- 一.JAVA
- 14 线程池
- 15 SpringMVC 工作原理?
- 16 volatile 的作用
- 17 重写equals方法
- 18 AOP如何实现及实现原理
- 二.Linux
- 三.Hadoop
- 四.MySQL
- 3.索引为什么采用B+树,而不用B-树,红黑树?
- 4.日常工作中,MySQL 如何做优化?
一.JAVA
1.重载重写
重载:必须改变参数列表 可以改变返回值 方法名相同 参数不同 内部不变
重写:外可不变 核心重写
总结:
方法重载是一个类里面定义了多个方法名相同 参数的数量或类型不同成为重载
方法重写是子类与父类的方法名相同,参数的个数和类型相同,返回值也一样成为重写
方法重载是一个类多态的表现方法重写是一个子类和父类的多态表现
2.HashMap
2.1底层原理
- HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
- HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
- HashMap 是无序的,即不会记录插入的顺序。
- HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
无序,不可重复
为什么是无序的?因为不一定挂到哪一个单向链表上的,因此加入顺序和取出也不一样。
怎么保持不可重复?使用equals方法来保证HashMap集合key不可重复,如key重复来,value就会覆盖。存放在HashMap集合key部分的元素,其实就是存放在HashSet集合中,则HashSet集合也需要重写equals和hashCode方法。
hashmap集合的默认初始化容量为16,默认加载因子为0.75,也就是说这个默认加载因子是当hashMap集合底层数组的容量达到75%时,数组就开始扩容。将会创建原来HashMap大小的两倍的bucket数组(jdk1.6,但不超过最大容量),来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
2.2 put()和get()的实现原理
1、map.put(k,v)实现原理
第一步首先将k,v封装到Node对象当中(节点)。
第二步它的底层会调用K的hashCode()方法得出hash值。
第三步通过哈希表函数/哈希算法(取模),将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
2、map.get(k)实现原理
第一步:先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
第二步:通过上一步哈希算法转换成数组的下标之后,在通过数组下标快速定位到某个位置上。重点理解如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
为什么放在hashMap集合key部分的元素需要重写equals方法?因为equals默认比较是两个对象内存地址
2.3与 HashTable主要区别
在于 HashMap 不是同步的,支持 null 键和值等。
存储:HashMap 允许key 和 value 为 null,而 Hashtable 不允许。
线程安全:Hashtable 是线程安全的,而 HashMap 是非线程安全的。
推荐使用:在 Hashtable 的类注释可以看到,Hashtable 是保留类不建议使用,推荐在单线程环境下使用 HashMap 替代,如果需要多线程使用则用 ConcurrentHashMap 替代。
2.4与HashSet主要区别
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
2.5总结:工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。
当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。
当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
3.单例模式
//饿汉式单例public class Hungry {//构造器私有private Hungry() {}//私有化静态变量创建对象private static Hungry Hungry = new Hungry();//静态公共方法 静态工厂方法public static Hungry getInstance() {return Hungry;}}
//懒汉模式public class LazyMan {//私有化构造器private LazyMan() {}//私有化静态变量 用于存储当前对象private static LazyMan lazyMan;//以自己实例为返回值的静态的公共方法 静态工厂方法public static LazyMan getInstance() {//没有就创建if (lazyMan == null) {lazyMan = new LazyMan();}return lazyMan;}}
4.Array 和 ArrayList 有何区别?
Array 可以存储基本数据类型和对象,ArrayList 只能存储对象
5.并行和并发有什么区别?
