1.存储类型
存储有序的字符串(从左到右),元素可以重复。可以充当队列和栈的角色。在早期的版本中,数据量较小时用 ziplist 存储,达到临界值时转换为 linkedlist 进行存储,分别对应 OBJ_ENCODING_ZIPLIST 和 OBJ_ENCODING_LINKEDLIST 。3.2 版本之后,统一用 quicklist 来存储。quicklist 存储了一个双向链表,每个节点都是一个 ziplist。

2.zipList
2.1 存储结构
ziplist在上一篇文章中其实我们已经涉及到了,也做了简单的介绍,但是哈希对象中的ziplist和列表对象中的ziplist的不同之处在于哈希对象是key-value形式的,所以其ziplist中页表现为key-value,key和value紧挨在一起,ziplist的存在就是为了提高存储效率。ziplist会将列表中每一个元素存放在前后连续的地址空间中,整体占用一大块内存,以减少内存碎片的产生。因为ziplist占用了一块连续的内存空间,对他的追加操作会引发内存的realloc,导致ziplist的内存位置发生变化,因此往ziplist中插入数据时会产生一个新的ziplist。
接下来看一下前面提到的哈希中的ziplist。ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。一个ziplist可以包含任意多个entry,而每一个entry又可以保存一个字节数组或者一个整数值。ziplist的组成结构如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
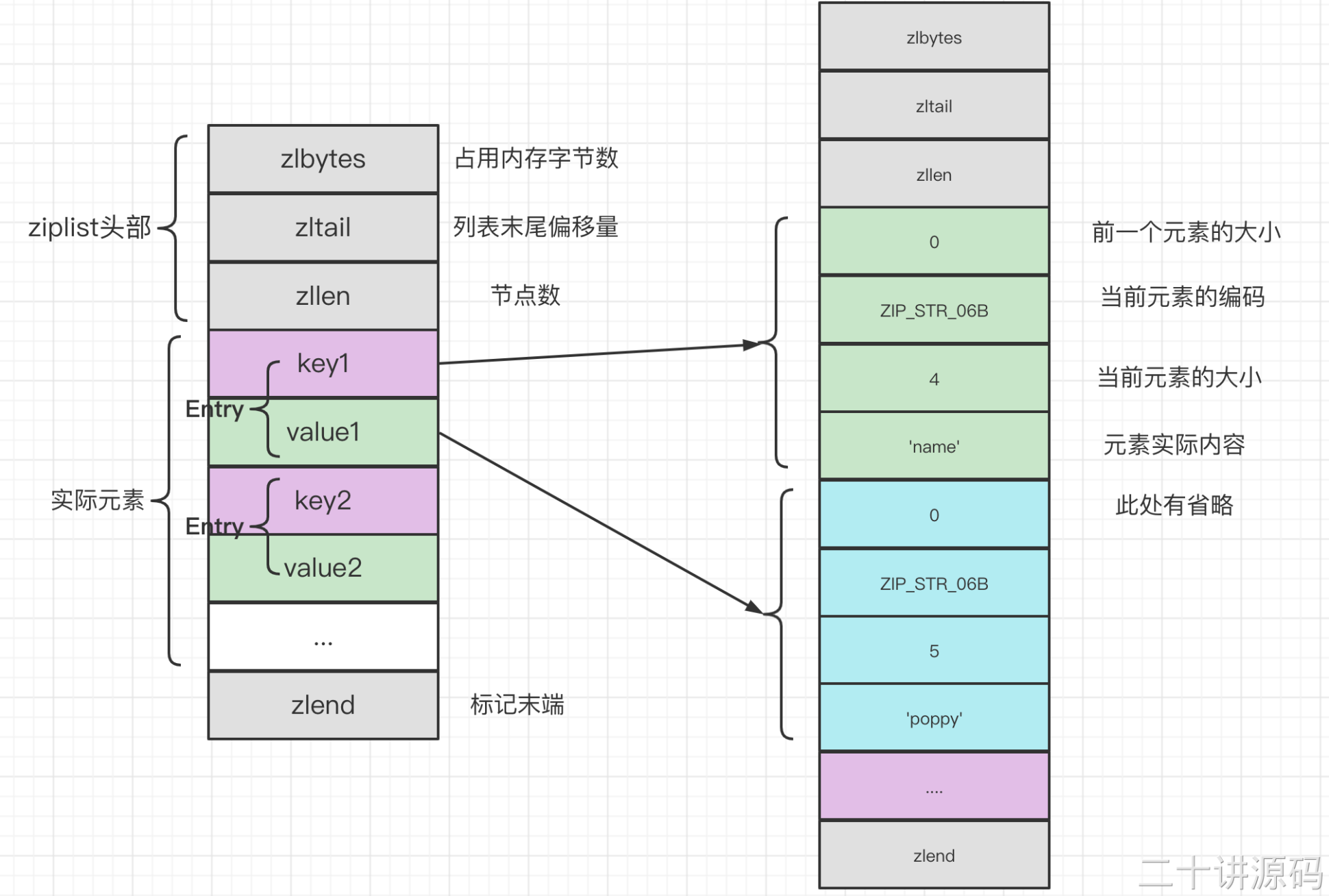
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 记录压缩列表占用内存字节数(包括本身做占用的4个字节) |
| zltail | uint32_t | 4字节 | 记录压缩列表尾节点距离压缩列表的起始地址有多少个字节(通过这个值可以计算出尾节点的地址) |
| zllen | uint16_t | 2字节 | 记录压缩列表中包含的节点数量,当列表值超过可以存储的最大值(65535)时,次值固定存储216-1(65535),因此此时需要遍历整个压缩列表才能计算出真实节点数 |
| entry | 列表结点 | - | 压缩列表中的各个节点,长度由存储的实际数据决定 |
| zlend | uint8_t | 1字节 | 特殊字符0xFF(十进制255),用来标记压缩列表的末端(其他正常的节点没有被标记为255的,因为255用来标识末尾,后面可以看到,正常节点都是标记为254) |
2.2 节点
ziplist 中的每个 entry 都以包含两段信息的元数据作为前缀,每一个 entry 的组成结构为:
