1) 码点餐
1.请简单介绍一下你们这个项目?
是一种基于SaaS平台的,所谓Sass平台就是一种服务商部署在自己服务器上,对商家提供软件租赁。
商家只对我们软件租赁只需要配置域名,比如说用友就是一种基于SaaS技术平台。SaaS平台的主要特征:服务共享,数据隔离。
该项目开发分为三个平台:
运营平台:负责商家管理平台和一些基础数据模块,统一权限、日志、图片、数字字典
商家平台:点餐后台核心业务,管理员工,店铺,桌台,菜品,结算订单等功能
点餐平台:用户可以扫码开桌点餐,追加菜品等功能
2.说一下你们项目的架构?
微服务架构,基于Spring Could和Spring Cloud Alibaba实现的,Spring Could Alibaba是对Could增加,解决问题
主要组件:
- Sentinel |
分布式服务架构的轻量级流量控制,降级保护产品 |
|---|---|
- Nacos |
服务注册和配置中心 |
- RocketMQ |
一种消息队列中间件 |
- Dubbo |
基于RPC协议的远程调用框架 |
- Seata |
分布式事务管理 |
- Alibaba Cloud OSS |
阿里云提供的海量存储服务 |
- Alibaba Cloud Schedulerx |
定时任务调度组件 |
3.介绍一下你们数据库是怎么设计的?
按照功能模块领域垂直把数据库分为5个库:
订单表冗余字段table_id避免跨库查询
4.1商家品牌模块管理对应接口功能实现?
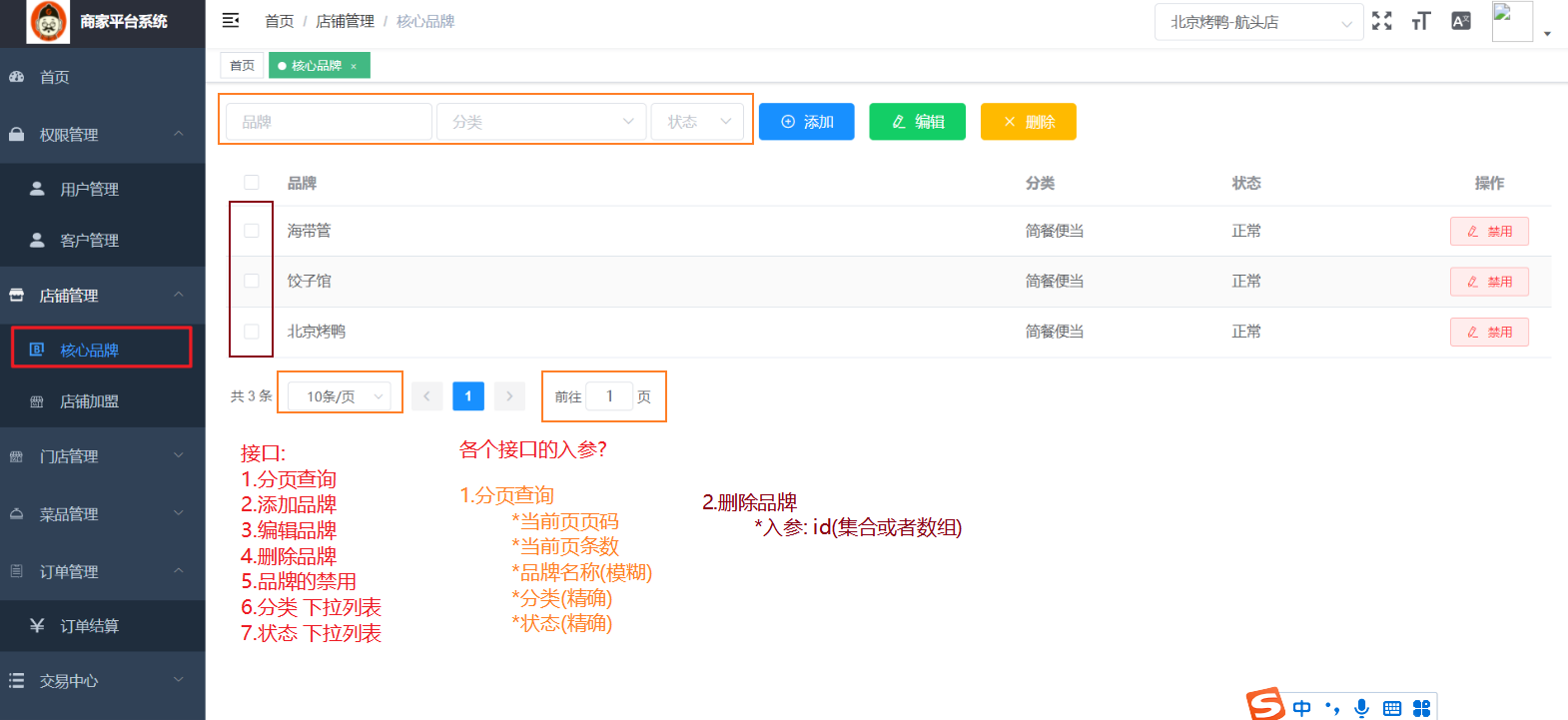
接口分析:
①分页查询功能:
搜索品牌模糊查询,选择下拉框:分类category(字典表parent_key一致:0特色小吃,5米线烫捞…)状态enableflag(Yes,No)
调用链路:
BrandController:接收前端请求通过dubbo的rpc远程调用品牌的dubbo定义接口BradnFace
BradnFaceImpl:调用BrandService层(对应数据库)接口,根据查询到结果brandId远程调用Affix服务(businessId业务id)=>affixVo,统一封装为BrandVo返回给controller层
BrandServiceImpl:根据pageSize,pageNum以及brandVo查询数据库,获得对应的pojo
②新增接口:
第一次请求:上传图片到Affix表,返回affixId,但是此时的Affix表还未和品牌产生关联,需要bussinessId(brandId)
第二次请求:携带brandVo(affixId,brandName,category,状态),先将信息存入到Brand表==>mybatisPuls
自增主键回填,远程调用Affix服务更新updateById(affixo)=>brand与affix就相关联了;回显数据给前端(url,brandId,affixId)
③修改接口:(修改和禁用功能)
修改类似新增,根据brandId查询图片集合,只需要判断图片是否修改(文件表中是否存在affixId);存在只修改brand表,不存在删除此图片新增
④删除接口:(需要禁用状态)
根据品牌前的复选框可进行批量删除,brandVo.getCheckedIds,先删除brand表中数据,再删除关联affix表中数据
注意:
①此功能模块中新增,修改,删除涉及到跨库和rpc的远程调用,本地事务无法完成回滚,需要依赖Seata的分布式事务。
②分析表关系:一个商家对应多个品牌==>品牌表中需要有enterprise_id(多的一方放少的一方主键)
一个品牌有多个门店,门店表中有品牌的id(brandId)
