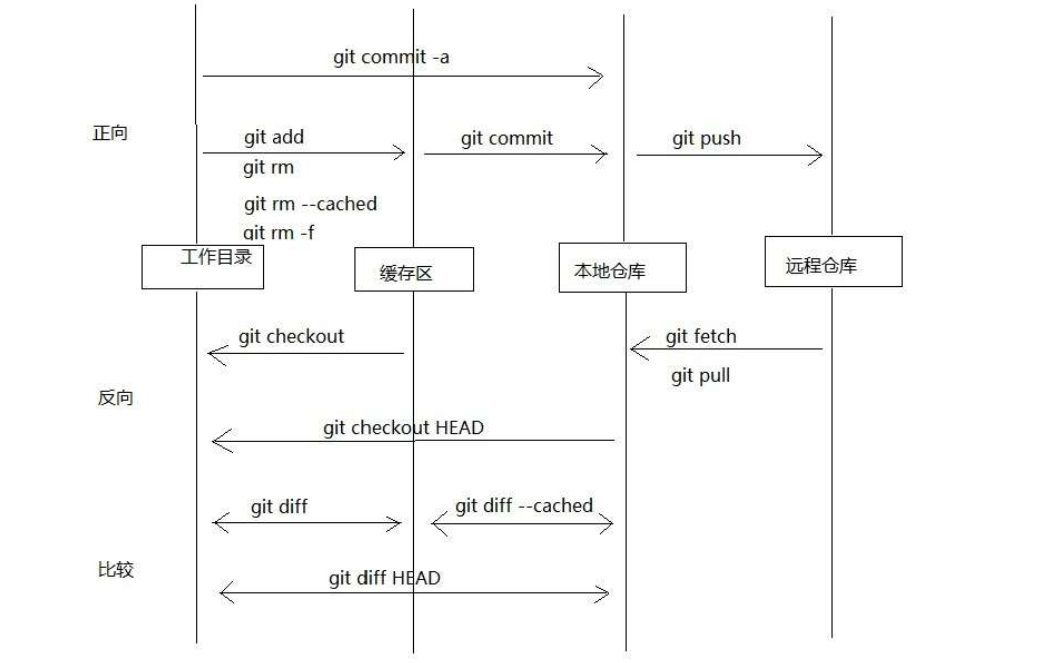
- 一.回顾
- 二.前期准备
- 三.源数据准备
- ! /bin/bash
hive -e “
use yzj;
weibo_origin 建表语句或weibo_product 建表语句
“
然后sh weibo_origin.sh
sh weibo_product.sh
即可在Hive建好两个表 - 3.将解压完的明文每天数据表,按天 load 到 weibo_origin 载入原始数据
- 4.数据检验与校正
- 5.清洗原始数据表 weibo_origin,按天分区插入到 weibo_product 表中
- ! /bin/bash
- ! /bin/bash
- 定义数据库名称
- 定义jar包路径
- 定义classpath
- 定义数据源和输出表
- 写sql实现表的生成
- 1.use db
- 2.add jar jarpath
- 3.创建临时函数 将classpath加入其中
- 4.一次查询多次插入语法
- 4.把表推送到mysql表中
- 五. 前端Web页面展示
- 六. 项目脚本化
一.回顾
链式学习法
- 就是把所学的内容串成一条线,按照线的脉落进行预习、复习、自我出题和review等过程。
- 需求概述的输入和输出
- 输入: 用户需求- 输出:- PRD-product requirement document
- 需求分析的IO
- Input:PRD- Output:- 标准:需求分析说明书- 业界:逻辑模型(原型)- 解决问题:功能交互问题- Axure- 墨刀- 数据类型的开发项目- 一个完整的数据节点的处理链路- 即:数据流-Data Flow- 需求概述要解决什么问题- 宏观上描述清楚项目要做一个什么事情- 需求分析要解决什么问题- 可行性问题
- 技术方案的IO
- Input:- 数据流图-DAG- Ouput:- 数据流图当中的每个节点当中添加系统化、具体的技术解决方法
- 开发计划IO
- Input:数据流图当中的每个节点当中添加系统化、具体的技术解决方法- Output:任务排期表
- 数据开发人员的最基本专业素养之一
- 数据敏感性
- 24小时-1440分钟-86400秒
- 数据敏感性
- 专业术语
- 单天活跃用户数-DAU
- 国内开源市场不太景气的原因
- 没有形成一套完备的、可持续的运营体系。
- 国外开源市场比较历害的原因
- 形成一套比较健全、可持续的良性运营体系闭环。
- Apache、Github
- 文件格式和压缩格式
- 文件格式:csv,txt,xml,word,excel等。
- 压缩格式:zip,rar,gzip,bz2,snappy,lzo等等。
- 应用系统当中删数据的常规操作
- 是真的删除掉物理数据吗?
- 现在的标准做法,都是标记删除。
- 心得体会
- 做正确的事情,然后事情做正确。
- 机器角色划分
- 开发机:写代码、开发项目的机器
- 线上机器(生产机器): 发布项目后,正式对外部用户提供服务的机器
- 堡垒机(跳转机):为用户和生产机器之间搭一个安全缓冲地带,类似于各个地点的大门、入口。
- 入口机:用于让用户通过该机器可以操作远程集群。
- 机器(大数据)集群: 就是常规意义上真正解决分布式存储、调度、计算等任务的众多机器组成的集群。
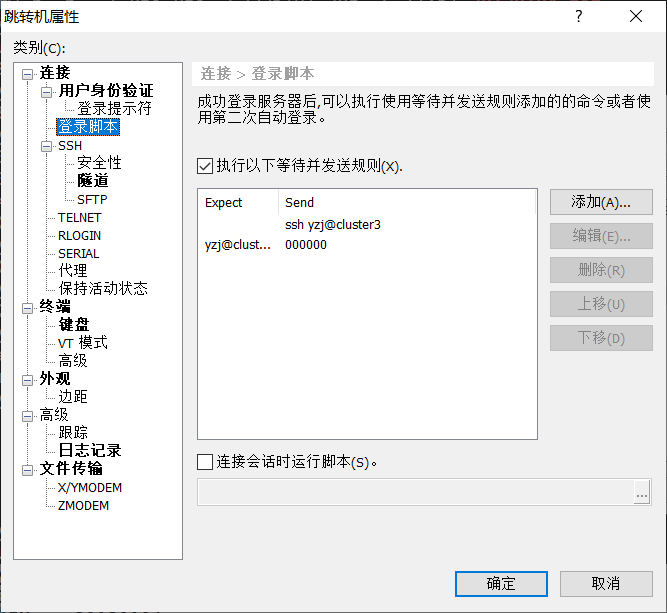
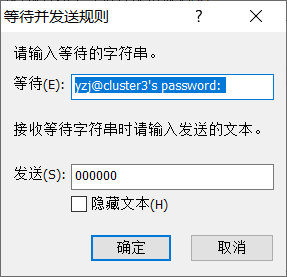
- linux自动登陆入口机的方法
- linux expect机制:解决linux系统内部人机自动交互的问题。
- expect通过什么机制实现的人机自动交互
- 即通过expect脚本自动填充之人工交互时候的输入,从而实现自动交互。
- 大数据中的数据是以什么为度量单位?
