事实上,依个人浅薄意见,什么中间件就该做什么事,Redis的设计初衷是为了缓存,所以如果真的需要用到消息的订阅发布,我们首选的应该是消息队列,stream我们仅仅作为了解即可。
1.数据结构
5.0推出的数据类型。支持多播的可持久化的消息队列,用于实现发布订阅功能,借鉴了kafka的设计。它采用的存储结构OBJ_ENCODING_STREAM与其他的存储结构差距很大。
OBJ_ENCODING_STREAM底层使用压缩前缀树(radix tree) 来存储字符串元素,从源文件 rax.h 的注释可以知道,radix tree 其实是字典树(Trie tree)的压缩优化版本,它会把多个只有一个子节点的连续节点保存的字符压缩到一个节点中。
Trie Tree 的原理 将每个字符串元素 key 按照单个字符拆分,然后对应到每个分支上。这样从根节点遍历到某个分支的叶节点,所有经过的节点保存的字符拼接出的字符串即为这条分支对应的元素 key。更多的介绍可以看我的数据结构知识库学习。
Stream 添加数据的命令格式如下,其中 key 为 Stream 的名称,ID 为消息的唯一标志,不可重复,field string 就是键值对。
XADD key [MAXLEN [~|=] <count>] <ID or *> [field value] [field value]
我们来看一下redis中对于stream数据结构的定义。
typedef struct streamID {uint64_t ms; /* Unix time in milliseconds. */uint64_t seq; /* Sequence number. */} streamID;typedef struct stream {rax *rax; /* 指向 radix tree 的指针 */uint64_t length; /* 保存的元素的总数,以消息 ID 为统计对象 */streamID last_id; /* Stream 中的最后一个消息 ID */rax *cgroups; /* 保存监听该 Stream 的消费端信息 */} stream;
Stram 底层采用压缩前缀树 radix tree 来存储数据,其最外层的数据结构为rax,我们来看一下代码:
typedef struct rax {raxNode *head; /*radix tree 的头节点*/uint64_t numele;/*radix tree 所存储的元素总数,每插入一个 ID,计数加 1*/uint64_t numnodes;/*radix tree 的节点总数*/} rax;
压缩前缀树 radix tree 的每个节点以raxNode表示,我们来看一下代码:
typedef struct raxNode {uint32_t iskey:1; /* 标志当前节点是否包含了一个完整的 key,key 也就是消息 ID */uint32_t isnull:1; /* 是否有存储值,此处的值是指 XADD 命令中的 [field value] 对 */uint32_t iscompr:1; /* 是否做了前缀压缩,如果有压缩则当前节点只有一个后继节点,没有压缩则每个字符都有自己的后继节点 */uint32_t size:29; /* 如果做了前缀压缩,则表示该节点存储的可用于组成完整 key 的字符数,否则表示该节点的子节点个数 *//*字符数组,存储了当前节点 [field value] 对及其子节点的信息,在实际对这个字段进行操作时,会将其作为 listpack 来处理*/unsigned char data[];} raxNode;
2.压缩树的操作
2.1 插入数据
压缩树的插入函数axInsert()调用了raxGenericInsert()实现了插入操作。rax.c文件里面的raxGenericInsert()函数实现非常复杂,我们来对着源码进行一个梳理:
- 首先调用raxLowWalk()函数根据传入的字符串(也就是消息 ID) 去压缩树中查找这个新增的消息应该插入的位置
- 如果找到压缩树里面已经有这个消息 ID 的字符串存在了,并且它将要插入的位置上的节点没有压缩过:
- 如果这个字符串还不是以完整的 key(iskey =0) 存储的,则重新为当前节点申请内存保存新的 data 域,然后更新当前节点父节点的指针
- 如果这个字符串在压缩树里是以完整的 key(iskey =1) 存储的,则只需要更新当前节点的 data 域
- 如果这个消息id将要插入的位置上的节点压缩过,那么这个节点就需要分裂,以便将新的消息插入进来。源码的注释中提到了 5 种场景

int raxInsert(rax *rax, unsigned char *s, size_t len, void *data, void **old) {return raxGenericInsert(rax,s,len,data,old,1);}int raxGenericInsert(rax *rax, unsigned char *s, size_t len, void *data, void **old, int overwrite) {size_t i;int j = 0;raxNode *h, **parentlink;debugf("### Insert %.*s with value %p\n", (int)len, s, data);i = raxLowWalk(rax,s,len,&h,&parentlink,&j,NULL);if (i == len && (!h->iscompr || j == 0 /* not in the middle if j is 0 */)) {debugf("### Insert: node representing key exists\n");/* Make space for the value pointer if needed. */if (!h->iskey || (h->isnull && overwrite)) {h = raxReallocForData(h,data);if (h) memcpy(parentlink,&h,sizeof(h));}if (h == NULL) {errno = ENOMEM;return 0;}/* Update the existing key if there is already one. */if (h->iskey) {if (old) *old = raxGetData(h);if (overwrite) raxSetData(h,data);errno = 0;return 0; /* Element already exists. */}/* Otherwise set the node as a key. Note that raxSetData()* will set h->iskey. */raxSetData(h,data);rax->numele++;return 1; /* Element inserted. */}/* If the node we stopped at is a compressed node, we need to* split it before to continue.** Splitting a compressed node have a few possible cases.* Imagine that the node 'h' we are currently at is a compressed* node containing the string "ANNIBALE" (it means that it represents* nodes A -> N -> N -> I -> B -> A -> L -> E with the only child* pointer of this node pointing at the 'E' node, because remember that* we have characters at the edges of the graph, not inside the nodes* themselves.