笔记内容选自慕课网《大数据开发工程师》体系课
2.1 什么是Hadoop
- Hadoop的作者是Doug Cutting,Hadoop这个名字是作者的孩子给他的毛绒象玩具起的名字
- 我们生活在一个数据大爆炸的时代,数据飞快的增长,急需解决海量数据的存储和计算问题
- Hadoop适合海量数据,且包含三大组件HDFS(分布式存储)和MapReduce(分布式计算)和YARN(分布式资源管理)
2.2 虚拟机基本环境搭建
# 1、准备一台VMware的CentOS7虚拟机,修改ipvi /etc/sysconfig/network-scripts/ifcfg-ens33# 第一台节点为:192.168.53.100BOOTPROTO="static"IPADDR=192.168.53.100GATEWAY=192.168.53.2DNS1=192.168.53.2# 重启网卡service network restart# 设置第一台主机名称为:bigdata01vi /etc/hostnamebigdata01# 关闭防火墙systemctl stop firewalld# 剔除防火墙开机自启systemctl disable firewalld# 设置公钥,免密登录,一直按enterssh-keygen -t rsa# 查看公钥,私钥文件ll ~/.ssh/# 把文件重定向到自动授权里cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys# 登录无需输密码ssh bigdata01exit# 2、创建文件夹安装jdkmkdir -p /data/soft# 通过sftp把 jdk-8u202-linux-x64.tar.gz 上传到soft文件夹里cd /data/soft# 解压jdktar -zxvf jdk-8u202-linux-x64.tar.gz# 重命名jdkmv jdk1.8.0_202/ jdk1.8# 配置环境变量vi /etc/profile...export JAVA_HOME=/data/soft/jdk1.8export PATH=.:$JAVA_HOME/bin:$PATH# 重新加载source /etc/profile# 检查版本java -version
2.3 单体Hadoop环境搭建
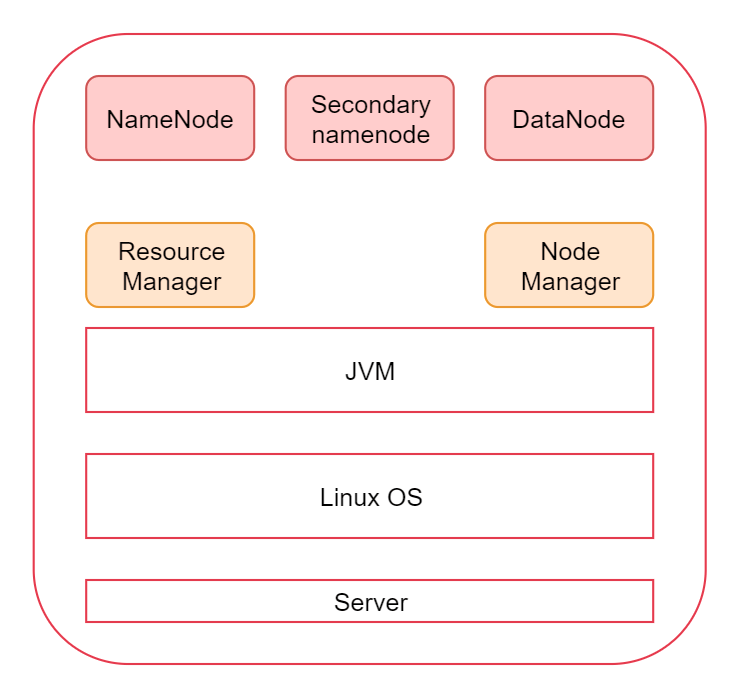
# 安装Hadoop,通过sftp把 hadoop-3.2.0.tar.gz 上传到soft文件夹里进行解压tar -zxvf hadoop-3.2.0.tar.gz# 修改环境变量vi /etc/profile...export JAVA_HOME=/data/soft/jdk1.8export HADOOP_HOME=/data/soft/hadoop-3.2.0export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH# 重新加载source /etc/profile# 检查是否配置成功hdfsyarn# 进入Hadoopcd hadoop-3.2.0# 查看Hadoop文件内部结构drwxr-xr-x. 2 1001 1002 203 Jan 8 2019 bindrwxr-xr-x. 3 1001 1002 20 Jan 8 2019 etcdrwxr-xr-x. 2 1001 1002 106 Jan 8 2019 includedrwxr-xr-x. 3 1001 1002 20 Jan 8 2019 libdrwxr-xr-x. 4 1001 1002 4096 Jan 8 2019 libexec-rw-rw-r--. 1 1001 1002 150569 Oct 19 2018 LICENSE.txt-rw-rw-r--. 1 1001 1002 22125 Oct 19 2018 NOTICE.txt-rw-rw-r--. 1 1001 1002 1361 Oct 19 2018 README.txtdrwxr-xr-x. 3 1001 1002 4096 Jan 8 2019 sbindrwxr-xr-x. 4 1001 1002 31 Jan 8 2019 share#!hadoop目录下面有两个重要的目录,一个是bin目录,一个是sbin目录bin目录,这里面有hdfs,yarn等脚本,这些脚本后期主要是为了操作hadoop集群中的hdfs和yarn组件的sbin目录,这里面有很多start、stop开头的脚本,这些脚本是负责启动 或者停止集群中的组件的。etc/hadoop目录,这里面都是些 xml 文件,用于Hadoop配置信息# 修改Hadoop配置文件,主要修改下面这几个文件hadoop-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xmlworkers# 进入目录cd /etc/hadoop#! 修改第一个vi hadoop-env.sh...export JAVA_HOME=/data/soft/jdk1.8export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop#! 修改第二个vi core-site.xml...