作者 | Ting Chen1Simon Kornblith1Mohammad Norouzi1Geoffrey Hinton1
单位 | Google Research, Brain Team
代码 | https://github.com/Spijkervet/SimCLR
ICML, 2020
SIMCLR 是一个用在 CV 上 的对比学习框架,用来生成下游任务可用的通用表征。该论文的主要贡献为:
- 证明了数据扩充的重要性,并提出采用了两种数据扩充方式:
- 空间/几何转换,包含裁剪、调整水平大小(水平翻转)、旋转合裁剪
- 外观变换:如色彩失真(包含色彩下降、亮度、对比度、饱和度、色调)、高斯模糊合 Sobel 滤波
- 同时还验证了数据扩充方式组合的重要性, 无监督对比学习比监督学习更可以从数据扩充中获益。
- 在特征表示数据和对比损失之间引入非线性转换,可以提高特征表示质量
- 与监督学习对比,更大的 bach size 和更多的训练步骤有利于对比学习
- 对比交叉熵损失的表示学习受益于 norm embeddig 和适当的 temperature 参数。一个适当的temperature可以帮助模型学习困难负例
整个模型的网络结构还是比较经典的,如下图所示。它包含四个组成部分:1)一个随机数据增强模块,用于产生同一个示例的两个相关图片,这两个相关图片可以被认为是正例。数据增强方式就是前面提到的(随机裁剪而后调整到与原图一样大小,随机颜色扭曲、随机高斯模糊)。2)一个神经网络编码层f(),用于提取表示向量,这部分对网络结构没有限制,论文里用的是 ResNet。3)映射层,用于将表示层输出映射到对比损失空间。4)对比学习loss。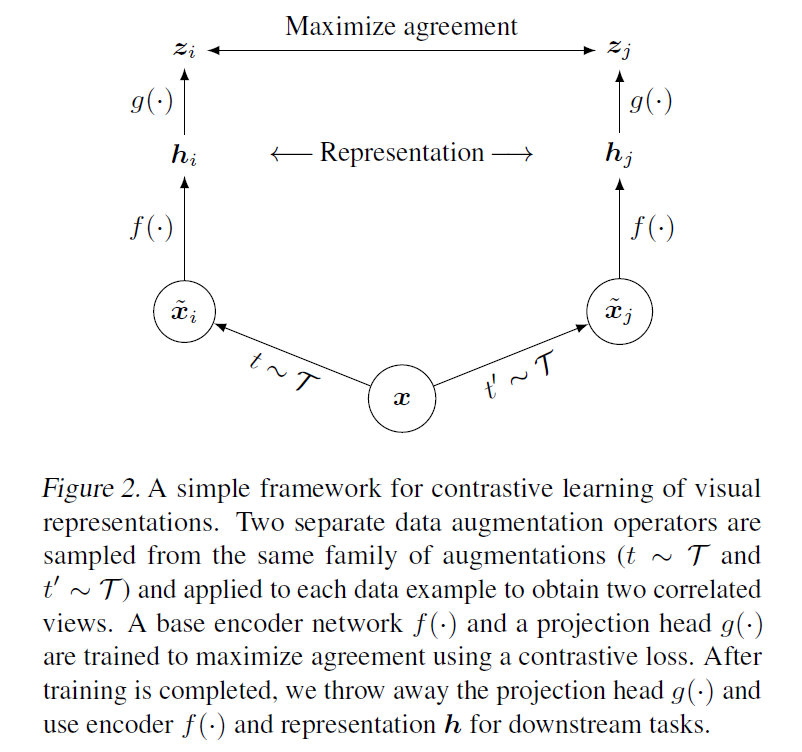
对比学习 loss 的计算公式为: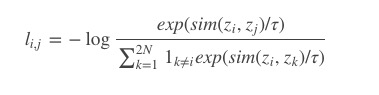
其中 sim 使用 L2 标准化的表征上计算 cosine 相似度。公式的含义是正例的相似度与其他所有负例的相似度在除以 ττ 后算一下 softmax loss。也就是尽肯能的让正例在样本空间与原图片更相近,负例推得更远。
论文还论证了数据扩充方式组合的重要性。当组合增加时,对比预测任务变的更加困难,但表示质量显著提高。
还有一些其他的结论:
- 有监督模型和在无监督模型上训练的线性分类器之间的差距随着模型规模的增大而减小,这表明无监督学习比监督模型从更大的模型中受益更多
- 使用表示层和loss 层间,加一个非线性投影可以显著改善特征表示质量。这个比较好理解,不映射的话高层特征表示会被任务污染,损失一些信息
- 相比于NT-logistic 和 triplet 损失函数,一方面这俩loss 需要使用 semi-hard 负例挖掘,另一方面这俩loss 的表现即使用负例挖掘表现也不如 NT-Xent loss。
- 更大的 batch size 和更长的训练,更有利于对比学习。随着 epoch 变多,不同 batch size 之间的差距会减少或消失
SimCLR 后续还有一些改进-SimCLR v2,主要改进点为:
- 编码层:将 ResNet50 换成了带有 SK 的 ResNet152
- 增大了非线性层的深度,变成了 3 层,并且在进行下游任务时保留了第一层
- 借鉴 Moco 中的记忆机制

若有收获,就点个赞吧
0 人点赞