- 以记录为基本度量单位
- Java序列化和反序列化是干什么
- 序列化:serializable
- 将内存里的对象数据转化成二进制数据。
- 什么情况下需要序列化
- 当你的对象或是其它类型数据需要存入磁盘或是外部传递的时候。
- 反序列化:de-serializable
- 将二进制数据转换成内存当中的对象类型的数据
- 反序列化
- 当需要将磁盘当中的二进制文件数据转化成内存当中的对象时。
- 序列化:serializable
- Hive分区操作的进一步细化说明
- 虚字段
- 物理呈现形式:一个分区即为其hdfs路径当中的一个目录
- Hive的一次查询多次插入
- 概念:一次查询母表,多次并行插入多张子表。
- 特点特征
- 执行效率和代码复杂度明显优于常规的SQL代码实现多次查询同一张表生成其子表的情况。
- 应用场景
- 只要涉及一张大表潜在会生成出多张小表的情况,均可以使用。
- 代码实现
- From big_table
- Insert overwrite table1 … where …
- Insert overwrite table2 … where …
- Insert overwrite table3 … where …
- 建表的注意事项:
- 表的内外表类型- 表结构和类型- 分区分桶设计- 存储类型选择
- 表数据构成分析
- 元数据:描述数据的数据- 实体数据:真正承载真实数据的内容
- DAG:有向无环图,数据表的操作都可以抽象成一个DAG。
- 数据仓库类项目的目录规范
- Create- Config- Deal- Udf- Data
- 表创建sql编写
- Sql代码的文件名称和表名称保持一致- Hive –e “hivesql”
- shell脚本的执行方式
- 4种
- 相对路径:用.导航,要求被执行文件有x权限。
- 绝对路径:用”/”来导航,要被执行文件有x权限。
- Sh:无条件执行传入的shell脚本,sh执行时候会新开一个session会话执行shell脚本,不会对当前窗口会话产生影响。
- Source:无条件执行传入的shell脚本。执行时候是在当前窗口的session当中执行,会直接影响当前窗口会话。
- 4种
- Hive load方式
- Load data local inpath—从文件本地装载- Load data inpath—从hdfs装载。
- HIve 3.0 load操作注意事项
- Load时,会将hdfs路径当中的源文件-move到hive 表当中。
- 为什么要move,而不是copy?
- 减少不必要的副本个数
- Move的话还是3个副本,否则的话则是6个太多了。
- Maven中的package和install有什么区别和联系?
- Package:只负责打包- Install:package+包安装,即将包copy到指定的maven仓库,默认是本地的.m2目录。
- Maven scope的作用
- Scope: 范围,视野- Provided: 正常开发则正常依赖,只有到打包的时候,将该jar包进行去除在打包范围之外。- Compile- Test- Runtime- System
- 分布式架构
- 有中心化-master/slave结构- Hdfs:中心NameNode /孩子节点DataNode- Yarn:中心ResourceManager/孩子节点Nodemanager等- 去中心化-弱中心节点- Git- 无中心化-无中心节点- 比特币
二.前期准备
1.scp 复制文件给别人
scp 20120103.zip 20120104.zip yxd@cluster3:~/2.设置Linux自动登录跳转机
3.文件查询工作
[yzj@cluster3 bigdata]$ du -sh . 查看文件大小总和
387M .
[yzj@cluster3 bigdata]$ du -sh * 查看各个文件大小
130M 20120103.csv
53M 20120103.zip
145M 20120104.csv
60M 20120104.zip
[yzj@cluster3 bigdata]$ wc -l 20120103.csv 查看文件有多少行数据
723908 20120103.csv
求最大文件 先排序 再选取一个 这里
[yzj@cluster3 bigdata]$ du -sh * | sort
130M 20120103.csv
145M 20120104.csv 这里还是不太合理
53M 20120103.zip
60M 20120104.zip
[yzj@cluster3 bigdata]$ du -sh * | sort -n 按数字大小排序
53M 20120103.zip
60M 20120104.zip
130M 20120103.csv
145M 20120104.csv
[yzj@cluster3 bigdata]$ du -sh * | sort |head -1
130M 20120103.csv
4.创建表的注意事项
1. 表的类型-内表还是外表
- 2) 表的结构-哪些字段和类型
- 3)是否分区或是分桶-为了优化查询效率
- 4)表的存储文件类型
- 表数据构成分析
- 元数据:描述数据的数据
- 实体数据:真正承载真实数据的内容
- DAG:有向无环图,数据表的操作都可以抽象成一个DAG。
- 内表还是外表的对比说明
- 概念
- External修饰的表称为外表
- 没有external修饰的表称为内表
- 特点特征
- 内表:元数据和实体数据都归Hive自身管理,一删除则全部删除。
- 外表:元数据归Hive管理,实体数据归HDFS管理,删除表的话,只会删除元数据,不会删除实体数据。
- 应用场景
- 如果表自身数据是可以自循环、自生成的,则使用内表。
- 如果表自身是外部导入的,即不可实现自循环自生成的,则使用外表。
代码实现
概念
- 分区:对表数据进行partition划分,即水平划分数据。
- 分桶:对表数据进行bucket划分,即垂直划分数据。
- 特点特征
- 分区:虚拟字段进行数据的水平划分,在HDFS上是以该虚拟字段的值作为一个分区的目录名称,即分目录。
- 分桶:字体字段进行Hash计算的垂直拆分,最终按分桶的数量切分出对应的文件个数,即分文件。
- 应用场景
- 为了提高查询效率
- 分区:数据本身具备明显的水平可分隔的特性,比如时间字段、国家、地区、城市等字段。
- 分桶:数据本身具备明显的垂直可分隔的特性,比如名字查询、ID查询等。
- 为了提高查询效率
代码实现
概念
- 表数据存储时候的文件格式的选择,可以是txt,seq,rc,orc等。
- 特点特征
- 不同的文件类型会导致完全相同的数据在存储效率和使用效率差异很大。
- 应用场景
- 文件类型4种,
- 面向行:txt,seq
- 面向列:rc,orc
- 文件类型4种,
代码实现
如果表类型是外部表,则文件类型是由外部表地应源数据格式来决定。
- 如果表类型是内部表,则由Hive数据仓库支持的文件存储类型来决定。一般多见设置的rc或是orc,现在最多是的ORC。
- 就像下方,
三.源数据准备
mkdir bigdata
在bigdata目录下创建yuqing_hot_mining
在yuqing_hot_mining目录下创建五个目录
create
config
udf
data
deal
1.zip 原始数据批量解压
ls * | xargs echo 把当前目录(包含子目录)下所有文件名输出
20120103.zip 20120104.zip yuqing_hot_mining: config create data deal udf
ls * | xargs -n 1 把当前目录文件名按每行一个进行分行
ls | xargs -n 1 unzip -d 路径 读取当前目录依次进行解压
ls | xargs -n 1 unzip -o -d 路径 读取当前目录依次强制进行解压
2.在 hive 中创建 weibo_origin 和 weibo_product 两张同构表
1.在create中创建两个sh文件并编辑
! /bin/bash
hive -e “
use yzj;
weibo_origin 建表语句或weibo_product 建表语句
“
然后sh weibo_origin.sh
sh weibo_product.sh
即可在Hive建好两个表
表 weibo_origin.sh 因为是外部导入的数据 所以是外部表
CREATE external TABLE weibo_origin(mid string,retweeted_status_mid string,uid string,retweeted_uid string,source string,image string,text string,geo string,created_at string,deleted_last_seen string,permission_denied string)comment 'weibo content table'partitioned by (day_seq string comment 'the daysequence')ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINESTERMINATED BY '\n'STORED AS textfile;
