1.存储原理
String 类型的无序集合,最大存储数量 2^32-1(40 亿左右)。
Redis 用 intset 或 hashtable 存储 set。如果元素都是整数类型,就用 intset 存储。如果不是整数类型,就用 hashtable(数组+链表的存来储结构)。
KV 怎么存储 set 的元素?key 就是元素的值,value 为 null。
如果元素个数超过 512 个,也会用 hashtable 存储。
# 集合只有一种特殊的编码方式:当一个集合由恰好是64位有符号整数范围内基数为10的整数组成时。# 以下配置设置设置了集的大小限制,以便使用这种特殊的内存节省编码。set-max-intset-entries 512
我们来看一下添加set元素过程中编码是如何选择的?
- 如果集合的编码格式为hashtable
- 构建dictEntry添加到hashtable
- 如果添加成功,key就是我们要存储的val,value存储存放一个null
- 如果编码格式为intset
- 判断能否转换为长整形
- 如果能转换,以intset编码添加
- 如果添加成功,判断set_max_intset_entries是不是达到了intset转换成hashtable的条件
- 此时说明无法转换为长整形,此时就要以hashtable的形式来存储
- 判断能否转换为长整形
intset,hashtable两种编码都用不了,就抛异常。
int setTypeAdd(robj *subject, sds value) {long long llval;//如果集合的编码格式为hashtable,前面说过,redis的编码类型不能逆转,一旦设置成hashtable,不能在逆转为intset。if (subject->encoding == OBJ_ENCODING_HT) {dict *ht = subject->ptr;dictEntry *de = dictAddRaw(ht,value,NULL);if (de) {//这里只用了key,value存储的nulldictSetKey(ht,de,sdsdup(value));dictSetVal(ht,de,NULL);return 1;}//编码格式为intset} else if (subject->encoding == OBJ_ENCODING_INTSET) {//判断新追加的元素是否能转换成long long int 类型if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {uint8_t success = 0;//以intset编码添加subject->ptr = intsetAdd(subject->ptr,llval,&success);//如果添加成功if (success) {/* 判断set_max_intset_entries是不是达到了intset转换成hashtable的条件 */if (intsetLen(subject->ptr) > server.set_max_intset_entries)setTypeConvert(subject,OBJ_ENCODING_HT);return 1;}} else {/* 这里是无法转换成intset的情况,此时就要存储为hashtable的形式 */setTypeConvert(subject,OBJ_ENCODING_HT);/* 此时的情况明显是 没达到存储为hashtable的长度,但是存储的value类型是不是int*/serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);return 1;}} else { //此时两种编码都不能用,抛异常serverPanic("Unknown set encoding");}return 0;}
最后我们再来看一下,set结构在redis中的保存形式。
2.存储结构
2.1 intset
①定义
intset 内部其实是一个数组,而且存储数据的时候是有序的,其数据查找是通过二分查找来实现的。
typedef struct intset {uint32_t encoding; //编码uint32_t length; // 长度int8_t contents[]; // 元素} intset;
②添加流程
我们来分析一下intset是如何添加一个元素的:
- 判断添加的元素需要编码为何种数据类型
- 比较新元素的编码 valenc 与 当前集合的编码
- 如果当前集合无法存储新元素,需调用函数 intsetUpgradeAndAdd() 对集合进行编码升级
- 否则集合无需升级
- 判断新元素是否已经存在,存在直接返回
- 新元素不存在,扩充集合空间
- 如果新元素插入的位置小于 intset 长度,调用 intsetMoveTail() 将目标位置之后的元素往后移动,为新元素腾出位置
- 将新元素插入指定位置
