转义符号 & 转义字符
在javaScript字符串中/表示「转义」!!!
在/后面跟上一个特定的符号或者字母就表示「转义字符」!!!
举例 🌰:
在javaScript的字符串中""内是不能继续使用""的(或者''内不能继续使用''),那我就想把「大神」用""引起来,这样就可以用\将字符串内的""进行转义。
var str = "我是\"大神\"程序员";console.log(str);

或者使用//将「大神」括起来
var str = "我是\\大神\\程序员";console.log(str);

\还有固定的组合(规定好的转义字符):
\n表示换行\r表示回车换行\t表示一个Tab按键的空格 ```javascript // \n 表示换行 var str = “我是\n大神程序员”; console.log(str); document.write(str); // 页面显示的时候不会进行换行,转义字符是给编辑系统使用的,HTML是文档不会识别
// \r 表示回车换行 var str = “我是\r大神程序员”; console.log(str); // 效果不明显
// \t 表示一个 tab(四个空格),也称制表符 var str = “我是\t大神程序员”; console.log(str);
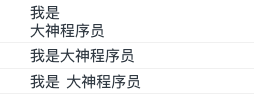另外还需要说一点的是在`javaScript`中的字符串默认是不容许换行的。<br />我们可以用`\`来将空格转化为空格。<br />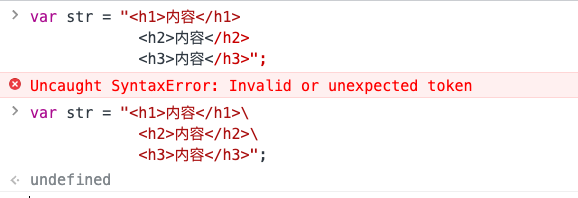<a name="BHH09"></a>## RegExp 正则表达式:::info`RegExp(regular expression)`正则表达式就是“将字符串按照一定的规则进行匹配或者检索这个规则中执行的字符类型”。:::「正则表达式」是一个对象,创建正则的方式有两种:<br />1、对象字面量(或者直接声明对象)```javascript// 类似创建对象和数组// var obj = {}// var arr = []var reg = /正则/修饰符;
2、实例化对象
// 类似创建对象和数组// var obj = new Object// var arr = new Arrayvar reg = new RegExp("正则","修饰符");
正则的引用关系
// new 的时候是完全新的正则对象(深拷贝)var reg1 = /test/;var reg2 = new RegExp(reg1);reg1.a = 1;console.log(reg2.a); // undefind// 不 new 的时候是拿来正则对象的引用var reg1 = /test/;var reg2 = RegExp(reg1);reg1.a = 1;console.log(reg2.a); // 1
正则的字符/括号
修饰符
正则表达式有以下修饰符
i |
不区分大小写 |
|---|---|
g |
全局匹配 |
m |
多行匹配 |
// i 是让正则在检测字符串的时候不区分大小写// 用正则查找字符串中的 testvar reg = new RegExp("test");var str = "This is a test";// test() 是 RegExp 对象的一个方法,表示检测字符串中是否有匹配的字符console.log(reg.test(str)); // true// 用正则查找字符串中的 testvar reg = /test/;var str = "This is a Test";console.log(reg.test(str)); // false// 如果我们不加修饰符得到 false ,因为字符串中没有小写的 test// 当我们加上修饰符 i 就能得到var reg = /test/i;var str = "This is a Test";console.log(reg.test(str)); // true
// g 是让正则在检测字符串进行全局查找(默认在匹配成功一个之后就不会继续匹配)// 不加修饰符 gvar reg = /test/i;var str = "This is a Test; Test is important.";console.log(str.match(reg)); // ['Test']// 加了修饰符 gvar reg = /test/ig;var str = "This is a Test; Test is important.";console.log(str.match(reg)); // ['Test', 'Test']
// m 是让正则在匹配的时候多行匹配(默认只会匹配开头)// ^ 表示以...开头// 不加 mvar reg = /^Test/gi;var str = "Test is a function; \nTest is important;";console.log(str.match(reg)); // ['Test']// 加了 mvar reg = /^Test/gim;var str = "Test is a function; \nTest is important;";console.log(str.match(reg)); // ['Test', 'Test']