| tab_brand(主表) | 商家品牌表 | 类型/取值 |
|---|---|---|
| id | 主键 | bigint |
| enable_flag | 状态 | varchar |
| ct | 创建时间 | datetime |
| ut | 更新时间 | datetime |
| brand_name | 品牌名称 | varchar |
| category_id | 品牌分类表id | varchar/品牌表分类与品牌表属于一对多 |
| enterprise_id | 对应商家表id | 一个商家对应多品牌 |
| tab_affix(从表) | 文件附件表 | 类型/取值 |
| business_id | 业务id 与主表主键关联(图片) | 一个品牌对应多个文件附件(bigint) |
| business_type | 类型(0品牌,1文章,2视频) | 用来标识文件类型/varcahr |
| tab_data_direct(从表) | 常量维护表(与代码解耦合) | 类型/取值 |
| parent_key | 父项键 | 用于字典表的搜索/varchar |
| data_key | 子项键 (parent_key+value 唯一) | 用于字典表的搜索/varchar |
| data_value | 前端给后端传的值 | varchar |
| description | 用户看到的值 | varchar |
①为什么会出现分布式事务?
Spring中事务是基于DataSource数据源,Spring数据源的代理创建数据源对象,管理本地事务,底层是AOP代理
远程调用其他服务:Spring的IOC容器不同(不同服务调用,不存在事务传播行为)
数据源DataSource不同,无法统一管理
②分布式事务判断标准?
● 多服务多数据源
● 存在增删改的远程调用
4.2用户通过扫码进入系统,然后完成开桌,进行点餐操作?

开桌接口:
业务描述:用户扫描桌台上的二维码,传入桌台id并且选择就餐人数完成开桌(本质就是创建订单)
实现流程:
前端传入桌台id和就餐人数去开桌(创建订单),为了防止重复创建订单,并发访问下被一个线程使用,保证数据唯一性。使用基于redis的redisson分布式锁:String结构 key为业务id+桌台id;
为了保证幂等性,防止之前创建过此订单,会根据桌台id去查询订单服务:如果结果为空,则创建订单(tableId,orderState(【DFK待付款,FKZ付款中,QXDD取消订单,YJS已结算,MD免单,GZ挂账】),人数,价格BigDecimal初始为0)保存==>修改桌台状态tableStatus( FREE:空闲 USER:开桌 lOCK 锁桌)
同时下面需要通过tableId再次查询订单order对象==>定义一个处理当前订单明细的方法(计算价格),从数据库中根据orderNo(订单编号)查询出订单明细:如果不为空根据dishId查询出附件(affixo),调用stream中的归并运算计算价格总额;同时也需要计算redis中的明细(业务前缀+订单号 RMapCache结构);最后分别返回明细和总金额。
我猜你会问到:
①为什么要使用分布式锁?Synchronized不能实现?使用分布式锁需要注意什么?
- 为了保证并发访问共享数据时,同一时刻被一个线程使用,保证数据的一致性
- 分布式架构,服务是集群部署的,每个服务部署在不同的JVM上;Synchronized是基于JVM的,无法保证分布式访问的都是同一把锁;
- 如果释放锁的时候释放失败, 锁设置过期时间!!!调用tryLock(等待时间,过期时间,单位)等待时间略大于过期时间
②你是怎么理解幂等性的?