表weibo_product.sh 加工生成的数据 所以内部表
按天分区 seq后面为注释
CREATE TABLE weibo_product(
mid string,
retweeted_status_mid string,
uid string,
retweeted_uid string,
source string,
image string,
text string,
geo string,
created_at string,
deleted_last_seen string,
permission_denied string
)
comment 'weibo content table'
partitioned by (day_seq string comment 'the day
sequence')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES
TERMINATED BY '\n'
STORED AS orcfile;
2.编辑中断问题
1.如果编辑vi过程中断,则下次打开有swp文件作为临时缓冲文件
需要E进入然后wq保存退出,然后ll -a显示出./*文件 删掉即可
3.shell脚本执行优化
nohup 英文全称:no hang up
不挂断的运行,可以使命令永久的执行下去,和用户终端 没有关系,
例如我们断开 SSH 连接都不会影响他的运行。
但是会关闭标准输入,终端不再能够接收任何输入(标准输入),
例 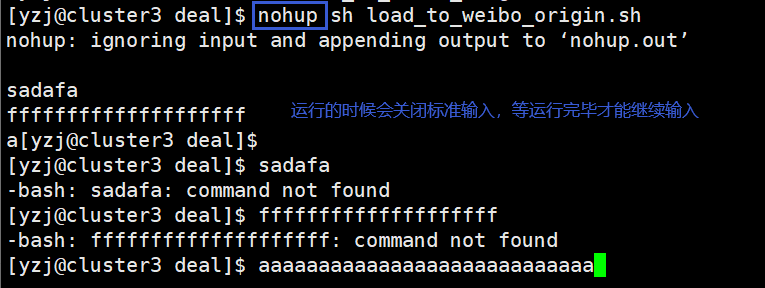
重定向标准输出和标准错误到当前目录下的 nohup.out 文 件。
没有后台运行的意思,但有一些后台执行的形式在里边
&
在后台运行,但当用户会话退出(挂起)的时候,命令自动 也跟着退出
命令联用:nohup Command &
最终脚本命令: nohup sh load_to_weibo_origin.sh &
命令永久的在后台执行,直到结束 保证 shell 在断开客户端情况下,依然可以继续执行
3.将解压完的明文每天数据表,按天 load 到 weibo_origin 载入原始数据
csv文件在本地的day_csv_data目录下
在bigdata/yuqing_hot_mining/deal中编辑load_to_weibo_origin.sh 文件
然后执行 sh load_to_weibo_origin.sh
注意:
1./bin/bash代表用哪个解析器解析
2.反引号位 () 位于键盘的Tab键的上方、1键的左方。注意与单引号(')位于Enter键的左方的区别。 在Linux中起着命令替换的作用。**命令替换是指shell能够将一个命令的标准输出插在一个命令行中任何位置。就是内嵌了一个shell脚本执行器。**<br /> 如下,shell会执行反引号中的date命令,把结果插入到echo命令显示的内容中。<br /> [root@localhost fwz]# echo The date isdate<br /> The date is 2016年 04月 21日 星期一 21:15:43 CST<br />3.关于line:15ls $csv_root_dir`加的问题
加*解决了全路径问题 因为必须sh文件跟#csv文件在一个目录下面
否则找不到文件
也可以用拼接文件位置+文件的方法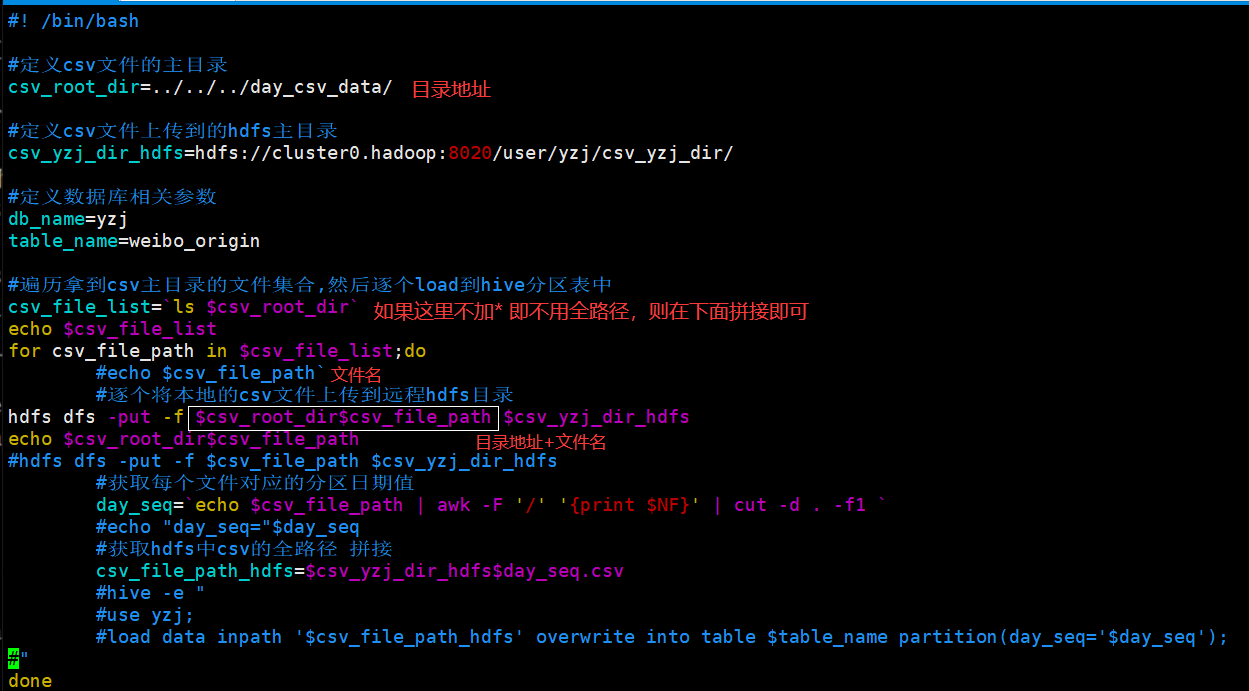
从deal目录查找csv文件位置:
全路径:
[yzj@cluster3 deal]$ ls ../../../day_csv_data/*
../../../day_csv_data/20120103.csv ../../../day_csv_data/20120104.csv
相对路径:
[yzj@cluster3 deal]$ ls ../../../day_csv_data/
20120103.csv 20120104.csv
4.关于line21:
-F ‘/‘ 用/分割 NF :浏览记录的域的个数 列数 最后一列
[yzj@cluster3 ~]$ echo “../../day_csv_data/20120103.csv” | awk -F ‘/‘ ‘{print $NF}’
20120103.csv
[yzj@cluster3 ~]$ echo “../../day_csv_data/20120103.csv” | awk -F ‘/‘ ‘{print $NF}’ | cut -d . -f1 用.切割
20120103
cut 选项 参数
-d:指定字段的分隔符,默认的字段分隔符为”TAB” -f:显示指定字段的内容 指定获取的列
#! /bin/bash
#定义csv文件的主目录-本地
csv_root_dir=../../../day_csv_data/
#定义csv文件上传到的hdfs主目录
csv_yzj_dir_hdfs=hdfs://cluster0.hadoop:8020/user/yzj/csv_yzj_dir/
#定义数据库相关参数
db_name=yzj
table_name=weibo_origin
#遍历拿到csv主目录的文件集合,然后逐个load到hive分区表中
csv_file_list=`ls $csv_root_dir*`
for csv_file_path in $csv_file_list;do
#echo $csv_file_path`
#逐个将本地的csv文件上传到远程hdfs目录
hdfs dfs -put -f $csv_file_path $csv_yzj_dir_hdfs
#获取每个文件对应的分区日期值 比如20120104/20120103 -d分隔符delimeters
day_seq=`echo $csv_file_path | awk -F '/' '{print $NF}' | cut -d . -f1 `
echo "day_seq="$day_seq
#获取hdfs中csv的全路径 拼接
csv_file_path_hdfs=$csv_yzj_dir_hdfs$day_seq.csv
echo csv_file_path_hdfs
hive -e "
use yzj;
load data inpath '$csv_file_path_hdfs' overwrite into table $table_name partition(day_seq='$day_seq');
"
done
4.数据检验与校正
1.导入数据的正确与否校验
- 样例数据查是否正常(limit m,查看数据样例数据有无明显异常)
- 数据量级是否相同(主要是指数据当量,十成级、百万级)
- 数据完整性是否一致(主要是指别丢数据)
- 数据格式与字段是否对齐
2.校正方法
- 将数据的导入方式与数据表的解析方式保持完全一致
修改 weibo_origin 表创建脚本 删除原表 ,然后执行sh
CREATE external TABLE weibo_origin( mid string, retweeted_status_mid string, uid string, retweeted_uid string, source string, image string, text string, geo string, created_at string, deleted_last_seen string, permission_denied string ) comment 'weibo content table' partitioned by (day_seq string comment 'the day sequence') #注意修改存储格式 row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde' STORED AS textfile;3.数据去躁和数据清洗的区别
Hive的一次查询多次插入
- 概念:一次查询母表,多次并行插入多张子表。
- 特点特征
- 执行效率和代码复杂度明显优于常规的SQL代码实现多次查询同一张表生成其子表的情况。
- 应用场景
- 只要涉及一张大表潜在会生成出多张小表的情况,均可以使用。 ```shell
! /bin/bash
db_name=yzj input_table=weibo_origin output_table=weibo_product
hive -e “ use $db_name; from $input_table insert overwrite table $output_table partition(day_seq) select * where mid!=’mid’; “