** In order to show a real case imagine our node to also point to* another compressed node, that finally points at the node without* children, representing 'O':** "ANNIBALE" -> "SCO" -> []** When inserting we may face the following cases. Note that all the cases* require the insertion of a non compressed node with exactly two* children, except for the last case which just requires splitting a* compressed node.** 1) Inserting "ANNIENTARE"** |B| -> "ALE" -> "SCO" -> []* "ANNI" -> |-|* |E| -> (... continue algo ...) "NTARE" -> []** 2) Inserting "ANNIBALI"** |E| -> "SCO" -> []* "ANNIBAL" -> |-|* |I| -> (... continue algo ...) []** 3) Inserting "AGO" (Like case 1, but set iscompr = 0 into original node)** |N| -> "NIBALE" -> "SCO" -> []* |A| -> |-|* |G| -> (... continue algo ...) |O| -> []** 4) Inserting "CIAO"** |A| -> "NNIBALE" -> "SCO" -> []* |-|* |C| -> (... continue algo ...) "IAO" -> []** 5) Inserting "ANNI"** "ANNI" -> "BALE" -> "SCO" -> []** The final algorithm for insertion covering all the above cases is as* follows.** ============================= ALGO 1 =============================** For the above cases 1 to 4, that is, all cases where we stopped in* the middle of a compressed node for a character mismatch, do:** Let $SPLITPOS be the zero-based index at which, in the* compressed node array of characters, we found the mismatching* character. For example if the node contains "ANNIBALE" and we add* "ANNIENTARE" the $SPLITPOS is 4, that is, the index at which the* mismatching character is found.** 1. Save the current compressed node $NEXT pointer (the pointer to the* child element, that is always present in compressed nodes).** 2. Create "split node" having as child the non common letter* at the compressed node. The other non common letter (at the key)* will be added later as we continue the normal insertion algorithm* at step "6".** 3a. IF $SPLITPOS == 0:* Replace the old node with the split node, by copying the auxiliary* data if any. Fix parent's reference. Free old node eventually* (we still need its data for the next steps of the algorithm).** 3b. IF $SPLITPOS != 0:* Trim the compressed node (reallocating it as well) in order to* contain $splitpos characters. Change child pointer in order to link* to the split node. If new compressed node len is just 1, set* iscompr to 0 (layout is the same). Fix parent's reference.** 4a. IF the postfix len (the length of the remaining string of the* original compressed node after the split character) is non zero,* create a "postfix node". If the postfix node has just one character* set iscompr to 0, otherwise iscompr to 1. Set the postfix node* child pointer to $NEXT.** 4b. IF the postfix len is zero, just use $NEXT as postfix pointer.** 5. Set child[0] of split node to postfix node.** 6. Set the split node as the current node, set current index at child[1]* and continue insertion algorithm as usually.** ============================= ALGO 2 =============================** For case 5, that is, if we stopped in the middle of a compressed* node but no mismatch was found, do:** Let $SPLITPOS be the zero-based index at which, in the* compressed node array of characters, we stopped iterating because* there were no more keys character to match. So in the example of* the node "ANNIBALE", addig the string "ANNI", the $SPLITPOS is 4.