<configuration><property><name>fs.defaultFS</name><value>hdfs://bigdata01:9000</value></property><property><name>hadoop.tmp.dir</name><value>/data/hadoop_repo</value></property></configuration>#! 修改第三个vi hdfs-site.xml...<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>#! 修改第四个vi mapred-site.xml...<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>#! 修改第五个vi yarn-site.xml...<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>#! 修改第六个vi workers...bigdata01# 配置完成,还不能启动,需要HDFS格式化,就像买了一块新硬盘需要格式化才能装程序cd /data/soft/hadoop-3.2.0bin/hdfs namenode -format#! 一般只格式化一次,如果想重新格式化,需要移除 rm -rf /data/hadoop_repo/# 修改sbin目录cd sbin# 主要修改一下几个脚本start-dfs.shstop-dfs.shstart-yarn.shstop-yarn.sh#! 修改第一个vi start-dfs.sh...# limitations under the License.HDFS_DATANODE_USER=rootHDFS_DATANODE_SECURE_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root#! 修改第二个vi stop-dfs.sh...# limitations under the License.HDFS_DATANODE_USER=rootHDFS_DATANODE_SECURE_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root#! 修改第三个vi start-yarn.sh...# limitations under the License.YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root#! 修改第四个vi stop-yarn.sh...# limitations under the License.YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root# 启动Hadoop集群/data/soft/hadoop-3.2.0/sbin/start-all.sh# jps:查看Hadoop启动进程11224 Jps10332 DataNode10173 NameNode11086 NodeManager10767 ResourceManager10531 SecondaryNameNode#! 如果启动失败,可以到 /data/hadoop_repo/logs/hadoop 里查看启动日志# 界面测试HDFS webui界面:192.168.53.100:9870YARN webui界面:192.168.53.100:8088# 修改电脑的host192.168.53.100 bigdata01# 进入测试bigdata01:8088# 停止Hadoop集群/data/soft/hadoop-3.2.0/sbin/stop-all.sh
2.4 集群Hadoop基本环境搭建

# 重复虚拟机环境搭建出3台,这三台机器的ip、hostname、firewalld、ssh免密码登录、JDK这些基础环境已经配置ok,分别为「主节点」bigdata01 192.168.53.100「子节点」bigdata02 192.168.53.101「子节点」bigdata03 192.168.53.102# 修改本地电脑的host文件,Mac和Win的路径不同192.168.53.100 bigdata01192.168.53.101 bigdata02192.168.53.102 bigdata03# 修改三台虚拟机hosts,从而可以互相ping通vi /etc/hosts192.168.53.100 bigdata01192.168.53.101 bigdata02192.168.53.102 bigdata03# 添加时间服务器到三台虚拟机,从而实现集群之间的时间同步问题yum install -y ntpdatevi /etc/crontab...* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn# 切到bigdata01服务器,把主节点的公钥拷贝到两个子节点scp ~/.ssh/authorized_keys bigdata02:~/scp ~/.ssh/authorized_keys bigdata03:~/# 切到bigdata02服务器,追加免登陆信息cat ~/authorized_keys >> ~/.ssh/authorized_keys# 切到bigdata03服务器,追加免登陆信息cat ~/authorized_keys >> ~/.ssh/authorized_keys# 切到bigdata01服务器,测试连接到02,03服务器ssh bigdata02ssh bigdata03
2.4.1开始安装Hadoop
