我的思路是:在Linux安装Docker,然后下载CentOS7系统镜像,然后基于此镜像创建个名为hadoop100的基础容器,在里面安装Linux的基本工具,应用,jdk,Hadoop等,之后再提交打包该容器成镜像为:centos/hadoop100,基于此镜像来创建一主二从的Hadoop集群,ip、路径和软件均参考尚硅谷的数仓4.0项目课程,需要做大数据项目的也可以沿用该环境
1.1 Linux系统
- 在VMware虚拟机创建Linux系统
- 购买一个云服务器自带Linux系统
- 我使用的是CentOS7系统
1.1.1 配置hosts
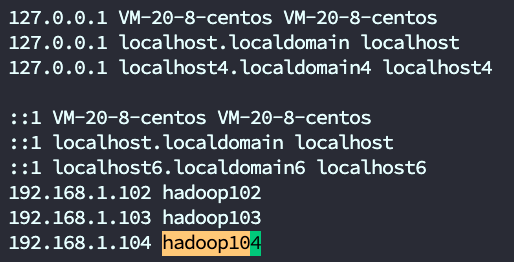
# 配置三台集群hosts[root@VM-20-8-centos ~]# vim /etc/hosts192.168.1.102 hadoop102192.168.1.103 hadoop103192.168.1.104 hadoop104
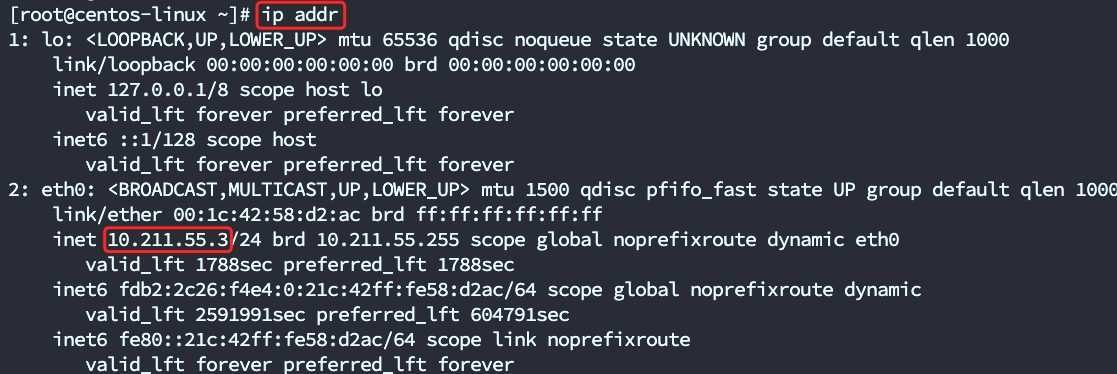
查看Linux的ip地址
- ip addr
- ifconfig
1.1.2 软件存放位置
# 软件安装包存放位置[root@VM-20-8-centos ~]# mkdir -p /opt/software/# 软件安装程序存放位置[root@VM-20-8-centos ~]# mkdir -p /opt/module/
1.1.3 软件上传至software
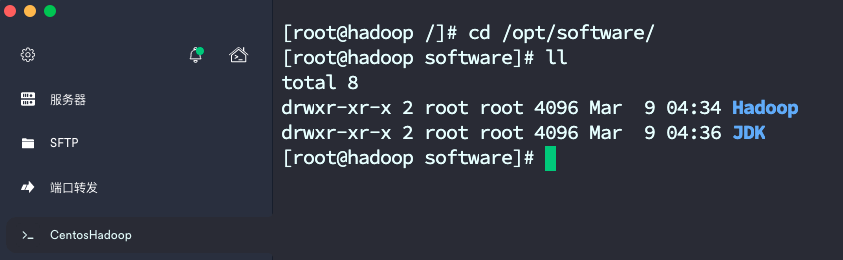
1.1.4 配置环境变量
提前配置好jdk和hadoop的环境变量,方便后续docker容器直接映射环境变量
[root@VM-20-8-centos ~]# vim /etc/profile.d/my_env.sh
HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
<a name="cDSxG"></a>### 1.1.5 创建放置脚本的路径```basic[root@VM-20-8-centos ~]# mkdir -p /home/root/bin
1.1.6 Linux的yum配置国内镜像
[root@VM-20-8-centos ~]# yum install -y wget
[root@VM-20-8-centos ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
[root@VM-20-8-centos ~]# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo -O /etc/yum.repos.d/CentOS-Base.repo
[root@VM-20-8-centos ~]# yum clean all && yum makecache fast
1.1.7 安装Docker
[root@VM-20-8-centos ~]# yum install -y docker
1.1.8 设置Docker自启动
[root@VM-20-8-centos ~]# sudo systemctl start docker
[root@VM-20-8-centos ~]# sudo systemctl enable docker
1.1.9 配置Docker国内源
vi /etc/docker/daemon.json
# 内容如下:
{
"registry-mirrors": [
"https://xx4bwyg2.mirror.aliyuncs.com",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com",
"http://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn"
]
}{}
# 退出并保存
:wq
# 使配置生效
systemctl daemon-reload
# 重启Docker
systemctl restart docker
2.1 Docker镜像容器
docker ps:查看活动的容器
docker ps -a:查看所有的容器(包括终止状态的)
