Title: 《Self-supervied Product Quantization for Deep Unsupervised Image Retrival》
ICCV, 2021
Github: https://github.com/youngkyunJang/SPQ
论文阅读
韩国首尔国立大学INMC欧洲经委会系
kyun0914@ispl.snu.ac.kr, nicho@snu.ac.kr
摘要
基于有监督深度学习的哈希和矢量量化使得快速和大规模的图像检索系统成为可能。通过充分利用标签注释,与传统方法相比,它们获得了优异的检索性能。然而,为大量的训练数据精确地指定标签是非常困难的,而且注释过程容易出错。为了解决这些问题,我们提出了第一种深度无监督图像检索方法,称为自监督乘积量化(SPQ)网络,它是无标签的,并以自监督的方式进行训练。我们设计了一种交叉量化对比学习策略,通过比较单独转换的图像(视图),联合学习码字和深度视觉描述符。我们的方法分析图像内容以提取描述性特征,使我们能够理解图像表示以进行准确检索。通过在基准上进行大量实验,我们证明了所提出的方法即使在没有监督预训练的情况下也能产生最先进的结果。
1.导言
近似最近邻(ANN)搜索以其低的存储成本和快速的搜索速度在图像检索研究中受到广泛关注。ANN研究中有两种主流方法,一种是哈希[42],另一种是矢量量化(VQ)[16]。这两种方法都旨在将高维图像数据转换为紧凑的二进制代码,同时保持语义相似性,其区别在于测量二进制代码之间的距离。
在散列方法[7,43,17,15,32]中,使用汉明距离(即简单的异或运算)计算二进制代码之间的距离。然而,这种方法有一个局限性,即距离只能用几个不同的值来表示,而复杂的距离表示是无法实现的。为了缓解这个问题,提出了基于矢量量化的方法[23,13,24,2,48,3,49],在距离测量中使用量化实值向量。其中,乘积量化(PQ)[23]是最好的方法之一,能够快速准确地提供检索结果。
PQ的本质是将特征向量(图像描述符)的高维空间分解为若干子空间的笛卡尔积。然后,根据子空间将每个图像描述符划分为若干子向量,并对这些子向量进行聚类以形成质心。结果,每个子空间的码本Codebook配置有相应的质心(码字),其被视为图像的量化表示。PQ方案中两个不同二进制码之间的距离通过使用带查找表的重新赋值码字进行不对称近似,从而得到比哈希更丰富的距离表示。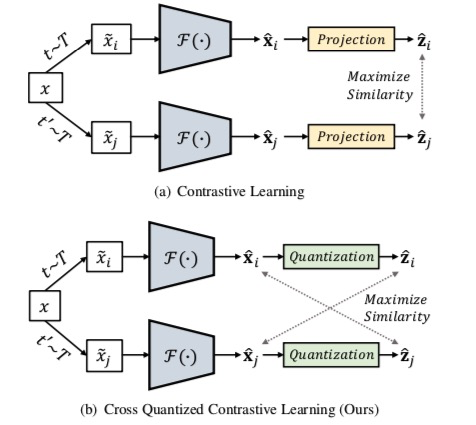
图1。比较(a)对比学习和(b)交叉量化对比学习。分别对两个变换进行采样(![[SPQ]Self-supervised Product Quantization - 图2](/uploads/projects/xhades@dnhkkp/ddb509df37bb5d2c99da7aa4e49436c0.svg) 应用于图像以生成两个不同的视图
应用于图像以生成两个不同的视图![[SPQ]Self-supervised Product Quantization - 图3](/uploads/projects/xhades@dnhkkp/25edd07b776de866c16ebd0c9ed82f02.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图4](/uploads/projects/xhades@dnhkkp/5fe6d164274305d6249808f54a08645d.svg) ,以及相应的深度描述符
,以及相应的深度描述符![[SPQ]Self-supervised Product Quantization - 图5](/uploads/projects/xhades@dnhkkp/f20a26a5ed623cad98f4b3bbcd6505db.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图6](/uploads/projects/xhades@dnhkkp/b662255b902b1a124873396038847de1.svg) ,并分别从特征提取器
,并分别从特征提取器![[SPQ]Self-supervised Product Quantization - 图7](/uploads/projects/xhades@dnhkkp/aef30e904c8c3847f994aac40db4da98.svg) 获得。对比学习中的特征表示是通过比较预测头输出
获得。对比学习中的特征表示是通过比较预测头输出![[SPQ]Self-supervised Product Quantization - 图8](/uploads/projects/xhades@dnhkkp/336f498a0e0cc0e4c3d3d51a5fad4757.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图9](/uploads/projects/xhades@dnhkkp/a3ae10522776e47c52d818e57b0ef5e1.svg) 的相似性来实现的。代替预测头,我们引入了量化头,它收集乘积量化的码本。通过最大化一个视图的深度描述符和另一个视图的乘积量化描述符之间的交叉相似性,将码字和深度描述符联合训练以包含区分性图像内容表示。
的相似性来实现的。代替预测头,我们引入了量化头,它收集乘积量化的码本。通过最大化一个视图的深度描述符和另一个视图的乘积量化描述符之间的交叉相似性,将码字和深度描述符联合训练以包含区分性图像内容表示。
最近,有监督的深度哈希方法[44,5,22,29,47]在大规模图像检索系统中显示了有前景的结果。然而,由于二进制哈希码不能直接用于学习深度连续表示,与使用实向量的检索相比,性能下降是不可避免的。为了解决这个问题,在[20,4,46,31,26,21]中提出了基于量化的深度图像检索方法。通过在连续深度图像特征向量(深度描述符)上引入可微量化方法,允许在实值空间中直接学习深度表示。