<prevlen> <encoding> <entry-data>
prevlen属性存储了前一个entry的长度,以便能够从后到前遍历列表。 prevlen 的长度可能是1字节也可能是5字节:
- 当链表的前一个entry占用字节数小于254,此时prevlen只用1个字节进行表示。
- 当链表的前一个entry占用字节数大于等于254,此时prevlen用5个字节来表示,其中第1个字节的值是254(相当于是一个标记,代表后面跟了一个更大的值),后面4个字节才是真正存储前一个entry的占用字节数。
1个字节完全能存储255,之所以只取到254是因为zlend就是固定的255,所以255这个数要用来判断是否是ziplist的结尾。
encoding属性存储了当前entry所保存数据的类型以及长度。encoding长度为1字节,2字节或者5字节长。前面我们提到,每一个entry中可以保存字节数组和整数,而encoding属性的第1个字节就是用来确定当前entry存储的是整数还是字节数组。当存储整数时,第1个字节的前两位总是11,而存储字节数组时,则可能是00、01和10。
- 当存储整数时,第1个字节的前2位固定为11,其他位则用来记录整数值的类型或者整数值
| 编码 | 长度 | entry保存的数据 |
|---|---|---|
| 11000000 | 1字节 | int16_t类型整数 |
| 11010000 | 1字节 | int32_t类型整数 |
| 11100000 | 1字节 | int64_t类型整数 |
| 11110000 | 1字节 | 24位有符号整数 |
| 11111110 | 1字节 | 8位有符号整数 |
| 1111xxxx | 1字节 | xxxx代表区间0001-1101,存储了一个介于0-12之间的整数,此时无需entry-data属性 |
xxxx四位编码范围是0000-1111,但是0000,1111和1110已经被占用了,所以实际上的范围是0001-1101,此时能保存数据1-13,再减去1之后范围就是0-12。至于为什么要减去1个人的理解是从使用概率上来说0是很常用的一个数字,所以才会选择统一减去1来存储一个0-12的区间而不是直接存储1-13的区间。
- 当存储字节数组时,第1个字节的前2位为00、01或者10,其他位则用来记录字节数组的长度 | 编码 | 长度 | entry保存的数据 | | —- | —- | —- | | 00pppppp | 1字节 | 长度小于等于63字节(6位)的字节数组 | | 01pppppp qqqqqqqq | 2字节 | 长度小于等于16383字节(14位)的字节数组 | | 10000000 qqqqqqqq rrrrrrrr ssssssss tttttttt | 5字节 | 长度小于等于232-1字节(32位)的字节数组,其中第1个字节的后6位设置为0,暂时没有用到,后面的32位(4个字节)存储了数据 |