访问同一个URL,无论多少次请求,得到的结果都是一致的,主要在并发新增,删除
防止重复创建订单,开桌的实质就是创建订单;
③说一说你对redisson分布式锁原理的理解
- 所谓的加锁就是在redis中存值,我们采用过期时间的方式(默认三十秒)
- 获得锁成功之后执行自己的业务逻辑
- 业务逻辑执行完成之后就会释放锁
看门狗机制:会为当前主线程续期,延长时间所以业务代码中我们必须手动释放锁;
设置过期时间是为了防止出现手动释放锁失败的情况,过期时间结束了就会释放
4.3短信通道的申请
短信包含签名,模板相关内容,在发送短信之前还需要对短信的渠道进行开通,我主要负责短信通道向三分平台(腾讯,阿里,百度)的申请,以及此模块的增删改查;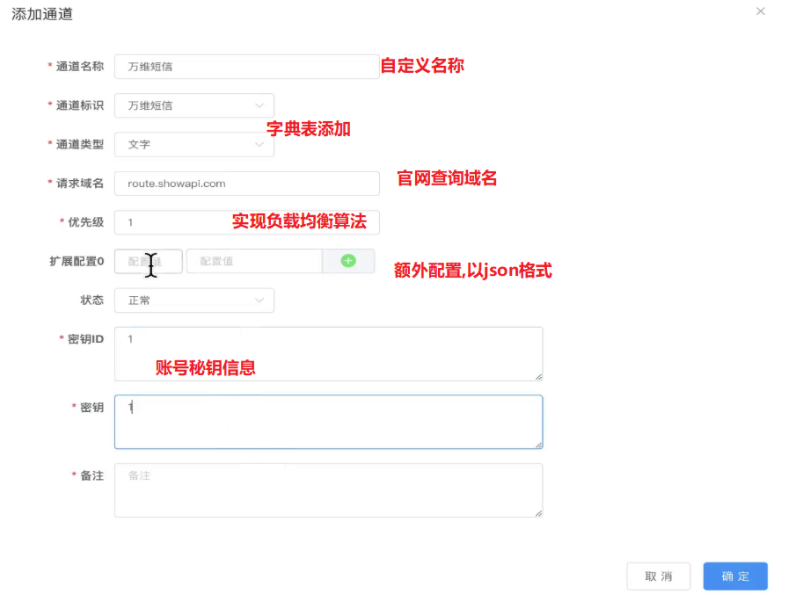
业务描述:
前端填写表单,完成通道的申请(修改和添加功能基本相同):
①先添加渠道名称去数字字典表(子项键保证唯一,选择的是descrption字段)
②当我们点击短信通道模块编辑时,就会向字典表查询父项键,字典表中的渠道描述就都展示了
③渠道中我们填写表单(根据三方渠道信息设计):名称,选择标识,域名(BAT提供),优先级(保证负载均衡算法),扩展配置(以json格式存储:otherconfig),秘钥和秘钥id
④由于对配置信息使用频繁,存入redis中
具体实现:
①先引入三方BAT配置短信的依赖,用来创建对应的对象信息
②每次添加,修改,删除都先操作数据库,然后操作redis(String格式,sms:+渠道名称)
③新建通道的时候都创建一个对应通道的配置类(Client对象,阅读官方文档),以后发送短信,创建模板和签名
4.4 用户对购物车的操作
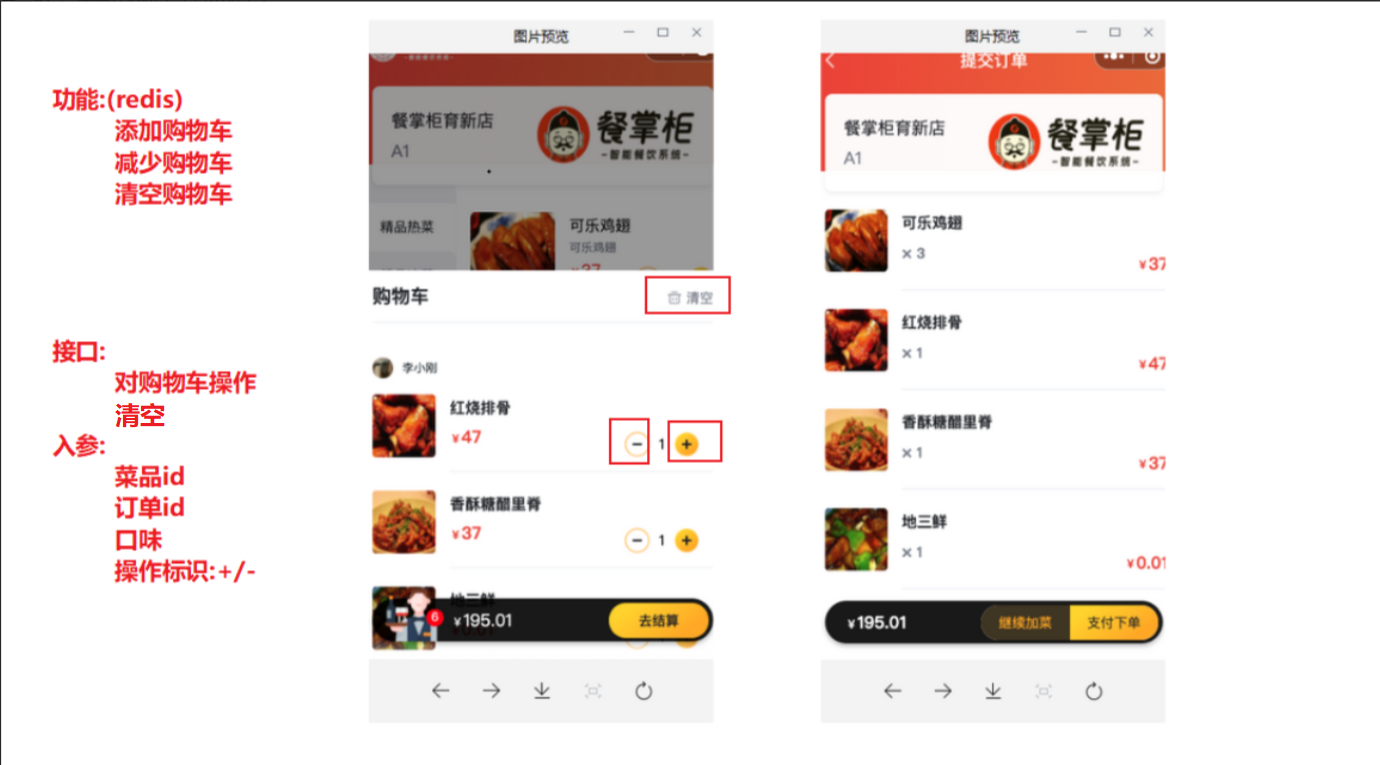
业务描述:用户通过添加/减少菜品来操作购物车,传入dishId,OrderNo,口味,标识
实现流程:
由于对购物车的操作比较频繁我们使用redis做缓存,同时多并发的情况下,由于数据库可重复读隔离级别,会出现超卖(销量大于库存);所以我们需要借助Spring的生命周期注解@PostConstruct注解完成起售菜品的数据同步到redis中:RAtomcLong key为业务前缀和dishId,值为数量完成预扣方案,redisson中的原子类操作对象atomicLong能保证(并发情况下,保证线程安全的,数据一致)
在操作订单之前需要加分布式锁(String类型),多处操作库存:点餐扣库存,后台更新菜品的库存。通过业务前缀+dishId从redis中获取存储好的菜品数量,根据前端的+/- 来判断是添加还是移除购物车:参数dishId,OrderNo,口味,atomicLong
添加:先减redis库存(完成预扣),atomicLong.decrementAndGet() >= 0不够归还库存,够了扣减mysqal中的内存(扣减失败,归还内存抛出异常);根据业务前缀+订单编号(orderNo)作为大key获取(RMapCache对象)根据dishId(小key)去redis中查询订单明细判断如果为空,说明第一次添加构建orderItem(与数据库明细格式保持一致,方便后期合并)将数据更新到redis中;不为空直接明细数量+1即可
减少:先添加mysql库存,再根据dishId查询出redis中的订单明细,如果不为空进行操作:dishNum>1对其减一,如果为1直接移除即可;最后在添加redis中的菜品库存(atomicLong.incrementAndGet())
①你还了解哪些解决超卖的方案?