插入完成后在hive上查看数据量<br />select day_seq,count(1) from weibo_product group by day_seq;<br /><br />show create table weibo_product<br />查看地址<br />hdfs://cluster0.hadoop:8020/warehouse/tablespace/managed/hive/yzj.db/weibo_product<br />在本地执行hdfs<br />hdfs dfs -du -h hdfs://cluster0.hadoop:8020/warehouse/tablespace/managed/hive/yzj.db/weibo_product<br />能看到有三个副本
<a name="nYESL"></a>
# 四. 热点挖掘处理过程
<a name="jFiy8"></a>
## 1.分词UDF编写
- 正排索引:全文扫描
- 倒排索引:按照字典索引去搜索
<a name="Ixijg"></a>
### 1.分词器选择
- java 分词器
- ansj 分词(比较简单易用,本项目选择该分词器)
- Ansj分词器的分词工具类
- BaseAnalysis 基本分词
- ToAnalysis 精准分词 
- NlpAnalysis nlp分词
- IndexAnalysis 面向索引的分词
- DicAnalysis
- hanLP 分词
- mmseg
- IK 分词
- jieba 分词
- PaoDing 分词
- 天亮分词器
- python
- jieba 分词
- c/c++
- ICTCLAS
<a name="JviQr"></a>
### 2.ansj 分词器应用集成
- 相关资料
github 主页:https://github.com/NLPchina/ansj_seg <br />在线学习手册:[http://nlpchina.github.io/ansj_seg/](http://nlpchina.github.io/ansj_seg/)<br />引入依赖
```shell
<groupId>com.tl.bigdata</groupId>
<artifactId>YuQingHotMining</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 首先配置仓库的服务器位置,首选阿里云,也可以配置镜像方式,效果雷同 -->
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories>
<dependencies>
<!-- 引入hadoop-cli-2.7.4依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<version>1.2.1</version>
<scope>provided</scope>
</dependency>
<!-- ansj依赖jar配置 ==start -->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.1</version>
</dependency>
<!-- ansj依赖jar配置 ==end -->
</dependencies>
<build>
<finalName>TlHadoopCore</finalName>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
测试用例
package com.tl.bigdata;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
import java.util.List;
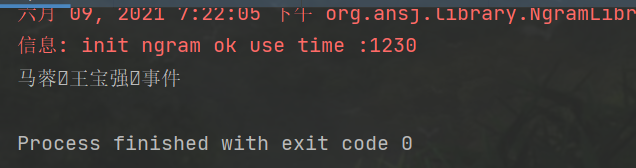
public class nlp {
public static void main(String[] args) {
//1.定义一个待分词的句子
String sentence = "马蓉王宝强事件";
//2.用NlpAnalysis进行分词
Result result = NlpAnalysis.parse(sentence);
//3.解析其返回的对象Result,形成分词结果集
StringBuilder stringBuilder = new StringBuilder();
int counter = 0;
// 将分词结果集合返回给变量 itemList
List<Term> termList = result.getTerms();
//遍历集合,加入结果集中
for (Term term : termList) {
if (counter > 0) {
stringBuilder.append("\001");
}
//只要分词的名字结果,不要词性部分
stringBuilder.append(term.getName());
counter++;
}
//4.打印分词结果集
System.out.println(stringBuilder.toString());
}
}
StringBuffer和StringBuilder对象则代表一个字符序列可变的字符串,一旦生成了最终想要的字符串,就可以调用它的toString()方法将其转换为一个String对象。不同的是:StringBuffer是线程安全的,而StringBuilder则没有实现线程安全功能,所以性能略高。
StringBuffer b = new StringBuffer(“123”);b.append(“456”);
// b打印结果为:123456
System.out.println(b);
https://blog.csdn.net/csxypr/article/details/92378336
UDF 编码
package com.tl.bigdata.udf;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.List;
public class CwsUDF extends UDF {
public String evaluate(String sentence){
if(sentence==null || sentence.trim().length()==0){
return null;
}
Result result= NlpAnalysis.parse(sentence);
if (result==null || result.getTerms()==null){
return null;
}
List<Term> termList= result.getTerms();
StringBuilder stringBuilder=new StringBuilder();
int counter=0;
for (Term term:termList){
if (counter>0){
stringBuilder.append("#");
}
stringBuilder.append(term.getName());
counter++;
}
return stringBuilder.toString();
}
#测试方法
public static void main(String[] args) {
String sentence="马蓉王宝强事件";
CwsUDF udf=new CwsUDF();
String result= udf.evaluate(sentence);
System.out.println(result);
}
}

2.生成分词结果表
1.创建 执行生成表 weibo_seg_result.sh
#! /bin/bash
hive -e "
use yzj;
CREATE TABLE weibo_seg_result(
mid string,
retweeted_status_mid string,
uid string,
retweeted_uid string,
source string,
text string,
text_seg string,
geo string,
created_at string
)
comment 'weibo seg result table'
partitioned by (day_seq string comment 'the day sequence')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY
'\n'
STORED AS orcfile;
"
2.调用分词 udf 生成分词结果表
- 环境准备
- eclipse+maven all in one 打包 - 将 jar 包上传至 hive cli 端 用rz -bye 命令上传 - 添加 jar 包到 classpath - 创建临时函数
- hql 脚本 - 完整脚本(produce_weibo_seg_result.sh)
```java
! /bin/bash
定义数据库名称
db_name=yzj
定义jar包路径