entry-data:具体数据。当存储小整数时,encoding就是数据本身,此时没有entry-data部分,没有entry-data部分之后的ziplist结构如下:
<prevlen> <encoding>
压缩列表中entry的数据结构定义如下(源码ziplist.c内),当然这个代码注释写了实际存储并没有用到这个结构,这个结构只是用来接收数据,所以了解一下就可以了。
typedef struct zlentry {unsigned int prevrawlensize;//存储prevrawlen所占用的字节数unsigned int prevrawlen;//存储上一个链表节点需要的字节数unsigned int lensize;//存储len所占用的字节数unsigned int len;//存储链表当前节点的字节数unsigned int headersize;//当前链表节点的头部大小(prevrawlensize + lensize)即非数据域的大小unsigned char encoding;//编码方式unsigned char *p;//指向当前节点的起始位置(因为列表内的数据也是一个字符串对象)} zlentry;
2.3 数据示例
我们通过一个ziplist存储整数为例子来分析一下。
[0f 00 00 00] [0c 00 00 00] [02 00] [00 f3] [02 f6] [ff]| | | | | |zlbytes zltail zllen "2" "5" end
- 第一组4个字节代表zlbytes,0f转成二进制就是1111也就是15,也就是这整个ziplist长度是15个字节。
- 第二组4个字节zltail,0c转成二进制就是1100也就是12,就是说[02 f6]这个尾节点距离起始位置有12个字节。
- 第三组2个字节就是记录了当前ziplist中entry的数量,02转成二进制就是10,也就是说当前ziplist有2个节点
- [00 f3]就是第一个entry,00表示0,因为这是第1个节点,所以前一个节点长度为0,f3转成二进制就是11110011,刚好对应了编码1111xxxx,所以后面四位就是存储了一个0-12的整数。0011转成十进制就是3,减去1得到2,所以第一个entry存储的数据就是2。后面[02 f6]一样的算法可以得出就是5。
- 最后一组1个字节[ff]转成二进制就是11111111,代表这是整个ziplist的结尾。
假如这时候又添加了一个Hello World到列表中,那么就会新增一个entry:
[02] [0b] [48 65 6c 6c 6f 20 57 6f 72 6c 64]
- 第一个字节02转成十进制就是2表示前一个节点长度是2.
- 第2个字节0b转成二进制为00001011,以00开头,符合编码00pppppp,而除掉最开始的两位00计算之后得到十进制11,这就说明后面字节数组的长度是11.