- 从本质数据库出发:加乐观锁==>数据库压力变大
当前用户在读取数据时,给数据添加版本号,在修改数据时版本号加1,
其他用户读取时版本不一样,无法操作,重新读取数据
- 分布式锁
当前用户拿到锁之后,才能操作数据库,其他用户只能等待其释放锁
- redis库存预扣
②删除菜品:先删除mysql,后删除redis?
先操作数据库,后redis;redis操作错误,抛出异常,catch中抛出异常,
@Translation mysql中数据回滚;redis事务基础队列,不受spring管理,无法回滚
③库存扣减的时机?
商家角度:下单扣减库存==>不会占有库存,下单不一定买到(jd,淘宝)
消费者角度:加购物车扣减==>下单一定能买到,商品滞销(唯品会)
解决:
前端:按钮禁用,黑名单
后端:延时队列
4.4.2 对购物车的优化
问题描述:当前如果客户出现加入购物车不下单,会出现库存被占用。通过SpringCloud Stream 消息驱动集成RabbitMq,通过安装mq中的延时插件来实现超时未支付情况
定义生产者:将dishId,roderNo存放到map中,转为json格式,注入mq对象调用output().send()给.setHeader(“x-delay”,过期时间)
定义消费者:获取到dishId回滚数据库中菜品库存,如果回滚失败直接抛异常;回滚redis库存(这里如果回滚错误了,一定要抛异常,否则mysql无法回滚);删除购物车中对应的菜品;
2) 时头条
1.Admin运营端记录运营管理人员增删改频道和敏感词日志记录
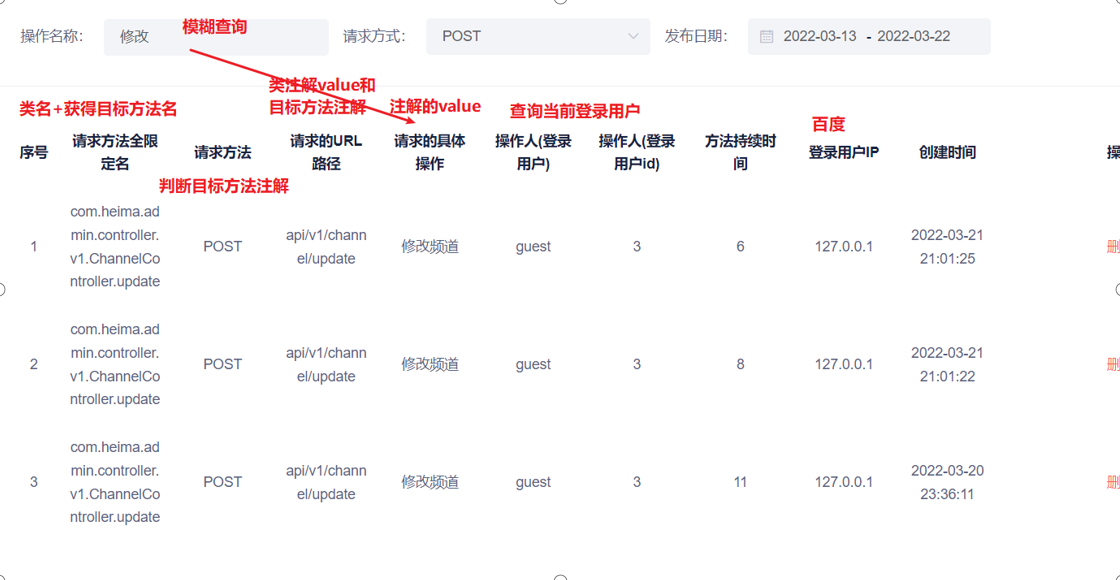
功能描述:当管理人员对频道,敏感词进行操作时,对其行为进行动态记录(请求的全限定名,请求方法,路径,具体的操作,操作人,操作人id,持续时间,用户ip,修改时间)并且显示到操作日志模块上,我们可以对其名称进行模糊查询,方式精确匹配,和时间范围查询
实现流程:
①由于Spring为我们提供了AOP功能,我们通过@EnableAspectJAutoProxy开启
②自定义一个注解,分别给频道模块,敏感词模块的增删改方法加上此注解
③有了注解之后我们便可以通过自定义切面@Aspect+@Component,自定义切入点表达式,拦截当前controller包下的所有方法
④通过自己定义的环绕通知,传入的proceedingJoinPoint对象,pjp.getSignature()获取方法签名(通过此签名获取目标方法信息),pjp.getTarget().getClass()获取当前目标类的Class对象,