# 切到bigdata01服务器,安装Hadoop,通过sftp把 hadoop-3.2.0.tar.gz 上传到soft文件夹里进行解压cd /data/softtar -zxvf hadoop-3.2.0.tar.gz# 修改环境变量vi /etc/profile...export JAVA_HOME=/data/soft/jdk1.8export HADOOP_HOME=/data/soft/hadoop-3.2.0export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH# 重新加载source /etc/profile# 检查是否配置成功hdfsyarn# 进入Hadoopcd hadoop-3.2.0# 查看Hadoop文件内部结构drwxr-xr-x. 2 1001 1002 203 Jan 8 2019 bindrwxr-xr-x. 3 1001 1002 20 Jan 8 2019 etcdrwxr-xr-x. 2 1001 1002 106 Jan 8 2019 includedrwxr-xr-x. 3 1001 1002 20 Jan 8 2019 libdrwxr-xr-x. 4 1001 1002 4096 Jan 8 2019 libexec-rw-rw-r--. 1 1001 1002 150569 Oct 19 2018 LICENSE.txt-rw-rw-r--. 1 1001 1002 22125 Oct 19 2018 NOTICE.txt-rw-rw-r--. 1 1001 1002 1361 Oct 19 2018 README.txtdrwxr-xr-x. 3 1001 1002 4096 Jan 8 2019 sbindrwxr-xr-x. 4 1001 1002 31 Jan 8 2019 share#!hadoop目录下面有两个重要的目录,一个是bin目录,一个是sbin目录bin目录,这里面有hdfs,yarn等脚本,这些脚本后期主要是为了操作hadoop集群中的hdfs和yarn组件的sbin目录,这里面有很多start、stop开头的脚本,这些脚本是负责启动 或者停止集群中的组件的。etc/hadoop目录,这里面都是些 xml 文件,用于Hadoop配置信息# 修改Hadoop配置文件,主要修改下面这几个文件hadoop-env.shcore-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xmlworkers# 进入目录cd etc/hadoop
2.4.2 vi hadoop-env.sh
export JAVA_HOME=/data/soft/jdk1.8export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
2.4.3 vi core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://bigdata01:9000</value></property><property><name>hadoop.tmp.dir</name><value>/data/hadoop_repo</value></property></configuration>
2.4.4 vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
</configuration>
2.4.5 vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.4.6 vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
</configuration>
2.4.7 vi workers
bigdata02
bigdata03
2.4.8 修改启动脚本
cd /data/soft/hadoop-3.2.0/sbin
# 修改hdfs启动脚本
vi start-dfs.sh
...
# limitations under the License.
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 修改hdfs关闭脚本
vi stop-dfs.sh
...
# limitations under the License.
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 修改yarn启动脚本
vi start-yarn.sh
...
# limitations under the License.
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
# 修改yarn关闭脚本
vi stop-yarn.sh
...
