通过上个章节我们已经学会了中间件的用法,在 gin 框架中路由的回调函数、中间件回调函数本质都是一样的,我相信大家使用已经没有任何问题了,那么在本章节我们就由浅入深,继续深度学习中间件.
基础用法
1.中间件的加载(注册)
注意:Use 函数仅仅只是负责加载(注册)中间件,不负责调用.
// 路由可以载入很多个中间件,很多个到底是多少个?// 想知道答案,那我们继续追踪gin源码去揭晓答案,这里请带着你的疑问向后学习backend.Use(authorization.CheckTokenAuth(), 下一个中间件,继续下一个中间件, 省略很多个...)
进阶学习
后续知识点对于初学者来说存在一定的难度,主要是因为在 gin 中,加载的中间件函数: func ( *gin.Context){ } 在后续执行时会和注册的路由回调函数在同一个逻辑处执行,中间件函数、路由回调函数都是平行关系,不同的区别是先后顺序不同,gin 对这块逻辑处理是相同的方式,这就需要我们从路由开始追踪,因此涉及到的代码会比较多,过程比较复杂.
学完本章节,gin 最核心的主线逻辑也就彻底搞明白了。
这个过程其实就是对一个 request -> response 的全过程源代码剖析,难度比较大,
2.gin 中间件加载过程
// Use 的作用就是首先载入中间件回调函数:func(*Context)// 首先存储起来,然后等着被后续逻辑调用// 我们使用 goland ,ctrl+鼠标左键,点击 Use 继续追踪gin源码func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes {group.Handlers = append(group.Handlers, middleware...)return group.returnObj()}// group.Handlers 定义的最终原型如下,本质上就是 func(*Context) 的切片,存储很多个回调函数type HandlersChain []HandlerFunc // type HandlerFunc func(*Context)// 学习到这里,你必须知道的就是:// gin的中间件回调函数全部被存储在 group.Handlers 变量了// 这里您对该变量有印象就行,后面还需要继续使用该变量
学习到这里,我们已经知道中间件处理函数被 Use 函数注册了在了 group.Handlers 变量存储起来了,Use 函数可以加载很多个中间件,究竟是多少个,这里我们依然不知道他的具体数量,还有它们什么时候执行,我们也不知道 … …
我们只看见 Use 函数最后返回了group.returnObj() ,它是所有路由的处理接口:IRoutes ,已经结束了,我们无法向下追踪了,那就只能从其他地方入手追踪了,既然中间件是加载在具体的路由前面,那么它肯定在某个具体的路由被访问时执行。
3.gin 中间件执行逻辑
3.1 一个具体的路由地址被请求后的 gin 源码究竟是什么
3.1.1 定义一个具体的路由以及回调函数
// 1.省略其它无关代码users.GET("list", func (c *gin.Context){// 编写该路由路径对应的业务处理回调函数// 我们省略具体过程 ... ...})
3.1.2 **users.GET** 背后的 gin 源码追踪分析
// 2.在 goland 中,ctrl+鼠标左键 点击 GET 函数,源代码如下:func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {// 很明显该函数是 GET + relativePath(开发者定义的路由路径)对应的业务处理逻辑// 与中间件一样,他的请求回调函数也可以有很多个,具体数量不知道...// 那么就需要继续追踪 group.handle 源代码return group.handle(http.MethodGet, relativePath, handlers)}// 3.group.handle 函数源码func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {// 将定义的路由相对路径拼接为完整的绝对路径// 因为一个完整的路径往往和前面定义的路由组路径有关系,因此需要一系列拼接absolutePath := group.calculateAbsolutePath(relativePath)// 针对完整路由路径将关联的回调函数全部组合出来// 究竟如何组合,后续继续追踪源码handlers = group.combineHandlers(handlers)// 将请求方式(GET、POST等)结合完整路径作为key,处理函数作为 value// 以 key => value 的形式注册,value 可以是很多个回调函数group.engine.addRoute(httpMethod, absolutePath, handlers)return group.returnObj()}//4. group.combineHandlers 源代码追踪func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain {// 看到这里还记得 group.Handlers 变量吗?