并行:多个处理器或多核处理器同时处理多个任务。
并发:多个任务在同一个 CPU 核上,按细分的时间片轮流(交替)执行,从逻辑上来看那些任务是同时执行。
6.面向对象三大特性:
封装:将类的某些信息隐藏在类的内部,不允许外部程序直接访问,而是通过该类提供的方法来实现对隐藏信息的访问和操作。
- 好处:只能通过规定方法访问数据/隐藏类的实例细节,方便修改和实现
- 继承:类和类的继承。
好处:子类拥有父类的所有属性和方法,从而实现了代码的复用
- 多态:同一个行为具有不同表现形式或形态的能力,或是同一个接口使用不同的实例执行不同操作。
三个必要条件:继承
重写
父类引用指向子类对象 Parent p=new Child();
好处:使程序有良好的扩展性,可以对所有类的对象进行通用处理。
7.接口和抽象类区别
1.一个类只能继承一个抽象类,而一个类却可以实现多个接口。
2.抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;且必须给其初值,所以实现类中不能重新定义,也不能改变其值;抽象类中的变量默认是 friendly 型,其值可以在子类中重新定义,也可以重新赋值。
3.抽象类中可以有非抽象方法,接口中则不能有非抽象方法。
4.接口可以省略abstract 关键字,抽象类不能。
5.接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象
设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计
8.创建线程四种方法
1.继承Thread类
2.实现Runable接口
3.通过Callable和future创建线程
实现call方法
4.通过线程池
runnable 和 callable 有什么区别?
runnable没有返回值 callable可以有返回值,callable可以看作runnable补充
线程池都有哪些状态?
- RUNNING:这是最正常的状态,接受新的任务,处理等待队列中的任务。
- SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
- TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()。
TERMINATED:terminated()方法结束后,线程池的状态就会变成这个。
9.final、finally、finalize 有什么区别?
final:是修饰符,如果修饰类,此类不能被继承;如果修饰方法和变量,则表示此方法和此变量不能在被改变,只能使用。
- finally:是 try{} catch{} finally{} 最后一部分,表示不论发生任何情况都会执行,finally 部分可以省略,但如果 finally 部分存在,则一定会执行 finally 里面的代码。
finalize: 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法。
10.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
答:用hashmap的分桶法,将100G文件分成1000份,将每个IP地址映射到相应文件中:file_id = hash(ip) % 1000
• 在每个文件中分别求出最高频的IP,再合并 Hash分桶法:
• 使用Hash分桶法把数据分发到不同文件
• 各个文件分别统计top K