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {//判断添加的元素需要编码为何种数据类型uint8_t valenc = _intsetValueEncoding(value);uint32_t pos;if (success) *success = 1;/* 比较新元素的编码 valenc 与 当前集合的编码 */if (valenc > intrev32ifbe(is->encoding)) {/* 如果当前集合无法存储新元素,需调用函数 intsetUpgradeAndAdd() 对集合进行编码升级*/return intsetUpgradeAndAdd(is, value);} else {/*否则集合无需升级*//* 判断新元素是否已经存在 */if (intsetSearch(is, value, &pos)) {if (success) *success = 0;return is;}//此时说明新元素不存在,扩充集合空间is = intsetResize(is, intrev32ifbe(is->length) + 1);//如果新元素插入的位置小于 intset 长度,调用 intsetMoveTail() 将目标位置之后的元素往后移动,为新元素腾出位置if (pos < intrev32ifbe(is->length)) intsetMoveTail(is, pos, pos + 1);}//将新元素插入指定位置_intsetSet(is, pos, value);is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);return is;}
③对集合编码进行升级
- 将 intset 的 encoding 编码属性设置为新的值
- 计算新编码下整个 intset 所需的空间,重新为 intset 申请内存
- 将 intset 中的值按照顺序重新填入到新的 inset 中
头插或者尾插新的值
static intset *intsetUpgradeAndAdd(intset *is, int64_t value) {uint8_t curenc = intrev32ifbe(is->encoding);uint8_t newenc = _intsetValueEncoding(value);int length = intrev32ifbe(is->length);int prepend = value < 0 ? 1 : 0;//将 intset 的 encoding 编码属性设置为新的值is->encoding = intrev32ifbe(newenc);//计算新编码下整个 intset 所需的空间,重新为 intset 申请内存is = intsetResize(is, intrev32ifbe(is->length) + 1);/* 将 intset 中的值按照顺序重新填入到新的 inset 中 */while (length--)_intsetSet(is, length + prepend, _intsetGetEncoded(is, length, curenc));/* 头插或者尾插新的值 */if (prepend)_intsetSet(is, 0, value);else_intsetSet(is, intrev32ifbe(is->length), value);is->length = intrev32ifbe(intrev32ifbe(is->length) + 1);return is;}
④查找要添加的元素是否已经存在
这里面的核心逻辑其实就是通过二分查找来查找是否已经存在要添加的元素,使用二分查找,说明set结构一定是有序的。 ```java static uint8_t intsetSearch(intset is, int64_t value, uint32_t pos) { int min = 0, max = intrev32ifbe(is->length) - 1, mid = -1; int64_t cur = -1;
/ 堆set进行判空 / if (intrev32ifbe(is->length) == 0) {
if (pos) *pos = 0;return 0;
} else {
/* 知道找不到值但知道插入位置 */if (value > _intsetGet(is, max)) {if (pos) *pos = intrev32ifbe(is->length);return 0;} else if (value < _intsetGet(is, 0)) {if (pos) *pos = 0;return 0;}
}
while (max >= min) {
mid = ((unsigned int) min + (unsigned int) max) >> 1; cur = _intsetGet(is, mid); if (value > cur) { min = mid + 1; } else if (value < cur) { max = mid - 1; } else { break; }}
if (value == cur) {
if (pos) *pos = mid; return 1;} else {
if (pos) *pos = min; return 0;} }
---
<a name="IB1US"></a>