docker images:查看镜像
docker run:基于镜像新建一个容器
docker container start 容器id:启动已经终止的容器,但不会进入容器,容器在后台执行
docker container stop 容器id:终止容器
docker container rm 容器id:删除终止状态的容器
docker image rm 镜像id:删除镜像
进入容器有两个命令:attach和exec
docker attach 容器id:进入容器,使用exit退出时,容器会终止
docker exec -it 容器id bash:进入容器,使用exit退出时,容器不会终止(推荐)
2.1.1 创建桥接网络,分配容器ip
[root@VM-20-8-centos ~]# docker network create --subnet=192.168.1.0/16 mynetwork
2.1.2 下载centos7镜像
[root@VM-20-8-centos ~]# docker pull centos:centos7
2.1.3 创建hadoop100
- 这是一个模板机,里面用于配备基本工具,软件,jdk,hadoop等等 ```basic [root@VM-20-8-centos ~]# docker run -itd —net mynetwork —ip 192.168.1.100 —privileged —restart=always \ -e LANG=”en_US.UTF-8” \ -h hadoop100 —name=hadoop100 \ -v /opt:/opt -v /home/root/bin:/home/root/bin -v /etc/hosts:/etc/hosts -v /etc/profile.d:/etc/profile.d \ -p 1100:22 \ centos:centos7 /usr/sbin/init
[root@VM-20-8-centos ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 59caf99da93f centos:centos7 “/usr/sbin/init” 2 minutes ago Up 2 minutes 0.0.0.0:1100->22/tcp hadoop100
```basic
docker命令参数分析
--net mynetwork --ip 192.168.1.100 添加桥接网络设定
-v 表示基于容器的centos系统的/opt目录与本地/opt,共享;这可以很方便将本地文件上传到Docker内部的centos系统;
-h 指定主机名为master
–-name 指定容器名
-e LANG="en_US.UTF-8" 设置容器内中文编码
-p 端口映射
/bin/bash 使用bash命令
2.1.4 进入hadoop100内部
[root@VM-20-8-centos ~]# docker exec -it 59caf99da93f /bin/bash
2.1.5 开启安装和启动ssh
参照1.1.5:为yum配置国内镜像源即可,以便后续yum安装速度更快
# 安装基本工具
[root@hadoop100 /]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git openssh-server
# 给root用户设置密码,输入2次密码
# 看到 passwd: all authentication tokens updated successfully. 则是设置成功了
[root@hadoop100 /]# passwd root
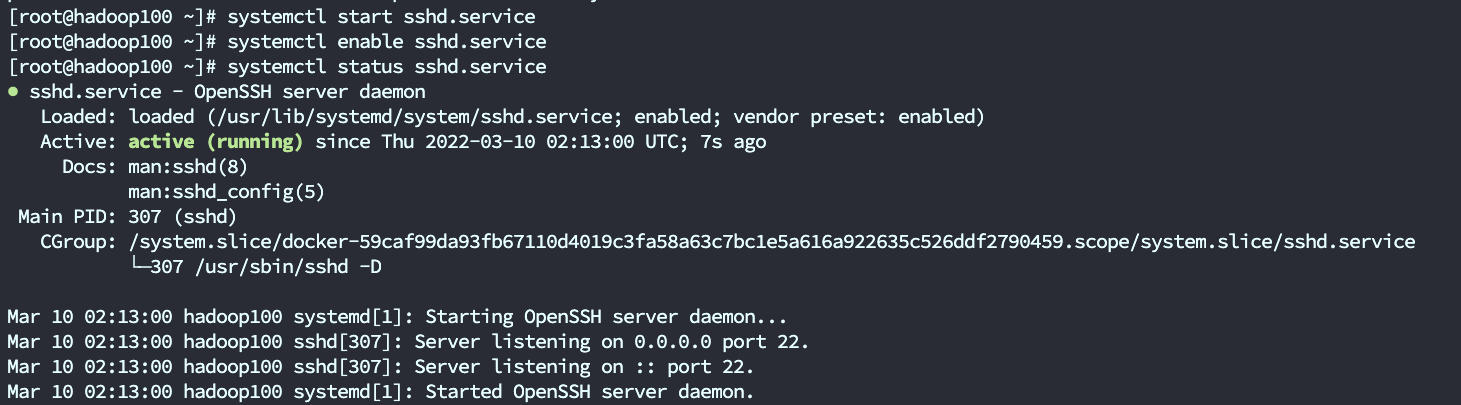
2.1.6 设置sshd自启
[root@hadoop100 /]# systemctl start sshd.service
[root@hadoop100 /]# systemctl enable sshd.service
[root@hadoop100 /]# systemctl status sshd.service
- 输入exit,退出容器交互模式,采用ssh连接模式
[root@hadoop100 /]# exit