如果不记得请查看本章节 2 标题部分// finalSize 表示 中间件回调函数的数量 + 具体路由的回调函数数量的总和finalSize := len(group.Handlers) + len(handlers)// 如果 finalSize >= abortIndex 就会发生panic,// abortIndex 的定义值: math.MaxInt8 / 2 ,// 在go语言中,官方定义: MaxInt8 = 1<<7 - 1, 表示 1*(2^7)-1,最终值:127// 那么 abortIndex = 127/2 取整 = 63// 至此我们终于知道, gin 的中间件函数数量 + 路由回调函数的数量总和最大允许 63 个.// 为什么是 63 个回调函数不是62? 因为回调函数的存储索引是从0开始的,最大索引为:62if finalSize >= int(abortIndex) {panic("too many handlers")}// 以上条件检查全部通过后,将中间件回调函数和路由回调函数全部合并在一起存储// HandlersChain 本质就是 [] func(*Context)mergedHandlers := make(HandlersChain, finalSize)// group.Handlers 是中间件函数,他在 mergedHandlers 中存储的顺序靠前,也就是索引比较小copy(mergedHandlers, group.Handlers)// handlers 是路由回调函数,他的存储位置比中间函数靠后copy(mergedHandlers[len(group.Handlers):], handlers)// 最终返回中间件函数+路由函数组合在一起的全部回调函数return mergedHandlers}//5. group.engine.addRoute 源码分析// gin的路由是一个很复杂的路由前缀树算法模型,完整过程很复杂// 这里我们主要追踪路由以及回调函数的 存储/注册 过程func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {assert1(path[0] == '/', "path must begin with '/'")assert1(method != "", "HTTP method can not be empty")assert1(len(handlers) > 0, "there must be at least one handler")debugPrintRoute(method, path, handlers)root := engine.trees.get(method)if root == nil {root = new(node)root.fullPath = "/"engine.trees = append(engine.trees, methodTree{method: method, root: root})}// 在这里,gin 将我们定义的完整路径和回调函数进行了注册// 源码后续继续追、分析root.addRoute(path, handlers)// Update maxParamsif paramsCount := countParams(path); paramsCount > engine.maxParams {engine.maxParams = paramsCount}}//6.root.addRoute(path, handlers) 函数在按照键 => 值进行注册路由与回调函数时调用了很多其他函数// 这里我将过程函数名字列举如下func (n *node) addRoute(path string, handlers HandlersChain) {// 省略其他无关代码// 又继续调用如下函数n.insertChild(path, fullPath, handlers)// ... ...}// 省略很多其他的代码}// 7. n.insertChildfunc (n *node) insertChild(path string, fullPath string, handlers HandlersChain) {//省略其他无关代码child := &node{priority: 1,fullPath: fullPath, // 完整的路由路径}// 最终所有的回调函数n.handlers = handlers}// node 的结构体定义,发现就是自己嵌套自己的一个结构体// handlers 成员的数据类型(HandlersChain)本质就是 []func(*gin.Context)// 至此我们彻底明白:路由的存储模型是一个树形结构,每个节点都有自己路由路径以及回调函数 handlerstype node struct {path stringindices stringwildChild boolnType nodeTypepriority uint32children []*node // child nodes, at most 1 :param style node at the end of the arrayhandlers HandlersChainfullPath string}
通过以上分析,我们搞清楚了 users.GET(路由路径, 回调函数1,回调函数2,...) 后背的源码逻辑,总结起来就是按照 路由键 加载相关的全部回调函数,包括中间件回调函数+路由回调函数,并且所有回调函数的总数量加起来最大值为 63 个。
但是学习到这里我们依然不知道,以上所有回调函数什么时候被执行,那么继续向下学习
3.1.3 gin路由背后的所有回调函数什么时候被执行?