尽管深度监督图像检索系统提供了优异的性能,但它们需要昂贵的训练数据注释。因此,还提出了深度无监督散列方法[30、11、39、50、41、14、36、45、37],该方法研究图像相似性,以发现无注释的语义上可区分的二进制代码。然而,尽管基于量化的方法比基于散列的方法具有优势,但只有有限的研究采用量化进行深度无监督检索。例如,[35]使用预提取的视觉描述符代替图像进行无监督量化。
本文提出了第一种基于无监督端到端深度量化的图像检索方法;自监督乘积量化(SPQ)网络,它联合学习特征提取器和码字。如图1所示,SPQ的主要思想是基于自监督对比学习[8,40,6]。我们认为单个图像的两个不同“视图”(单独转换的输出)是相关的,相反,从其他图像生成的视图是不相关的。为了训练PQ码字,我们引入了交叉量化对比学习,最大化了相关深度描述符和乘积量化描述符之间的交叉相似性。这种策略使得深度描述符和PQ码字都变得有区分能力,从而使SPQ框架能够实现高检索精度。
为了证明我们的方案的有效性,我们在不同的训练条件下进行了实验。具体地说,与以前利用从大型标记数据集学习的预训练模型权重的方法不同,我们在排除人类监督的“真正”无监督环境下进行实验。尽管没有标签信息,SPQ仍实现了最先进的性能。
本文的贡献总结如下:
- SPQ是第一个基于深度无监督量化的图像检索方案,其中特征提取和量化都包含在单个框架中,并以自监督的方式进行训练。
- 通过引入交叉量化对比学习策略,从两个不同的角度联合学习深度描述符和PQ码字,提供区分性表示以获得较高的检索分数。
- 在快速图像检索数据集上进行的大量实验验证,即使在真正无监督的设置下,SPQ也显示出最先进的检索性能。
2.相关工作
本节根据是否使用深度学习(传统方法与深度方法)对图像检索算法进行分类,并简要说明这些方法。有关更全面的理解,请参阅调查文件[42]。
常规方法。快速图像检索最常用的策略之一是Hashing散列。例如,局部敏感散列(LSH)[7]使用随机线性投影进行散列。光谱散列(SH)[43]和离散图散列(DGH)[32]利用基于图的方法来保持原始特征空间的数据相似性。K-均值散列(KMH)[17]和迭代量化(ITQ)[15]专注于最小化将原始特征映射到离散二进制码时出现的量化误差。
另一种快速图像检索策略是矢量量化VQ。有乘积量化(PQ)[23]及其改进的变体;Optimized PQ(OPQ)[13]、局部优化PQ(LOPQ)[24]以及使用不同量化器的方法,如加法量化器[2]、复合量化器[48]、树量化器[3]和稀疏复合量化器[49]。我们的SPQ属于PQ家族,其中深层特征数据空间被划分为几个不相交的子空间。然后使用我们提出的损失函数对分割的深子向量进行训练,以找到最优码字。
深度学习方法。基于监督深度卷积神经网络(CNN)的哈希方法[44,5,22,29,47]在许多图像检索任务中表现出优异的性能。还有一些基于量化的深度图像检索方法[4,26],它们使用预训练的CNN,并对网络进行微调,以共同训练鲁棒的码字。为了改进,在[46,31,21]中应用了度量学习方案来学习码字和深度表示以及成对语义相似度。需要注意的是,本文利用一种度量学习,即对比学习,这种方法在学习码字时不需要标签信息。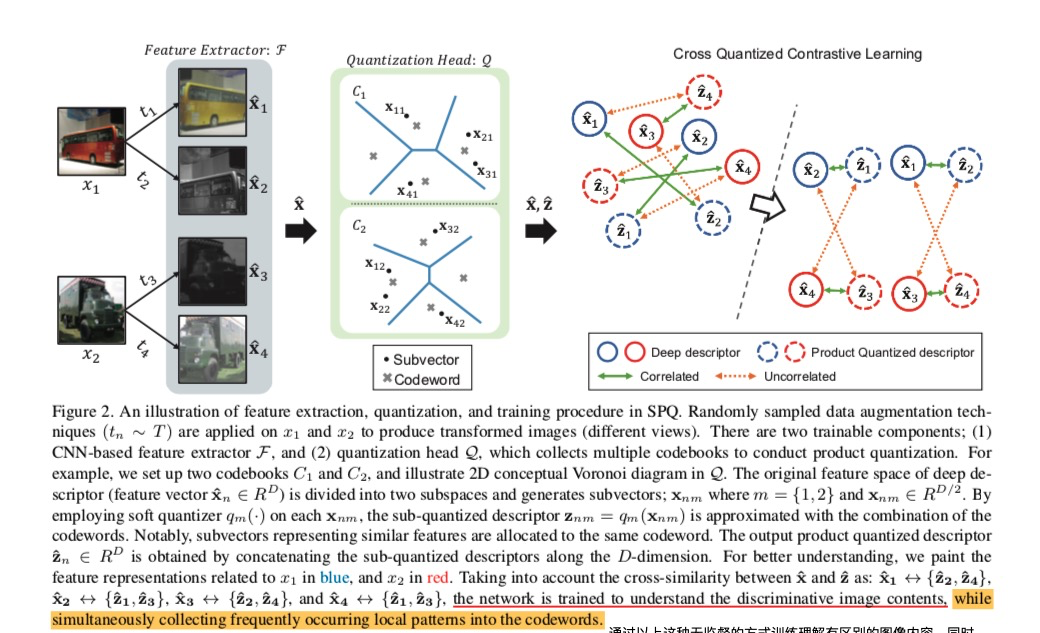 图2。SPQ中特征提取、量化和训练过程的说明。随机抽样数据增强技术
图2。SPQ中特征提取、量化和训练过程的说明。随机抽样数据增强技术![[SPQ]Self-supervised Product Quantization - 图11](/uploads/projects/xhades@dnhkkp/e65f8ff863b6b0e10d711462342ac8e5.svg) 应用于
应用于![[SPQ]Self-supervised Product Quantization - 图12](/uploads/projects/xhades@dnhkkp/c722dfe09bcfcd856e7f0bfb5978849e.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图13](/uploads/projects/xhades@dnhkkp/ae5585f672dac4897f659bb429aea529.svg) 以生成变换的图像(不同视图)。这个框架有两个可训练的部分;(1)基于CNN的特征提取器
以生成变换的图像(不同视图)。这个框架有两个可训练的部分;(1)基于CNN的特征提取器![[SPQ]Self-supervised Product Quantization - 图14](/uploads/projects/xhades@dnhkkp/d6c9752dca3b66d07af322de835f92ed.svg) 和(2)量化头
和(2)量化头![[SPQ]Self-supervised Product Quantization - 图15](/uploads/projects/xhades@dnhkkp/fd617c122c09d9f0b719de206345f78f.svg) ,其收集多个码本以进行乘积量化。例如,我们建立了两个码本
,其收集多个码本以进行乘积量化。例如,我们建立了两个码本![[SPQ]Self-supervised Product Quantization - 图16](/uploads/projects/xhades@dnhkkp/57444f4b13f57ddcfcc930f9bb9082cc.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图17](/uploads/projects/xhades@dnhkkp/8739b285ffb58080d77c46cd4c256848.svg) ,并在