• 最后Top K汇总
Linux命令,假设top 10:sort log_file | uniq -c | sort -nr k1,1 | head -1011.海量日志数据,提取出某日访问百度次数最多的那个IP。
算法思想:分而治之+Hash
1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理;
2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值(hash映射),把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址;
3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址;
4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP;
需要注意的是,相同的IP经过Hash映射之后一定处于同一组中,故这种方法一定能统计到出现频率最大的那个IP。12. http建立连接过程,和https区别
HTTP 与 HTTPS 区别
HTTP 明文传输,数据都是未加密的,安全性较差,HTTPS(SSL+HTTP) 数据传输过程是加密的,安全性较好。
- 使用 HTTPS 协议需要到 CA(Certificate Authority,数字证书认证机构) 申请证书,一般免费证书较少,因而需要一定费用。证书颁发机构如:Symantec、Comodo、GoDaddy 和 GlobalSign 等。
- HTTP 页面响应速度比 HTTPS 快,主要是因为 HTTP 使用 TCP 三次握手建立连接,客户端和服务器需要交换 3 个包,而 HTTPS除了 TCP 的三个包,还要加上 ssl 握手需要的 9 个包,所以一共是 12 个包。
- http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80,后者是 443。
HTTPS 其实就是建构在 SSL/TLS 之上的 HTTP 协议,所以,要比较 HTTPS 比 HTTP 要更耗费服务器资源。
TCP 三次握手
第一次握手:客户端尝试连接服务器,向服务器发送 syn 包(同步序列编号Synchronize Sequence Numbers),syn=j,客户端进入 SYN_SEND 状态等待服务器确认
- 第二次握手:服务器接收客户端syn包并确认(ack=j+1),同时向客户端发送一个 SYN包(syn=k),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态
- 第三次握手:第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手
13. JVM
https://www.cnblogs.com/ityouknow/p/5610232.html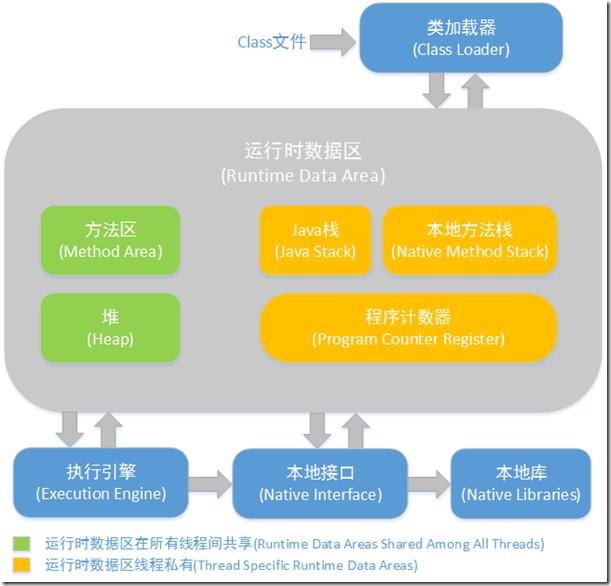
累加载
类的生命周期包括:加载、链接、初始化、使用和卸载,其中加载、链接、初始化,属于类加载的过程,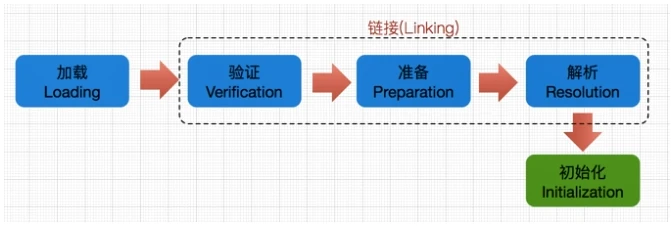
上面filenotfound写错 应为classnotfound
(1)如果一个类加载器接收到了类加载的请求,它自己不会先去加载,会把这个请求委托给父类加载器去执行。
