《持续交付 发布可靠软件的系统方法》读书笔记
数据库脚本化
与系统中其他变更一样,作为构建、部署、测试和发布过程的一部分,任何对数据库的修改都应该通过自动化过程来管理。也就是说,数据库的初始化和所有的迁移都需要脚本化,并提交到版本控制库中。无论是为开发人员创建一个新的本地数据库,还是为测试人员升级系统集成测试环境,或者作为发布过程的一部分迁移生产环境中的数据库,都应该能够使用这些脚本来管理交付流程中的每个数据库。
当然,数据库的模式会随着应用程序不断演变。这就引出了一个要求,即某个版本的数据库模式应该与该应用程序的某个具体版本相对应。例如,当做试运行环境的部署时,就要能够把试运行环境的数据迁移到适当的数据库模式上,以便与正在部署的新版本应用程序相匹配。通过对脚本的细心管理可以让这项工作成为可能。
增量式修改
持续集成要求在每次修改应用程序后,它都能够正常运行。这也包括对数据结构和数据内容的修改。
持续交付要求我们必须能够部署应用程序的任意一个已通过验证的版本(包括对数据库变更的版本)到生产环境(对于用户自行安装且包含数据库的软件也是一样的)。除了那种最简单的系统,对数据库进行更新的同时,还要保留它们的数据。最后,由于在部署时需要保留数据库中的已有数据,所以需要有回滚策略,以便当部署失败时使用。
数据库回滚和无停机发布
- 当回滚时需要保留本次升级后产生的数据;
- 根据签订的
SLA,要保持应用程序的可用状态,也叫做热部署或无停机发布;测试数据的管理
为单元测试进行数据库模拟
单元测试不使用真正的数据库是非常重要的,通常单元测试会使用测试替身对象来取代与数据库打交道的服务。
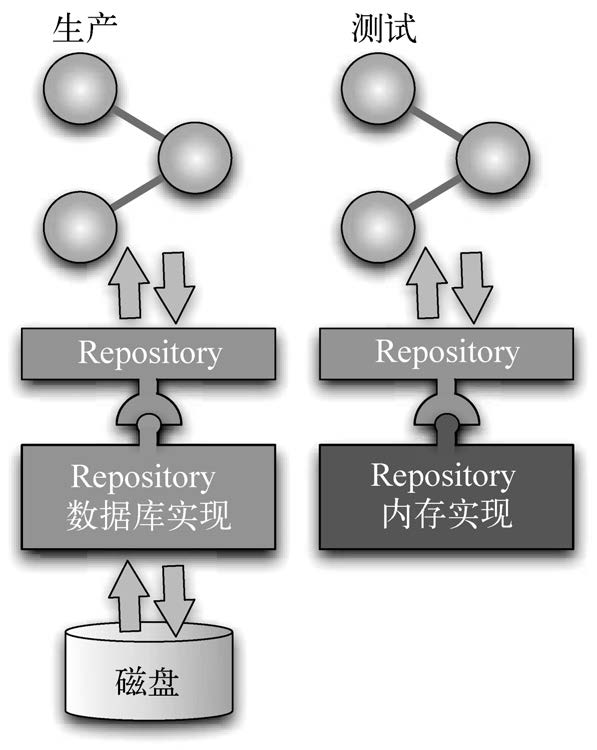
管理测试与数据之间的耦合
有以下三种方法可以用来做测试设计,以便管理好数据的状态:
- 测试的独立性:合理地组织测试,以便每个测试的数据只对该测试可见。
- 适应性测试:按如下方式进行测试设计—每次运行时先对数据环境进行检查,然后使用这些检查中得到的数据作为数据基础,对系统行为进行测试。
- 测试的顺序性:按如下方式进行测试设计——按某种已知的序列运行,每个测试的输入依赖于前一个的输出。
测试独立性
测试独立性是指确保每个测试都具有原子性。也就是说,每个测试不应该用其他测试的结果建立它的初始状态,并且其他测试也不应该以任何形式影响该测试的成功或失败。
最简单的方法是确保在测试结束时,总是将数据库中的数据状态恢复到该测试运行之前的状态。可以用手工方法来做,但最简单的方法是依靠大多数 RDMS 提供的事务特性。
建立和销毁
无论选择的策略是什么,在测试运行之前建立一个已知的状态良好的起始点,并且在其运行结束时再重建这个起始点是至关重要的,可以避免测试间依赖。
连贯的测试场景