⑤然后判断目标方法上面是否有自定义的注解,有进行记录操作获取相关参数封装到存入log表中;无的话pjp.proceed()直接调用切入点方法,不用增强;
遇到的bug:切入点返回值一定要(proceed= pjp.proceed())return,不然表达式扫描的方法无法正常运行,比如登录功能;
2、自媒体端文章发布、修改、删除文章功能模块开发
需要加事务,本地事务即可,没有跨库
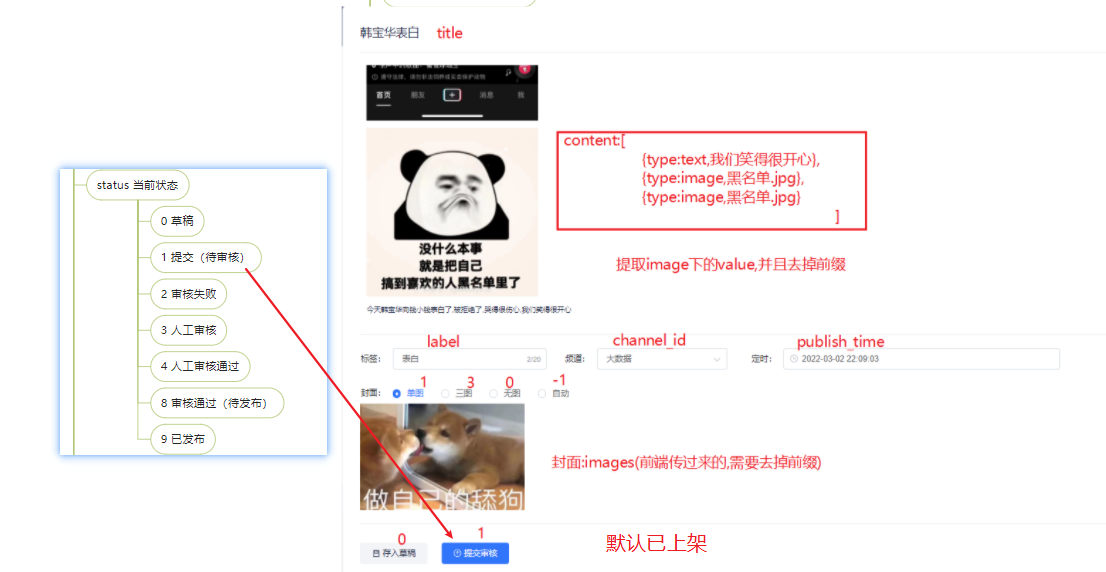
功能描述:自媒体人发布文章:title,content【type有两个取值:text,image】,标签,频道,发布时间,封面(1单图,3三图,0无图,-1自动:数据库的类型为unsigned不能为负数),status(0草稿,1提交待审核)
文章表,素材表,中间表
实现流程:
①参数校验:文章内容,标题不为空,用户是登录状态(登陆时网关的全局过滤器,拦截当前用户存放在了TreadLocal中),转换成WmNew对象;判断标题图片是否选用了自动生成==-1,同时去掉前端穿过来图片的前缀,使用“,”拼接(Stream流中的收集方法.joining(“,”))方法
②存储数据:补全必要参数(user_id,设置默认已上架:1,0是下架)==>判断是否第一次保存(id是否为null),第一次保存,直接保存;不是第一次,先删除文章;如果是草稿,直接返回不用处理关联关系
③处理图片和素材的关联关系:
内容中【type:image,type:cotent】:获取内容中的图片url,去重收集到集合中
根据集合中的url以及当前登录用户的id去查询素材表,获取自己素材的id集合
判断素材不能为空,素材集合大小不能小于id集合,批量插入(关联表:素材id,文章id,引用类型(0文章,1封面))
封面:
选择单图,多图,无图==>判断如果有图转为字符串,服用内容图片保持关联关系的方法,保存封面和素材关联(1封面)
选择自动生成(根据封面的图片数量) :
size > 0 && size <=2(单图截取一个)同时修改wmNew中的tpye为1(之前设置了null)
如果 size 数量大于2 设置为多图 , 截取素材url集合中的 3个作为封面,设置type为3
tpye无图设置为0
修改wmNew表中数据
处理关联关系
3、Admin运营端文章列表的自动审核
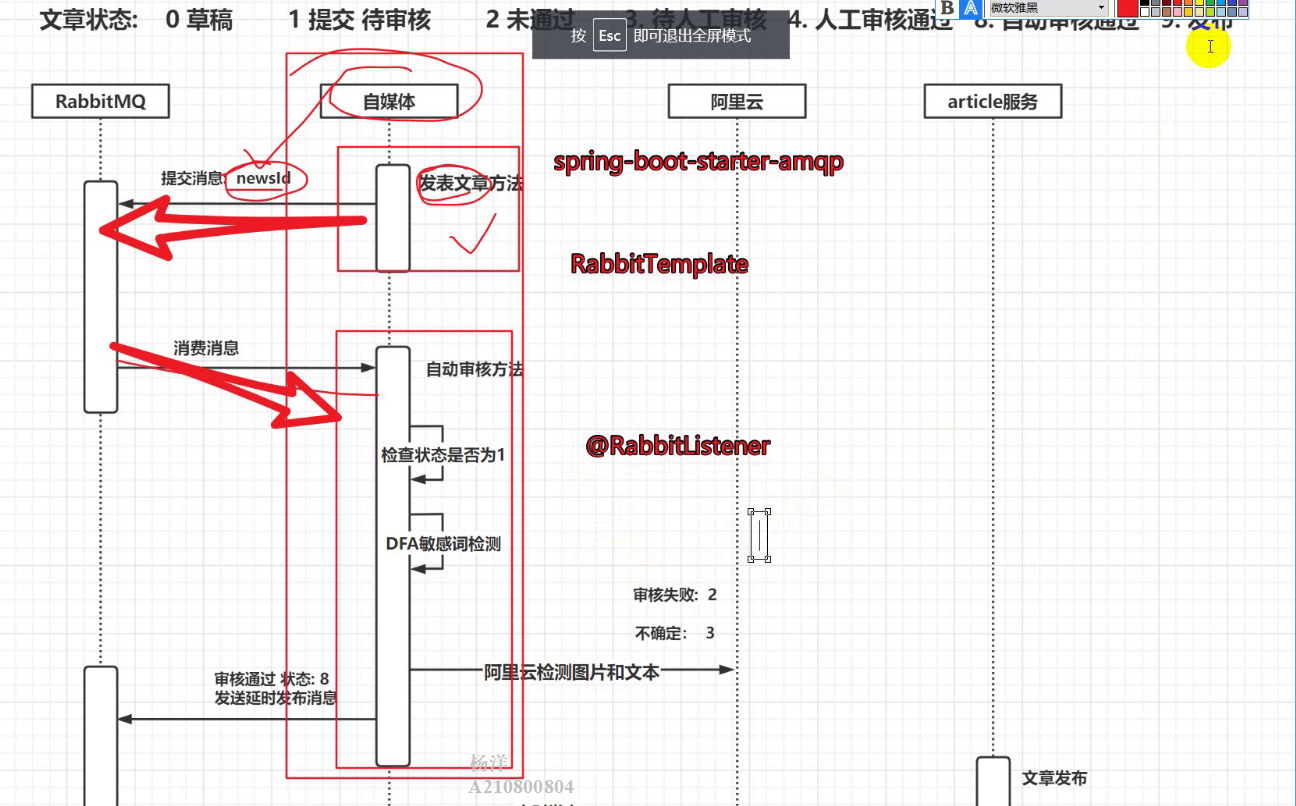