jar_path=”hdfs:///user/yzj/jars/TlHadoopCore-jar-with-dependencies.jar”
定义classpath
class_path=com.tl.bigdata.udf.CwsUDF
定义数据源和输出表
input_table=weibo_product output_table=weibo_seg_result
写sql实现表的生成
1.use db
2.add jar jarpath
3.创建临时函数 将classpath加入其中
4.一次查询多次插入语法
hive -e “ use $db_name; add jar $jar_path; create temporary function seg as ‘$class_path’; from $input_table insert overwrite table $output_table partition(day_seq) select mid,retweeted_status_mid,uid,retweeted_uid,source,text,seg(text) as text_seg, geo,created_at,day_seq; “
查询结果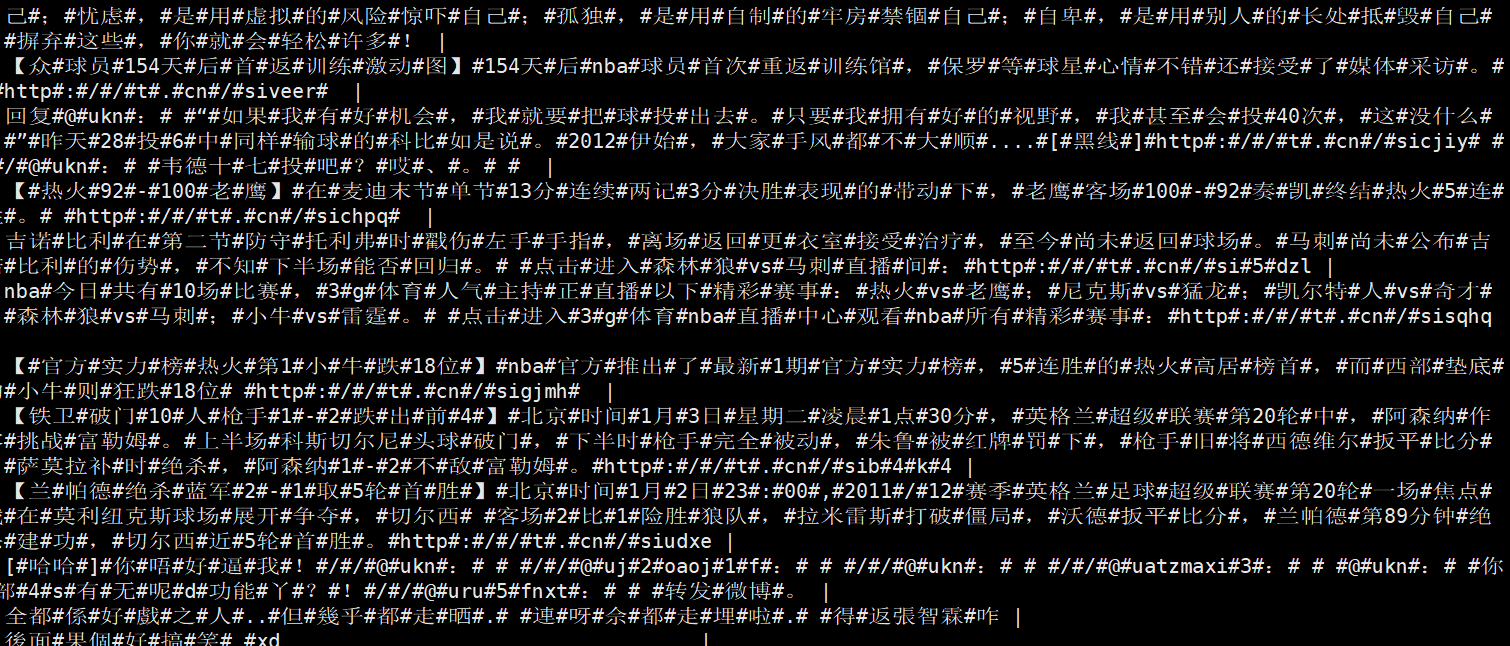<br /> select text,text_seg from weibo_seg_result limit 10;
<a name="taekK"></a>
## 3.生成wordcount倒排表按词频降序排列
创建倒排表 weibo_seg_wc.sh
```java
#! /bin/bash
hive -e "
use yzj;
CREATE TABLE weibo_seg_wc(
word string,
freq int
)
comment 'weibo seg wc'
partitioned by (day_seq string comment 'the day sequence')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'
STORED AS orcfile;
"
优化导入hive produce_weibo_seg_wc.sh
#! /bin/bash
#定义数据库
db_name=yzj
#定义输入源和数据表
input_table=weibo_seg_result
output_table=weibo_seg_wc
#写sql实现业务逻辑
#1、对result表进行split操作,拿到单个的word词条,然后进行word count,最后进行order by排序输出
hive -e "
use $db_name;
insert overwrite table $output_table partition(day_seq)
select word,count(1) as freq,day_seq from $input_table
lateral view explode(split(text_seg,'#')) word_table as word
where length(word)>1 group by day_seq,word order by day_seq,freq desc;
"
1.继续优化 导入白名单
package com.tl.bigdata.udf;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* udf集成分词,添加词性过滤
*/
public class CwsUDFV2 extends UDF {
// 用于标记用于去重的 natureSet 是否已经初始化的标志位
public boolean natureSetHaveIntFlag=false;
//用于词性过滤的set集合初始化
public Set<String> whiteSet=new HashSet<String>();
//传入需要分词的句子和黑白名单
public String evaluate(String sentence,String natureStr){
if(sentence==null || sentence.trim().length()==0){
return null;
}
//白名单的Set集合初始化,只需要初始化依次就能反复使用
if(!natureSetHaveIntFlag&&natureStr.trim().length()>0){
String[] natureArray=natureStr.split(",");
for (String nature:natureArray){
whiteSet.add(nature);
}
natureSetHaveIntFlag=true;
}
Result result= NlpAnalysis.parse(sentence);
if (result==null || result.getTerms()==null){
return null;
}
List<Term> termList= result.getTerms();
StringBuilder stringBuilder=new StringBuilder();
int counter=0;
for (Term term:termList){
// 判断分词的 Term 的词性是否包含在词性的白名单中,如果在则加入,否则忽略掉
if(whiteSet.contains(term.getNatureStr())){
// 循环记数器,当 counter>0 的时候,每次添加元素前先添加分隔符#
if (counter>0){
stringBuilder.append("#");
}
stringBuilder.append(term.getName());
counter++;
}
}
return stringBuilder.toString();
}
public static void main(String[] args) {
String sentence="马蓉王宝强事件你是真的会玩";
String natureList="n,nr,nr1,nr2,nrj,nrf,ns,nsf,nt,nz,nl,ng,nw,v,vd,vn,vf,vx,vi,vl,vg,a,ad,an,ag,al";
CwsUDFV2 udf=new CwsUDFV2();
String result= udf.evaluate(sentence,natureList);
System.out.println(result);
}
}
然后重新上传jar
生成新的produce_weibo_seg_result——v2.sh 查询
#定义数据库名称
db_name=yzj
#定义jar包路径
jar_path="hdfs:///user/yzj/jars/TlHadoopCore-jar-with-dependencies.jar"
#定义classpath
class_path=com.tl.bigdata.udf.CwsUDFV2
#定义数据源和输出表
input_table=weibo_product
output_table=weibo_seg_result
#定义白名单词性集合
nature_str='n,nr,nr1,nr2,nrj,nrf,ns,nsf,nt,nz,nl,ng,nw,v,vd,vn,vf,vx,vi,vl,vg,a,ad,an,ag,al'
#写sql实现表的生成
#1.use db
#2.add jar jarpath
#3.创建临时函数 将classpath加入其中
#4.一次查询多次插入语法
hive -e "
use $db_name;
add jar $jar_path;
create temporary function seg as '$class_path';
from $input_table
insert overwrite table $output_table partition(day_seq)
select mid,retweeted_status_mid,uid,retweeted_uid,source,text,seg(text,'$nature_str') as text_seg,geo,created_at,day_seq;
再执行weibo_seg_result.sh查看分词结果
select text,text_seg from weibo_seg_result limit 10;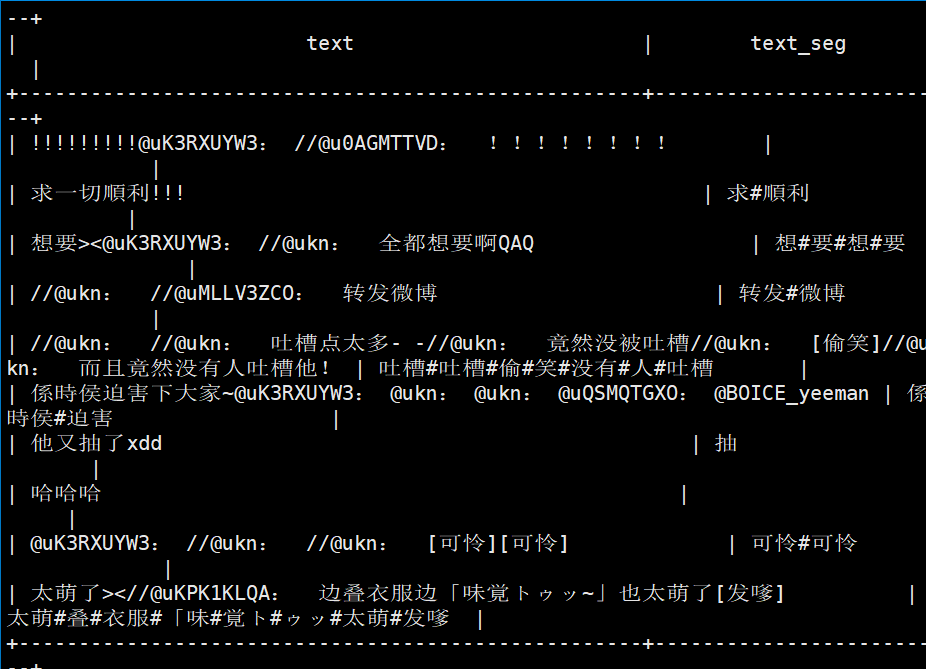
生成黑名单produce_weibo_seg_wc_v2.sh 执行
select * from weibo_seg_wc where day_seq=20120103 limit 20;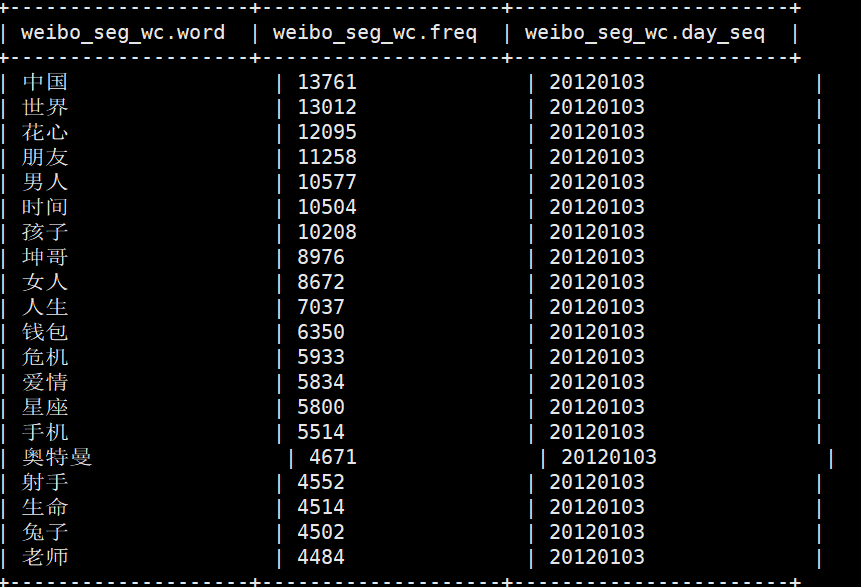
4.把表推送到mysql表中
编辑 download_data_to_local_4_seg_wc.sh 把数据下载hdfs 然后拷贝到本地
#! /bin/bash
#定义数据库和表