元字符(转义字符)
\\w |
表示任意一个字母、数字或下划线 |
|---|---|
\\W |
表示非… |
\\d |
表示 0 - 9 任意一个数字 |
\\D |
表示非… |
\\s |
表示 \\r或\\n或\\t或\\v或\\f的空白字符 |
\\S |
表示非… |
\\b |
表示单词边界 |
\\B |
表示非… |
// \w 表示任意一个字母、数字或下划线[0-9A-z_]// \W 表示非...var reg = /\wab/g;var str = "234abc_%&";console.log(str.match(reg)); // ['4ab']// ========== 分割 ==========var reg = /\Wab/g;var str = "234abc_%&";console.log(str.match(reg)); // null
// \d 表示 [0-9]的数字// \D 表示非...var reg = /\dabc/g;var str = "234abc_%&";console.log(str.match(reg)); // ["4abc"]// ========== 分割 ==========var reg = /\Dabc/g;var str = "234eabc_%&";console.log(str.match(reg)); // ["eabc"]
// \s 表示 [\r\n\t\v\f] 字符// \S 表示非...// \r回车 \n换行 \tTab \v垂直换行 \f换页var reg = /\sab/g;var str = "23 abc-&%\nabv";console.log(str.match(reg)); // [' ab', '\nab']
// \b 表示单词边界// \D 表示非...// 单词边届的意思:https://zhidao.baidu.com/question/584326176.htmlvar reg = /\bThis/g;var str = "This is a test";console.log(str.match(reg)); // ['This']
量词
个人对量词的理解📗: 正则默认只会按着一位进行匹配,量词是设置前面的字符按照
n位进行匹配
:::info
💡正则表达式匹配的时候有两个特点需要切记:
1、不会回头在进行匹配:当一个或一组字符匹配成功后不会再进行匹配
2、贪婪模式:正则在进行匹配的时候能匹配多就不匹配少
总结:字符串从左到右依次先匹配多,再匹配少,如果一旦匹配上就不回头匹配了
:::
| n+ | 表示n字符至少出现 1 次,最多出现无数次(等价{1,}) |
| —- | —- |
| n* | 表示n字符至少出现 0 次,最多出现无数次(等价{0,}) |
| n? | 表示n字符至少出现 0 次,最多出现 1 次(等价{0,1}) |
| n{x, y} | 表示n字符至少出现x次,最多出现y次 |
| n{x} | 表示n字符只能出现x次 |
// n+var reg = /\w+/g; // 匹配任意字符出现 {1,} 位var str = "abcdefg";console.log(str.match(reg)); // ['abcdefg']
// n*var reg = /\w*/g; // 匹配任意字符出现 {0,} 位var str = "abcdefg"; // g 和 " 之间也会被匹配console.log(str.match(reg)); // ['abcdefg', '']// ========== 分割 ==========var reg = /\d*/g; // 匹配任意数字出现 {0,} 位var str = "abcdefg"; // 当匹配不到数字的时候就会去匹配空格,例如 a 和 b 之间的空格,b 和 c 之间的 空格console.log(str.match(reg)); // ['', '', '', '', '', '', '', '']
// n?var reg = /\w?/g; // 匹配任意字符,出现 {0,1} 位var str = "abcdefg";console.log(str.match(reg)); // ['a', 'b', 'c', 'd', 'e', 'f', 'g', '']
// n{x,y}var reg = /\w{1,2}/g; // 匹配任意字符出现 {1,2} 位var str = "abcdefg";console.log(str.match(reg)); // ['ab', 'cd', 'ef', 'g']
// n{x,}var reg = /\w{5,}/g;var str = "abcdefg";console.log(str.match(reg)); // ['abcdefg']