(2)如果父类还存在父类加载器,则继续向上委托,一直委托到启动类加载器:Bootstrap ClassLoader
(3)如果父类加载器可以完成加载任务,就返回成功结果,如果父类加载失败,就由子类自己去尝试加载,如果子类加载失败就会抛出ClassNotFoundException异常,这就是双亲委派模式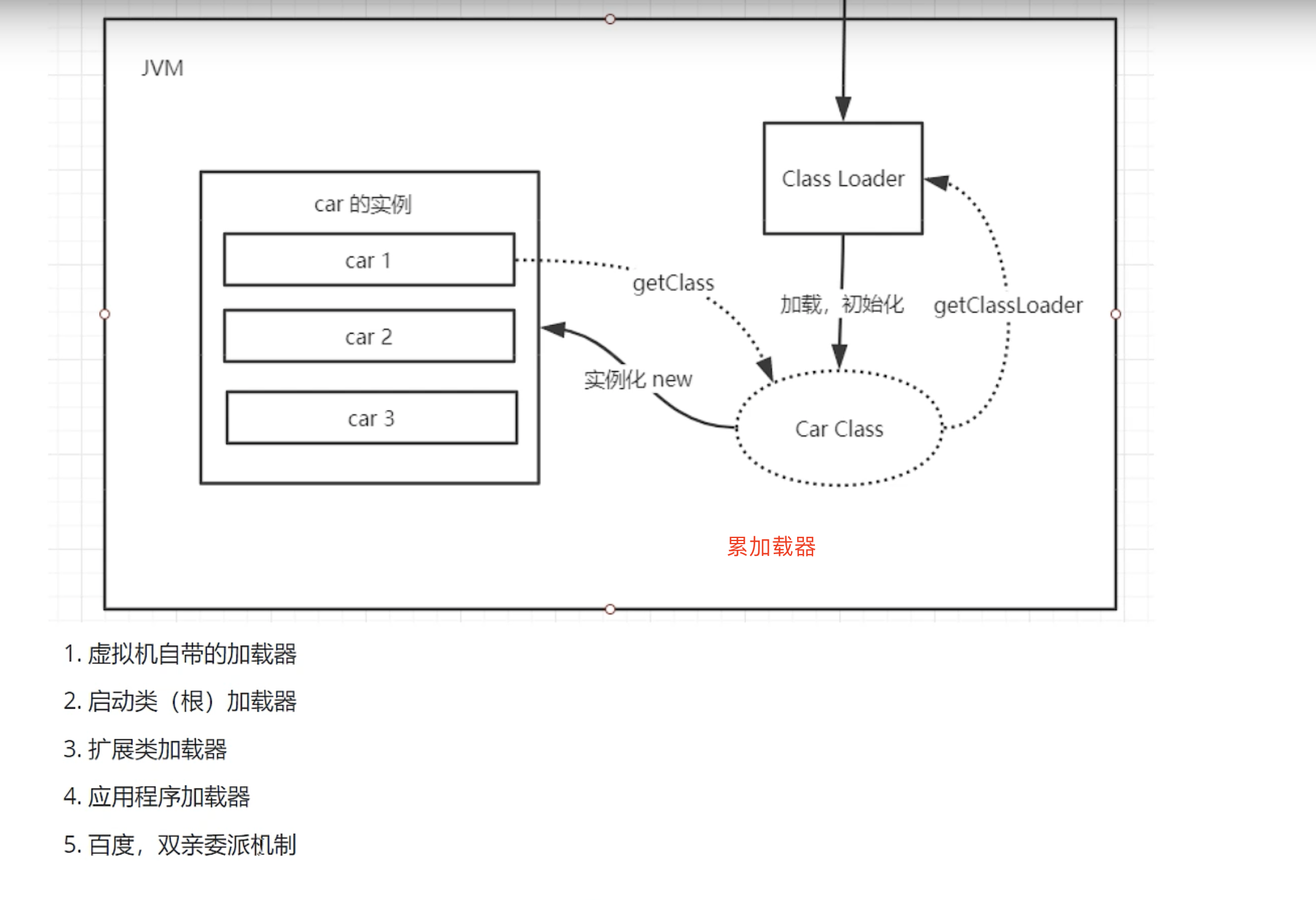
native

14 线程池
https://www.cnblogs.com/chiangchou/p/thread-pool.html
15 SpringMVC 工作原理?
1)客户端发送请求到 DispatcherServlet
2)DispatcherServlet 查询 handlerMapping 找到处理请求的 Controller
3)Controller 调用业务逻辑后,返回 ModelAndView
4)DispatcherServlet 查询 ModelAndView,找到指定视图
5)视图将结果返回到客户端
16 volatile 的作用
https://zhuanlan.zhihu.com/p/138819184
主要作用有两点: - 保证变量的内存可见性 - 禁止指令重排序
使用 volatile 修饰共享变量后,每个线程要操作变量时会从主内存中将变量拷贝到本地内存作为副本,当线程操作变量副本并写回主内存后,会通过 CPU 总线嗅探机制告知其他线程该变量副本已经失效,需要重新从主内存中读取。
volatile 保证了不同线程对共享变量操作的可见性,也就是说一个线程修改了 volatile 修饰的变量,当修改后的变量写回主内存时,其他线程能立即看到最新值
17 重写equals方法
https://blog.csdn.net/u013521220/article/details/108761048
https://www.cnblogs.com/1693977889zz/p/7089320.html
18 AOP如何实现及实现原理
https://blog.csdn.net/qq_41701956/article/details/84427891
二.Linux
三.Hadoop
1.spark为什么比hive速度快?
- spark底层不需要调用MapReduce,而hive底层调用的是MapReduce;
- spark基于内存计算,而hive基于磁盘计算,内存的读取速度远超过磁盘读取速度;
- spark以线程方式进行运行,而hive以进程方式运行,一个进程中可以跑多个线程,进程要比线程耗费资源和时间;
详细原因:
1.消除了冗余的HDFS读写
Hadoop每次shuffle操作后,必须写到磁盘,而Spark在shuffle后不一定落盘,可以cache到内存中,以便迭代时使用。如果操作复杂,很多的shufle操作,那么Hadoop的读写IO时间会大大增加。
2.消除了冗余的MapReduce阶段
Hadoop的shuffle操作一定连着完整的MapReduce操作,冗余繁琐。而Spark基于RDD提供了丰富的算子操作,且reduce操作产生shuffle数据,可以缓存在内存中。
3.JVM的优化
Spark Task的启动时间快。Spark采用fork线程的方式,Spark每次MapReduce操作是基于线程的,只在启动。而Hadoop采用创建新的进程的方式,启动一个Task便会启动一次JVM。
Spark的Executor是启动一次JVM,内存的Task操作是在线程池内线程复用的。
2.Hive-sql和sql的区别是什么?