db_name=yzj
input_table=weibo_seg_wc
#定义hdfs接收数据的路径
data_save_hdfs_path=hdfs://cluster0.hadoop:8020/user/yzj/weibo_sorted/
#定义本地接收hdfs文件的目录
data_save_local_path=../data/weibo_sorted/
#写hivesql将表数据插入hdfs目录当中
hive -e "
use $db_name;
insert overwrite directory '$data_save_hdfs_path'
row format delimited fields terminated by '\t'
select word,freq,day_seq from (select day_seq,word,freq,dense_rank() over(order by freq desc) as topN from weibo_seg_wc where day_seq=20120103) rank_table where topN<=100;
"
#将hdfs数据下载到本地
hdfs dfs -get -f $data_save_hdfs_path/000000_0 $data_save_local_path
编辑synchronized_data_to_mysql.sh 把数据推送到mysql中
#! /bin/bash
#定义数据源
hotwords_data_path="../data/weibo_sorted/000000_0"
#定义mysql库和表
db_name_mysql=job016_bigdata_group4
output_table=weibo_hot_words_yzj
#写sql实现业务逻辑
mysql -hcluster0 -P3307 -ujob016_bigdata_group4 -pTianliang2020.. -e "
use $db_name_mysql;
load data local infile '$hotwords_data_path' into table $output_table
fields terminated by '\t' (word,freq,day_seq);
"
五. 前端Web页面展示
1.构建springboot项目
2.加入echars绘图软件
3.前端界面生成
六. 项目脚本化
梳理数据流:
zip 文件 -> csv 文件 -> weibo_origin -> weibo_product -> weibo_seg_result -> weibo_seg_wc -> download_weibo_hot_words -> upload_to_mysql_table -> web 可 视化
1.逐个数据流进行脚本化
- zip->csv 脚本名称:data_prepare_zip_to_csv.sh
vi data_prepare_zip_to_csv.sh
#! /bin/bash
#定义zip的目录
zip_yzj_dir="../../../day_zip_data/"
#定义csv的目录
csv_yzj_dir="../../../day_csv_data/"
ls $zip_yzj_dir* | xargs -n 1 unzip -o -d $csv_yzj_dir
#ls $zip_yzj_dir*
csv (local)->csv(hdfs)文件
csv(hdfs)->weibo_origin 脚本名称:load_data_to_weibo_origin.sh
- weibo_origin -> weibo_product
- weibo_product -> weibo_seg_result
- weibo_seg_result -> weibo_seg_wc
6.1停用词表-创建表和初始化脚本就绪 load_to_weibo_stopwords.sh
#! /bin/bash
#定义stopwords的本地路径
stopwords_file_path_local=../data/div_stopwords/
#定义stopwords的加载到的hdfs路径
stopwords_file_path_hdfs=hdfs://cluster0.hadoop:8020/user/yzj/dic/
#数据库和输出表名称
db_name=yzj
to_table=weibo_stopwords
#sql将数据导入到表中
#将local词典文件上传到hdfs指定目录中
hdfs dfs -put $stopwords_file_path_local* $stopwords_file_path_hdfs
hive -e "
use $db_name;
load data inpath '$stopwords_file_path_hdfs*' overwrite into
table $to_table;
"
weibo_seg_wc -> hotwords(download_to_local_dir)
hotwords -> weibo_hot_words(upload 数据到 mysql 中的表)
-
2.流程化
shell编程中如何接收外部传过来的参数?§ $1,$2,$#,$
vi test.sh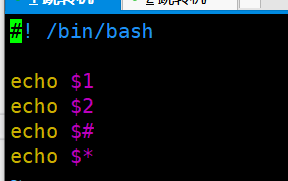

*Shell当中如何判断一个脚本执行成功与否? $? ,即返回最近一个(上一个)脚本的执行成功的状态码
- 0代表成功,非0代表异常
- Java当中的System.exit(int)
1.改写zip-csv脚本
cp data_prepare_zip_to_csv.sh data_prepare_zip_to_csv_4_oneday.sh
vi data_prepare_zip_to_csv_4_oneday.sh 只解决给我一个zip文件 然后生成csv文件 即执行脚本
#! /bin/bash
#只解决给我一个zip文件 然后生成csv文件 即执行脚本
#定义接收zip文件的目录
zip_yzj_dir=$1
#定义csv要解压的目录
csv_yzj_dir=$2
#ls $zip_yzj_dir* | xargs -n 1 unzip -o -d $csv_yzj_dir
#ls $zip_yzj_dir*
unzip -o $zip_yzj_dir -d $csv_yzj_dir
#1.这个解压过程一定能完成吗?
#2.如何判定解压成功?
#3.解压成功 解压失败怎么办?
#将上句代码的执行状态暂存
ret_flag=$?
#对状态码进行判断 做更好的用户体验处理
if [ $ret_flag -eq 0 ];then
echo "解压成功,即将删除zip源文件$zip_yzj_dir!!!"
rm -rf $zip_yzj_dir
delete_flag=$?
if [ $delete_flag -eq 0 ];then
echo "删除zip源文件$zip_yzj_dir成功!!"
else
echo "删除zip源文件$zip_yzj_dir 失败,请检查数据"
exit $delete_flag
fi
else
echo "解压异常,请检查数据!!"
exit $ret_flag
fi
#echo $?
执行 sh data_prepare_zip_to_csv_4_oneday.sh ../../../day_zip_data/20120103.zip ../../../day_csv_data/
2.改写load到origin脚本
cp load_to_weibo_origin.sh load_to_weibo_origin_4_oneday.sh
#! /bin/bash
#定义接收过来的csv的单天数据
day_seq=$1
csv_yzj_dir=$2
#定义csv文件上传到的hdfs主目录
csv_yzj_dir_hdfs=hdfs://cluster0.hadoop:8020$3
#定义数据库相关参数
db_name=yzj
table_name=weibo_origin
#逐个将本地的csv文件上传到远程hdfs目录
hdfs dfs -put -f $csv_yzj_dir $csv_yzj_dir_hdfs
#获取hdfs中csv的全路径 拼接
csv_file_path_hdfs=$csv_yzj_dir_hdfs$day_seq.csv
hive -e "
use yzj;
load data inpath '$csv_file_path_hdfs' overwrite into table $table_name partition(day_seq='$day_seq');
"
ret_flag=$?
if [ $ret_flag -eq 0 ];then
echo "数据加载成功 即将删除csv源文件,$csv_yzj_dir"
rm -rf $csv_file_path_local
else
echo "数据加载失败 请检查代码的准确性"
exit $ret_flag
fi
echo $?