** 1. Save the current compressed node $NEXT pointer (the pointer to the* child element, that is always present in compressed nodes).** 2. Create a "postfix node" containing all the characters from $SPLITPOS* to the end. Use $NEXT as the postfix node child pointer.* If the postfix node length is 1, set iscompr to 0.* Set the node as a key with the associated value of the new* inserted key.** 3. Trim the current node to contain the first $SPLITPOS characters.* As usually if the new node length is just 1, set iscompr to 0.* Take the iskey / associated value as it was in the orignal node.* Fix the parent's reference.** 4. Set the postfix node as the only child pointer of the trimmed* node created at step 1.*//* ------------------------- ALGORITHM 1 --------------------------- */if (h->iscompr && i != len) {debugf("ALGO 1: Stopped at compressed node %.*s (%p)\n",h->size, h->data, (void*)h);debugf("Still to insert: %.*s\n", (int)(len-i), s+i);debugf("Splitting at %d: '%c'\n", j, ((char*)h->data)[j]);debugf("Other (key) letter is '%c'\n", s[i]);/* 1: Save next pointer. */raxNode **childfield = raxNodeLastChildPtr(h);raxNode *next;memcpy(&next,childfield,sizeof(next));debugf("Next is %p\n", (void*)next);debugf("iskey %d\n", h->iskey);if (h->iskey) {debugf("key value is %p\n", raxGetData(h));}/* Set the length of the additional nodes we will need. */size_t trimmedlen = j;size_t postfixlen = h->size - j - 1;int split_node_is_key = !trimmedlen && h->iskey && !h->isnull;size_t nodesize;/* 2: Create the split node. Also allocate the other nodes we'll need* ASAP, so that it will be simpler to handle OOM. */raxNode *splitnode = raxNewNode(1, split_node_is_key);raxNode *trimmed = NULL;raxNode *postfix = NULL;if (trimmedlen) {nodesize = sizeof(raxNode)+trimmedlen+raxPadding(trimmedlen)+sizeof(raxNode*);if (h->iskey && !h->isnull) nodesize += sizeof(void*);trimmed = rax_malloc(nodesize);}if (postfixlen) {nodesize = sizeof(raxNode)+postfixlen+raxPadding(postfixlen)+sizeof(raxNode*);postfix = rax_malloc(nodesize);}/* OOM? Abort now that the tree is untouched. */if (splitnode == NULL ||(trimmedlen && trimmed == NULL) ||(postfixlen && postfix == NULL)){rax_free(splitnode);rax_free(trimmed);rax_free(postfix);errno = ENOMEM;return 0;}splitnode->data[0] = h->data[j];if (j == 0) {/* 3a: Replace the old node with the split node. */if (h->iskey) {void *ndata = raxGetData(h);raxSetData(splitnode,ndata);}memcpy(parentlink,&splitnode,sizeof(splitnode));} else {/* 3b: Trim the compressed node. */trimmed->size = j;memcpy(trimmed->data,h->data,j);trimmed->iscompr = j > 1 ? 1 : 0;trimmed->iskey = h->iskey;trimmed->isnull = h->isnull;if (h->iskey && !h->isnull) {void *ndata = raxGetData(h);raxSetData(trimmed,ndata);}raxNode **cp = raxNodeLastChildPtr(trimmed);memcpy(cp,&splitnode,sizeof(splitnode));memcpy(parentlink,&trimmed,sizeof(trimmed));parentlink = cp; /* Set parentlink to splitnode parent. */rax->numnodes++;}/* 4: Create the postfix node: what remains of the original* compressed node after the split. */if (postfixlen) {/* 4a: create a postfix node. */postfix->iskey = 0;postfix->isnull = 0;postfix->size = postfixlen;postfix->iscompr = postfixlen > 1;memcpy(postfix->data,h->data+j+1,postfixlen);raxNode **cp = raxNodeLastChildPtr(postfix);memcpy(cp,&next,sizeof(next));rax->numnodes++;} else {/* 4b: just use next as postfix node. */postfix = next;}/* 5: Set splitnode first child as the postfix node. */raxNode **splitchild = raxNodeLastChildPtr(splitnode);memcpy(splitchild,&postfix,sizeof(postfix));/* 6. Continue insertion: this will cause the splitnode to* get a new child (the non common character at the currently* inserted key). */rax_free(h);h = splitnode;} else if (h->iscompr && i == len) {/* ------------------------- ALGORITHM 2 --------------------------- */debugf("ALGO 2: Stopped at compressed node %.