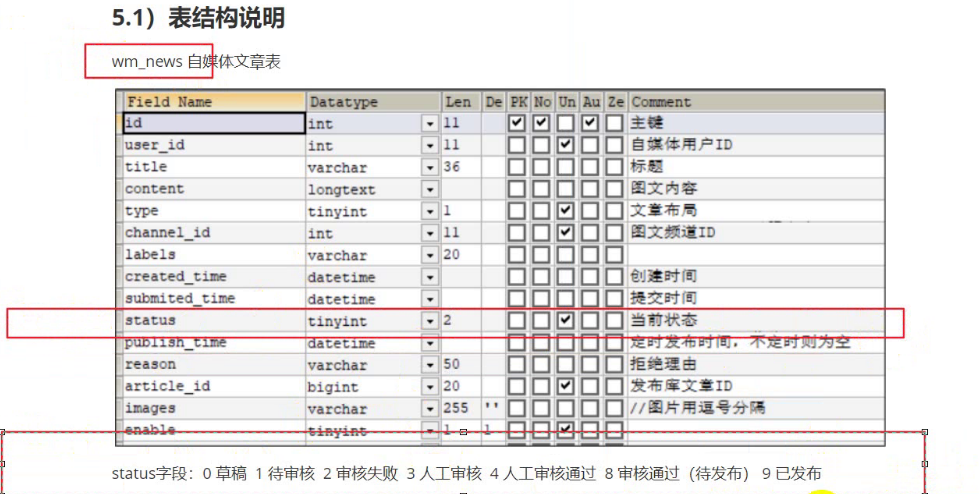
业务描述:自媒体人发布完消息后,调先调用我们项目中维护的敏感词(DFA算法实现快速查找),然后对接阿里云的文本与图片校验,判断是否有违禁词与不合法图片(涉黄,涉政,log,二维码,…)如果通过文章状态改为8,否则改为2
具体实现:
①在发布文章完成后,通过rabbitMq异步调用自动审核的代码(确保消息保证可靠性,与解耦避免级联失败),传入文章id(消息生产者)
②消息消费者:接受到文章id,校验文章id是否为待审核(1),保证幂等性,防止之前文章已经审核过。查询文章对象
将文章内容和图片封装为Map集合,JSON.parseArray(contentJson, Map.class)json格式的转换为Map类型的集合,文本:内容+标题 图片:标题+内容(需要拼接上website前缀和去重)
处理敏感词:先通过feign调用admin端的服务查询敏感词,如果匹配到敏感词将文章状态设置为2,并且返回。调用阿里云的文本扫描,传入文本内容,获取suggestion值:block违规,修改文章状态为失败;review待审核,修改文章状态为人工待审核;pass通过,继续执行
处理图片:调用阿里云处理图片,逻辑和铭感词基本一致
如果都通过了设置文章状态为待发布(8,定时发布)
盲猜你会问:
如何确认消息的可靠性?发消息使用mq的好处是什么?
我们通过自定义配置类实现InitializingBean,SpringBean的声明周期接口,代表完成bean装配后执行初始化方法。注入rabbitTemplate对象设置发送确认回调方法:rabbitTemplate.setConfirmCallback,保证消息能发送到交换机。设置消息返还回调方法:rabbitTemplate.setReturnCallback,确认消息路由到队列;
使用mq帮助我们解除了不同业务之间的耦合性,同时也避免了可能由于审核文章失败导致发布文章失败的级联失败问题。
使用RabbitMq保证消息可靠性需要注意什么?
需要我们在配置文件中手动开启,消息发送确认机制和消息返还机制。同时为了避免无限重试,我们需要配置最大充实次数,和时间因子,避免无限重试和给我们解决问题时间。
项目是如何集成阿里云文本图片检测的?
导入阿里云文本,图片扫描的依赖,自定义配置类@ComponentScan(“com.heima.aliyun”)当前包下的两个工具类,通过spring的自动装配机制,创建META-INF下面的spring.factories文件,写上全限定类名
说一下DFA算法?