,并在![[SPQ]Self-supervised Product Quantization - 图18](/uploads/projects/xhades@dnhkkp/07fa5250bf76ab0b4e9670313ad8d370.svg) 中说明了2D维诺图(指离某一物体最近的点的集合)。深度描述符(特征向量的原始特征空间
中说明了2D维诺图(指离某一物体最近的点的集合)。深度描述符(特征向量的原始特征空间![[SPQ]Self-supervised Product Quantization - 图19](/uploads/projects/xhades@dnhkkp/50d4736351a5978556399c90a4895470.svg) )被划分为两个子空间并生成子向量;
)被划分为两个子空间并生成子向量;
其中![[SPQ]Self-supervised Product Quantization - 图20](data:image/svg+xml;utf8,%3Csvg%20xmlns%3Axlink%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxlink%22%20width%3D%224.448ex%22%20height%3D%222.343ex%22%20style%3D%22vertical-align%3A%20-1.005ex%3B%22%20viewBox%3D%220%20-576.1%201915.2%201008.6%22%20role%3D%22img%22%20focusable%3D%22false%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20aria-labelledby%3D%22MathJax-SVG-1-Title%22%3E%0A%3Ctitle%20id%3D%22MathJax-SVG-1-Title%22%3Ex_%7Bn%2Cm%7D%3C%2Ftitle%3E%0A%3Cdefs%20aria-hidden%3D%22true%22%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-78%22%20d%3D%22M52%20289Q59%20331%20106%20386T222%20442Q257%20442%20286%20424T329%20379Q371%20442%20430%20442Q467%20442%20494%20420T522%20361Q522%20332%20508%20314T481%20292T458%20288Q439%20288%20427%20299T415%20328Q415%20374%20465%20391Q454%20404%20425%20404Q412%20404%20406%20402Q368%20386%20350%20336Q290%20115%20290%2078Q290%2050%20306%2038T341%2026Q378%2026%20414%2059T463%20140Q466%20150%20469%20151T485%20153H489Q504%20153%20504%20145Q504%20144%20502%20134Q486%2077%20440%2033T333%20-11Q263%20-11%20227%2052Q186%20-10%20133%20-10H127Q78%20-10%2057%2016T35%2071Q35%20103%2054%20123T99%20143Q142%20143%20142%20101Q142%2081%20130%2066T107%2046T94%2041L91%2040Q91%2039%2097%2036T113%2029T132%2026Q168%2026%20194%2071Q203%2087%20217%20139T245%20247T261%20313Q266%20340%20266%20352Q266%20380%20251%20392T217%20404Q177%20404%20142%20372T93%20290Q91%20281%2088%20280T72%20278H58Q52%20284%2052%20289Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-6E%22%20d%3D%22M21%20287Q22%20293%2024%20303T36%20341T56%20388T89%20425T135%20442Q171%20442%20195%20424T225%20390T231%20369Q231%20367%20232%20367L243%20378Q304%20442%20382%20442Q436%20442%20469%20415T503%20336T465%20179T427%2052Q427%2026%20444%2026Q450%2026%20453%2027Q482%2032%20505%2065T540%20145Q542%20153%20560%20153Q580%20153%20580%20145Q580%20144%20576%20130Q568%20101%20554%2073T508%2017T439%20-10Q392%20-10%20371%2017T350%2073Q350%2092%20386%20193T423%20345Q423%20404%20379%20404H374Q288%20404%20229%20303L222%20291L189%20157Q156%2026%20151%2016Q138%20-11%20108%20-11Q95%20-11%2087%20-5T76%207T74%2017Q74%2030%20112%20180T152%20343Q153%20348%20153%20366Q153%20405%20129%20405Q91%20405%2066%20305Q60%20285%2060%20284Q58%20278