WordCountMapper
package com.mapreduce;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;/** KEYIN:行首的偏移量,LongWritable(相当于java的long类型)* VALUEIN:分片后的文本内容,Text类型(相当于java中的string)* KEYOUT:输出的key,为一个单词(Text类型)* VALUEOUT:输出的value(都是1,记作{"word",1},数字类型IntWritable(java中为int))*/public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text outkey =new Text();private IntWritable outvalue=new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1、把输入的文本(value)分割成多个单词String data=value.toString();//正则表达式:逗号、句号、空格String words[]=data.split("[,\\.\\s]+");//2、遍历这些单词,将每一个单词都转换成(key,value)for(String word:words) {outkey.set(word);context.write(outkey, outvalue);}}}
WordCountReducer
package com.mapreduce;import java.io.IOException;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;/** KEYIN:reduse输入key(是一个单词,Text)* VALUEIN:reduse输入value(是单词的次数IntWritable)* KEYOUT:reduse输出的key(一个单词,Text)* VALUEOUT:reduse输出的value(单词次数,IntWritable)*/public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable outvalue = new IntWritable();/** key,{value1,value2,...,valueN}* THOUGHTS,{1,1}*/@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum=0;for(IntWritable value:values) {sum+=value.get();}outvalue.set(sum);context.write(key, outvalue);}}