通过Map集合的方式,最外面一层为第一个字,里面嵌套了isEnd字段,如果值为0说明不是敏感词,如果值为1说明为组成了敏感词;相同的key唯一,基于hash结构搜索的效率很快;比传统的字符串比较效率快很多。
有没有遇到什么bug?
因为文章拼接文本,需要进行我们自定义基于DFA算法敏感词过滤,拼接的过程中需要拼接特殊字符,不然可能会出现误判的情况。比如:你今天很美国家很伟大。如果美国是敏感词,就出现了误判。
4、App用户端文章的海量搜索设计,以及文章及时同步问题?
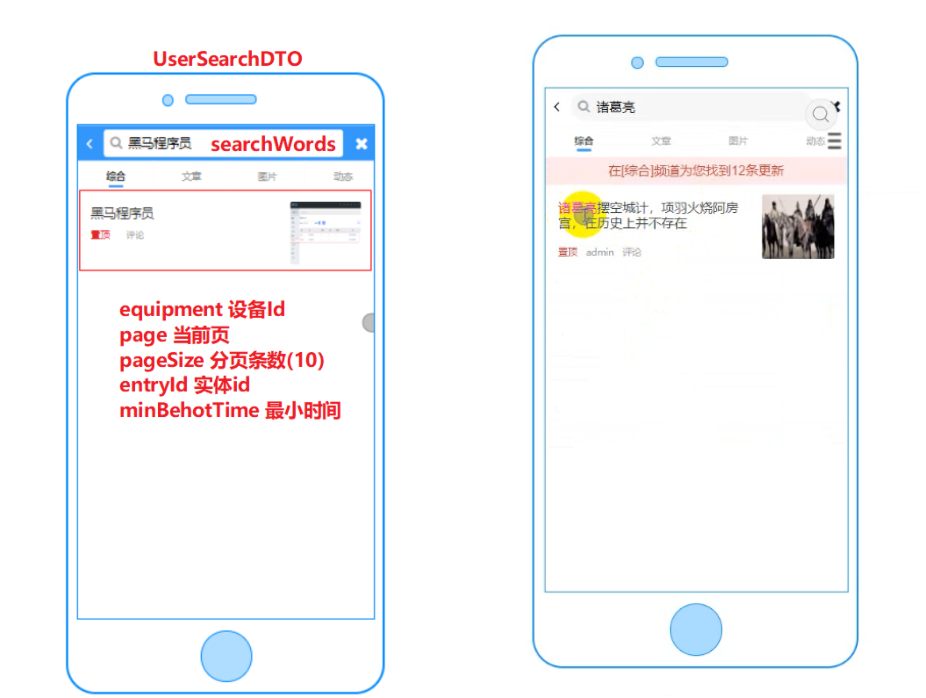
业务描述:mysql在搜索文章标题的时候需要用到模糊查询,前后加上了%%,mysql的数据库索引会失效,全表查询,所以我是使用es:使用倒排索引,根据搜索内容分词得到新的分词,去查询文档id,根据文档id查询对应编号文档,海量数据完成快速搜索。同时利用rabbit mq 在发布文章(下架自媒体文章),发送消息给es所在的服务,在es所在的服务监听完成上下架同步操作。
实现流程:
①前端传递:设备id,当前页,分页条数,最小时间;其中title和发布时间需要共同满足查询。构建BoolQueryBuilder对象,titile需要算分boolQuery.must方法,发布时间boolQuery.filter方法(通过发布时间实现翻页,小于当前页码的最小时间),sort方法实现按照发布时间排序,构建分页条件。构建高亮条件(哪个字段,前置标签,后置标签):highlightBuilder.preTags(““),postTags(““),field(“title”)
②执行查询,获取结果,拼接静态页面详情(fremarker+minio实现)的前缀地址;给图片添加上url前缀,返回结果
③同时在下架文章以及审核通过文章模块,通过mq发送文章id。搜索服务监听消息查到文章消息存入到es中。
你不问我不说:
说一下es采用倒排索引的原理?优势有哪些?
倒排索引由文档(每一条数据就是文档),词条(文档照语句分成的词语)组成,生成对应的文档id。当我们搜索词时会进行分词,得到每个分词的id,根据id查到所有的文档。比如:搜索华为手机,分为 华为(2,3)和手机(1,2),就回去文档中查询id为1,2,3的数据,包含了当前词的都会被查询出来;海量数据能帮助我们快速查询。
构建索引库,有什么注意条件?**
将不需要搜索条件的字段:images,staticUrl,tpype类型设置为keyword,index为false;需要分词搜索的title,type类型设置为text,analyzer(ik_max_word最大分词)分词方式设置为ik_smart最小分词。
3)国盛证券-金睛智投
1、账号密码与验证码登录功能