%2041%20278H27Q21%20284%2021%20287Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMAIN-2C%22%20d%3D%22M78%2035T78%2060T94%20103T137%20121Q165%20121%20187%2096T210%208Q210%20-27%20201%20-60T180%20-117T154%20-158T130%20-185T117%20-194Q113%20-194%20104%20-185T95%20-172Q95%20-168%20106%20-156T131%20-126T157%20-76T173%20-3V9L172%208Q170%207%20167%206T161%203T152%201T140%200Q113%200%2096%2017Z%22%3E%3C%2Fpath%3E%0A%3Cpath%20stroke-width%3D%221%22%20id%3D%22E1-MJMATHI-6D%22%20d%3D%22M21%20287Q22%20293%2024%20303T36%20341T56%20388T88%20425T132%20442T175%20435T205%20417T221%20395T229%20376L231%20369Q231%20367%20232%20367L243%20378Q303%20442%20384%20442Q401%20442%20415%20440T441%20433T460%20423T475%20411T485%20398T493%20385T497%20373T500%20364T502%20357L510%20367Q573%20442%20659%20442Q713%20442%20746%20415T780%20336Q780%20285%20742%20178T704%2050Q705%2036%20709%2031T724%2026Q752%2026%20776%2056T815%20138Q818%20149%20821%20151T837%20153Q857%20153%20857%20145Q857%20144%20853%20130Q845%20101%20831%2073T785%2017T716%20-10Q669%20-10%20648%2017T627%2073Q627%2092%20663%20193T700%20345Q700%20404%20656%20404H651Q565%20404%20506%20303L499%20291L466%20157Q433%2026%20428%2016Q415%20-11%20385%20-11Q372%20-11%20364%20-4T353%208T350%2018Q350%2029%20384%20161L420%20307Q423%20322%20423%20345Q423%20404%20379%20404H374Q288%20404%20229%20303L222%20291L189%20157Q156%2026%20151%2016Q138%20-11%20108%20-11Q95%20-11%2087%20-5T76%207T74%2017Q74%2030%20112%20181Q151%20335%20151%20342Q154%20357%20154%20369Q154%20405%20129%20405Q107%20405%2092%20377T69%20316T57%20280Q55%20278%2041%20278H27Q21%20284%2021%20287Z%22%3E%3C%2Fpath%3E%0A%3C%2Fdefs%3E%0A%3Cg%20stroke%3D%22currentColor%22%20fill%3D%22currentColor%22%20stroke-width%3D%220%22%20transform%3D%22matrix(1%200%200%20-1%200%200) %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(572%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%22600%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%22879%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=x%7Bn%2Cm%7D&id=gJVZx)中
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(572%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%22600%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%22879%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=x%7Bn%2Cm%7D&id=gJVZx)中![[SPQ]Self-supervised Product Quantization - 图21](/uploads/projects/xhades@dnhkkp/84dd29c64775dd9734e368919e5b0cfd.svg) ,。通过在每一个%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(572%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%22600%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%22879%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=x%7Bn%2Cm%7D&id=PTL0a)上采用软量化器,子量化描述符