- Hive-sql不支持等值连接,而sql支持;
- Hive-sql不支持“Insert into 表 Values()”、UPDATA、DELETE操作,而sql支持;
- Hive-sql不支持事务,而sql支持。
- Hive不支持将数据插入现有的表或分区中
Hive仅支持覆盖重写整个表。insert overwrite 表 (重写覆盖) - Hive不支持 Insert into 表 Values(), UPDATA , DELETE 操作
insert into 就是往表或者分区中追加数据。 - Hive支持嵌入mapreduce程序,来处理复杂的逻辑
- Hive支持将转换后的数据直接写入不同的表,还能写入分区,hdfs和本地目录
避免多次扫描输入表的开销。3.MapReduce 的过程? shuffle 过程中经历了几次 sort ?
https://www.cnblogs.com/bigband/p/13518507.html
https://blog.csdn.net/Android_xue/article/details/80334975
总结:
对文本进行分片,将每片内的数据作为单个 Map Task 的输入。map读取split的数据(一行一行的读取)然后进行分区、快速排序,结果写入内存缓冲区,内存缓冲区默认是100MB。默认达到80%会进行溢写磁盘。然后重新利用这个缓冲区。磁盘中会生成很多个溢写小文件,而这些小文件内部是有序的,但小文件和小文件之间是无序的,所以需要进行一次归并排序(Combiner)形成一个全盘有序的文件。缓冲区的作用就是批量收集Map结果,减少磁盘I/O影响。
由于一个split对应一个map,reduce端是从多个map中拉取数据,先放到内存缓冲区中,当内存中的数据达到一定阈值时,溢写到磁盘, 进行merge归并排序为一个有序的文件,最终每个相同的key分为一组执行一次reduce方法。
4.HIve和数据仓库有什么区别?
5. Spark比mr快的原因分析?
1、硬件
基于内存 快100倍链接
2、软件-架构设计-运行模式
将传统的MR当中的多进程调度任务改成为多线程任务调度,更加轻量级和灵活,执行效率更高。(Executor可以启动多个task任务
6.kafka如何实现高吞吐量?