*s (%p) j = %d\n",h->size, h->data, (void*)h, j);/* Allocate postfix & trimmed nodes ASAP to fail for OOM gracefully. */size_t postfixlen = h->size - j;size_t nodesize = sizeof(raxNode)+postfixlen+raxPadding(postfixlen)+sizeof(raxNode*);if (data != NULL) nodesize += sizeof(void*);raxNode *postfix = rax_malloc(nodesize);nodesize = sizeof(raxNode)+j+raxPadding(j)+sizeof(raxNode*);if (h->iskey && !h->isnull) nodesize += sizeof(void*);raxNode *trimmed = rax_malloc(nodesize);if (postfix == NULL || trimmed == NULL) {rax_free(postfix);rax_free(trimmed);errno = ENOMEM;return 0;}/* 1: Save next pointer. */raxNode **childfield = raxNodeLastChildPtr(h);raxNode *next;memcpy(&next,childfield,sizeof(next));/* 2: Create the postfix node. */postfix->size = postfixlen;postfix->iscompr = postfixlen > 1;postfix->iskey = 1;postfix->isnull = 0;memcpy(postfix->data,h->data+j,postfixlen);raxSetData(postfix,data);raxNode **cp = raxNodeLastChildPtr(postfix);memcpy(cp,&next,sizeof(next));rax->numnodes++;/* 3: Trim the compressed node. */trimmed->size = j;trimmed->iscompr = j > 1;trimmed->iskey = 0;trimmed->isnull = 0;memcpy(trimmed->data,h->data,j);memcpy(parentlink,&trimmed,sizeof(trimmed));if (h->iskey) {void *aux = raxGetData(h);raxSetData(trimmed,aux);}/* Fix the trimmed node child pointer to point to* the postfix node. */cp = raxNodeLastChildPtr(trimmed);memcpy(cp,&postfix,sizeof(postfix));/* Finish! We don't need to continue with the insertion* algorithm for ALGO 2. The key is already inserted. */rax->numele++;rax_free(h);return 1; /* Key inserted. */}/* We walked the radix tree as far as we could, but still there are left* chars in our string. We need to insert the missing nodes. */while(i < len) {raxNode *child;/* If this node is going to have a single child, and there* are other characters, so that that would result in a chain* of single-childed nodes, turn it into a compressed node. */if (h->size == 0 && len-i > 1) {debugf("Inserting compressed node\n");size_t comprsize = len-i;if (comprsize > RAX_NODE_MAX_SIZE)comprsize = RAX_NODE_MAX_SIZE;raxNode *newh = raxCompressNode(h,s+i,comprsize,&child);if (newh == NULL) goto oom;h = newh;memcpy(parentlink,&h,sizeof(h));parentlink = raxNodeLastChildPtr(h);i += comprsize;} else {debugf("Inserting normal node\n");raxNode **new_parentlink;raxNode *newh = raxAddChild(h,s[i],&child,&new_parentlink);if (newh == NULL) goto oom;h = newh;memcpy(parentlink,&h,sizeof(h));parentlink = new_parentlink;i++;}rax->numnodes++;h = child;}raxNode *newh = raxReallocForData(h,data);if (newh == NULL) goto oom;h = newh;if (!h->iskey) rax->numele++;raxSetData(h,data);memcpy(parentlink,&h,sizeof(h));return 1; /* Element inserted. */oom:/* This code path handles out of memory after part of the sub-tree was* already modified. Set the node as a key, and then remove it. However we* do that only if the node is a terminal node, otherwise if the OOM* happened reallocating a node in the middle, we don't need to free* anything. */if (h->size == 0) {h->isnull = 1;h->iskey = 1;rax->numele++; /* Compensate the next remove. */assert(raxRemove(rax,s,i,NULL) != 0);}errno = ENOMEM;return 0;}