gin 最核心的东西其实是一个路由包,负责定义路由以及回调函数,当客户端的请求来临时负责快速匹配路径,进行组合相关的回调数。
至于什么时候执行其实是依赖于 go语言的 net/http 库的函数 ServerHTTP。
// 1.gin初始化一个路由引擎,它返回的是一个 *gin.Enginevar router = gin.Default()// 省略无关代码// 由gin路由引擎启动一个web服务// 我们继续追踪源码去分析内部实现router.Run()// 2.router.Run() 源码定义func (engine *Engine) Run(addr ...string) (err error) {defer func() { debugPrintError(err) }()trustedCIDRs, err := engine.prepareTrustedCIDRs()if err != nil {return err}engine.trustedCIDRs = trustedCIDRsaddress := resolveAddress(addr)debugPrint("Listening and serving HTTP on %s\n", address)// 最关键的在这里// gin 将 engine 传递给了 http.ListenAndServe ,这个是 go 语言官方的 web 服务器启动函数// engine 其实就是我们初始化出来的一个路由引擎(router = gin.Default())// 然后不停地给这个路由引擎注册路由键,以及对应的回调函数,最终交给了 go 语言web服务入口去执行// 那么 http.ListenAndServe 为什么会调用 gin 初始化出来的路由引擎呢?// 需要我们继续追踪源代码err = http.ListenAndServe(address, engine)return}//3.ListenAndServe 官方web服务启动函数入口// 参数一:web服务器的ip端口,例如:0.0.0.0:8080// 参数二:(请看下文)func ListenAndServe(addr string, handler Handler) error {server := &Server{Addr: addr, Handler: handler}return server.ListenAndServe()}// 参数二定义原型,他是一个接口,只要开发者实现了这个接口,将你的实现原型传递进来// 官方的net库函数就会回调你type Handler interface {ServeHTTP(ResponseWriter, *Request)}//4.那么我们看一下gin 是如何实现上面这个接口的func (engine *Engine) ServeHTTP (w http.ResponseWriter, req *http.Request) {// engine.pool.Get() 本质就是创建一个空白的 Context// engine.pool 是组合的go官方 sync.pool 主要作用是就是提供一个对象池,不要频繁创建大对象c := engine.pool.Get().(*Context)// 这里的响应器实际上是由 go 官方的 net/http 库相关函数在接收到请求时初始化化的c.writermem.reset(w)// 这里的Request也是由 go 官方的 net/http 库相关函数在接收到请求时初始化化的c.Request = req// 这里有个地方也很关键,c.index 初始化值被设置为: -1 ,// 后文 Next 函数 c.index++ 其实就是从0所以开始c.reset()// gin的 Context 上下文成员参数初始化完成后// gin将处理逻辑继续交给了该函数,需要我们继续追踪engine.handleHTTPRequest(c)// 上下文对象使用完后放回对象池,下次可以直接获取,避免频繁创建大对象engine.pool.Put(c)}// 5.engine.handleHTTPRequest(c) 源码追踪// 该函数代码比较多,主要是检查核心函数执行前的所有条件必须满足,否则就在这里报错func (engine *Engine) handleHTTPRequest(c *Context) {// 省略其他代码....