- 第三部分的11个字节就是存储了Hello World的字节数组
2.4 插入流程&连锁更新
在ziplist.c文件的ziplistPush函数是 ziplist 插入数据的函数之一,实际上是去调用 ziplist.c的__ziplistInsert函数。ziplist的添加流程不是很复杂,我们大概的梳理一下:
- 计算出待插入位置的 entry 的前一个节点的长度
- 看看能不能将要插入的数据转成整数编码
- 将待插入数据占用的总字节数赋给 reqlen
- 将待插入位置原来的 entry 的 prevrawlen 字段的变化也加到reqlen上
- 计算前一个节点的内存变化
- 根据计算出来的插入新节点后的 ziplist 大小重新调整压缩列表的大小,
- 如果计算出来前一个节点的长度变化!=0,会再次进行连锁更新操作
- 将待插入位置的 entry 及其后面的所有 entry 都往后移动,并将组装好的新的 entry 放在待插入位置
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {unsigned char *p;p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);return __ziplistInsert(zl,p,s,slen);}
压缩列表这里涉及到了一个连锁更新的概念,我大概唠叨一下:
在压缩列表中当节点的前驱节点长度如果小于 254 字节,那么这个entry的prev_entry_length 属性的占用的空间为1字节,当前驱节点的长度大于或等于254字节,那么prev_entry_length属性占用的空间增长为5字节。这样就会有一个问题:
假如压缩列表有 N 个连续的节点的长度在 250-253 字节之间,那么这个时候它们记录前一个节点的长度的 prev_entry_length 都只需要 1 个字节。此时节点A前添加了一个新节点B,它的长度大于或等于254字节。这时 节点A 的 prev_entry_length 属性需要记录节点B的长度,但是由于节点A的 prev_entry_length 属性只有1个字节,没法记录节点B的长度,就需要将其 prev_entry_length 扩展为5个字节。这就会使得原本长度为250到253字节的节点A变为大于或等于254字节,使得节点B也需要扩展 prev_entry_length 属性为5字节,从而引发 节点B的下一个节点直到节点N的prev_entry_length 属性的改变。
这就是Redis压缩列表的连锁更新,事实上连锁更新这种会造成性能降低的情况很少见,因此对Redis的性能影响很小。
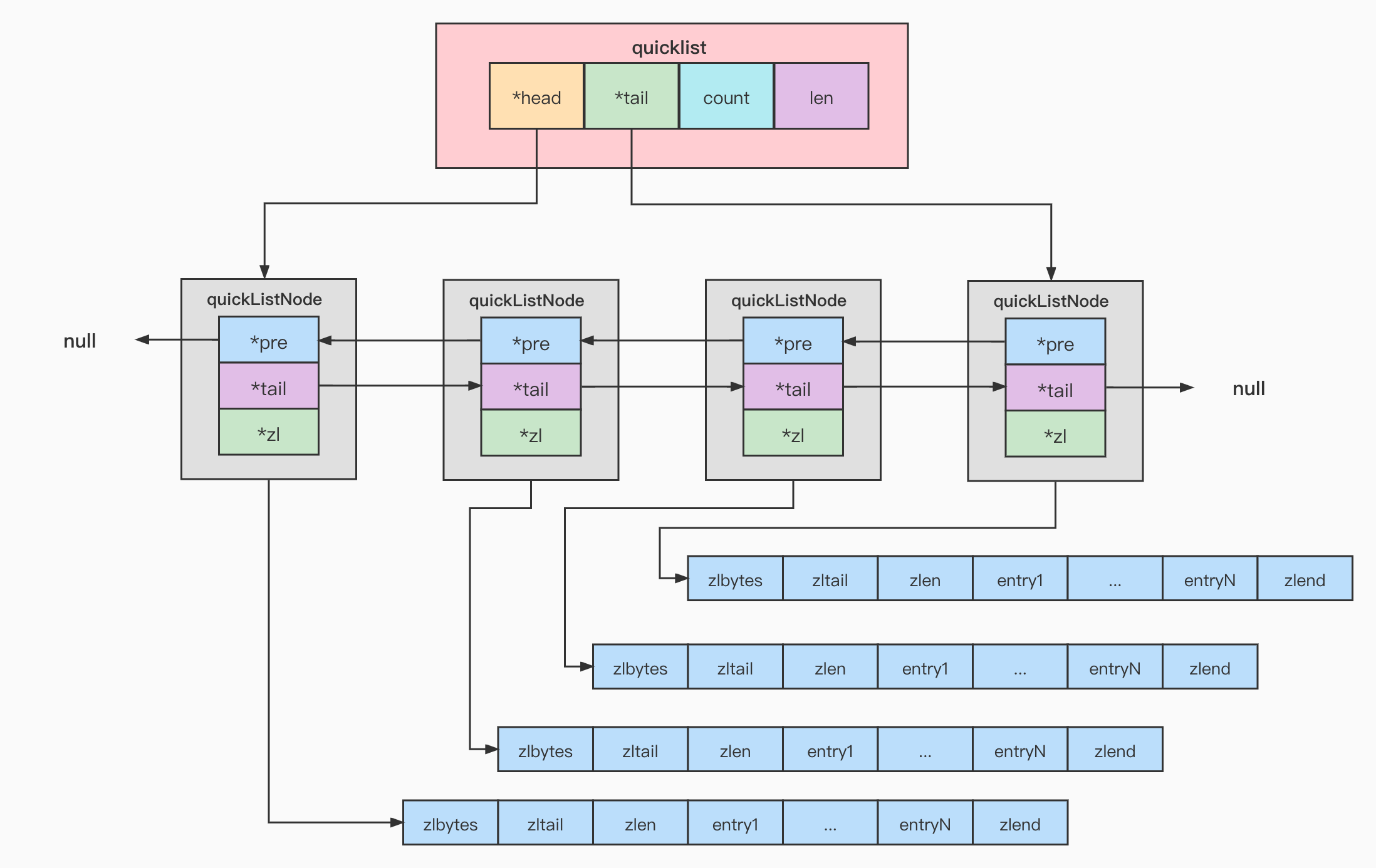
3.quicklist
3.1 存储结构
快速列表是一个双向链表,链表中的每个节点都使用压缩列表存储数据。在老版本的redis中,List的底层数据结构是 ziplist 和 linkedlist。当List中元素的长度比较小或者数量比较少的时候,采用ziplist 存储;当列表对象中元素的长度比较大或者数量比较多的时候,使用双向列表 linkedlist 来存储。但是这样的设计有些问题:
双向链表方便在列表的两端进行push和pop操作,但是它的内存开销比较大。
- 它的每个节点上除了要保存数据之外,还要保存两个指针
2. 双向链表的各个节点是单独的内存块,地址不连续,节点增多了容易产生内存碎片
压缩列表由于是一整块连续内存,所以存储效率很高。但是它每次增删数据都会引发一次内存的 realloc,当压缩列表存储的数据很多的时候,一次realloc 可能会导致大量的数据拷贝,对性能影响很大。所以综合了双向链表和压缩列表的优点,redis作者造出了能够在时间效率和空间效率间取了一个折中的快速列表。
