goroutine调度器的由来
单进程的问题
- 单一执行流程, 计算只能一任务一个任务的处理
- 进程阻塞带来CPU时间的浪费
多进程、多线程的问题
- 设计变得复杂
进程、线程的数量越多,切换成本越大,也就也浪费 多线程追着同步竞争(如 锁、竞争资源冲突等) - 多进程、多线程的壁垒 高内存占用及高CPU切换
协程 co-routine的问题
- N:1
- 无法利用多个CPU
- 出现阻塞瓶颈
- 1:1
- 与多线程无异
- M:N
- 可以利用多核
- 过度依赖协程调度器的优化和算法
- 调度器的优化
Goroutine的优化
- 内存占用小 几kb
灵活调度 切换成本低
早期的GO的调度器
基本的全局GO队列和比较传统的轮训利用多个thread去调度
弊端
- 创建、销毁、调度G都需要每个M获取锁,造成激烈的锁竞争
- M转移G会造成延迟和额外的系统负载
- 系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销
GMP模型介绍
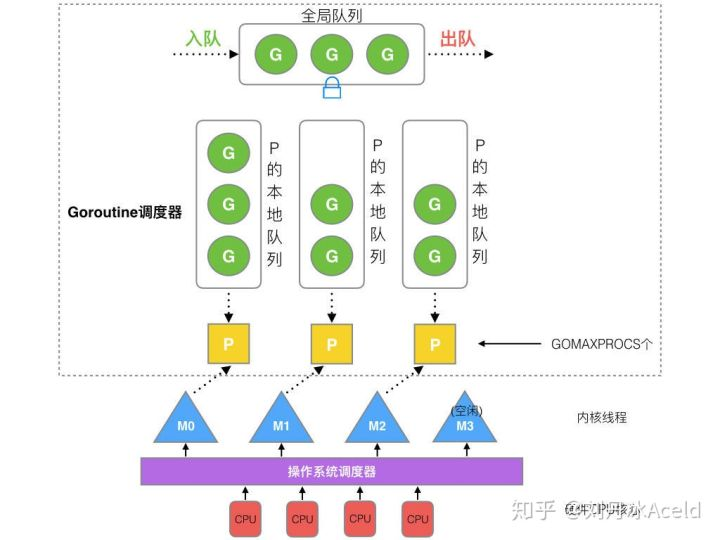
GMP
- G goroutine 协程
- P processor 处理器
- M thread 内核线程
全局队列
存放等待运行的G
P的本地队列
- 存放等待运行的G
- 数量限制:不超过256
- 优先将G放入本地队列,当本地队列满足了之后,才会放入全局队列
P列表
- 程序启动时创建
- 最多有GOMAXPROCS个
M列表
当前操作系统分配到当前GO程序的内核线程数
P和M的数量
- P的数量问题
- 环境变量GOMAXPROCS设置
- runtime.GOMAXPROCS()设置
- M的数量
- GO最大M限制是10000
- runtime/debug包中的setMaxThrads函数来限制
- 有一个M阻塞,会创建一个新的M
- 如果M有空闲,就会回收或者睡眠
调度器的设计思想
复用线程
避免频繁的创建和销毁线程,而是对线程的复用
work stealing机制
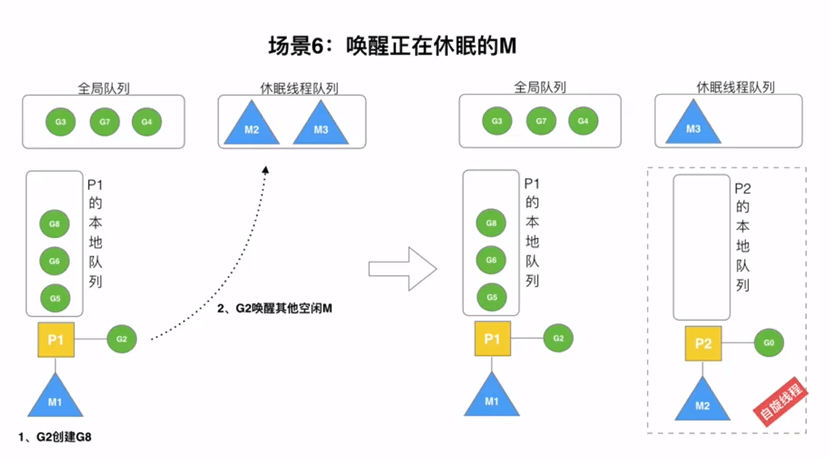