,。通过在每一个%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-78%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(572%2C-150)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6E%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%22600%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6D%22%20x%3D%22879%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=x%7Bn%2Cm%7D&id=PTL0a)上采用软量化器,子量化描述符![[SPQ]Self-supervised Product Quantization - 图23](/uploads/projects/xhades@dnhkkp/03aa4a70950a34e107d1f9d55c99c27c.svg) 用码字的组合来近似。值得注意的是,代表相似特征的子向量被分配给相同的码字。输出的乘积量化描述符
用码字的组合来近似。值得注意的是,代表相似特征的子向量被分配给相同的码字。输出的乘积量化描述符![[SPQ]Self-supervised Product Quantization - 图24](/uploads/projects/xhades@dnhkkp/fa9ef39de8523ededcedb988019dd898.svg) 是通过沿着
是通过沿着![[SPQ]Self-supervised Product Quantization - 图25](/uploads/projects/xhades@dnhkkp/d163c0152526052795707d6974b140b2.svg) 维连接子量化描述符获得的。为了更好地理解,我们用蓝色表示
维连接子量化描述符获得的。为了更好地理解,我们用蓝色表示![[SPQ]Self-supervised Product Quantization - 图26](/uploads/projects/xhades@dnhkkp/ce2dbbfde7f88cc91bb6b27d2c3f4342.svg) 特征,用红色表征
特征,用红色表征![[SPQ]Self-supervised Product Quantization - 图27](/uploads/projects/xhades@dnhkkp/2f1f3938a4fc169924a0a71c6aa7d9ab.svg) 特征。考虑到
特征。考虑到![[SPQ]Self-supervised Product Quantization - 图28](/uploads/projects/xhades@dnhkkp/e08e84926cd90b2636103229d2ef730d.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图29](/uploads/projects/xhades@dnhkkp/bc0998e58a8bc136d214dac8eb5eadbd.svg) 之间的交叉相似性:
之间的交叉相似性:![[SPQ]Self-supervised Product Quantization - 图30](/uploads/projects/xhades@dnhkkp/6f6610cd4a767b8343826d6eea281989.svg) ,对网络进行训练以理解有区别的图像内容,同时将频繁出现的局部模式收集到码字codewords中。
,对网络进行训练以理解有区别的图像内容,同时将频繁出现的局部模式收集到码字codewords中。
关于无监督的深度图像检索,大多数工作都是基于哈希的。具体而言,[11,39,50,14]中使用了生成机制,而[36,37]中使用了基于图形的技术。值得注意的是,DeepBit[30]与SPQ的概念相似,都是变换图像与原始图像之间的距离最小。然而,散列码表示有一个局限性,即仅利用简单的旋转变换。就深度量化而言,只有一项研究被称为无监督神经网络量化模型(UNQ)[35],它使用预先提取的视觉描述符,而不是使用图像本身来查找码字。
为了提高基于无监督深度PQ检索的图像描述符和码字的质量,我们使用特征提取器配置SPQ来探索整个图像信息。然后,我们以自监督的方式共同学习SPQ的每个组成部分。与[8,40,6]类似,数据集的完整知识通过一些变换得到了增强,如裁剪和调整大小、翻转、颜色失真和高斯模糊。通过交叉对比不同的增强图像,图像描述符和码字都变得具有辨别力,以获得较高的检索分数。
3.自监督乘积量化
3.1. 总体框架
图像检索模型的目标是学习映射![[SPQ]Self-supervised Product Quantization - 图31](/uploads/projects/xhades@dnhkkp/00340dff3d7683ba8053fd78fc923aa9.svg) ,其中
,其中![[SPQ]Self-supervised Product Quantization - 图32](/uploads/projects/xhades@dnhkkp/153d8923aa951ef79f057836298fde91.svg) 表示整个系统,
表示整个系统,![[SPQ]Self-supervised Product Quantization - 图33](/uploads/projects/xhades@dnhkkp/36b80a4f572baddeca2867aaa0a82ced.svg) 是包含在数据集