2.2 查找数据
是压缩树中查找特定 key 所在位置的函数是raxLowWalk() ,它的本质就是树的遍历操作。
- 从 rax 头节点开始遍历
- 如果节点是压缩的
- 依次比较当前节点上保存的 key 字符与目标字符
- 找到一个与目标字符不相等的就跳出循环
- 根据条件判断是否需要去后继节点上继续查找
- 如果节点不是压缩的
- 当一个字符匹配上的时候,就从这个字符的后继节点上继续查找
- 如果节点是压缩的
static inline size_t raxLowWalk(rax *rax, unsigned char *s, size_t len, raxNode **stopnode, raxNode ***plink, int *splitpos, raxStack *ts) {
raxNode *h = rax->head;
raxNode **parentlink = &rax->head;
size_t i = 0; /* Position in the string. */
size_t j = 0; /* Position in the node children (or bytes if compressed).*/
while(h->size && i < len) {
debugnode("Lookup current node",h);
unsigned char *v = h->data;
if (h->iscompr) {
for (j = 0; j < h->size && i < len; j++, i++) {
if (v[j] != s[i]) break;
}
if (j != h->size) break;
} else {
for (j = 0; j < h->size; j++) {
if (v[j] == s[i]) break;
}
if (j == h->size) break;
i++;
}
if (ts) raxStackPush(ts,h); /* Save stack of parent nodes. */
raxNode **children = raxNodeFirstChildPtr(h);
if (h->iscompr) j = 0; /* Compressed node only child is at index 0. */
memcpy(&h,children+j,sizeof(h));
parentlink = children+j;
j = 0;
}
debugnode("Lookup stop node is",h);
if (stopnode) *stopnode = h;
if (plink) *plink = parentlink;
if (splitpos && h->iscompr) *splitpos = j;
return i;
}
3.流的操作
流的操作命令的处理函数是xaddCommand()。源码有点长,但是逻辑并不复杂,我们来梳理一下:
- 将客户端传输过来的命令参数解析,并做语法检查
- 调用streamTypeLookupWriteOrCreate()用目标流的key去数据库中找是否存在对应的 Stream 对象,不存在则创建
- 向流添加元素前要校验其last_id记录的消息id是否达到了最大值,校验通过则调用streamAppendItem() 函数将元素添加到流中
- 根据命令中的maxlen参数调用streamTrimByLength()函数对流进行剪切,以便其保存的元素总数<=maxlen的限定。另外由于主从复制和AOF持久化,判断是否需要调用函数streamRewriteApproxMaxlen()将命令参数进行重写转化,否则在从节点上对流的剪切不一定和主节点一致
- 如果有客户端阻塞在流的读取上,需要通知它有新数据到来了
/* XADD key [MAXLEN [~|=] <count>] [NOMKSTREAM] <ID or *> [field value] [field value] ... */
void xaddCommand(client *c) {
streamID id;
int id_given = 0; /* Was an ID different than "*" specified? */
long long maxlen = -1; /* If left to -1 no trimming is performed. */
int approx_maxlen = 0; /* If 1 only delete whole radix tree nodes, so
the maximum length is not applied verbatim. */
int maxlen_arg_idx = 0; /* Index of the count in MAXLEN, for rewriting. */
int no_mkstream = 0; /* if set to 1 do not create new stream */
/* Parse options. */
int i = 2; /* This is the first argument position where we could
find an option, or the ID. */
//将客户端传输过来的命令参数解析,并做语法检查
for (; i < c->argc; i++) {
int moreargs = (c->argc-1) - i; /* Number of additional arguments. */
char *opt = c->argv[i]->ptr;
if (opt[0] == '*' && opt[1] == '\0') {
/* This is just a fast path for the common case of auto-ID
* creation. */
break;
} else if (!strcasecmp(opt,"maxlen") && moreargs) {
approx_maxlen = 0;
char *next = c->argv[i+1]->ptr;
/* Check for the form MAXLEN ~ <count>. */
if (moreargs >= 2 && next[0] == '~' && next[1] == '\0') {
approx_maxlen = 1;
i++;
} else if (moreargs >= 2 && next[0] == '=' && next[1] == '\0') {
i++;
}
if (getLongLongFromObjectOrReply(c,c->argv[i+1],&maxlen,NULL)
!= C_OK) return;
if (maxlen < 0) {
addReplyError(c,"The MAXLEN argument must be >= 0.");
return;
}
i++;
maxlen_arg_idx = i;
} else if (!strcasecmp(opt,"nomkstream")) {
no_mkstream = 1;
} else {
/* If we are here is a syntax error or a valid ID. */