### 2.2 dict
dict 底层的实现和 Java 中的 HashMap 很像,其容量始终为 2 的次幂,数据下标定位算法也是 hashcode & (size -1)。但是, redis 中 dict 底层哈希表的扩容实现与 Java 中的 HashMap 是不同的,redis 采用的是渐进式hash,前面我也简单介绍过,接下来还会在来唠叨一遍。
所谓的渐进式哈希其实就是,dict 中有两个 hash 表,数据最开始存储在 ht[0] 中,其为初始大小为 4 的 hash 表。一旦 ht[0] 中的size 大于等于 used,也就是 hash 表满了,则新建一个 size*2 大小的 hash 表 ht[1]。此时并不会直接将 ht[0] 中的数据复制进 ht[1] 中,而是在以后的增删改查操作中慢慢将数据复制进去,以后新添加的元素则添加进 ht[1]。
我们看下dict添加元素的过程:这个其实前面已经分析过了,我再来帮大家加深一下印象。
```c
int dictAdd(dict *d, void *key, void *val) {
dictEntry *entry = dictAddRaw(d, key, NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
可以看到这个函数的核心其实在dictAddRaw中,我们来总结下这个插入的流程:
- 判断当前的字典是否在进行 rehash,如果是,则执行一步 rehash,否则忽略。判断 rehash 的依据就是 rehashidx 是否为 -1
- 通过 _dictKeyIndex 找到一个索引,如果返回-1表明字典中已经存在相同的 key,调用_dictKeyIndex
- 根据是否在 rehash 选择对应的哈希表
- 分配哈希表节点 dictEntry 的内存空间,执行插入,插入操作始终在链表头插入,这样可以保证每次的插入操作的时间复杂度一定是 O(1) 的,插入完毕,used属性自增
- dictSetKey 是个宏,调用字典处理函数中的 keyDup 函数进行键的复制
宏:编译前定义的,静态代码替换。
我们再来看一下定位元素下标的过程:
- 判断当前哈希表是否需要进行扩展
- 通过位与计算索引,即插入到哈希表的哪个槽位中
- 查找当前槽位中的链表里是否已经存在该键,如果存在直接返回 -1;这里的 dictCompareKeys 也是一个宏,用到了keyCompare 这个比较键的函数
如果当前没有在做 rehash,那么 ht[1] 必然是一个空表,所以不能遍历 ht[1],需要及时跳出循环 ```c dictEntry dictAddRaw(dict d, void key, dictEntry **existing) { long index; dictEntry entry; dictht *ht; //判断 dict 是否正在 rehash 中,如果在 rehash 过程中, // 则调用 _dictRehashStep() 函数将 hash 表底层数组中某一个下标上的数据迁移到新的哈希表 if (dictIsRehashing(d)) _dictRehashStep(d);
/ 判断哈希表中是否已经存在目标 key,存在则返回 NULL / if ((index = _dictKeyIndex(d, key, dictHashKey(d, key), existing)) == -1)
return NULL;/ 根据是否rehash,选择hash表,如果在 rehash 过程中,则将元素添加到 rehash 新建的哈希表中 / ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; //分配内存,执行插入 entry = zmalloc(sizeof(*entry)); entry->next = ht->table[index]; ht->table[index] = entry; ht->used++;
/ 设置key / dictSetKey(d, entry, key); return entry; }
在这个函数里我们还需要看一下,具体是如何判断是不是需要扩容的。
```c
static int _dictExpandIfNeeded(dict *d) {
/* 如果当前增在进行rehash操作,直接返回。 */
if (dictIsRehashing(d)) return DICT_OK;
/* 如果哈希表是空的,对哈希表进行初始化操作,初始化长度为4。 */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/*
* 如果已使用节点与字典大小的比例达到1:1 ,
* 并且我们在全局设置里面允许哈希表的扩容
* 或者在安全的扩容区间内
* 或者或负载因子达到5。
* 我们将哈希表的桶位扩容为原来的2倍
*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used / d->ht[0].size > dict_force_resize_ratio) &&
dictTypeExpandAllowed(d)) {
return dictExpand(d, d->ht[0].used + 1);
}
return DICT_OK;
}
3.set集合命令的存储过程
分析完了set存储所使用的两种数据结构,我们来看一下set集合命令的存储过程。入口函数在t_set.c文件的saddCommand函数。