是包含在数据集![[SPQ]Self-supervised Product Quantization - 图34](/uploads/projects/xhades@dnhkkp/5219e435a0cceec951710ad88016e4b2.svg) 中的一张图像,
中的一张图像,![[SPQ]Self-supervised Product Quantization - 图35](/uploads/projects/xhades@dnhkkp/c97da14b8623207dfa8b735df9270cad.svg) 是一个B位二进制代码
是一个B位二进制代码![[SPQ]Self-supervised Product Quantization - 图36](/uploads/projects/xhades@dnhkkp/765bf4f9cc2ae31342e29dd10d21b755.svg) 。如图2所示,SPQ的
。如图2所示,SPQ的![[SPQ]Self-supervised Product Quantization - 图37](/uploads/projects/xhades@dnhkkp/4f969c99c6dbeabfd8511b50038cc0d2.svg) 包含一个基于深度CNN的特征提取器
包含一个基于深度CNN的特征提取器![[SPQ]Self-supervised Product Quantization - 图38](/uploads/projects/xhades@dnhkkp/e773340221b22a385b4bb7d23b1382f1.svg) ,它输出一个稠密的深度描述符(特征向量)
,它输出一个稠密的深度描述符(特征向量)![[SPQ]Self-supervised Product Quantization - 图39](/uploads/projects/xhades@dnhkkp/8b31bcbed7c6c860cc7e346c960cbaeb.svg) 。任何CNN架构都可以用作特征提取器,只要它能够处理完全连接的层,例如AlexNet[28]、VGG[38]或ResNet[18]。我们使用ResNet50配置基线网络体系结构,ResNet50通常在图像表示学习方面表现出色,详情见第4.2节。
。任何CNN架构都可以用作特征提取器,只要它能够处理完全连接的层,例如AlexNet[28]、VGG[38]或ResNet[18]。我们使用ResNet50配置基线网络体系结构,ResNet50通常在图像表示学习方面表现出色,详情见第4.2节。
关于用于快速图像检索的量化,R在{C1,…,CM}的量化头Q(xˆ;θQ)中使用码本⊂ Q、其中包含代码字∈ RD/mas={cm1,…,cmK}。通过将深度特征空间划分为多个子空间的笛卡尔积,在Q中进行PQ。对应子空间的每个码本都表现出代表图像数据集X的几个显著特征。属于该码本的每个码字都推断出一个划分的深描述符的聚集形心,其目的是保持经常出现的局部模式。在量化期间,图像之间的相似属性通过分配给相同的码字而共享,而可区分的特征具有不同的码字。结果,实现了用于高效图像检索的各种距离表示。
3.2 自监督训练
为了更好地理解,我们简要描述了算法1中SPQ的训练方案,其中![[SPQ]Self-supervised Product Quantization - 图40](/uploads/projects/xhades@dnhkkp/dae44757bf3c136b8df36001650d64f0.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图41](/uploads/projects/xhades@dnhkkp/dcb47949c51b73efb99a2d3f2c3f1eac.svg) 分别表示特征提取器和量化头的可训练参数,
分别表示特征提取器和量化头的可训练参数,![[SPQ]Self-supervised Product Quantization - 图42](/uploads/projects/xhades@dnhkkp/c7ed3f070bc9639fcc01bbcfe3313788.svg) 是一个学习率。在本例中,
是一个学习率。在本例中,![[SPQ]Self-supervised Product Quantization - 图43](/uploads/projects/xhades@dnhkkp/77a65287152396b143d548c5c8b3075d.svg) 表示码本codebooks的集合。下面详细介绍了SPQ的训练方案和量化过程。
表示码本codebooks的集合。下面详细介绍了SPQ的训练方案和量化过程。
首先,为了以端到端的方式对![[SPQ]Self-supervised Product Quantization - 图44](/uploads/projects/xhades@dnhkkp/6678cd7cd7c4bc617c86965cd33cdf74.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图45](/uploads/projects/xhades@dnhkkp/7c50b4dd5bce5df383c69928a7bd3e71.svg) 进行深入学习,使整个码字有助于训练,我们需要解决硬赋值量化的不可导导计算问题。为此,按照[46]中的方法,我们使用软量化器
进行深入学习,使整个码字有助于训练,我们需要解决硬赋值量化的不可导导计算问题。为此,按照[46]中的方法,我们使用软量化器![[SPQ]Self-supervised Product Quantization - 图46](/uploads/projects/xhades@dnhkkp/8ae7b08aea75633522dd1a5f4a2c97e1.svg) 在量化头上引入软量化