if (streamParseStrictIDOrReply(c,c->argv[i],&id,0) != C_OK) return;
id_given = 1;
break;
}
}
int field_pos = i+1;
/* Check arity. */
if ((c->argc - field_pos) < 2 || ((c->argc-field_pos) % 2) == 1) {
addReplyError(c,"wrong number of arguments for XADD");
return;
}
/* Return ASAP if minimal ID (0-0) was given so we avoid possibly creating
* a new stream and have streamAppendItem fail, leaving an empty key in the
* database. */
if (id_given && id.ms == 0 && id.seq == 0) {
addReplyError(c,"The ID specified in XADD must be greater than 0-0");
return;
}
/* Lookup the stream at key. */
robj *o;
stream *s;
//用目标流的key去数据库中找是否存在对应的 Stream 对象,不存在则创建
if ((o = streamTypeLookupWriteOrCreate(c,c->argv[1],no_mkstream)) == NULL) return;
s = o->ptr;
//校验其last_id记录的消息id是否达到了最大值
if (s->last_id.ms == UINT64_MAX && s->last_id.seq == UINT64_MAX) {
addReplyError(c,"The stream has exhausted the last possible ID, "
"unable to add more items");
return;
}
/* 将元素添加到流中*/
if (streamAppendItem(s,c->argv+field_pos,(c->argc-field_pos)/2,
&id, id_given ? &id : NULL)
== C_ERR)
{
addReplyError(c,"The ID specified in XADD is equal or smaller than the "
"target stream top item");
return;
}
addReplyStreamID(c,&id);
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STREAM,"xadd",c->argv[1],c->db->id);
server.dirty++;
//如果条件成立,
if (maxlen >= 0) {
/* 对流进行剪切 */
if (streamTrimByLength(s,maxlen,approx_maxlen)) {
notifyKeyspaceEvent(NOTIFY_STREAM,"xtrim",c->argv[1],c->db->id);
}
//判断是否需要将命令参数进行重写转化,否则在从节点上对流的剪切不一定和主节点一致
if (approx_maxlen) streamRewriteApproxMaxlen(c,s,maxlen_arg_idx);
}
/* Let's rewrite the ID argument with the one actually generated for
* AOF/replication propagation. */
robj *idarg = createObjectFromStreamID(&id);
rewriteClientCommandArgument(c,i,idarg);
decrRefCount(idarg);
/* 如果有客户端阻塞在流的读取上,需要通知它有新数据到来了 */
signalKeyAsReady(c->db, c->argv[1], OBJ_STREAM);
}
3.1 streamTypeLookupWriteOrCreate
这个函数的主要作用就是去数据库查查数是否已经存在了,不存在就创建出来。大概流程如下:
根据key去数据库查找
- 如果找到redisObject对象需要判断其类型是否是OBJ_STREAM,是的话直接返回
- 没有找到则调用createStreamObject()新建一个流对象
robj *streamTypeLookupWriteOrCreate(client *c, robj *key, int no_create) { //根据传入的key去数据库查找 robj *o = lookupKeyWrite(c->db,key); //类型检查 if (checkType(c,o,OBJ_STREAM)) return NULL; //没找到就创建 if (o == NULL) { if (no_create) { addReplyNull(c); return NULL; } //创建流对象 o = createStreamObject(); //保存到数据库 dbAdd(c->db,key,o); } return o; }3.2 streamAppendItem
streamAppendItem()代码有点顶,我也是大概推测一下他的流程,在网上看了一些资料,大概梳理清楚点了。
如果添加元素到 Stream 中的命令没有指定 ID 参数为特定一个值,则添加元素总是会成功,否则有可能失败。因为streamCompareID() 函数会比较客户端传过来的 ID 和 Stream 中当前的最后一个 ID,二者有可能存在冲突
- 添加元素过程中首先取 Stream 对象中的 rax 结构生成迭代器,调用raxSeek(&ri,”$”,NULL,0);找到 radix tree 的最后一个节点,校验这个节点的 data 占用的空间是否超过配置(stream-node-max-bytes,默认 4096),以及其保存的元素总数是否超过配置(stream-node-max-entries,默认 100)。如果超过就将指向 data 的指针清空,没有超过则使用最后一个节点的 data 空间
- 如果最后一个节点的 data 数据域已经满了,则调用 lpNew() 函数生成一个 listpack ,其内部其实也就是一个 char 指针。之后的步骤是把向 Stram 中添加的 field 用以下方式组织存入到 listpack 中,接着调用函数rax.c#raxInsert()将其以指定的 id 插入到 radix tree 中;如果最后一个节点的 data 数据域没有满,需要将新的 field 插入到这个 listpack 中,并检查新添加的这些 field 是否和原来的 field 完全相同
处理完 field 之后,需要处理 value ,通常将其以方式1组织,但是如果新添加的 field 和节点中原来的 field 完全相同,则只要更新 value 即可,不需要更新 filed,故此时采用方式2组织,最后调用 rax.c#raxInsert()函数将该字符串数据插回 radix tree 中
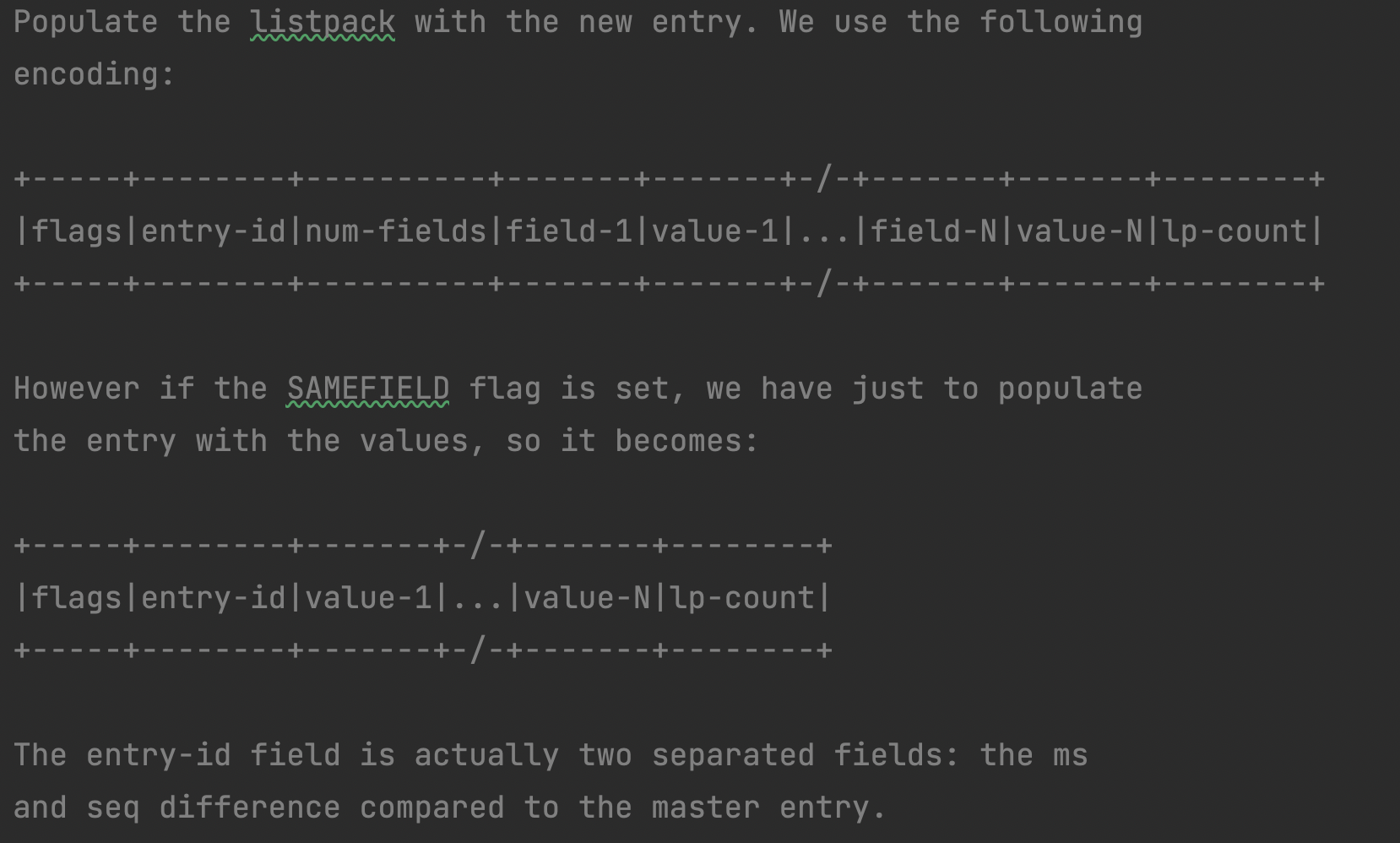
