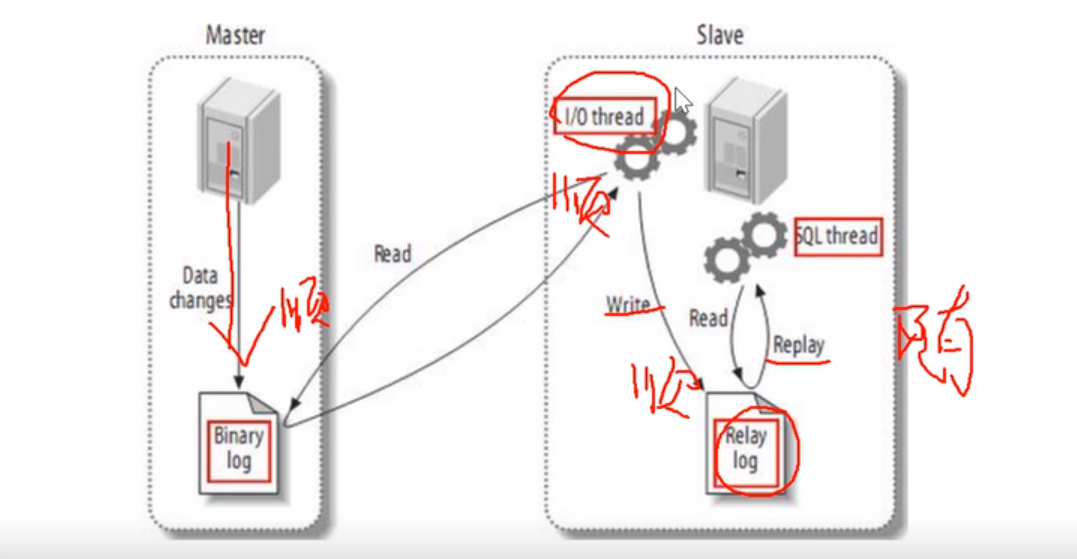
①我们对master服务数据进行操作记录到二进制binlog日志中,当master上数据改变时,将改变记录到二进制文件中
②Salve服务器会在一定时间间隔对master二进制文件探测是否改变,如果改变,开始一个I/OTread请求二进制事件
③同时主节点会为每个I/O线程启动一个dump线程,发送二进制事件,保存到从节点本地中继日志中,从节点启动sql线程,从中继日志中读取二进制日志,在本地重放,使得数据一致,最后I/OTread和SQLTread进入睡眠,等待下一次唤醒
2.mysql聚簇索引和非聚簇索引区别?
注意:索引是存在磁盘的,所以索引的存储是和存储引擎相关的
Innodb存储引擎:数据和索引文件都放在ibd文件中,既有聚簇索引也有非聚簇索引
myisam:数据文件放在myd文件中,索引放在myi文件中,非聚簇索引
区分聚簇索引和非聚簇索引,只要判断跟索引是否存储在一起;
innodb存储引擎在进行数据插入的时候,数据必须要和索引放在一起,如果有主键就使用主键,没有就使用唯一键,没有唯一键就使用6字节的rowid,因此和数据绑定在一起的就是聚簇索引;一个数据库中有多个索引,避免数据冗余,其他索引的叶子节点存储的是聚簇索引的key值,查询的时候通过回表的方式
3.mysql索引的基本原理?
为什么要索引?
什么是索引?
索引在MySQL中也叫是一种键,是存储引擎用于快速找到记录的一种数据结构
索引的原理?
由于数据和索引都是保存在磁盘上的,为了提高效率我们需要把其读取到内存中,才能更高效的访问;访问磁盘的成本是访问内存的十万倍,采用分块读取的方式:B+tree
索引的数据结构?
MySql主要用到两种数据结构:B+Tree索引和Hash索引
Inodb存储引擎默认是 B+Tree索引:单条记录比不上hash索引,但是更适合排序等范围操作
Memory存储引擎默认是 Hash索引:找某一条记录时速度非常快,不支持范围查询和排序等功能
B+Tree实现索引上的优势即过程?
4.mysql索引结构有哪些,各自的优缺点是什么?
索引的数据结构和存储引擎的实现有关;innodb:B+tree memory(内存中效率高可以使用):hash索引
B+Tree 是一个平衡的多叉树,根节点到每个叶子节点高度差不超过1,而且同层级两个点间有指针相连接,在B+Tree上的常规检索,从根节点到叶子节点搜索效率基本相当,不会出现大幅波动(BTree波动大),而且基于索引的顺序扫描室,也可以利用双向指针快速左右移动,效率非常高;因此B+Tree索引被广泛用于数据库,文件系统等场景
hash索引就是采用一定的hash算法,把键值换算成新的hash值,检索时不需要类似B+Tree那样从根节点开始逐级查找,只需一次hash算法就可以定位;
如果是等值查询速度很快,键值不唯一,则扫描链表;hash结构元素在其中散列分布,不支持范围查询,比如:like模糊查询,不支持多列联合索引的最左匹配原则
5.mysql为什么需要主从同步?
1.读写分离:主库负责写,从库负责读;有一条sql需要锁表,导致展示不能使用读的服务,让从库读
2.做数据的热备:准备两个主库,防止主库用户剧增,导致宕机
3.架构扩展,业务量越来越大,需要分库分表,降低磁盘I/O访问频率,提高单个机器的I/O性能
6.mysql中索引类型有哪些,以及对数据库的性能影响?
普通索引:允许被索引的数据包含的重复的值
唯一索引:可以保证数据记录的唯一性,可以为空
主键索引:一张表只能定义一个主键索引,用于唯一标识一条记录,使用关键字primary key来创建
联合索引:多个列组成的索引
全文索引:通过建立倒排索引,是目前搜索引擎使用的一种关键技术(es)
合适的索引可以极大的提高数据的查询速度,通过索引,在查询的过程中使用mysql优化隐藏器选择最优的,提高性能
但是会降低插入,删除,更新表的速度,索引和数据是独立的,进行操作时不仅要修改数据还要操作索引
索引需要占用空间,所有不是越多越好,如果要建立聚餐索引那么需要的空间就越大;非聚簇索引越多,叶子节点存储的是聚簇索引的key值,聚簇索引改变了,非聚簇索引也会跟着变化
7.什么是mysql的主从复制?
mysql主从复制是指数据可以从一个mysql数据库服务器主节点,复制到一个或多个从节点;mysql默认采用异步方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定数据库,或特定的表;

若有收获,就点个赞吧
0 人点赞