在量化头上引入软量化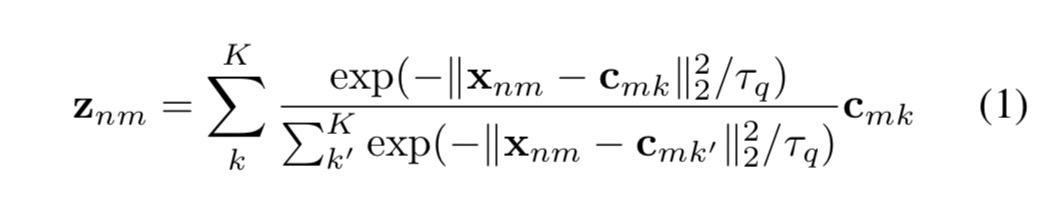
![[SPQ]Self-supervised Product Quantization - 图48](/uploads/projects/xhades@dnhkkp/41426f9937e29a60ea03cb25f5a9ed25.svg) 是一个非负参数,用于缩放softmax的输入,
是一个非负参数,用于缩放softmax的输入,![[SPQ]Self-supervised Product Quantization - 图49](/uploads/projects/xhades@dnhkkp/9c5f68bcc5fdacce2e4f64b00fdce4c6.svg) 表示用于度量输入之间相似性的平方欧氏距离。以这种方式,子量化描述符
表示用于度量输入之间相似性的平方欧氏距离。以这种方式,子量化描述符![[SPQ]Self-supervised Product Quantization - 图50](/uploads/projects/xhades@dnhkkp/fbc7e85baf3cb11364108fb70399a4a5.svg) 可被视为所属码字的指数加权和。请注意,码本中的整个码字用于近似量化输出,其中最仅的码字word贡献最大。
可被视为所属码字的指数加权和。请注意,码本中的整个码字用于近似量化输出,其中最仅的码字word贡献最大。
此外,与以前的深度PQ方法[46,21]不同,我们排除了间内归一化[1],用来在连接次量化描述符以获得整个乘积量化描述符![[SPQ]Self-supervised Product Quantization - 图51](/uploads/projects/xhades@dnhkkp/9f494934f251995a78e9d80466667878.svg) 时,可以最小化突发性视觉特征的影响。由于我们的SPQ是在没有标签监督的情况下训练的,这有助于发现不同的具有区分度的特征,因此我们专注于捕捉主要的视觉特征,而不是平衡每个码本codebook的影响。
时,可以最小化突发性视觉特征的影响。由于我们的SPQ是在没有标签监督的情况下训练的,这有助于发现不同的具有区分度的特征,因此我们专注于捕捉主要的视觉特征,而不是平衡每个码本codebook的影响。
为了同时学习深层描述符和码字,我们提出了交叉量化对比学习方案。受对比学习[8,40,6]的启发,我们试图比较各种视图(转换图像)的深度描述符和乘积量化描述符。如图2所示,如果视图来自同一个图像,则深度描述符和乘积量化描述符被视为相关,而如果视图来自不同的图像,则不相关。重点,为了增加码字的泛化能力,将忽略深度描述符和自身的量化描述符(和)之间的相关性。这是因为当子向量和最近的码字之间的一致性最大化时,其他码字的贡献减小。
对于给定的mini-batch ![[SPQ]Self-supervised Product Quantization - 图52](/uploads/projects/xhades@dnhkkp/64b4f558a77cf16dbe2470eeb1b9cac6.svg) ,我们从数据库
,我们从数据库![[SPQ]Self-supervised Product Quantization - 图53](/uploads/projects/xhades@dnhkkp/1b3b27c542e157b6e98a3a72615efb69.svg) 中随机抽取
中随机抽取![[SPQ]Self-supervised Product Quantization - 图54](/uploads/projects/xhades@dnhkkp/3110a5297f3b339aeca661d459a20241.svg) 个样本,并对每个图像应用随机增强技术组合两次,以生成
个样本,并对每个图像应用随机增强技术组合两次,以生成![[SPQ]Self-supervised Product Quantization - 图55](/uploads/projects/xhades@dnhkkp/4cd63df33eedb7fc33f28f7f7ee64e66.svg) 数据点(视图)。受[9,8,6]的启发,我们考虑到同一图像的两个独立视图
数据点(视图)。受[9,8,6]的启发,我们考虑到同一图像的两个独立视图![[SPQ]Self-supervised Product Quantization - 图56](/uploads/projects/xhades@dnhkkp/4b51c61c52ae8454cbd7a0c18b13bae0.svg) 相互关联,另外
相互关联,另外![[SPQ]Self-supervised Product Quantization - 图57](/uploads/projects/xhades@dnhkkp/ebd609fe306c3323768e7af00576e9d3.svg) 个来自小批量中不同图像的视图是不相关的。基于这一假设,我们设计了一个交叉量化对比损失函数来学习相关示例对
个来自小批量中不同图像的视图是不相关的。基于这一假设,我们设计了一个交叉量化对比损失函数来学习相关示例对![[SPQ]Self-supervised Product Quantization - 图58](/uploads/projects/xhades@dnhkkp/18f53e49cf690ff1995f3a38640dd213.svg) ,如下所示:
,如下所示: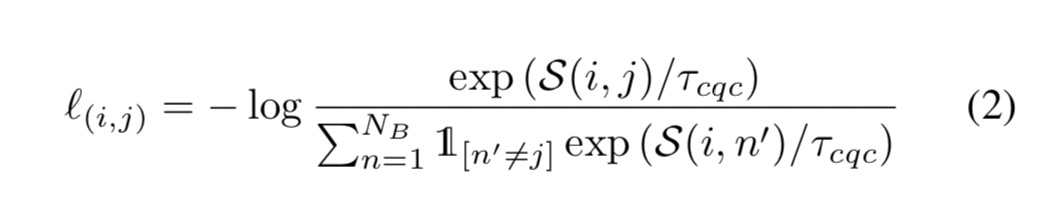
其中,![[SPQ]Self-supervised Product Quantization - 图60](/uploads/projects/xhades@dnhkkp/24a94ed43ebb684f5f37654bfb2950da.svg) ,
,![[SPQ]Self-supervised Product Quantization - 图61](/uploads/projects/xhades@dnhkkp/2c5b4b41d1df036c63c9cafcf7c1970c.svg) 表示