WordCountDriver
package com.mapreduce;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;// hadoop jar xxx.jar demo.wordcount /input /outputpublic class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1.创建job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2.设置jar路径job.setJarByClass(WordCountDriver.class);// 3.关联map与redjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4.设置map输出的键值对类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5.设置最终数据输出键值对类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6.设置输入路径(FileInputFormat)和输出路径(FileOutputFormat)FileInputFormat.setInputPaths(job, new Path("D:\\eclipse\\HdfsDemo\\input");FileOutputFormat.setOutputPath(job,new Path("D:\\eclipse\\HdfsDemo\\output");//FileInputFormat.setInputPaths(job, new Path(args[0]));//FileOutputFormat.setOutputPath(job,new Path(args[1])); //输出路径必须是不存在的// 7.提交jobboolean result = job.waitForCompletion(true);// true:打印运行信息System.exit(result ? 0 : 1); // 0:正常退出 1:非正常退出}}
//本地测试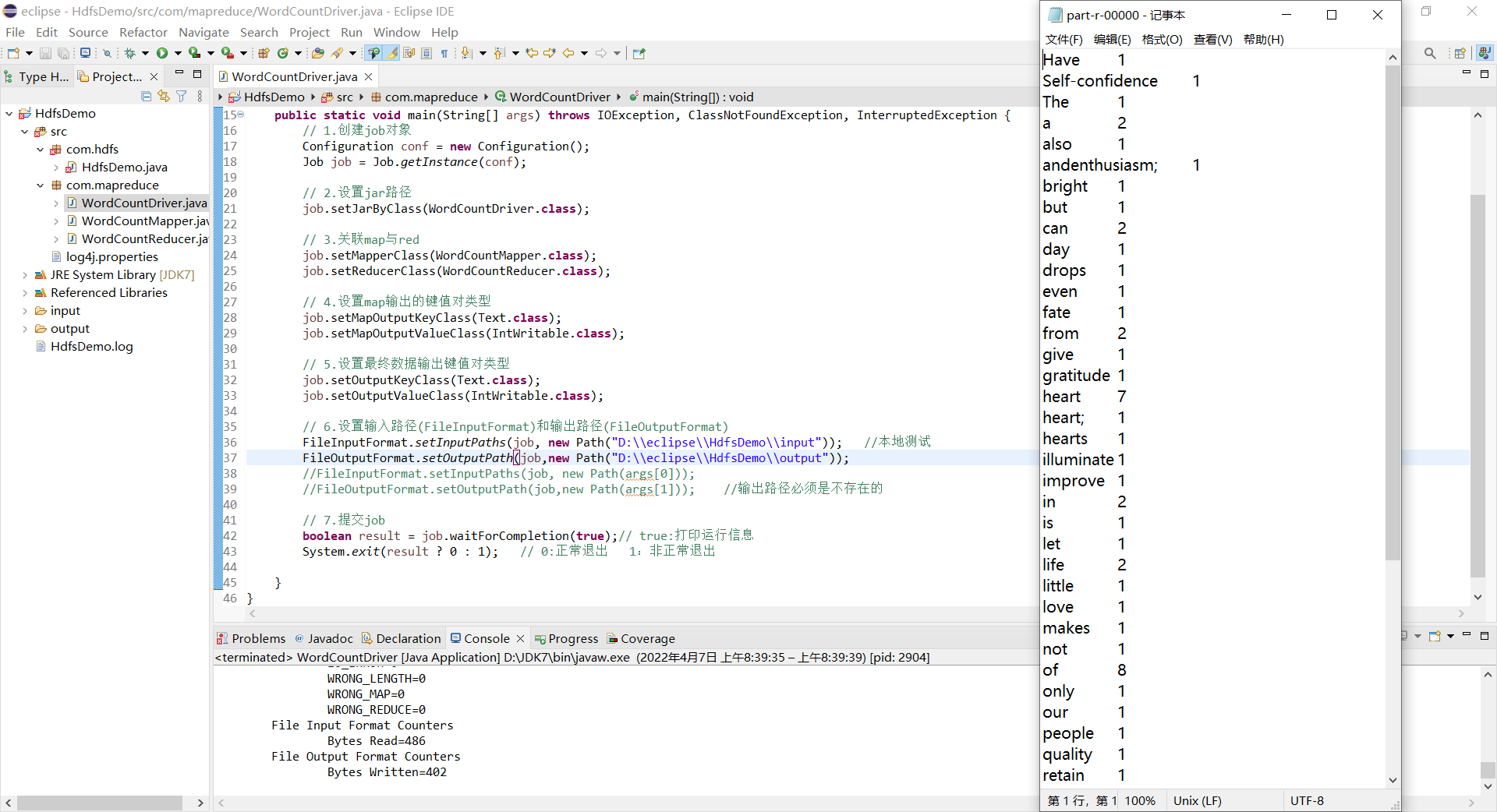
//查看运行结果
hadoop fs -cat /output/part-r-00000
//Hadoop测试
hadoop jar hdp.jar /wordcount /output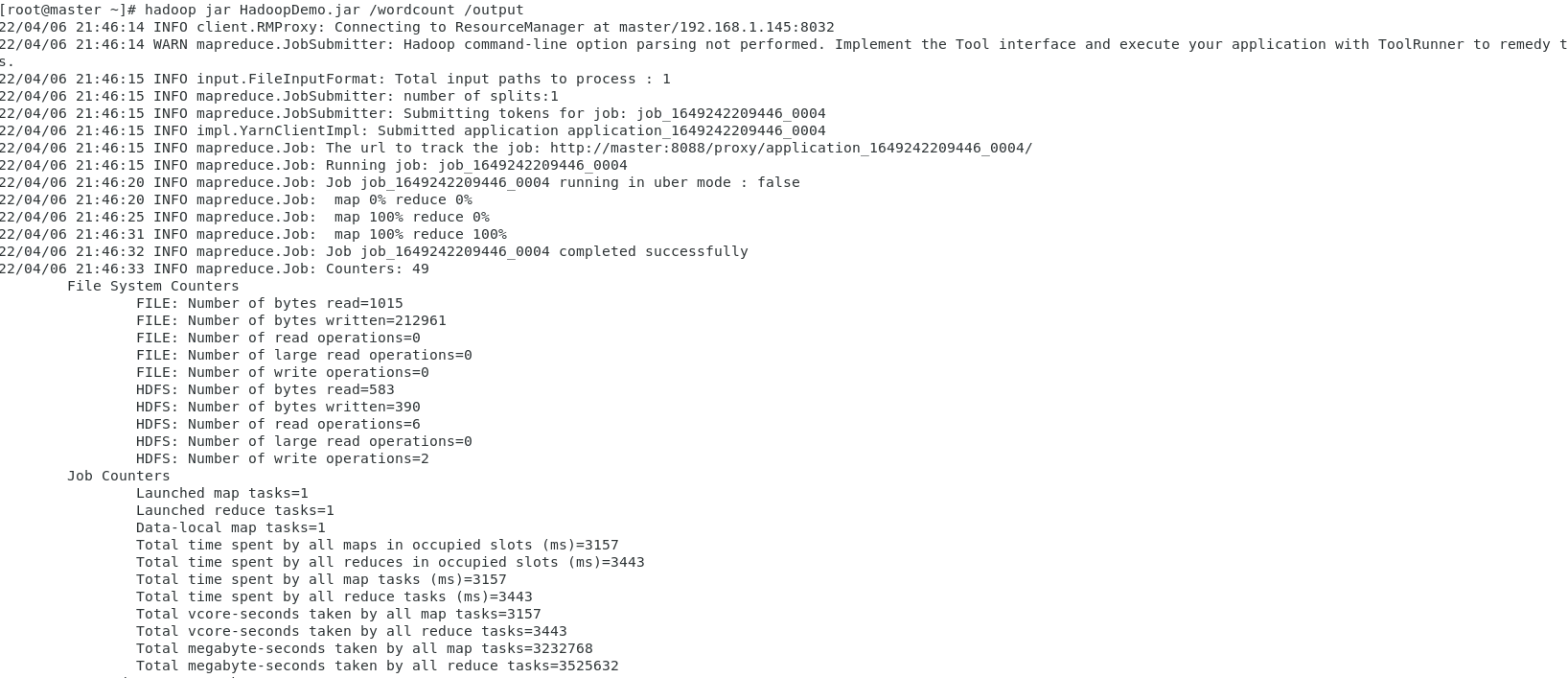



若有收获,就点个赞吧
0 人点赞