// n{x}// 匹配 138 开头的11位手机号码var str = "13812345678";var reg = /^138\d{8}/;console.log(reg.test(str));
单字符
| |
表示或者,可以和()组合 |
|---|---|
. |
表示任意一个非空白字符 |
^n |
表示以n开头的字符串 |
n$ |
表示以n结尾的字符串 |
// | 表示或者var str = "234asjkhjsais12312lajknkj";var reg = /(123|234)/g;console.log(str.match(reg)); // [234, 123]// ==========// 在()内使用 | 表示 123[a-z] 或者 234[a-z]var str = "234vajkhjsais123slajknkj";var reg = /(123|234)[a-z]/g;console.log(str.match(reg)); // ['234v', '123s']// ==========// 直接使用 | 表示 123 或者 234[a-z]var str = "234vajkhjsais123slajknkj";var reg = /123|234[a-z]/g;console.log(str.match(reg)); // ['234v', '123']
// . 表示任意一个非空白字符var reg = /./g;var str = "This\ris\ta\ntest;6&";console.log(str.match(reg)); // ['T', 'h', 'i', 's', 'i', 's', '\t', 'a', 't', 'e', 's', 't', ';', '6', '&']
// ^nvar reg = /^ab/gm;var str = "abcdabcd\nabcdabcd";console.log(str.match(reg)); // ['ab', 'ab']
// n$var reg = /cd$/gm;var str = "abcdabcd\nabcdabcd";console.log(str.match(reg)); // ['cd', 'cd']
// 检查以abcd开头和以abcd结尾的字符串var reg = /^abcd.*abcd$/g;var str = "abcd123123abcd";console.log(str.match(reg));// ========== 分割线 ==========// 匹配检查以abcd开头和以abcd结尾的字符串,且中间是数字var reg = /^abcd\d+abcd$/g;var str = "abcd123123abcd";console.log(str.match(reg));
正向预查和反向预查
相关链接:正向预查
n(?=z) |
正向匹配,表示n后紧挨着z的字符串,z不会出现在匹配结果字符串里面 |
|---|---|
n(!=z) |
反向匹配,表示n后非紧挨着z的字符串,z不会出现在匹配结果字符串里面 |
n(?:z) |
不捕获分组,不让字符串捕获子表达式 |
// n(?=z)var str = "abcdabcd";var reg = /a(?=b)/g; // 匹配 a 后面是 b 的字符串,b 不会出现在匹配的字符串里console.log(str.match(reg)); // ['a', 'a']// ========== 分割 ==========var str = "windows98 windows7 windows8 windows8.1 windows10 windowsVista windowsXP";var reg = /windows(?=7|8\.1|8)/g;var a = str.match(reg);console.log(a); //返回[ 'windows', 'windows', 'windows' ]// ========== 分割 ==========// 对密码进行校验,密码的规则:至少 6 位,必须包含数字、大写字母、小写字母、特殊符号// reg 有点多条件并列的意思 if(6位 && 包含数字 && ...)var reg = /^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&])/;var str = "123abcABC^";reg.test(str)
// n(!=z)var str = "windows98 windows7 windows8 windows8.1 windows10 windowsVista windowsXP";var reg = /windows(?!7|8\.1|8)/g;var a = str.match(reg);console.log(a); //返回[ 'windows', 'windows', 'windows' ,'windows']