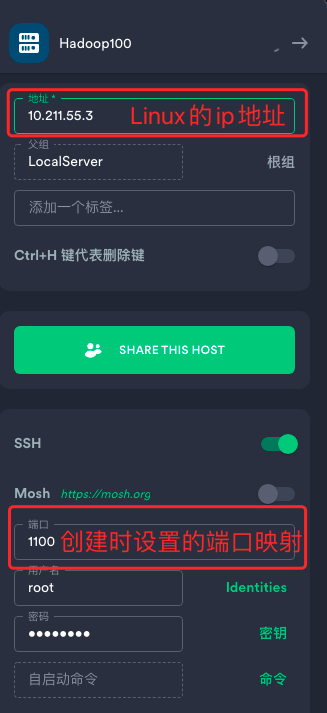
2.1.7 打开ssh工具连接
- docker里的Hadoop100容器已经开启sshd了,可以用ssh工具来连接了
- 如果是虚拟机的Linux系统,要打开防火墙端口限制
- 如果是云服务的Linux系统,要打开防火墙添加端口规则
- 如何查看Linux的ip地址
- ifconfig
- ip addr
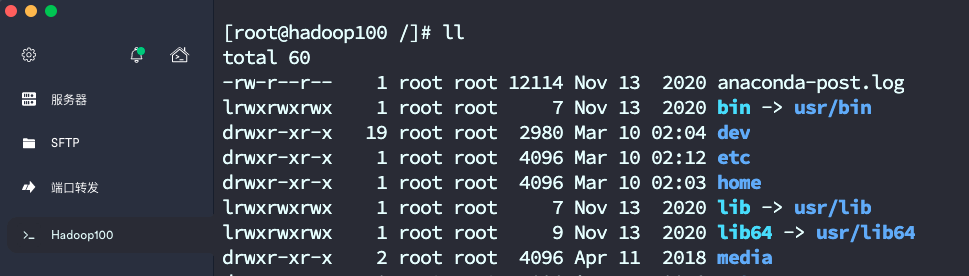
- 通过SSH工具成功连上docker容器内部的Linux系统了
2.1.8 设置免密码登录
# 输入这段命令后,一直按回车
[root@hadoop100 /]# ssh-keygen -t rsa
[root@hadoop100 /]# cd ~/.ssh
[root@hadoop100 /]# cat id_rsa.pub >> authorized_keys
# 切回根目录
[root@hadoop100 /]# cd /
3.1 应用安装
3.1.1 JDK
# 解压安装jdk
[root@hadoop100 /]# tar -zxvf /opt/software/JDK/jdk-8u212-linux-x64.tar.gz -C /opt/module/
# 配置环境变量
[root@hadoop100 /]# vim /etc/profile.d/my_env.sh
环境变量里的内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin刷新环境变量
[root@hadoop100 /]# source /etc/profile检验是否安装成功
[root@hadoop100 /]# java -version java version "1.8.0_212" Java(TM) SE Runtime Environment (build 1.8.0_212-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
3.1.2 Hadoop
# 解压Hadoop
[root@hadoop100 /]# tar -zxvf /opt/software/Hadoop/hadoop-3.1.3.tar.gz -C /opt/module/
# 配置环境变量
[root@hadoop100 /]# vim /etc/profile.d/my_env.sh
环境变量里的内容
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin刷新环境变量
[root@hadoop100 /]# source /etc/profile检验是否安装成功
[root@hadoop100 /]# hadoop version Hadoop 3.1.3
3.1.3 Hadoop配置
[root@hadoop100 /]# cd $HADOOP_HOME/etc/hadoop
1. 配置core-site.xml
vim core-site.xml
<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为root --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 配置该root(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <!-- 配置该root(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 配置该root(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.root.users</name> <value>*</value> </property> </configuration>
2. 配置hdfs-site.xml
vim hdfs-site.xml
<configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> <!-- 测试环境指定HDFS副本的数量1 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