sh load_to_weibo_origin_4_oneday.sh 20120104 ../../../day_csv_data/20120104.csv /user/yzj/csv_yzj_dir/ 成功
成功
3.修改origin-product脚本
cp produce_weibo_product.sh produce_weibo_product_4_oneday.sh
vi produce_weibo_product_4_oneday.sh
day_seq=$1
db_name=yzj
input_table=weibo_origin
output_table=weibo_product
hive -e "
use $db_name;
from (select * from $input_table where day_seq=$day_seq ) temp
insert overwrite table $output_table partition(day_seq)
select * where mid!='mid';
"
4.product-seg_result 过滤分词
cp produce_weibo_seg_result_v3.sh produce_weibo_seg_result_4_oneday.sh
vi produce_weibo_seg_result_4_oneday.sh
主要修改了from表(select * from $input_table where day_seq=$day_seq) temp 和day_seq=$1
#! /bin/bash
day_seq=$1
#定义数据库名称
db_name=yzj
#定义jar包路径
jar_path="hdfs:///user/yzj/jars/TlHadoopCore-jar-with-dependencies.jar"
#定义classpath
class_path=com.tl.bigdata.udf.CwsUDFV2
#定义数据源和输出表
input_table=weibo_product
output_table=weibo_seg_result
#定义白名单词性集合
nature_str='n,nr,nr1,nr2,nrj,nrf,ns,nsf,nt,nz,nl,ng,nw'
#写sql实现表的生成
#1.use db
#2.add jar jarpath
#3.创建临时函数 将classpath加入其中
#4.一次查询多次插入语法
hive -e "
use $db_name;
add jar $jar_path;
create temporary function seg as '$class_path';
from (select * from $input_table where day_seq=$day_seq) temp
insert overwrite table $output_table partition(day_seq)
select mid,retweeted_status_mid,uid,retweeted_uid,source,text,seg(text,'$nature_str') as text_seg,geo,created_at,day_seq;
"
sh produce_weibo_seg_result_4_oneday.sh 20120103
5.分词-统计排序
cp produce_weibo_seg_wc_v2.sh produce_weibo_seg_wc_4_oneday.sh
vi produce_weibo_seg_wc_4_oneday.sh
#! /bin/bash
day_seq=$1
#定义数据库
db_name=yzj
#定义输入源和数据表
input_table=weibo_seg_result
input_table_2=weibo_stopwords
output_table=weibo_seg_wc
#写sql实现业务逻辑
#1、对result表进行split操作,拿到单个的word词条,然后进行word count,最后进行order by排序输出
hive -e "
use $db_name;
insert overwrite table $output_table partition(day_seq)
select main.word,freq,day_seq from (select word,count(1) as freq,day_seq from $input_table lateral view explode(split(text_seg,'#')) word_table as word where day_seq=$day_seq and length(word)>1 group by day_seq,word) main
left join (select word from $input_table_2) stopwords
on main.word=stopwords.word
where stopwords.word is null
order by day_seq,freq desc
;
"
sh produce_weibo_seg_wc_4_oneday.sh 20120103
6.数据落地到hdfs和本地
cp download_data_to_local_4_seg_wc.sh download_data_to_local_4_seg_wc_4_oneday.sh
vi download_data_to_local_4_seg_wc_4_oneday.sh
#! /bin/bash
day_seq=$1
#定义数据库和表
db_name=yzj
input_table=weibo_seg_wc
#定义hdfs接收数据的路径
data_save_hdfs_path=hdfs://cluster0.hadoop:8020/user/yzj/weibo_sorted/
#定义本地接收hdfs文件的目录
data_save_local_path=../data/weibo_sorted/
#写hivesql将表数据插入hdfs目录当中
hive -e "
use $db_name;
insert overwrite directory '$data_save_hdfs_path'
row format delimited fields terminated by '\t'
select word,freq,day_seq from (select day_seq,word,freq,dense_rank() over(order by freq desc) as topN from weibo_seg_wc where day_seq=$day_seq) rank_table where topN<=100;
"
#将hdfs数据下载到本地
hdfs dfs -get -f $data_save_hdfs_path/000000_0 $data_save_local_path
7.数据推送到mysql
synchronized_data_to_mysql.sh
#! /bin/bash
#定义数据源
hotwords_data_path="../data/weibo_sorted/000000_0"
#定义mysql库和表
db_name_mysql=job016_bigdata_group4
output_table=weibo_hot_words_yzj
#写sql实现业务逻辑
mysql -hcluster0 -P3307 -ujob016_bigdata_group4 -pTianliang2020.. -e "
use $db_name_mysql;
load data local infile '$hotwords_data_path' into table $output_table
fields terminated by '\t' (word,freq,day_seq);
"
优化环境变量
cd ../config/ vi set_env.sh
#! /bin/bash
#设置一些系统常用环境变量 提升项目可移植性和可维护性
HIVE=/usr/bin/hive
MYSQL="mysql -hcluster0 -P3307 -ujob016_bigdata_group4 -pTianliang2020.."
如图修改别的sh文件 produce_weibo_product_4_oneday.sh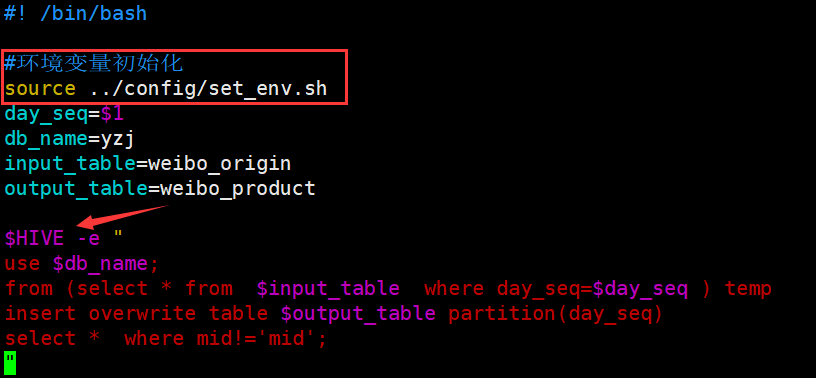
修改 synchronized_data_to_mysql.sh 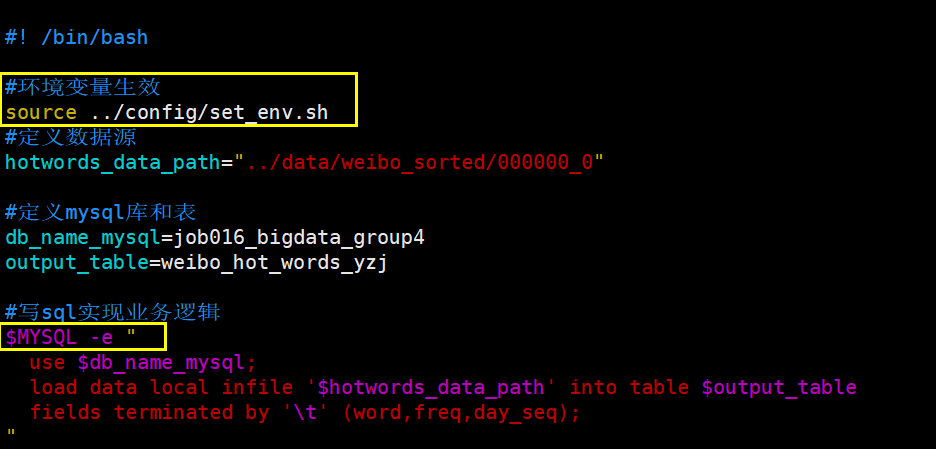
3.自动化
1.zip to csv
sh data_prepare_zip_to_csv_4_oneday.sh $zip_yzj_dir $csv_yzj_dir
#! /bin/bash
#只解决给我一个zip文件 然后生成csv文件 即执行脚本
#定义接收zip文件的目录
zip_yzj_dir=$1
#定义csv要解压的目录
csv_yzj_dir=$2
#ls $zip_yzj_dir* | xargs -n 1 unzip -o -d $csv_yzj_dir
#ls $zip_yzj_dir*
unzip -o $zip_yzj_dir -d $csv_yzj_dir
#1.这个解压过程一定能完成吗?
#2.如何判定解压成功?
#3.解压成功 解压失败怎么办?
#将上句代码的执行状态暂存
ret_flag=$?
echo $ret_flag
#对状态码进行判断 做更好的用户体验处理
if [ $ret_flag -eq 0 ];then
echo "解压成功,即将删除zip源文件$zip_yzj_dir!!!"