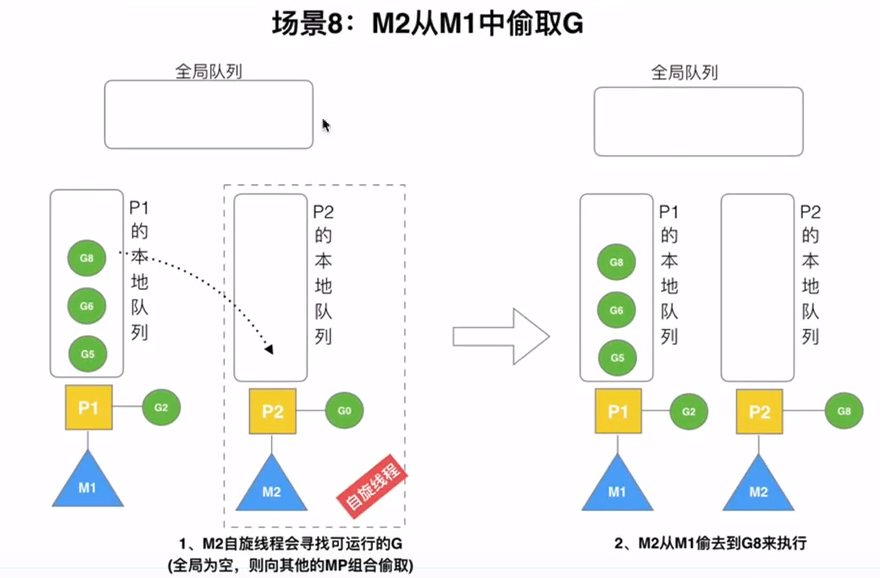
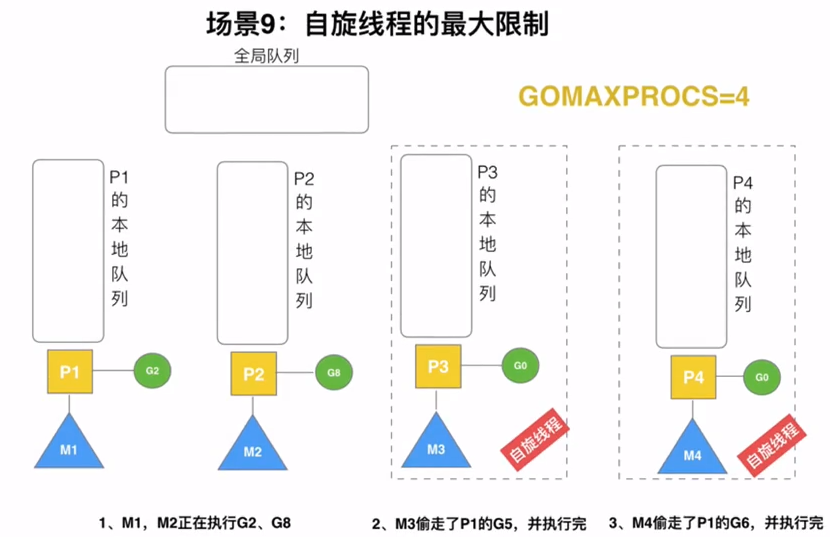
当本线程无可运行的G时,尝试从其他线程绑定的P偷取G,而不是销毁线程(优先去全局P)
head off机制
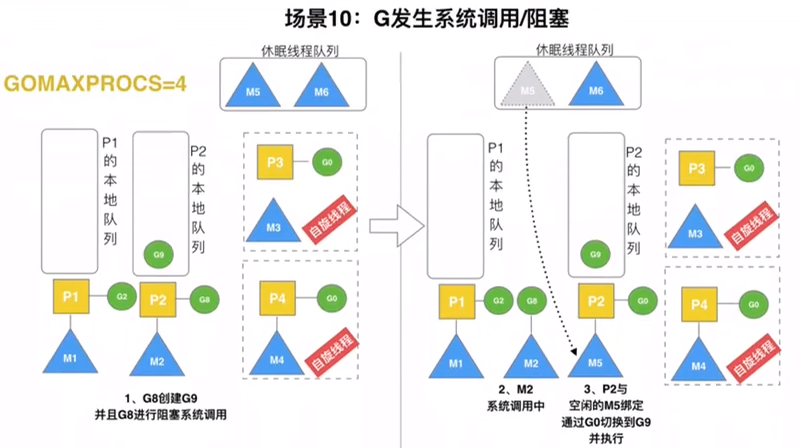
当本地线程因为G进行系统调用阻塞时,线程释放绑定的P,把P转移给其他空闲的线程执行
利用并行
GOMAXPROCS设置P的数量,最多有GOMAXPROCS个线程分布在多个CPU上运行
抢占
在coroutine中要等待一个协程主动让出CPU才执行下一个协程,在GO中,一个goroutine最多占用10ms,防止goroutine被饿死
全局队列
当M执行work stealing从其他P偷不到时,它可以从全局G队列获取G
go func(){} 经历什么过程
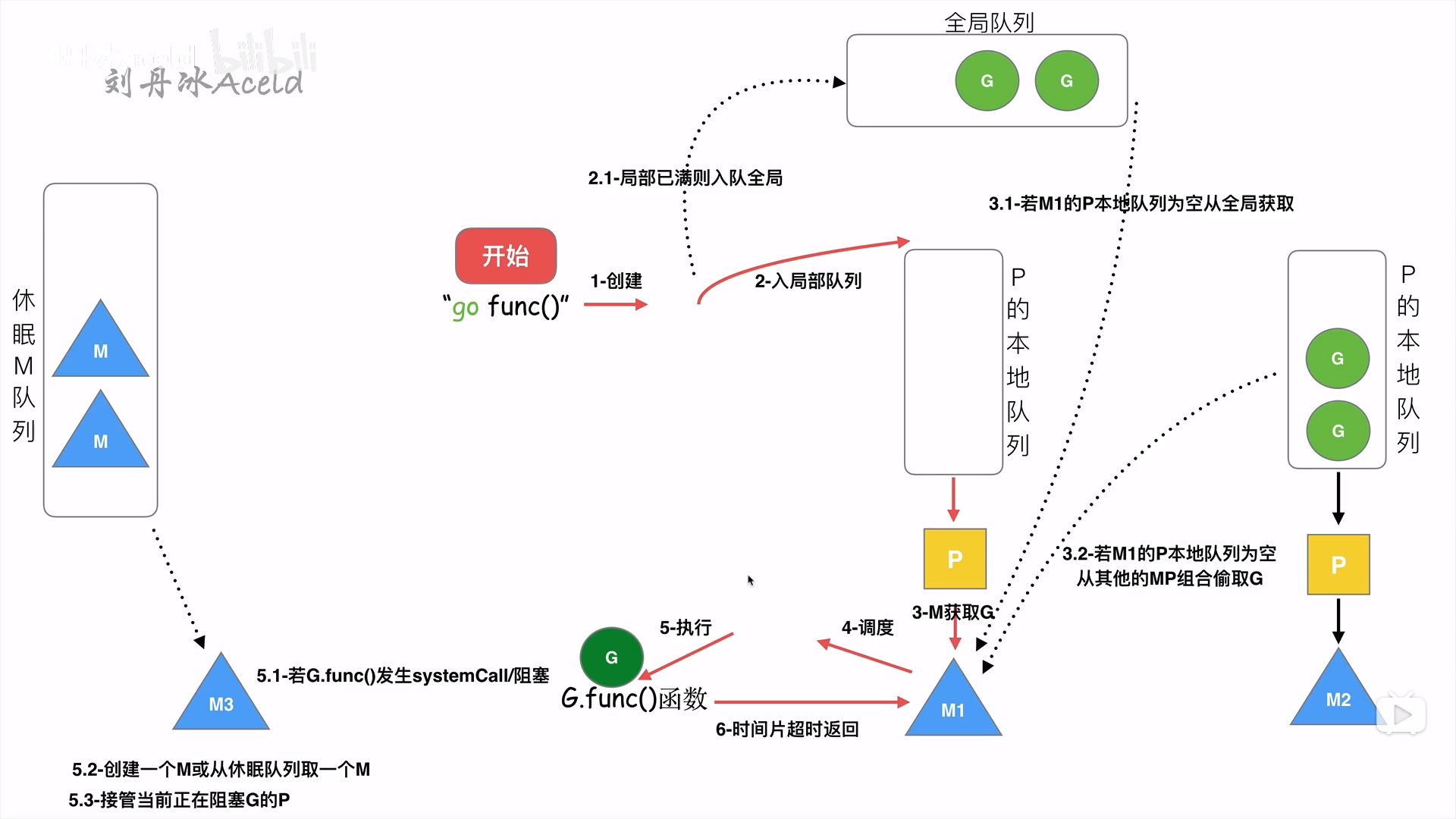
1. go func(){} 会创建一个goroutine