// 这里根据客户端实际请求的路径、参数,大小写不敏感模式去寻找已经注册的路由表中对应的调函数value := root.getValue(rPath, c.params, unescape)if value.params != nil {c.Params = *value.params}if value.handlers != nil {//value.handlers 路由键对应的全部回调函数c.handlers = value.handlers// 路由全路径c.fullPath = value.fullPath// 最核心的东西,所有回调函数要开始执行了// 内部具体是什么,需要我们继续追踪c.Next()c.writermem.WriteHeaderNow()return}// 省略其他代码....}//6. c.Next() 源码定义// 看到这里终于恍然大悟,所有的谜团全部被解开,原来 Next 是负责执行一个具体的路由定义的全部回调函数//它执行顺序是按照索引从小到大开始执行的,也就是说首先会执行中间件回调函数,然后才是路由对应的回调函数// 因为我们在定义路由回调函数的时候只有一个参数就是 *gin.Context, 开发者拿到的这个参数其实是// go 官方库 net/http 的web服务启动在接受到请求时调用了gin自己实现的接口函数,初始化好参数// 作为开发者就可以调用 context 上初始化好的参数,以及gin绑定在上面的所有函数func (c *Context) Next() {c.index++// 开发者在任何一个回调函数只要调用了 Abort 就会随时终止后面的回调函数执行// 具体参见后面第 7 条,以及前文分析的最大回调函数总数量为:63 个for c.index < int8(len(c.handlers)) {// 这里按照回调函数最开始的注册顺序,去执行.// 那么网上的教程说的gin的中间件是洋葱模型去哪里了?我们后文继续分析c.handlers[c.index](c)c.index++}}//7. 最后我们再继续分析一个函数// 如果开发者在任何一个回调函数调用了本函数,那么 index 值瞬间就被设置为 63func (c *Context) Abort() {// abortIndex 为一个常量值:63c.index = abortIndex}
3.2 深度剖析 中间件中的 Next 函数以及传说中的洋葱模型
我们先介绍一下洋葱模型概念:代码段的加载顺序和执行顺序是相反的,那么就是洋葱模型。 知道概念以后,我们就继续探索,在gin的中间件里面,洋葱模型是如何被触发的。
当你看文档已经看到看到这里了,距离完全掌握gin的主线核心逻辑仅差一步之遥,那么就继续分析一下 Next 函数以及传说中的洋葱模型是如何出现的。
在这里我再次提醒一下大家:
1.gin 提供的 web 服务,是按照 go 官方的 web 服务接口要求去实现的
// 1.任何人只要实现了这个接口func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {}//2.将你的具体实现结构体,gin 里面就是 engine// 传递给 ListenAndServe 函数,当请求到达时就能被官方的web服务回调 ServeHTTPerr = http.ListenAndServe(address, engine)
gin 实现的 ServerHTTP ```go // 3. gin 实现的 ServerHTTP func (engine Engine) ServeHTTP(w http.ResponseWriter, req http.Request) {
// engine.pool.Get() 本质就是创建一个空白的 Context // engine.pool 是组合的go官方 sync.pool 主要作用是就是提供一个对象池,不要频繁创建大对象 c := engine.pool.Get().(*Context) c.writermem.reset(w) c.Request = req
// 该函数里面有会把 c.index设置为 -1 c.reset()