常常有这样一种倾向,即创建一个连贯的“故事”(将多个测试场景串在一起),让一些测试顺序执行。这种方法的出发点是已创建的数据是有连续性的,这样可以将测试用例的建立和销毁工作最小化。而且,每个测试本身也会简单一点儿,因为它不再负责管理自己的测试数据了。另外,作为一个整体,测试套件运行得更快,因为它不用花太多时间创建和销毁测试数据了。
这种策略的问题在于我们正在努力把一个连贯的故事与测试紧紧耦合在一起。这种紧耦合有几个非常大的缺点。随着测试套件的增长,测试的设计越来越难。当一个测试失败以后,会对后续依赖于它的一系列测试造成影响,让它们也失败。业务场景或技术实现的变更可能导致重写测试套件,非常痛苦。
数据管理和部署流水线
我们通过测试来断言我们所开发的应用程序的行为符合我们期望的结果。
- 运行单元测试来避免刚做的修改破坏已有的应用程序;
- 运行验收测试来断言应用程序交付了用户所期望的价值;
- 运行容量测试来断言应用程序满足我们的容量需求;
- 运行一套集成测试来确认应用程序与其依赖的第三方服务可以正常通信;
那么,对于部署流水线的每个测试阶段,我们需要哪些测试数据,并应该如何管理它呢?
提交阶段的测试数据
好的提交测试会避免复杂的数据准备。如果你发现自己很难为某个测试准备数据的话,这是一个明显的信号,表示你的设计需要更好地解耦。要将设计分成多个互相独立的组件和测试,使用测试替身对象来模拟依赖。
验收测试中的数据
尽可能减少测试对大型复杂数据结构的依赖。方法基本上与提交阶段的测试一样:我们希望在测试用例的创建方面做到一些重用,并将每个测试对测试数据的依赖最小化。我们应该创建恰好够用的数据,用来验证我们对系统的期望行为。
容量测试的数据
容量测试用来指出应用程序所需的数据规模问题,该问题在两方面体现:
- 为测试提供足够的输入数据;
- 准备适当的引用数据来支撑测试中的多个用例;
我们把容量测试看做验收测试的重复利用,只是同时运行很多用例而已。
其他测试阶段的数据
抛开具体的实现技术,至少从设计理念上来讲,在验收测试阶段之后的所有自动化测试阶段中,我们都可以使用同样的方法。我们的目标是重用那些自动化验收测试所用的“行为规范”作为其他测试(不仅限于功能性测试)的起点。
小结
由于生命周期不同,数据管理也面临一些待解决的问题。尽管这些问题与部署流水线上下文中的问题有所不同,但管理数据所用的基本原则是一样的。关键是要把创建和迁移数据库全部变成自动化过程。这个过程是部署流程的一个组成部分,确保它的可重复性和可靠性。
即使有自动化的数据库迁移过程,细心地管理测试数据仍旧是非常必要的。尽管直接使用生产数据库的副本是一个充满诱惑力的选择,但通常会因为数据太大而不易使用。 相反,应该让测试自己创建它们所需的状态,并确保每个测试都独立于其他测试。甚至做手工测试时,也很少使用生产环境中数据库副本,它不是最佳起点。测试人员应该根据测试目的创建并管理自己的最小数据集。
推荐阅读

若有收获,就点个赞吧
0 人点赞