新建的goroutine会优先加入P的本地队列中,如果P的本地队列已经满了就会保存到全局队列中。
G只能运行在M中,一个M必须持有一个P,M会从本地的队列弹出一个可执行状态的G来执行。
一个M调度G的执行过程是一个循环
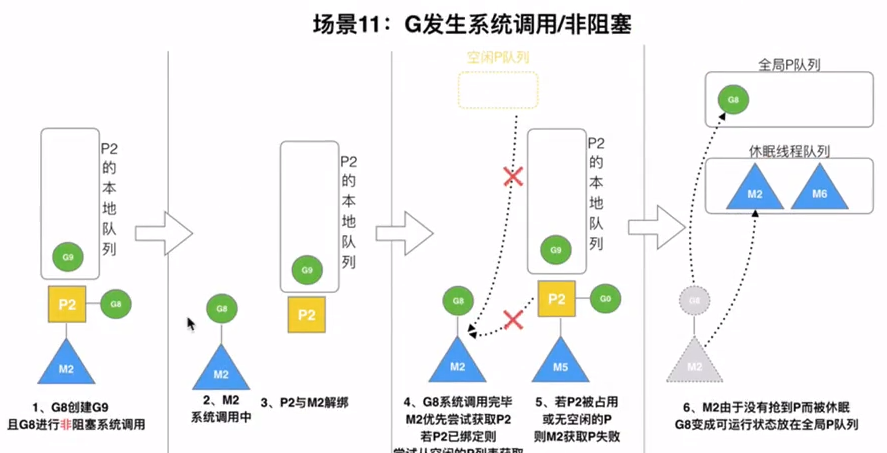
当M执行一个G的发生syscall或者其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除,然后创建一个新的操作系统的线程来服务这个P
当M系统调用结束时,这个G会进入其他的P或者全局队列,M会尝试获取P,如果获取不到,会变成休眠状态
调度器的生命周期
M0
M0是启动程序后编号为0的主线程,这个M对应的实例会在全局便连runtime.m0中,不需要在heep上分配,M0负责执行初始化操作和启动第一个G,在之后M0就和其他M一样了
G0
G0是每次启动一个M0都会第一个创建的goroutine,G0仅用于负责调度的G,G0不指向任何可执行的函数,每个M都会有一个自己的G0.。在调度或系统调用时会使用G0的栈空间,全局变量的G0是M0的G0