typedef struct quicklist {/* 指向双向列表的表头 */quicklistNode *head;/* 指向双向列表的表尾 */quicklistNode *tail;/* 所有的 ziplist 中一共存了多少个元素 */unsigned long count;/* 双向链表的长度,node 的数量 */unsigned long len;/* fill factor for individual nodes */int fill : QL_FILL_BITS;/* 压缩深度,0:不压缩; */unsigned int compress : QL_COMP_BITS;unsigned int bookmark_count: QL_BM_BITS;/*bookmakrs是realloc这个结构使用的一个可选特性,这样在不使用时就不会消耗内存。*/quicklistBookmark bookmarks[];} quicklist;
redis.conf 相关参数:
| 参数 | 含义 |
|---|---|
| list-max-ziplist-size(fill) | 正数表示单个 ziplist 最多所包含的 entry 个数。 负数代表单个 ziplist 的大小,默认 8k。 -1:4KB;-2:8KB;-3:16KB;-4:32KB;-5:64KB |
| list-compress-depth(compress) | 压缩深度(首尾两端不被压缩的 quicklistNode 节点个数),默认是 0。 1:首尾的 ziplist 不压缩;2:首尾第一第二个 ziplist 不压缩,以此类推 |
快速列表中包含了压缩列表和链表,每个节点的大小就是一个需要考虑的点。如果单个节点的压缩列表中存储的数据太多,会影响插入效率;如果单个节点存储的数据太少,又会跟普通链表一样造成空间浪费。这样一个节点上压缩列表的合理长度不好确定也不好写死,开发人员可以考虑自身的应用场景通过 list-max-ziplist-size参数来设置。
list的设计目标是存放很长的列表数据,当列表很长时占用的内存空间必然会相应增多。但是当列表很长的时候,list中访问频率最高的是两端的数据,中间的数据访问频率较低,如果对使用频率较低的数据进行压缩,在需要使用时再进行解压缩,那就可以进一步减少数据存储的空间。所以,redis 提供参数 list-compress-depth 来进行数据压缩配置,该值最终存放在 quicklist-> compress 属性中。
quicklistNode 中的*zl 指向一个 ziplist,一个 ziplist 可以存放多个元素。ziplist 的结构上面已经说过了,不再重复。
typedef struct quicklistNode {struct quicklistNode *prev; /* 前一个节点 */struct quicklistNode *next; /* 后一个节点 */unsigned char *zl; /* 指向实际的 ziplist */unsigned int sz; /* 当前 ziplist 占用多少字节 */unsigned int count : 16; /* 当前 ziplist 中存储了多少个元素,占 16bit(下同),最大 65536 个 */unsigned int encoding : 2; /* 是否采用了 LZF 压缩算法压缩节点,1:RAW 2:LZF */unsigned int container : 2; /* 2:ziplist,未来可能支持其他结构存储 */unsigned int recompress : 1; /* 当前 ziplist 是不是已经被解压出来作临时使用 */unsigned int attempted_compress : 1; /* 测试用 */unsigned int extra : 10; /* 预留给未来使用 */} quicklistNode;