// n(?:z)var str = "abc";var reg = /(a)(b)(c)/;console.log(str.match(reg)); // ['abc', 'a', 'b', 'c']// 用子表达式括起来,不仅能匹配(b)(c)还能单独匹配 (b) 和 (c)// 这样的行为称为 捕获分组(捕获子表达式)// ========== 分割 ==========var str = "abc";var reg = /(?:a)(b)(c)/;console.log(str.match(reg)); // ['abc', 'b', 'c']
括号表达式
[] |
表示只要是括号内的任意一位 |
|---|---|
() |
表达式的引用,一般和表达式一起使用(或者理解为一个分组) |
// [] 表示只要是括号内的任意一位var str = "0917sqjnka12198";var reg = /[1234567890][1234567890][1234567890]/g;console.log(str.match(reg)); // ['091', '121']// 以上的正则表示字符串中的第1位是[]里的任意1位,且第2位是[]里的任意1位,且第3位是[]里的任意1位// 匹配成功的字符不会再参与匹配// 比如:091 先进行匹配,如果 091 匹配成功,接着用 7sq 进行匹配,7sq 不匹配在用 sqj 进行匹配...// ========== 分割 ==========var str = "wxyz";var reg = /[wx][xy][z]/g;console.log(str.match(reg)); // [xyz]// 第一次:wxy 去匹配,不成功因为第3位要求是z// 第二次:xyz 去匹配,成功
// [] 内默认是或的关系,内部还可以用 - 表示区间var str = "ankjkjjkGhhjqwhq9Z087Jhjhjgu";// var reg = /[a-z][0-9][A-Z]/g;var reg = /[a-z0-9A-Z][0-9][A-Z]/;console.log(str.match(reg)); // ["q9Z"]
// [] 内使用 ^ 表示非的意思var str = "ankjkjjkGhhjqwhq9Z087Jhjhjgu";var reg = /[^0-9][a-z]/g;console.log(str.match(reg)); // ['an', 'kj', 'kj', 'jk', 'Gh', 'hj', 'qw', 'hq', 'Jh', 'jh', 'jg']
// 子表达式和反向引用// 例如下面的正则:匹配 xxyy yyzz 这样的迭代字符// 当我们想要匹配任意两个相同字符的时候,就可以使用 () 表面子表达式var str = "bbaaaaccaaaaidddbaaaaa";var reg = /(\w)\1(\w)\2/g;// () 内就是一个表达式,\1 表示引用第一个表达式,也就是 (\w)// \2 表示引用第二个表达式,也就是 (\w)// (\w)(\w) 和 (\w)\1 的区别:// (\w)(\w) 表示任意两个连续的字符,比如 Ac、MM、K9 都属于两个连续的 \w 字符// \1 则表示对 (\w) 的引用,当 (\w) 匹配到 b 的时候,\1 也表示 \bconsole.log(str.match(reg)); // ['bbaa', 'aacc', 'aaaa', 'aaaa']
正则对象的属性
正则表达式是个对象,所以它有相关的属性。
var reg = /(\w)\1(\w)\2/g;console.log(reg.global); // 是否设置 g 修饰符console.log(reg.ignoreCase); // 是否设置 i 修饰符console.log(reg.multiline); // 是否设置 m 修饰符console.log(reg.source); // 正则表达式的本体
正则对象的方法
reg.test(str)
:::info 用正则去检测字符串是否符合正则的规则! :::
// 匹配 138 开头的11位手机号码var str = "13812345678";var reg = /^138\d{8}/;console.log(reg.test(str));
reg.exec(str)
:::info
根据正则表达式查找,结果会返回一个长度为1的数组 (数组只有一个值)
每次调用后递增结果,递增到最后返回null然后从头递增
:::
var str = "This is Test. Test is important"var reg = /Test/gconsole.log(reg.exec(str));

另外字符串还有
match()、replace()可以和正则搭配使用。 详见:String 字符串相关的方法
贪婪模式和非贪婪模式
正则表达式默认是「贪婪模式」(能匹配多绝不匹配少)。
比如我们想匹配{{}}的字符串:
var str = "abc{{efg}}abcd{{xyz}}";var reg = /{{.*}}/g;console.log(str.match(reg)); // ['{{efg}}abcd{{xyz}}']
可以看到默认会直接从{{e然后匹配到z}},这就是贪婪模式的表现。
那么如何将「贪婪模式」转为「非贪婪模式」呢?