int streamAppendItem(stream *s, robj **argv, int64_t numfields, streamID *added_id, streamID *use_id) { /* Generate the new entry ID. */ streamID id; if (use_id) id = *use_id; else streamNextID(&s->last_id,&id); if (streamCompareID(&id,&s->last_id) <= 0) return C_ERR; /* Add the new entry. */ raxIterator ri; raxStart(&ri,s->rax); raxSeek(&ri,"$",NULL,0); size_t lp_bytes = 0; /* Total bytes in the tail listpack. */ unsigned char *lp = NULL; /* Tail listpack pointer. */ /* Get a reference to the tail node listpack. */ if (raxNext(&ri)) { lp = ri.data; lp_bytes = lpBytes(lp); } raxStop(&ri); if (lp != NULL) { if (server.stream_node_max_bytes && lp_bytes >= server.stream_node_max_bytes) { lp = NULL; } else if (server.stream_node_max_entries) { int64_t count = lpGetInteger(lpFirst(lp)); if (count >= server.stream_node_max_entries) lp = NULL; } } int flags = STREAM_ITEM_FLAG_NONE; if (lp == NULL) { master_id = id; streamEncodeID(rax_key,&id); /* Create the listpack having the master entry ID and fields. */ lp = lpNew(); lp = lpAppendInteger(lp,1); /* One item, the one we are adding. */ lp = lpAppendInteger(lp,0); /* Zero deleted so far. */ lp = lpAppendInteger(lp,numfields); for (int64_t i = 0; i < numfields; i++) { sds field = argv[i*2]->ptr; lp = lpAppend(lp,(unsigned char*)field,sdslen(field)); } lp = lpAppendInteger(lp,0); /* Master entry zero terminator. */ raxInsert(s->rax,(unsigned char*)&rax_key,sizeof(rax_key),lp,NULL); /* The first entry we insert, has obviously the same fields of the * master entry. */ flags |= STREAM_ITEM_FLAG_SAMEFIELDS; } else { serverAssert(ri.key_len == sizeof(rax_key)); memcpy(rax_key,ri.key,sizeof(rax_key)); /* Read the master ID from the radix tree key. */ streamDecodeID(rax_key,&master_id); unsigned char *lp_ele = lpFirst(lp); /* Update count and skip the deleted fields. */ int64_t count = lpGetInteger(lp_ele); lp = lpReplaceInteger(lp,&lp_ele,count+1); lp_ele = lpNext(lp,lp_ele); /* seek deleted. */ lp_ele = lpNext(lp,lp_ele); /* seek master entry num fields. */ /* Check if the entry we are adding, have the same fields * as the master entry. */ int64_t master_fields_count = lpGetInteger(lp_ele); lp_ele = lpNext(lp,lp_ele); if (numfields == master_fields_count) { int64_t i; for (i = 0; i < master_fields_count; i++) { sds field = argv[i*2]->ptr; int64_t e_len; unsigned char buf[LP_INTBUF_SIZE]; unsigned char *e = lpGet(lp_ele,&e_len,buf); /* Stop if there is a mismatch. */ if (sdslen(field) != (size_t)e_len || memcmp(e,field,e_len) != 0) break; lp_ele = lpNext(lp,lp_ele); } /* All fields are the same! We can compress the field names * setting a single bit in the flags. */ if (i == master_fields_count) flags |= STREAM_ITEM_FLAG_SAMEFIELDS; } } lp = lpAppendInteger(lp,flags); lp = lpAppendInteger(lp,id.ms - master_id.ms); lp = lpAppendInteger(lp,id.seq - master_id.seq); if (!(flags & STREAM_ITEM_FLAG_SAMEFIELDS)) lp = lpAppendInteger(lp,numfields); for (int64_t i = 0; i < numfields; i++) { sds field = argv[i*2]->ptr, value = argv[i*2+1]->ptr; if (!(flags & STREAM_ITEM_FLAG_SAMEFIELDS)) lp = lpAppend(lp,(unsigned char*)field,sdslen(field)); lp = lpAppend(lp,(unsigned char*)value,sdslen(value)); } /* Compute and store the lp-count field. */ int64_t lp_count = numfields; lp_count += 3; /* Add the 3 fixed fields flags + ms-diff + seq-diff. */ if (!(flags & STREAM_ITEM_FLAG_SAMEFIELDS)) { /* If the item is not compressed, it also has the fields other than * the values, and an additional num-fileds field. */ lp_count += numfields+1; } lp = lpAppendInteger(lp,lp_count); /* Insert back into the tree in order to update the listpack pointer. */ if (ri.data != lp) raxInsert(s->rax,(unsigned char*)&rax_key,sizeof(rax_key),lp,NULL); s->length++; s->last_id = id; if (added_id) *added_id = id; return C_OK; }3.3 streamTrimByLength