// 这里的 c 就是客户端请求到达服务器时,gin给我们初始化的Conetxt 上下文 // 而 开发者编写的回调函数参数都是 *gin.Context // 因此所有回调函数的参数都是一个上下文指针,并且前一个函数如果操作了上下文的对象成员 // 那么下一个函数拿到的值就是前一个回调函数处理的结果 engine.handleHTTPRequest(c)
// 上下文对象使用完后放回对象池,下次可以直接获取,避免频繁创建大对象engine.pool.Put(c)
}
gin 的 ServerHTTP 负责每一次客户端请求服务端时,初始化一个上下文 Context,而开发者编写的回调函数参数都是 *gin.Context, gin 官方的目的就是把 Context 底层初始化工作做好,然后当做参数交给开发者,由开发者继续基于这个 Context 开发其他功能。<br />那么,所有开发者必须明确一点,这个 Context 是一个结构体的指针,他的任何一个成员在所有回调函数都是共享的。<br />例如 Contex 结构体的定义如下:```go// gin 定义的Context,这里我们首先关注一下成员 indextype Context struct {writermem responseWriterRequest *http.RequestWriter ResponseWriterParams Paramshandlers HandlersChain// index 成员在 Next 函数被 index++ 然后使用// 这里要说的是,index++ 以后在任何一个开发者编写的回调函数,该值都是共享的// 那么为什么要介绍这个变量,下文我们会使用到该变量index int8fullPath stringengine *Engineparams *Params}
3.2.1 在 gin 中编写一个中间件标准格式1:
所有中间件回调函数、路由对应的回调函数都是由
func (c *Context) Next()统一调用的。
// 定义第一个中间件middleware1:= func(c *gin.Context) {fmt.Printf("中间件001\n")}// 定义第二个中间件middleware2:= func(c *gin.Context) {fmt.Printf("中间件002\n")}router.Use(middleware1, middleware2).GET("/test_middleware", func(context *gin.Context) {fmt.Printf("路由回调函数\n")context.String(http.StatusOK, "测试中间件")})
通过请求接口 http://127.0.0.1:20201/test_middleware 输出结果如下: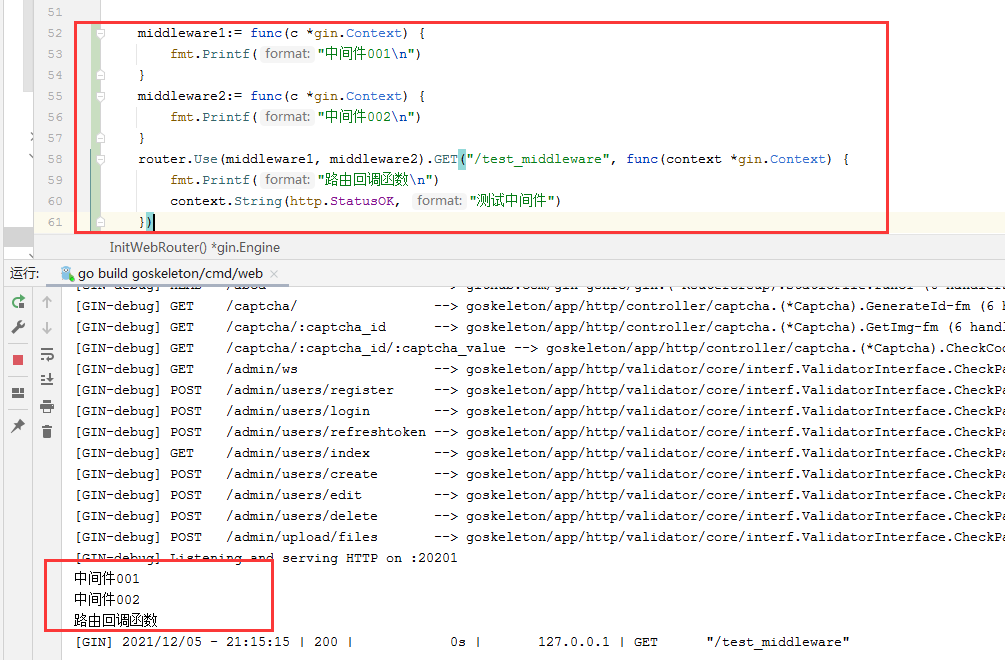
上述代码的执行,一路下一步,按照顺利依次去执行,最后执行了路由的回调函数。
上述过程也符合我们前面所介绍的 “所有路由键对应的函数都是从中间件函数到路由回调函数依次执行的”原则。
如果其中一个中间件不通过,那么就使用如下代码即可:
// 定义第一个中间件middleware1:= func(c *gin.Context) {// 通过前面的代码分析,我们都知道 Abort() 在任何一个回调函数都可以终止后续的所有回调继续执行// 但是 Abort 不终止本函数的代码c.Abort()fmt.Printf("中间件001\n")}// 定义第二个中间件middleware2:= func(c *gin.Context) {fmt.Printf("中间件002\n")}// 定义一个测试路由router.Use(middleware1, middleware2).GET("/test_middleware", func(context *gin.Context) {fmt.Printf("路由回调函数\n")context.String(http.StatusOK, "测试中间件")})
测试示例,说明了 Abort 函数的作用终止了后续的所有的回调函数,所谓的所有回调函数就是:中间件函数+路由回调函数。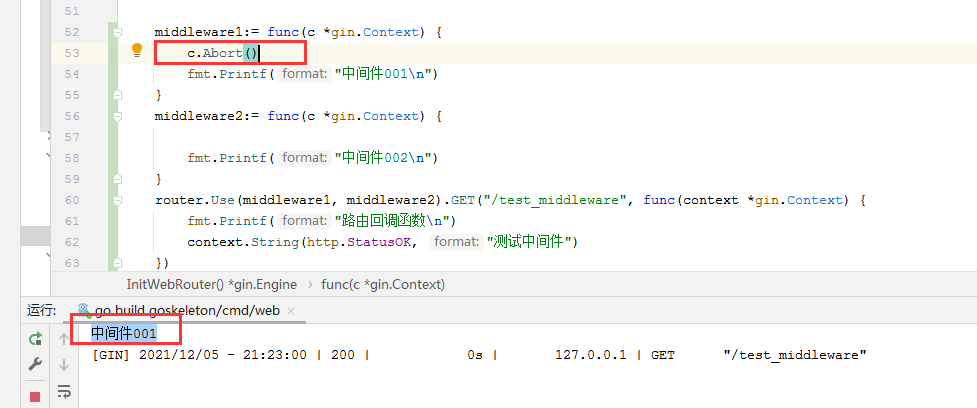
至此,我们没有发现任何洋葱模型,所有的函数都是顺序去执行。