- 顺序读写:kafka的消息是不断追加到文件中的,不需要硬盘磁头的寻道时间
- 零拷贝:把所有的消息放到一个文件中,当消费者需要数据的时候直接将文件发送给消费者
- 分区:kafka中的topic的内容被分为多个partition存在,每个partition又被分为多个segment存在,所以每 次操作都是针对一小部分操作,轻便,增加了并行操作的能力。
- 批量发送:producer发送消息的时候,可以将消息存在本地,等消息条数到了固定值再发送到kafka
- 数据压缩:Producer可以通过对消息进行gzip或snappy格式压缩,减少了传输的数据量,减轻了对网络传输的压力。
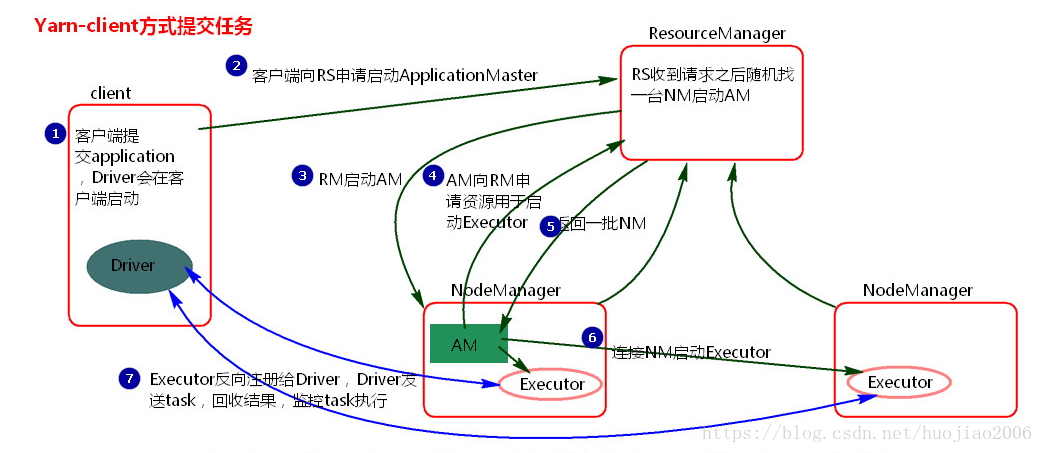
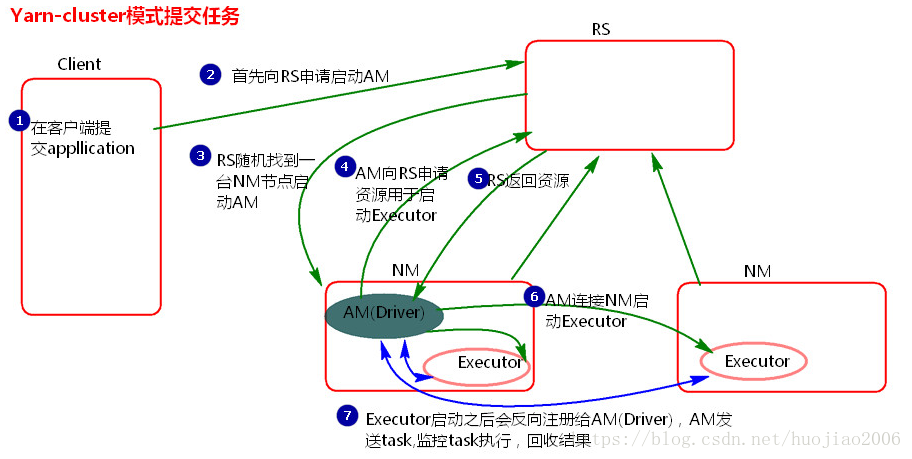
7.yarn-client和yarn-cluster的区别
1.在Yarn-cluster模式中Driver可以运行在ApplicationMaster上,Client提交完了可以直接关闭,
ApplicationMaster负责资源申请和驱动程序运行,适合生产环境。
2.在Yarn-client模式中,Driver运行在client上面,client提交完了不能关闭,要保持跟excutor通信, ApplicationMaster只负责资源申请,运行程序由client负责,这种模式适合交互和调试。
- 数据压缩:Producer可以通过对消息进行gzip或snappy格式压缩,减少了传输的数据量,减轻了对网络传输的压力。
8.Yarn三种调度策略
| 调度名称 | 特点 |
|---|---|
| FIFO Scheduler 先进先出 | 默认的队列内部调度器,只有一个队列,所有用户共享,容易阻塞,一般不在生产环境使用。 |
| Capacity Scheduler容器调度器 | 多用户、分队列、ACL控制、不支持抢占式,队列内部依然是FIFO,也可以采用Fair |
| Fair Scheduler公平调度器 | 多用户、分队列、ACL控制、支持抢占式,队列内部不是FIFO,而是公平分配的方式 |
9.orc为什么存储压缩效率高?
10.在spark rdd中再unit10个rdd为什么不行?