- 从数据库中查找以目标 key 存储的 redis 对象是否存在
- 不存在
- 新建 set 类型 redis 对象
- 将新建的 set 集合存入数据库
- 此时数据库中一定存在目标 set 类型对象
- 将本次要添加的数据增加到 set 集合中,具体添加过程上面分析过了
键空间通知&键事件通知的逻辑
void saddCommand(client *c) { robj *set; int j, added = 0; //从数据库中查找以目标 key 存储的 redis 对象是否存在 set = lookupKeyWrite(c->db,c->argv[1]); if (checkType(c,set,OBJ_SET)) return; if (set == NULL) { //不存在则新建 set 类型 redis 对象 set = setTypeCreate(c->argv[2]->ptr); //将新建的 set 集合存入数据库 dbAdd(c->db,c->argv[1],set); } //此时数据库中一定存在目标 set 类型对象 for (j = 2; j < c->argc; j++) { //将本次要添加的数据增加到 set 集合中 [setTypeAdd]在前面已经分析过了 if (setTypeAdd(set,c->argv[j]->ptr)) added++; } if (added) { signalModifiedKey(c,c->db,c->argv[1]); notifyKeyspaceEvent(NOTIFY_SET,"sadd",c->argv[1],c->db->id); } server.dirty += added; addReplyLongLong(c,added); }
3.1 新建set类型的redis对象
主要流程其实就是根据将要添加到集合中的值的类型来创建对应编码的 set 对象:
- 如果可以转化为长整形,创建底层存储结构为 inset 的 set 对象
- 否则,创建创建底层存储结构为哈希表的 set 对象
接下来我们看一下如何创建两种编码的set对象。robj *setTypeCreate(sds value) { //如果可以转化为长整形 if (isSdsRepresentableAsLongLong(value,NULL) == C_OK) //创建底层存储结构为 inset 的 set 对象 return createIntsetObject(); //创建创建底层存储结构为哈希表的 set 对象 return createSetObject(); }
robj *createSetObject(void) {
//创建 dict 对象
dict *d = dictCreate(&setDictType,NULL);
//创建 set 集合对象
robj *o = createObject(OBJ_SET,d);
//将集合对象的编码设置为 OBJ_ENCODING_HT
o->encoding = OBJ_ENCODING_HT;
return o;
}
robj *createIntsetObject(void) {
//创建一个空的intset对象,其实就是分配内存,初始化值
intset *is = intsetNew();
//创建 set 对象
robj *o = createObject(OBJ_SET,is);
//将集合对象的编码设置为 OBJ_ENCODING_INTSET
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
至此,整个set数据类型的底层原理我们就分析完了,接下来看一下set的应用场景。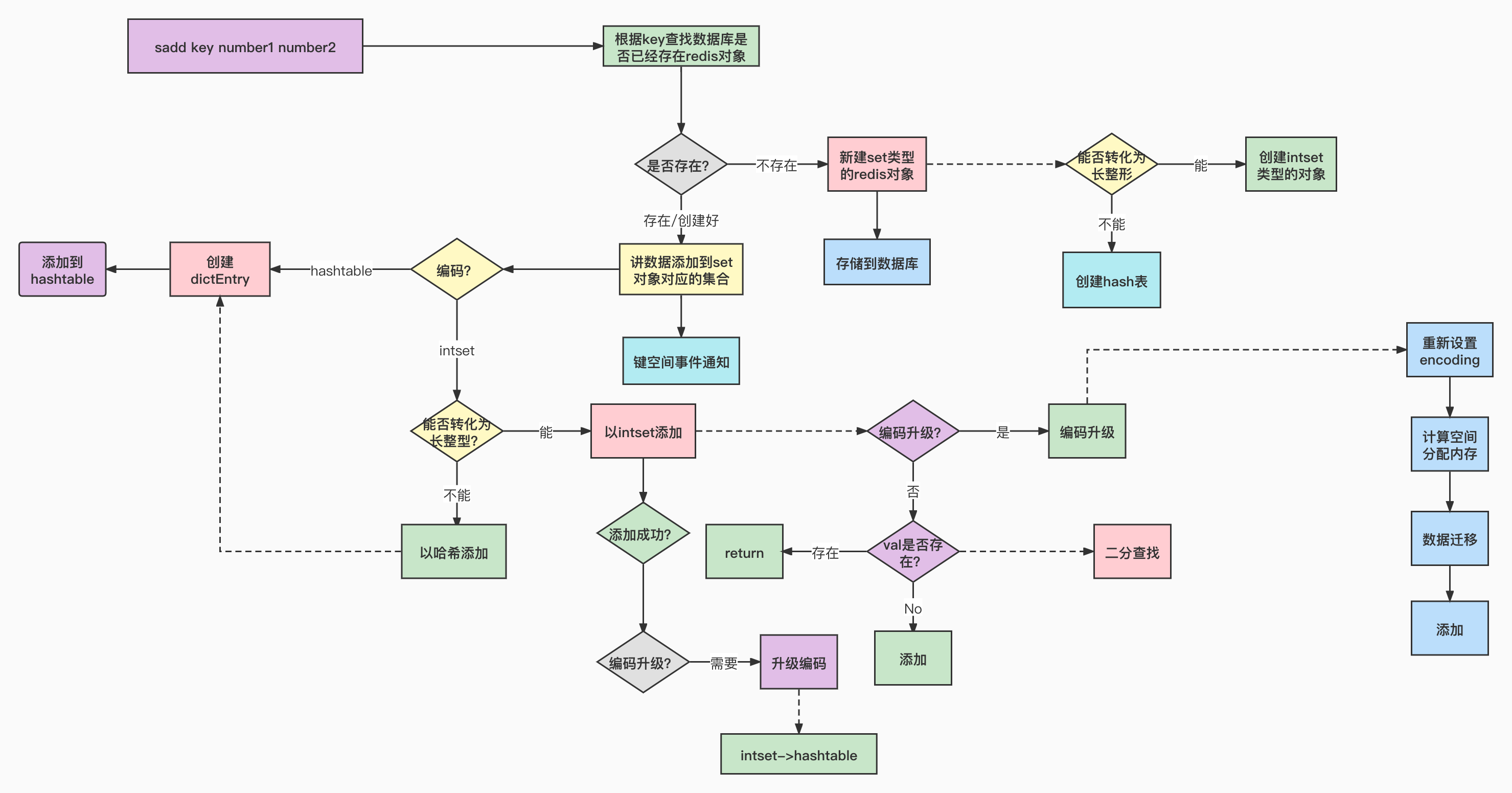
4.应用场景
①抽奖
随机获取元素
spop myset
②点赞,签到,打卡
这条微博的 ID 是 t1001,用户 ID 是 u3001。
用 like:t1001 来维护 t1001 这条微博的所有点赞用户。
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
③商品标签
用 tags:i5001 来维护商品所有的标签。
sadd tags:i5001 画面清晰细腻
sadd tags:i5001 真彩清晰显示屏
sadd tags:i5001 流畅至极
④商品筛选
获取差集
sdiff set1 set2
获取交集( intersection )
sinter set1 set2
获取并集
sunion set1 set2
iPhone11 上市了。
sadd brand:apple iPhone11
sadd brand:ios iPhone11
sad screensize:6.0-6.24 iPhone11
sad screentype:lcd iPhone11
筛选商品,苹果的,iOS 的,屏幕在 6.0-6.24 之间的,屏幕材质是 LCD 屏幕
sinter brand:apple brand:ios screensize:6.0-6.24 screentype:lcd
⑤用户关注,推荐模型
相互关注,我关注的人也关注了他,可能认识的人

若有收获,就点个赞吧
0 人点赞