项目描述:当我们进入登录页面时会调用生成验证码的接口,用户通过输入账号和密码以及验证码校验正确,即可完成登录。
实现流程:
①生成验证码:模仿传统的cookie和session机制,因为我们在前后端的情况下session无法共享,特别时集群部署的时候。所以我们使用redis的String结构,我们要保证key唯一(类似session的jsonId):生成唯一id基于雪花算法,value就存入验证码即可,并设置过期时间,验证码通过commons-lang3提供的类生成。
②校验登录,先校验验证码(减少数据库I/O)。然后查询数据库,通过我Spring security提供的BCryptPasswordEncoder方法采用SHA-256对密码进行加密以及校验。matches方法判断密码是否正确,正确即可放行。
2、涨幅榜数据导出功能
功能描述:通过页面提供的导出数据按钮,完成当前页的数据导出
实现流程:
①我们是通过response对象以流的方式响应数据给前端,设置响应格式,编码,文件格式的响应头
②查询当前页的数据,通过gson.fromJson(gson.toJsonTree(当前map),对象的Class对象),快速将map转为对象
③调用easyExcel.write方法响应给前端(通过注解格式化日期,指定字段的名称等)
3、个股日k线图展示功能
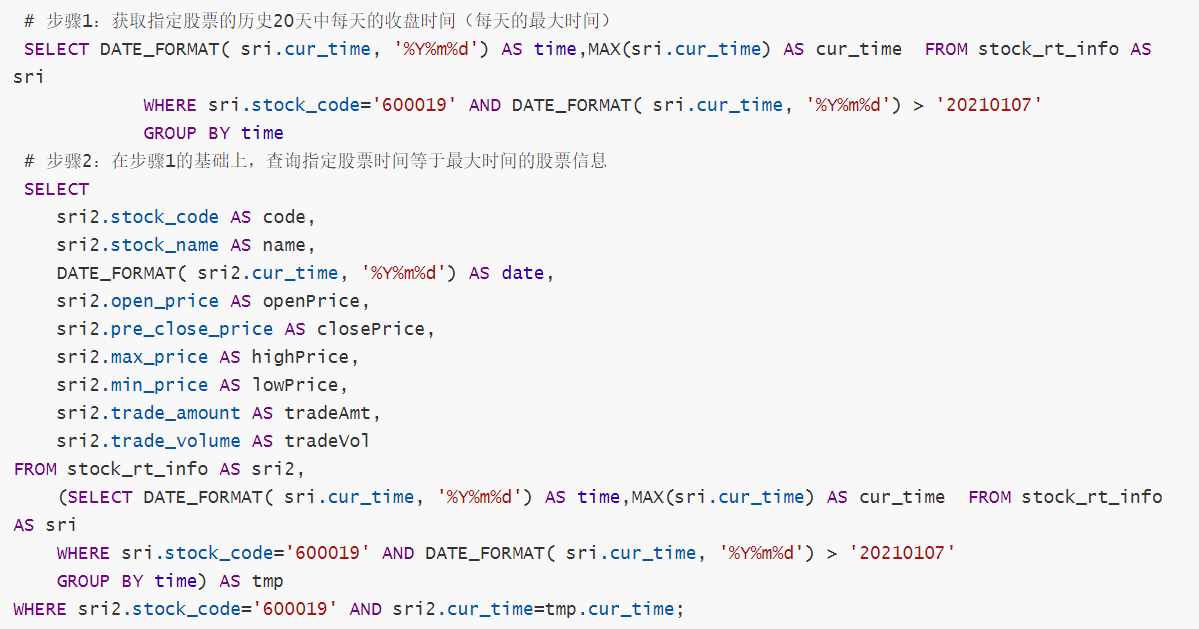
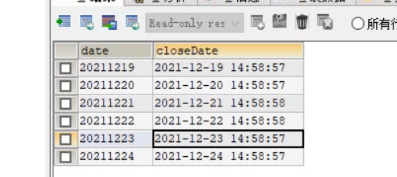
面临的问题:如果当前时间还已到闭盘时间,我们正常查询便可。但是如果还未到闭盘时间(交易量,最低价格,最高价格,交易金额应当查询最新数据),一天有多条数据我们该如何处理?
实现思路:
①先通过查询指定股票的历史20天中每天的最大时间:max时间 条件:大于指定时间,指定股票,再按当前天分组==>得到了最大时间(可以作为闭盘时间)作为临时表
②与原表股票信息表进行关联查询,当前表的时间和临时表的时间相等添加当前表的code码,完成查询
4、对接第三方股票平台,定时获取最新股票数据功能
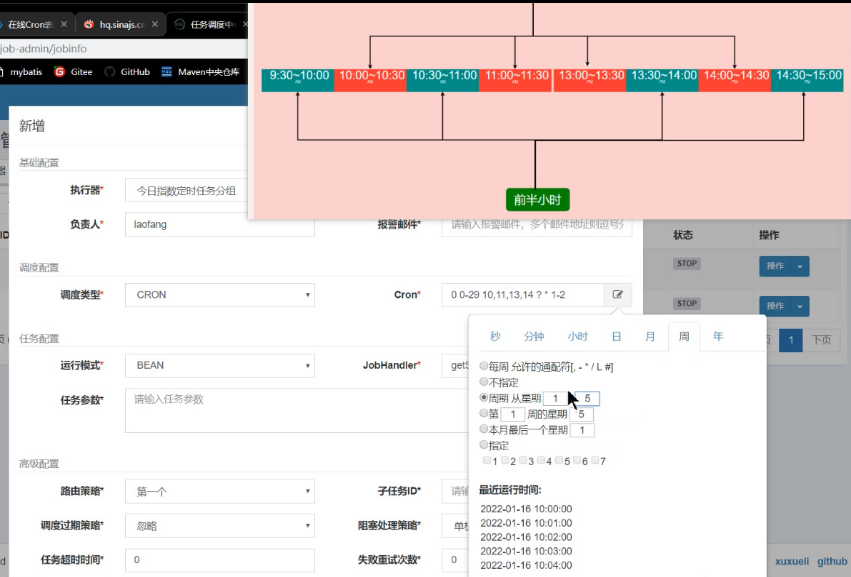
项目描述:通过xxl_job定时执行拉取三方(新浪)股票数据,并且通过线程池批量插入到数据库中
实现流程:
①项目集成xxl job,编写cron表达式,通过rabbit Tamplate 完成股票大盘(上海,深圳),实时数据的拉取,国外国内股票的实时数据
②获取国内外股票数据:先查询出所有股票id集合,然后判断以0开头(深圳),以6开头(上证)给id拼接上sh/sz,然后通过gugua为我们提供的Lists.partition(ids,100)同时配合线程池并发执行拉取和插入任务,大大的提升了效率

若有收获,就点个赞吧
0 人点赞