3.2.2 在 gin 中编写一个中间件标准格式2:
这里首先我们要继续回顾一下前面的一个函数 Next ,再次查看一下源代码的定义:
// 该函数在 3.1.3 章节 112 行已经做了介绍,这里复制过来func (c *Context) Next() {c.index++// 开发者在任何一个回调函数只要调用了 Abort 就会随时终止后面的回调函数执行// 具体参见后面第 7 条,以及前文分析的最大回调函数总数量为:63 个for c.index < int8(len(c.handlers)) {// 这里按照回调函数最开始的注册顺序,去执行.// 那么网上的教程说的gin的中间件是洋葱模型去哪里了?我们后文继续分析c.handlers[c.index](c)c.index++}}
开始定义中间件的另外一种形式:
middleware1:= func(c *gin.Context) {fmt.Printf("中间件001--执行顺序:1\n")c.Next()fmt.Printf("中间件001---执行顺序:4\n")}middleware2:= func(c *gin.Context) {fmt.Printf("中间件002--执行顺序:2\n")c.Next()fmt.Printf("中间件002--执行顺序:3\n")}router.Use(middleware1, middleware2).GET("/test_middleware", func(context *gin.Context) {fmt.Printf("路由回调函数\n")context.String(http.StatusOK, "测试中间件")})
通过请求接口 http://127.0.0.1:20201/test_middleware 输出结果如下: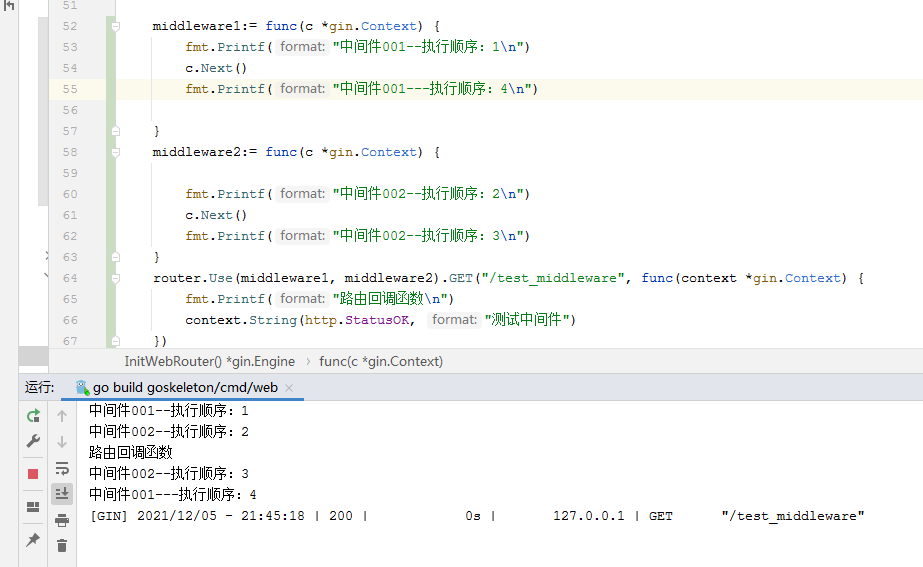
从结果可以看出代码的执行顺序不是顺序依次执行了,而是出现了所谓的洋葱模型,Next 前面的代码都是顺序执行的,但是Next函数后面的代码执行和加载顺序是相反的,很符合标准的洋葱模型(Next 后面的代码段先进后出)。
那么为什么会这样呢?我们从 Next 函数源代码解析透视本质:
// *Context 结构体指针是每一次客户端请求到达服务端时,gin 给我们初始化的// *Context 的成员在一次请求过程中被所有的回调函数共享func (c *Context) Next() {// index 的值在任何一个回调函数都是共享的// 因为一次请求只有一个 Context,但是回调函数可以有很多,他们共享了 *gin.Contexc.index++for c.index < int8(len(c.handlers)) {// 这里按照回调函数最开始的注册顺序,去执行.// 但是如果开发者编写的回调函数里面有 Next() ,等于是手动调用了本段代码第3行,// 那么就会立刻触发c.index ++ ,下一个回调函数被执行// 而原本的回调函数 Next 后面的代码就会滞后执行// 越是最先加载的回调函数 Next 函数后面的代码段越是被最后执行,从而形成了洋葱模型c.handlers[c.index](c)c.index++}}
洋葱模型主要的特点:前面的回调函数 Next 后面的代码段可以拿到后面函数的执行结果,前提是后面的回调函数需要把相关值通过 Set 函数设置在 Context 上.
开发者编写的中间件,如果没有 Next() 函数,所有的回调函数都有 gin 统一负责依次调用,如果开发者编写的中间件调用了 Next(),就相当于手动调用了 func (c *Context) Next(){ } ,c.index++ 被快速定位到下一个回调函数去执行。
由于 c.index 在 Context 是共享的,所有开发者调用 Next之后,c.index 的值会依次递增,gin 再次调用下一个时,也不会产生重复调用。
在我们刚学习时或许有一种想法:在中间件校验业务逻辑都 OK 后,是否必须调用 Next 函数才能进入下一个回调函数/下一个环节,现在我们也彻底明白了,最初的想法是错误的,在中间件使用 Next 函数或者不使用,都能进入下一个环节,但是调用 Abort函数,则直接终止后面全部回调函数的执行。

若有收获,就点个赞吧
0 人点赞