11. presto
https://tech.meituan.com/2014/06/16/presto.html
12 YARN 流程
- client向RM提交应用程序,其中包括启动该应用的ApplicationMaster的必须信息,例如ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
- ResourceManager启动一个container用于运行ApplicationMaster。
- 启动中的ApplicationMaster向ResourceManager注册自己,启动成功后与RM保持心跳。
- ApplicationMaster向ResourceManager发送请求,申请相应数目的container。
- ResourceManager返回ApplicationMaster的申请的containers信息。申请成功的container,由ApplicationMaster进行初始化。container的启动信息初始化后,AM与对应的NodeManager通信,要求NM启动container。AM与NM保持心跳,从而对NM上运行的任务进行监控和管理。
- container运行期间,ApplicationMaster对container进行监控。container通过RPC协议向对应的AM汇报自己的进度和状态等信息。
- 应用运行期间,client直接与AM通信获取应用的状态、进度更新等信息。
- 应用运行结束后,ApplicationMaster向ResourceManager注销自己,并允许属于它的container被收回。
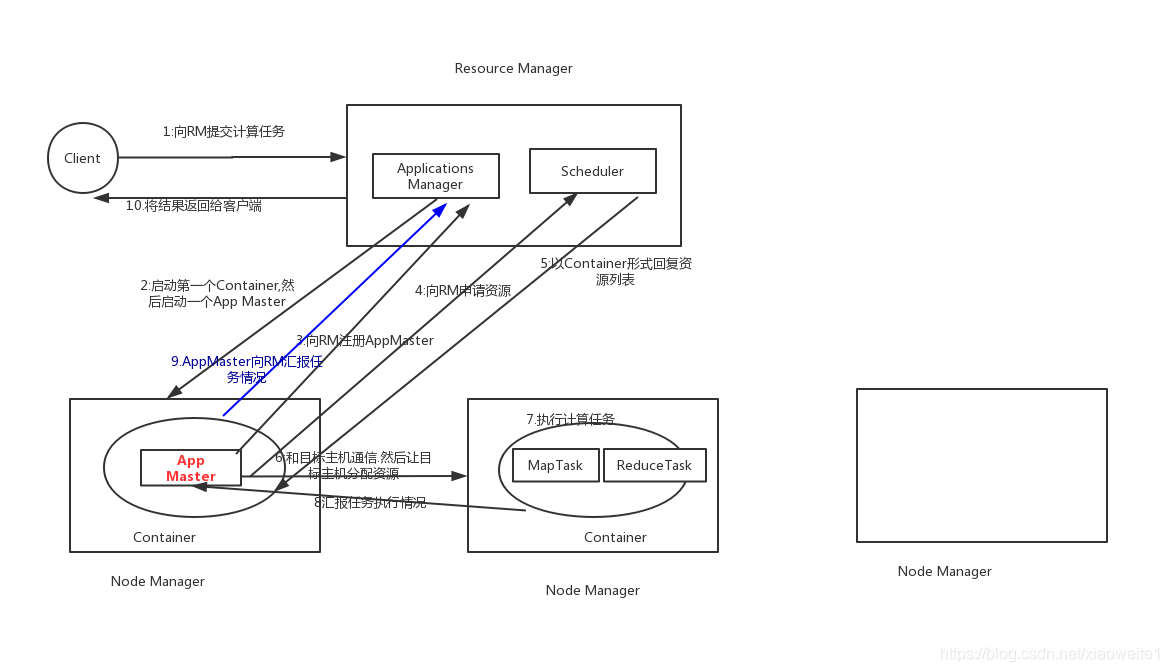
12 spark架构 流程
https://www.cnblogs.com/bettergoo/p/15799446.html
https://zhuanlan.zhihu.com/p/70424613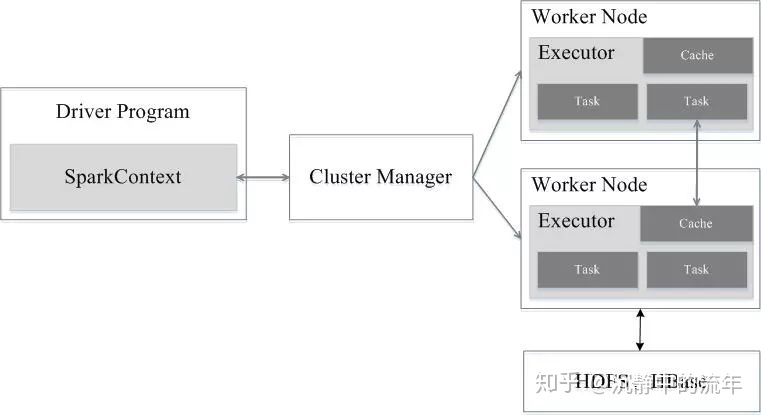
1,Application首先被Driver构建DAG图并分解成Stage。
2,然后Driver向Cluster Manager申请资源。
3,Cluster Manager向某些Work Node发送征召信号。
4,被征召的Work Node启动Executor进程响应征召,并向Driver申请任务。
5,Driver分配Task给Work Node。
6,Executor以Stage为单位执行Task,期间Driver进行监控。
7,Driver收到Executor任务完成的信号后向Cluster Manager发送注销信号。
8,Cluster Manager向Work Node发送释放资源信号。
9,Work Node对应Executor停止运行。
四.MySQL
1.数据库事务和隔离级别
原子性(Atomicity)
一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,多个并发事务之间要相互隔离。
持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
- 原子性。一个事务中的操作要么全部成功,要么全部失败。
- 持久性。数据的改变永久保存在数据库中。
- 一致性。总是从一个一致性的状态转换到另一个一致性的状态
- 隔离性。一个事务的修改在提交前,其他事务是感知不到的
上介绍完事务的四大特性(简称ACID),现在重点来说明下事务的隔离性,当多个线程都开启事务操作数据库中的数据时,数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性,在介绍数据库提供的各种隔离级别之前,我们先看看如果不考虑事务的隔离性,会发生的几种问题:
脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
虚读(幻读)
幻读是事务非独立执行时发生的一种现象
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
现在来看看MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
数据库默认隔离级别: mysql —-repeatable,
oracle,sql server —-read commited
2.kafka数据分区策略
四种策略
一、指定分区号,数据会直接发送到所指定的分区
二、没有指定分区号,指定了数据的key,可以通过key获取hashCode决定数据发送到哪个分区
三、都没有指定的话,会采取round-robin fashion,是kafka的轮询策略
四、还可以自定义分区策略
四种策略的Java实现
其他的代码都不需要变,只需要更改ProducerRecord()里面的值即可
//既不指定分区号也不指定数据的key producer.send(new ProducerRecord<String, String>("test", "这是第" + i + "条message"));
//指定数据的key,通过key获取hashCode //如果使用key作为分区依据,一定要让它是变化着的,否则就会将全部数据发送到一个分区 producer.send(new ProducerRecord<String, String>("test", "mykey"+i , "这是第" + i + "条message"));
//指定分区号 //指定分区号时也必须指定key producer.send(new ProducerRecord<String, String>("test", 0,"mykey","这是第" + i + "条message"));自定义分区策略见文章:【Kafka】自定义分区策略
举例
现在有一个Topic,一共有5个分区,因为操作不当,导致 0,1,2 三个分区数据太多,3,4 分区数据太少,发生了数据倾斜
解决办法
可以用第一种策略指定分区号,也可以用第四种策略,自定义分区策略
3.索引为什么采用B+树,而不用B-树,红黑树?
答案:提升查询速度,首先要减少磁盘IO次数,也就是要降低树的高度。
- 平衡二叉树、红黑树,都属于二叉树。时间复杂度为O(n),当表的数据量上千万时,树的深度很深,mysql读取时消耗大量 IO。另外,InnoDB引擎采用页为单位读取,每个节点一页,但是二叉树每个节点储存一个关键词,导致空间浪费。
- B-树,非叶子节点存储数据,占用较多空间,导致每个节点的指针少很多,无形增加了树的深度。
B+树数据都存储在叶子节点,非叶子节点只存储健值+指针,索引树更加扁平,三层深度可以支持千万级表存储。同时叶子节点之间通过链表关联,范围查找更快。
4.日常工作中,MySQL 如何做优化?
答案:
1、分页优化。比如电梯直达,limit 100000,10 先查找起始的主键id,再通过id>#{value}往后取10条
- 2、尽量使用覆盖索引,索引的叶节点中已经包含要查询的字段,减少回表查询
- 3、SQL优化(索引优化、小表驱动大表、虚拟列、适当增加冗余字段减少连表查询、联合索引、排序优化、慢日志 Explain 分析执行计划)。
- 4、设计优化(避免使用NULL、用简单数据类型如int、减少 text 类型、分库分表)。
- 5、硬件优化(使用SSD 减少 I/O 时间、足够大的网络带宽、尽量大的内存)

若有收获,就点个赞吧
0 人点赞