# limitations under the License.
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
2.4.9 拷贝配置好的Hadoop到子节点
# 把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点
cd /data/soft/
scp -rq hadoop-3.2.0 bigdata02:/data/soft/
scp -rq hadoop-3.2.0 bigdata03:/data/soft/
# 在bigdata01节点上格式化HDFS
cd /data/soft/hadoop-3.2.0
bin/hdfs namenode -format
# 在bigdata01节点启动集群
sbin/start-all.sh
# 在bigdata01节点验证进程
jps
6128 NameNode
6621 ResourceManager
6382 SecondaryNameNode
# 在bigdata02节点验证进程
jps
2276 DataNode
2385 NodeManager
# 在bigdata03节点验证进程
jps
2217 DataNode
2326 NodeManager
# 在bigdata01节点停止集群
sbin/stop-all.sh
2.5 Hadoop的客户端节点
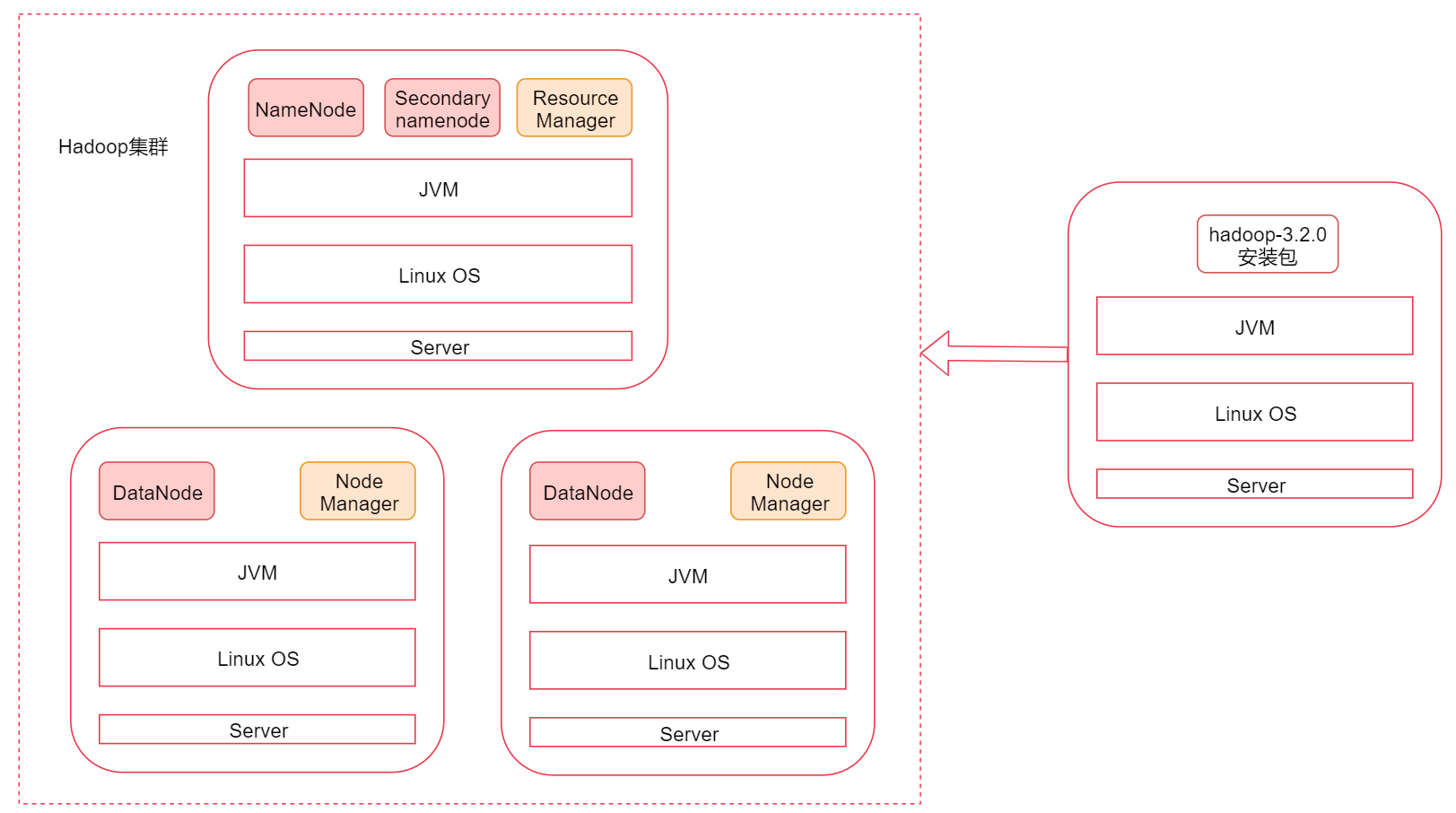
- 在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的
- 建议在业务机器上安装Hadoop,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点
- 类似于Navicat客户端操作MySQL服务,不会对MySQL服务整体运行有什么影响。

若有收获,就点个赞吧
0 人点赞