3.2 插入操作
快速列表的插入操作,其实不是很复杂,他会判断是指定节点后面插入还是指定节点前面插入,然后判断可不可能是这个快速列表还没初始化,这个时候要进行初始化操作,最后还要尝试对快速列表进行压缩。其实它判断头插还是尾插也是在为上层的头插和尾插赋能而已。源码如下:
/** 如果“after”为1,请在“old_node”后插入“new_node”。* 如果“after”为0,请在“old_node”之前插入“new_node”。* 注意:‘new _ node’是*总是*未压缩的,* 所以如果我们将其分配给head或tail,我们不需要对其进行解压缩。*/REDIS_STATIC void __quicklistInsertNode(quicklist *quicklist,quicklistNode *old_node,quicklistNode *new_node, int after) {if (after) {//指定节点后面插入new_node->prev = old_node;if (old_node) {new_node->next = old_node->next;if (old_node->next)old_node->next->prev = new_node;old_node->next = new_node;}if (quicklist->tail == old_node)quicklist->tail = new_node;} else { //指定节点前面插入new_node->next = old_node;if (old_node) {new_node->prev = old_node->prev;if (old_node->prev)old_node->prev->next = new_node;old_node->prev = new_node;}if (quicklist->head == old_node)quicklist->head = new_node;}/* 如果是第一个添加的元素,还得先初始化头节点和尾结点 */if (quicklist->len == 0) {quicklist->head = quicklist->tail = new_node;}if (old_node) //如果是尾插,还要尝试对快速列表进行压缩操作quicklistCompress(quicklist, old_node);quicklist->len++;}
聊完了list所使用的数据结构,现在我们再来看一下它的存储过程。
4.存储过程
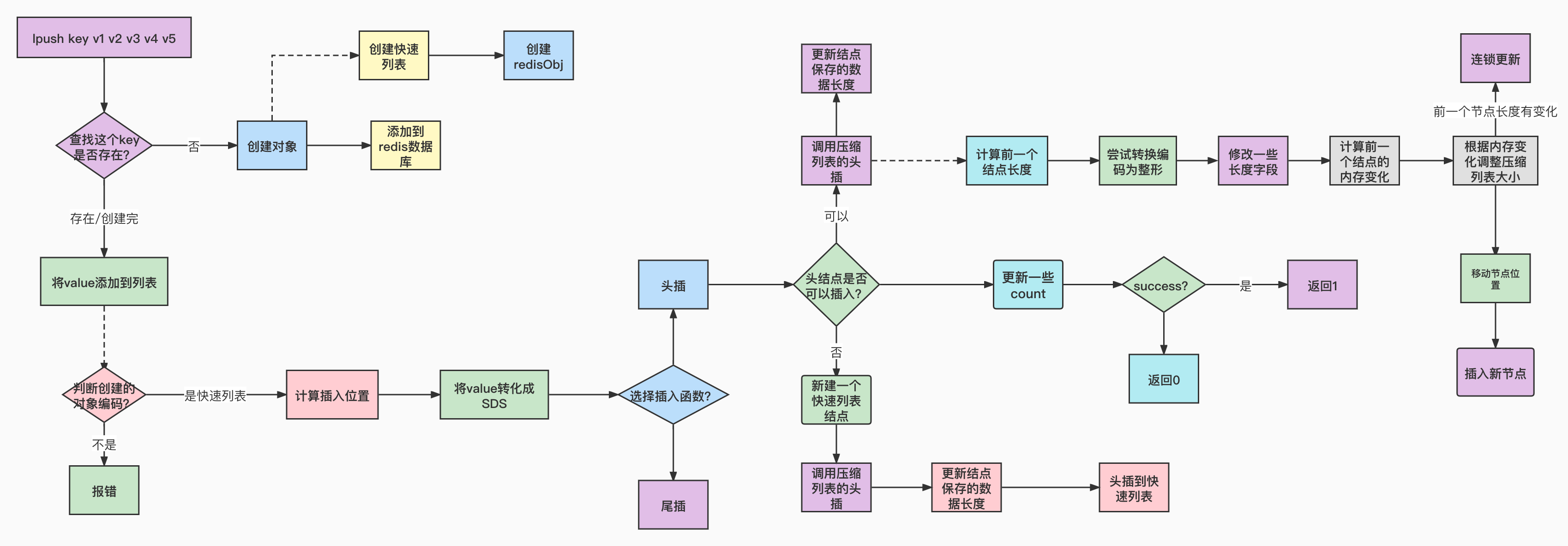
通过断点追踪,列表命令的处理入口在 t_list.c文件的lpushCommand(),主要逻辑是调用 pushGenericCommand() 函数。这个函数比较简短,主要完成的操作如下;
- 调用 lookupKeyWrite() 函数去数据库中查找是否存在目标 key 的数据
- 如果不存在就调用 createQuicklistObject() 函数新建一个存储结构为 quicklist 的 redisObject 对象,通过函数 dbAdd() 将其存储到数据库中,再调用listTypePush() 函数将 value 值插入到列表中