# rm -rf $zip_yzj_dir
delete_flag=$?
if [ $delete_flag -eq 0 ];then
echo "删除zip源文件$zip_yzj_dir成功!!"
else
echo "删除zip源文件$zip_yzj_dir 失败,请检查数据"
exit $delete_flag
fi
else
echo "解压异常,请检查数据!!"
exit $ret_flag
fi
2.csv to weibo_origin
即 local csv to hdfs csv,然后hdfs csv to weibo_origin
csv_file_path_local=”$csv_yzj_dir”
sh load_to_weibo_origin_4_oneday.sh $day_seq $csv_file_path_local $csv_yzj_dir_hdfs
#! /bin/bash
#定义接收过来的csv的单天数据
day_seq=$1
csv_yzj_dir=$2
#定义csv文件上传到的hdfs主目录
csv_yzj_dir_hdfs=hdfs://cluster0.hadoop:8020$3
#定义数据库相关参数
db_name=yzj
table_name=weibo_origin
#逐个将本地的csv文件上传到远程hdfs目录
#hdfs dfs -put -f $csv_root_dir$csv_file_path $csv_yzj_dir_hdfs
hdfs dfs -put -f $csv_yzj_dir$day_seq.csv $csv_yzj_dir_hdfs
#获取hdfs中csv的全路径 拼接
csv_file_path_hdfs=$csv_yzj_dir_hdfs$day_seq.csv
hive -e "
use $db_name;
load data inpath '$csv_file_path_hdfs' overwrite into table $table_name partition(day_seq='$day_seq');
"
ret_flag=$?
if [ $ret_flag -eq 0 ];then
echo "数据加载成功 即将删除csv源文件,$csv_yzj_dir"
rm -rf $csv_yzj_dir*
else
echo "数据加载失败 请检查代码的准确性"
exit $ret_flag
fi
echo $?
3.weibo_origin to weibo_product
sh produce_weibo_product_4_oneday.sh $day_seq
#! /bin/bash
#环境变量初始化
source ../config/set_env.sh
day_seq=$1
db_name=yzj
input_table=weibo_origin
output_table=weibo_product
$HIVE -e "
use $db_name;
from (select * from $input_table where day_seq=$day_seq ) temp
insert overwrite table $output_table partition(day_seq)
select * where mid!='mid';
"
4.product to seg_result
sh produce_weibo_seg_result_4_oneday.sh $day_seq
#! /bin/bash
day_seq=$1
#定义数据库名称
db_name=yzj
#定义jar包路径
jar_path="hdfs:///user/yzj/jars/TlHadoopCore-jar-with-dependencies.jar"
#定义classpath
class_path=com.tl.bigdata.udf.CwsUDFV2
#定义数据源和输出表
input_table=weibo_product
output_table=weibo_seg_result
#定义白名单词性集合
nature_str='n,nr,nr1,nr2,nrj,nrf,ns,nsf,nt,nz,nl,ng,nw'
#写sql实现表的生成
#1.use db
#2.add jar jarpath
#3.创建临时函数 将classpath加入其中
#4.一次查询多次插入语法
hive -e "
use $db_name;
add jar $jar_path;
create temporary function seg as '$class_path';
from (select * from $input_table where day_seq=$day_seq) temp
insert overwrite table $output_table partition(day_seq)
select mid,retweeted_status_mid,uid,retweeted_uid,source,text,seg(text,'$nature_str') as text_seg,geo,created_at,day_seq;
"
5.seg_result to seg_wc sh produce_weibo_seg_wc_4_oneday.sh $day_seq
#! /bin/bash
day_seq=$1
#定义数据库
db_name=yzj
#定义输入源和数据表
input_table=weibo_seg_result
input_table_2=weibo_stopwords
output_table=weibo_seg_wc
#写sql实现业务逻辑
#1、对result表进行split操作,拿到单个的word词条,然后进行word count,最后进行order by排序输出
hive -e "
use $db_name;
insert overwrite table $output_table partition(day_seq)
select main.word,freq,day_seq from (select word,count(1) as freq,day_seq from $input_table lateral view explode(split(text_seg,'#')) word_table as word where day_seq=$day_seq and length(word)>1 group by day_seq,word) main
left join (select word from $input_table_2) stopwords
on main.word=stopwords.word
where stopwords.word is null
order by day_seq,freq desc
;
"
6.seg_wc to download_to_hdfs , hdfs to download_to_local
sh download_data_to_local_4_seg_wc_4_oneday.sh $day_seq
#! /bin/bash
day_seq=$1
#定义数据库和表
db_name=yzj
input_table=weibo_seg_wc
#定义hdfs接收数据的路径
data_save_hdfs_path=hdfs://cluster0.hadoop:8020/user/yzj/weibo_sorted/
#定义本地接收hdfs文件的目录
data_save_local_path=../data/weibo_sorted/
#写hivesql将表数据插入hdfs目录当中
hive -e "
use $db_name;
insert overwrite directory '$data_save_hdfs_path'
row format delimited fields terminated by '\t'
select word,freq,day_seq from (select day_seq,word,freq,dense_rank() over(order by freq desc) as topN from weibo_seg_wc where day_seq=$day_seq) rank_table where topN<=100;
"
#将hdfs数据下载到本地
hdfs dfs -get -f $data_save_hdfs_path/000000_0 $data_save_local_path
7.local data to mysql table
sh synchronized_data_to_mysql.sh
#! /bin/bash
#环境变量生效
source ../config/set_env.sh
#定义数据源
hotwords_data_path="../data/weibo_sorted/000000_0"
#定义mysql库和表
db_name_mysql=job016_bigdata_group4
output_table=weibo_hot_words_yzj
#写sql实现业务逻辑
$MYSQL -e "
use $db_name_mysql;
load data local infile '$hotwords_data_path' into table $output_table
fields terminated by '\t' (word,freq,day_seq);
"
总流程脚本
#! /bin/bash
#脚本目标:将天级的执行脚本进行串联,形成天级流程脚本
#定义接收必要的传输参数
day_seq=$1
zip_yzj_dir=$2
csv_yzj_dir=$3
csv_yzj_dir_hdfs=$4
#1.zip to csv
sh data_prepare_zip_to_csv_4_oneday.sh $zip_yzj_dir $csv_yzj_dir
#多做一次数据正常与否的检验
ret_flag=$?
if [ $ret_flag -ne 0 ];then
echo "zip to csv 出现数据异常,天级调度进程将推出,请检查!!"
exit $ret_flag
fi
#2.csv to weibo_origin 即 local csv to hdfs csv,然后hdfs csv to weibo_origin
csv_file_path_local="$csv_yzj_dir"
sh load_to_weibo_origin_4_oneday.sh $day_seq $csv_file_path_local $csv_yzj_dir_hdfs
#3.weibo_origin to weibo_product
sh produce_weibo_product_4_oneday.sh $day_seq
#4.product to seg_result
sh produce_weibo_seg_result_4_oneday.sh $day_seq
#5.seg_result to seg_wc
sh produce_weibo_seg_wc_4_oneday.sh $day_seq
#6.seg_wc to download_to_hdfs , hdfs to download_to_local
sh download_data_to_local_4_seg_wc_4_oneday.sh $day_seq
#7.local data to mysql table
sh synchronized_data_to_mysql.sh
自动化脚本 a_main_4_oneday.sh
#! /bin/bash
#脚本意义:天级任务的入口版本
day_seq=$1
zip_yzj_dir=$2
csv_yzj_dir=$3
csv_yzj_dir_hdfs=$4
#sh schedule_one_day.sh $day_seq ../../../day_zip_data/$day_seq.zip ../../../day_csv_data/ /user/yzj/csv_yzj_dir/
sh schedule_one_day.sh $day_seq $zip_yzj_dir $csv_yzj_dir $csv_yzj_dir_hdfs
最终脚本 a_main_4_batch.sh
#! /bin/bash
#脚本意义:天级任务的入口版本
#定义相关必备的传入参数
zip_yzj_dir="../../../day_zip_data/"
csv_yzj_dir="../../../day_csv_data/"
csv_yzj_dir_hdfs="/user/yzj/csv_yzj_dir/"
#遍历zip目录 逐个处理zip文件
zip_file_list=`ls $zip_yzj_dir*`
for zip_file_path_local in $zip_file_list;do
echo $zip_file_path_local
#通过文件获取day_seq参数
day_seq=`echo $zip_file_path_local | awk -F '/' '{print $NF}' | cut -d . -f1 `
echo $day_seq
sh a_main_4_oneday.sh $day_seq $zip_file_path_local $csv_yzj_dir $csv_yzj_dir_hdfs
done

若有收获,就点个赞吧
0 人点赞