streamTrimByLength()函数会根据给定的长度从压缩树的头节点开始剪切,但是这并不意味着剪切之后压缩树中的元素数量就等于给定条件,因为压缩树要想删除元素只能将包含该元素的整个节点移除。
int64_t streamTrimByLength(stream *s, size_t maxlen, int approx) { if (s->length <= maxlen) return 0; raxIterator ri; raxStart(&ri,s->rax); raxSeek(&ri,"^",NULL,0); int64_t deleted = 0; while(s->length > maxlen && raxNext(&ri)) { unsigned char *lp = ri.data, *p = lpFirst(lp); int64_t entries = lpGetInteger(p); /* Check if we can remove the whole node, and still have at * least maxlen elements. */ if (s->length - entries >= maxlen) { lpFree(lp); raxRemove(s->rax,ri.key,ri.key_len,NULL); raxSeek(&ri,">=",ri.key,ri.key_len); s->length -= entries; deleted += entries; continue; } /* If we cannot remove a whole element, and approx is true, * stop here. */ if (approx) break; /* Otherwise, we have to mark single entries inside the listpack * as deleted. We start by updating the entries/deleted counters. */ int64_t to_delete = s->length - maxlen; serverAssert(to_delete < entries); lp = lpReplaceInteger(lp,&p,entries-to_delete); p = lpNext(lp,p); /* Seek deleted field. */ int64_t marked_deleted = lpGetInteger(p); lp = lpReplaceInteger(lp,&p,marked_deleted+to_delete); p = lpNext(lp,p); /* Seek num-of-fields in the master entry. */ /* Skip all the master fields. */ int64_t master_fields_count = lpGetInteger(p); p = lpNext(lp,p); /* Seek the first field. */ for (int64_t j = 0; j < master_fields_count; j++) p = lpNext(lp,p); /* Skip all master fields. */ p = lpNext(lp,p); /* Skip the zero master entry terminator. */ /* 'p' is now pointing to the first entry inside the listpack. * We have to run entry after entry, marking entries as deleted * if they are already not deleted. */ while(p) { int flags = lpGetInteger(p); int to_skip; /* Mark the entry as deleted. */ if (!(flags & STREAM_ITEM_FLAG_DELETED)) { flags |= STREAM_ITEM_FLAG_DELETED; lp = lpReplaceInteger(lp,&p,flags); deleted++; s->length--; if (s->length <= maxlen) break; /* Enough entries deleted. */ } p = lpNext(lp,p); /* Skip ID ms delta. */ p = lpNext(lp,p); /* Skip ID seq delta. */ p = lpNext(lp,p); /* Seek num-fields or values (if compressed). */ if (flags & STREAM_ITEM_FLAG_SAMEFIELDS) { to_skip = master_fields_count; } else { to_skip = lpGetInteger(p); to_skip = 1+(to_skip*2); } while(to_skip--) p = lpNext(lp,p); /* Skip the whole entry. */ p = lpNext(lp,p); /* Skip the final lp-count field. */ } /* Here we should perform garbage collection in case at this point * there are too many entries deleted inside the listpack. */ entries -= to_delete; marked_deleted += to_delete; if (entries + marked_deleted > 10 && marked_deleted > entries/2) { /* TODO: perform a garbage collection. */ } /* Update the listpack with the new pointer. */ raxInsert(s->rax,ri.key,ri.key_len,lp,NULL); break; /* If we are here, there was enough to delete in the current node, so no need to go to the next node. */ } raxStop(&ri); return deleted; }至此,整个stream数据结构就分析完了,下面我们再来看下stream的应用场景。
4.应用场景
①消息发布订阅

相比于现有的PUB/SUB、BLOCKED LIST,其虽然也可以在简单的场景下作为消息队列来使用,但是Redis Stream无疑要完善很多。Redis Stream提供了消息的持久化和主备复制功能、新的RadixTree数据结构来支持更高效的内存使用和消息读取、甚至是类似于Kafka的Consumer Group功能。

若有收获,就点个赞吧
0 人点赞