void pushGenericCommand(client *c, int where, int xx) {robj *lobj = lookupKeyWrite(c->db, c->argv[1]);//去数据库中查找是否存在目标 key 的数据if (checkType(c,lobj,OBJ_LIST)) return;if (!lobj) {//不存在...lobj = createQuicklistObject();//新建一个存储结构为 quicklist 的 redisObject 对象quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,server.list_compress_depth);dbAdd(c->db,c->argv[1],lobj);//存储到数据库}for (j = 2; j < c->argc; j++) {listTypePush(lobj,c->argv[j],where);//将 value 值插入到列表中server.dirty++;}...}
4.1 创建对象
我们再来看一下快速列表对象的创建流程也就是createQuicklistObject函数:这个方法的实现在object.c文件中。
- 调用 quicklistCreate() 函数创建 quicklist 结构
- 调用创建redis 对象的通用函数 createObject() 新建一个 redisObject 对象并返回
robj *createQuicklistObject(void) {quicklist *l = quicklistCreate();//创建 quicklist 结构robj *o = createObject(OBJ_LIST,l);//新建一个 redisObject 对象o->encoding = OBJ_ENCODING_QUICKLIST;return o;}
我们再继续追一下quicklistCreate()。
- 申请内存
- 初始化头尾结点和其他属性
quicklist *quicklistCreate(void) {struct quicklist *quicklist;quicklist = zmalloc(sizeof(*quicklist));//此处省略对必要的属性给默认值}
从这里也可以看出来快速列表是一个带有头尾结点的双向链表结构。
至此,对象创建的流程就分析完了,我们再来看一下value是如何添加到快速列表的。
4.2 添加操作
插入的主要流程:
- 判断列表对象的编码类型是否为 OBJ_ENCODING_QUICKLIST,如果不是就报错,根据 where 参数判断数据插入 quicklist 的位置
- getDecodedObject() 将需要插入的数据转成 sds 存储的 String 对象,并调用 sdslen() 函数获取数据的长度
quicklistPush() 函数根据入参 where 选择调用的插入函数
void listTypePush(robj *subject, robj *value, int where) {//判断列表对象的编码类型是否为 OBJ_ENCODING_QUICKLISTif (subject->encoding == OBJ_ENCODING_QUICKLIST) {//计算插入位置int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;value = getDecodedObject(value);//将需要插入的数据转成 sds 存储的 String 对象size_t len = sdslen(value->ptr);//获取转换后的value长度quicklistPush(subject->ptr, value->ptr, len, pos);//选择需要调用的插入函数decrRefCount(value);} else {serverPanic("Unknown list encoding");}}