GMP调试
go tool trace
func main() {f, err := os.Create("trace.out")if err != nil {panic(err)}defer f.Close()err = trace.Start(f)if err != nil {panic(err)}fmt.Println("GMP")trace.Stop()}
DEBUG trace
GODEBUG=schedtrace=1000 ./可执行程序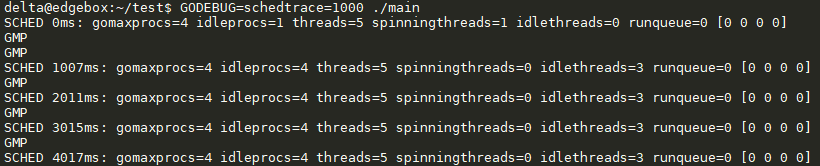
n ms
从程序运行到输出经历的时间
gomaxprocs
P的数量, 一般默认和CPU的核心数一致
idleprocs
处理idle状态的P的数量,gomaxprocs-idleprocs=目前正在执行的P的数量
threads
线程数量(包括M0,包括GODEBUG调试的线程)
spinningtreads
处于自旋状态的thread数量
idlethread
处理idle状态的thread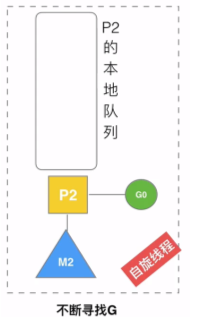
renqueue
全局G队列中的G的数量
[0,0]
每个P的local queue本地队列中,目前存在的G的数量
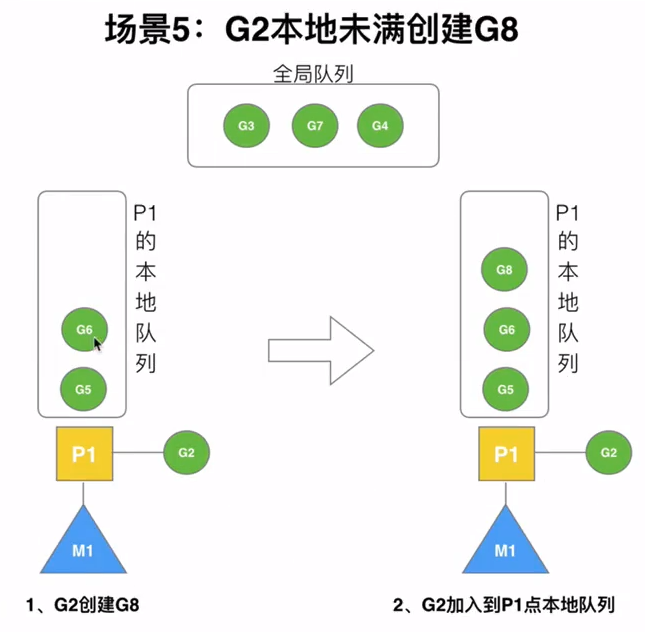
场景分析
G2会优先加入G1所在的本地队列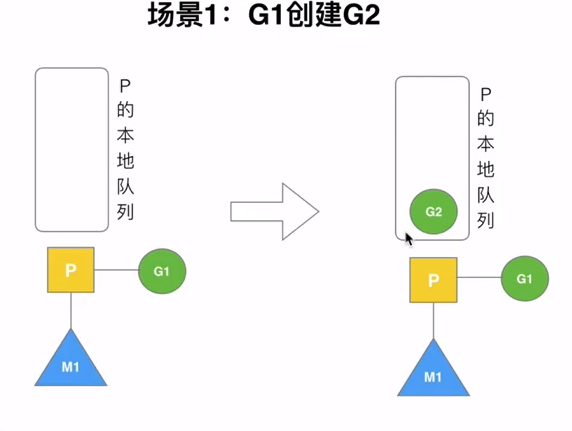
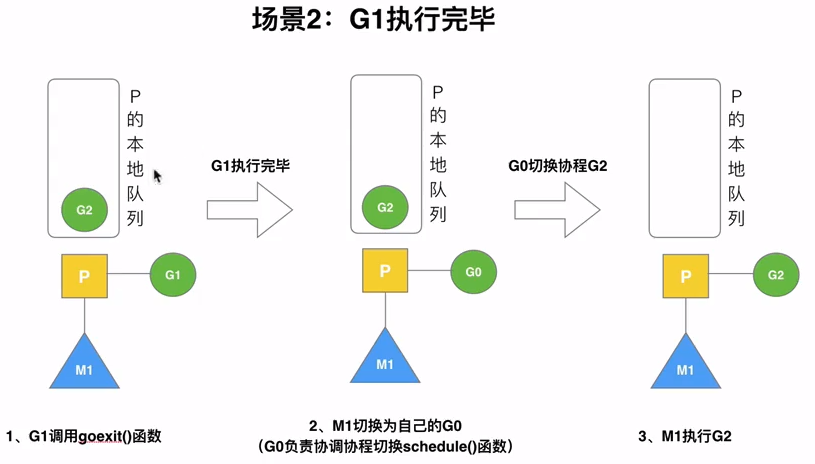
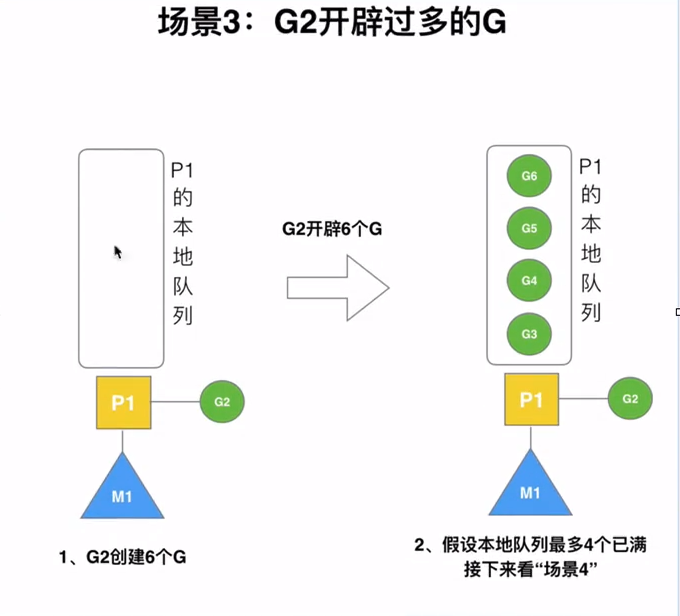
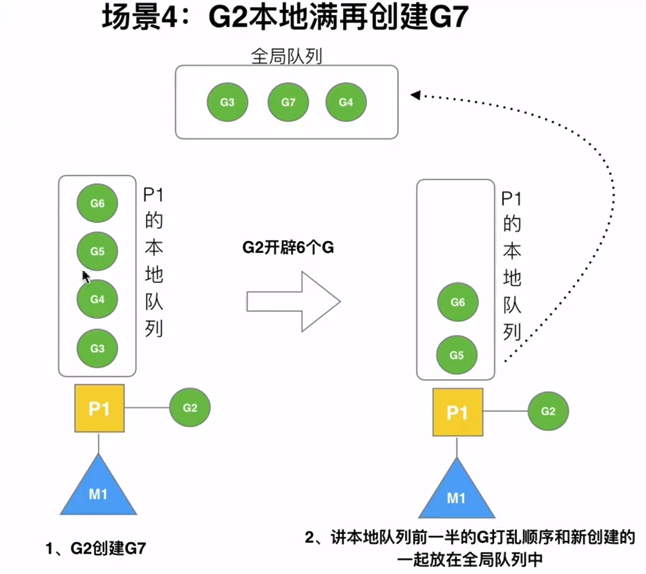
公式: n = min(len(GQ)/GOMAXPROCS+1, len(GQ)/2)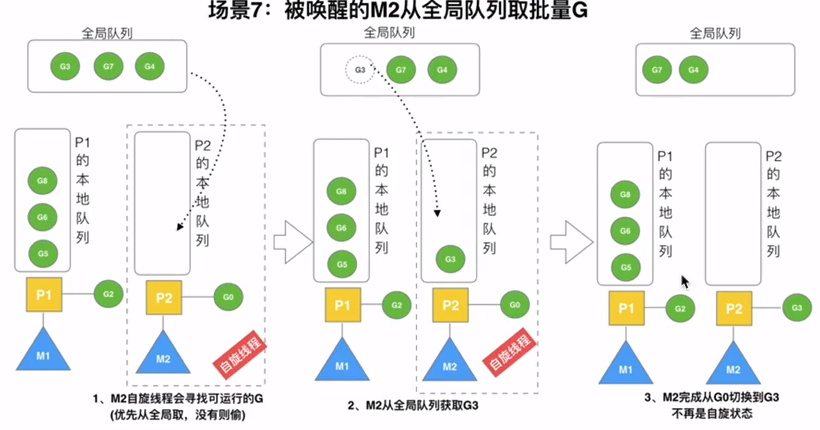

若有收获,就点个赞吧
0 人点赞