3. 配置yarn-site.xml
- vim yarn-site.xml ```xml
<a name="FXM1f"></a>
#### 4. 配置MapReduce
- vim mapred-site.xmlxml
<a name="VT9TZ"></a>
#### 5. 配置workers
- vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
> 注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。xml
hadoop102
hadoop103
hadoop104
> 要查看历史服务器和日志聚集的话,就需要配置以下内容,说白了就是看计算任务的运行详情
<a name="Md6Dh"></a>
#### 6. 配置历史服务器
- vim mapred-site.xmlxml
<a name="Mz2jK"></a>
#### 7. 配置日志聚集
- vim yarn-site.xmlxml
<a name="c2gpy"></a>
#### 8. 修改Hadoop内部启动脚本的权限
```basic
[root@hadoop100 ~]# cd /opt/module/hadoop-3.1.3/sbin
修改hdfs启动脚本
[root@hadoop100 ~]# vim start-dfs.sh- 新增内容
#!/usr/bin/env bash HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
- 新增内容
修改hdfs关闭脚本
[root@hadoop100 ~]# vim stop-dfs.sh- 新增内容
#!/usr/bin/env bash HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
- 新增内容
修改yarn启动脚本
[root@hadoop100 ~]# vim start-yarn.sh- 新增内容
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
- 新增内容
修改yarn关闭脚本
[root@hadoop100 ~]# vim stop-yarn.sh- 新增内容
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
- 新增内容
9. 配置完成退出保存
- 把该容器打包成镜像,之后基于该hadoop100的镜像来创建一主两从的hadoop集群
[root@hadoop100 /]# exit [root@VM-20-8-centos ~]# docker commit 59caf99da93f centos/hadoop100
3.1.4 创建hadoop集群
- 由上面的配置文件中web端可知
- hadoop102:9870
- hdfs的web端
- hadoop102:19888
- 历史服务的web端
- hadoop103:8088
- yarn的web端
- hadoop104:9868
- 2nn的web端
- hadoop102:9870
- 所以需要把这几个端口都映射出去,才能web端看到
- 开始创建大数据集群容器,一主二从
1. 创建hadoop102
[root@VM-20-8-centos ~]# docker run -itd --net mynetwork --ip 192.168.1.102 --privileged --restart=always \ -e LANG="en_US.UTF-8" \ -h hadoop102 --name=hadoop102 \ -v /opt:/opt -v /home/root/bin:/home/root/bin -v /etc/hosts:/etc/hosts -v /etc/profile.d:/etc/profile.d \ -p 1102:22 -p 9870:9870 -p 19888:19888 \ centos/hadoop100 /usr/sbin/init2. 创建hadoop103