对于插入函数的选择就分为头插和尾插。我们来看一下头插的过程:
判断 quicklist 的 head 头节点是否可以插入
- 如果可以
- 调用ziplist 的函数将数据插入到该节点的 ziplist 中
- 更新节点保存的数据的长度
- 如果不行
- 新建一个 quicklist 节点
- 调用ziplist 的函数将数据插入到该节点的 ziplist 中
- 更新节点保存的数据的长度
- 将新建节点作为头节点插入到 quicklist
- 更新 quicklist 和 quicklist 头节点的 count,count 用于记录存储的元素的总数
- 插入成功返回1,已经存在返回0
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {quicklistNode *orig_head = quicklist->head;if (likely(//判断 quicklist 的 head 头节点是否可以插入_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {//调用ziplist 的函数将数据插入到该节点的 ziplist 中quicklist->head->zl = ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);quicklistNodeUpdateSz(quicklist->head);//更新节点保存的数据的长度} else { //头节点不能插入quicklistNode *node = quicklistCreateNode();//新建一个 quicklist 节点//调用ziplist 的函数将数据插入到该节点的 ziplist 中node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);quicklistNodeUpdateSz(node);//更新节点保存的数据的长度//将新建节点作为头节点插入到 quicklist_quicklistInsertNodeBefore(quicklist, quicklist->head, node);}//更新 quicklist 和 quicklist 头节点的 count//count 用于记录存储的元素的总数quicklist->count++;quicklist->head->count++;return (orig_head != quicklist->head);}
至此,list的插入过程和整个存储流程就分析完了,接下来我们看一下list数据结构的适用场景。
5.使用场景
5.1 用户消息时间线
因为 List 是有序的,可以用来做用户时间线
5.2 消息 队列
List 提供了两个阻塞的弹出操作:BLPOP/BRPOP,可以设置超时时间。
BLPOP:BLPOP key1 timeout 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOP:BRPOP key1 timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
队列:先进先出:rpush blpop,左头右尾,右边进入队列,左边出队列。
栈:先进后出:rpush brpop

若有收获,就点个赞吧
0 人点赞