var str = "abc{{efg}}abcd{{xyz}}";var reg = /{{.*?}}/g;console.log(str.match(reg)); // ['{{efg}}', '{{xyz}}']
我们只需要在**{{.*}}**加上问号**{{.*?}}**就变为非贪婪模式了!!!**?**单独使用的时候是表示字符至少出现 0 次,最多出现 1 次,而**?**和量词一起使用的时候就会变成「非贪婪模式」
举例 🌰:
var str = "aaaaaa";var reg = /\w?/g;console.log(str.match(reg)); // ['a', 'a', 'a', 'a', 'a', 'a', '']// ========== 分割 ==========var str = "aaaaaa";var reg = /\w??/g;console.log(str.match(reg)); // ['', '', '', '', '', '', '']
和 String.prototype.replace() 联合的案例:
:::info
该方法用来替换字符串中的字符,接收两个参数
参数1:要替换的字符串或正则表达式
参数2:要将字符串替换为什么字符,参数2还可以是一个函数,函数的参数是正则中的子表达式
💡 该方法本身不具备全局替换的能力,默认只会替换一次
:::
// 将 plus 替换为 +var str = "JSplusplus";console.log(str.replace("plus", "+")) // JS+plus// 用正则的方式去替换var str = "JSplusplus";console.log(str.replace(/plus/g, "+")) // JS++
// 用 $ 去拿正则中的子表达式var str = "aabbccdd";var reg = /(\w)\1(\w)\2/g;console.log(str.replace(reg, "$2$2$1$1")); // bbaaddcc// 这里的 $2 表示正则中的 (\w)\2 中的 (\w)// $1 表示正则中的 (\w)\1 中的 (\w)
// 用 replace 的函数去实现var str = "aabbccdd";var reg = /(\w)\1(\w)\2/g;var str1 = str.replace(reg, function ($, $1, $2) {// $ 当前匹配出来的字符串 aabb 和 ccdd// $1 是第一个子表达式// $2 是第二个子表达式return $2 + $2 + $1 + $1;});console.log(str1); // bbaaddcc
// 将 -p 转为大写var str = "js-plus-plus";var reg = /\-p/g;var reg = str.replace(reg, "P");console.log(reg); // jsPlusPlus// 将 -b 和 -p 都转化为大写var str = "js-blus-plus";var reg = /\-(\w)/g;var reg = str.replace(reg, function ($, $1) {// $1 就表示 (\w) 也就是 b 和 preturn $1.toUpperCase();});console.log(reg);// Plus 转换为 _plusvar str = "jsPlusPlus";var reg = /([A-Z])/g;var res = str.replace(reg, function ($, $1) {return "_" + $1.toLowerCase();});console.log(res); // js_plus_plus
// 将 xxyyzz 转为 XxYyZzvar str = "xxyyzz",reg = /(\w)\1(\w)\2(\w)\3/,res = str.replace(reg, function ($, $1, $2, $3) {return $1.toUpperCase() + $1 + $2.toUpperCase() + $2 + $3.toUpperCase() + $3;});console.log(res); // XxYyZz
// 将 aabbcc 转为 a$b$c$ 且不能使用 replace 的 functionvar str = "aabbcc",reg = /(\w)\1(\w)\2(\w)\3/,res = str.replace(reg,`$1$$$2$$$3`); // 当使用 $ 的时候需要用 $ 进行转义,其他字符正常console.log(res); // a$b$c// ========== 分割 ==========var str = "aabbcc",reg = /(\w)\1(\w)\2(\w)\3/,res = str.replace(reg,`$1/$2/$3`);console.log(res); // a/b/c
// 正则给字符串去重var str = "aabbcc",reg = /(\w)\1(\w)\2(\w)\3/g;console.log(str.replace(reg, "$1$2$3")); // abc// ========== 分割 ==========var str = "aaaaabbbbbcccccccc",reg = /(\w)\1*/g;console.log(str.replace(reg, "$1")); // abc
// 给字符用千分位用,分割// 100000000000 =》 100,000,000var str = "1000000000000";var reg = /(?=(\B)(\d{3})+$)/g;console.log(str.replace(reg, "$1,")); // 1,000,000,000,000
// 用 replacr 给模版字符串替换数据var str = "My name is {{name}}. I'm {{age}} years old.";var reg = /{{(.*?)}}/g;var res = str.replace(reg, function ($, $1) {return {name: "Jone",age: 32,}[$1];});console.log(res); // My name is Jone. I'm 32 years old.

若有收获,就点个赞吧
0 人点赞