[root@VM-20-8-centos ~]# docker run -itd --net mynetwork --ip 192.168.1.103 --privileged --restart=always \ -e LANG="en_US.UTF-8" \ -h hadoop103 --name=hadoop103 \ -v /opt:/opt -v /home/root/bin:/home/root/bin -v /etc/hosts:/etc/hosts -v /etc/profile.d:/etc/profile.d \ -p 1103:22 -p 8088:8088 \ centos/hadoop100 /usr/sbin/init3. 创建hadoop104
[root@VM-20-8-centos ~]# docker run -itd --net mynetwork --ip 192.168.1.104 --privileged --restart=always \ -e LANG="en_US.UTF-8" \ -h hadoop104 --name=hadoop104 \ -v /opt:/opt -v /home/root/bin:/home/root/bin -v /etc/hosts:/etc/hosts -v /etc/profile.d:/etc/profile.d \ -p 1104:22 -p 9868:9868 \ centos/hadoop100 /usr/sbin/init
4. 打开ssh工具连接
- 参考2.1.7
- 工具连接hadoop104、hadoop103、hadoop102
- 建立三台集群的无密码连接
```basic
连接进hadoop104后
ssh hadoop102 ssh hadoop103 ssh hadoop104
连接进hadoop103后
ssh hadoop102 ssh hadoop103 ssh hadoop104
连接进hadoop102后
ssh hadoop102 ssh hadoop103 ssh hadoop104
<a name="ejIJc"></a>
## 4.1 准备启动
- 进入**hadoop102**,初始化hadoop
```basic
[root@hadoop102 /]# /opt/module/hadoop-3.1.3/bin/hdfs namenode -format
如果之前初始化过了,想要重新初始化,记得删除data目录 [root@hadoop102 /]# rm -rf /opt/module/hadoop-3.1.3/data
4.1.1 编写脚本
- 进入hadoop102,开始编写启动脚本
[root@hadoop102 /]# cd /home/root/bin
1. 集群分发脚本
vim xsync
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done设置权限
[root@hadoop102 bin]# chmod +x xsync测试脚本 ```basic
把文件分发到各节点,如创建个hello.txt
[root@hadoop102 bin]# ./xsync hello.txt
<a name="vwSsO"></a>
#### 2. 集群命令脚本
- vim xcall.sh
```shell
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "$*"
done
设置权限
[root@hadoop102 bin]# chmod 777 xcall.sh启动脚本
[root@hadoop102 bin]# ./xcall.sh jps
3. 集群启动hadoop脚本
vim hdp.sh
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac设置权限
[root@hadoop102 bin]# chmod 777 hdp.sh启动脚本 ```basic
启动hadoop
[root@hadoop102 bin]# ./hdp.sh start
关闭hadoop
[root@hadoop102 bin]# ./hdp.sh stop ```

若有收获,就点个赞吧
0 人点赞