表示![[SPQ]Self-supervised Product Quantization - 图62](/uploads/projects/xhades@dnhkkp/bac2674fd7845cabb5ba99991a119e04.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图63](/uploads/projects/xhades@dnhkkp/f025240c69e7218d3d11f03c531fa394.svg) 之间的cosine相似度,
之间的cosine相似度,![[SPQ]Self-supervised Product Quantization - 图64](/uploads/projects/xhades@dnhkkp/0a5b5d3500e636bdebdb2706ff62fe8b.svg) 是一个非负数参数,
是一个非负数参数,
SQP主要算法
关于生成各种视图的数据增强,我们采用了五种流行技术:
(1)调整裁剪大小以处理局部、全局和相邻视图,
(2)水平翻转以处理镜像输入,
(3)颜色抖动以处理颜色扭曲,
(4)灰度以更关注强度,
(5)高斯模糊处理图像中的噪声。默认设置直接取自[8],其中所有转换都以顺序方式随机应用(1-5)。例外的是,根据经验观察,我们将颜色抖动强度修改为0.5以适合SPQ。最后,SPQ能够通过以自我监督的方式对比不同的图像视图来解释图像中的内容。
3.3 检索
图像检索过程类似PQ[23]分两步执行。首先,使用数据集![[SPQ]Self-supervised Product Quantization - 图66](/uploads/projects/xhades@dnhkkp/84aa5a777ab4f90ceca168892786e4f4.svg) 图像库配置由二进制代码组成的检索数据库。通过使用
图像库配置由二进制代码组成的检索数据库。通过使用![[SPQ]Self-supervised Product Quantization - 图67](/uploads/projects/xhades@dnhkkp/4248a461b60aebe04d94d57940321e73.svg) 、 深度描述符
、 深度描述符![[SPQ]Self-supervised Product Quantization - 图68](/uploads/projects/xhades@dnhkkp/1ea68ac22aaad72f280179f048da9158.svg) 从
从![[SPQ]Self-supervised Product Quantization - 图69](/uploads/projects/xhades@dnhkkp/f47c6792845a1266825aeec9fefb9515.svg) 中获得并划分为
中获得并划分为![[SPQ]Self-supervised Product Quantization - 图70](/uploads/projects/xhades@dnhkkp/fc9e5acabdc118f3ac6c2488be3831f6.svg) 等长子向量,
等长子向量,![[SPQ]Self-supervised Product Quantization - 图71](/uploads/projects/xhades@dnhkkp/e4e6575ca1e4907b311dcba622124697.svg) 。
。
然后,每个子向量![[SPQ]Self-supervised Product Quantization - 图72](/uploads/projects/xhades@dnhkkp/84471fbceb1e7f3ed93fdde6433e7655.svg) 的最近的码字通过计算子向量和码本
的最近的码字通过计算子向量和码本![[SPQ]Self-supervised Product Quantization - 图73](/uploads/projects/xhades@dnhkkp/858443a86c7a9de5e7aafd98a53b52d0.svg) 中每个码字之间的平方欧氏距离来搜索得到。
中每个码字之间的平方欧氏距离来搜索得到。
然后,将最近码字![[SPQ]Self-supervised Product Quantization - 图74](/uploads/projects/xhades@dnhkkp/a3e117581b6c2313f0a756fdef6b27b9.svg) 的索引格式化建模为二进制代码以生成子二进制代码
的索引格式化建模为二进制代码以生成子二进制代码![[SPQ]Self-supervised Product Quantization - 图75](/uploads/projects/xhades@dnhkkp/48eaa36803fbb18b01b9c4611e3ef0a7.svg) 。最后,将所有子二进制码拼接以生成
。最后,将所有子二进制码拼接以生成![[SPQ]Self-supervised Product Quantization - 图76](/uploads/projects/xhades@dnhkkp/80707c026089f2146f2db7e14f3809bf.svg) 位二进制码
位二进制码![[SPQ]Self-supervised Product Quantization - 图77](/uploads/projects/xhades@dnhkkp/16f5cc374f43f1182224b0b79d0a4e84.svg) ,其中
,其中![[SPQ]Self-supervised Product Quantization - 图78](/uploads/projects/xhades@dnhkkp/9ff9e5d3b856053adcd138567ca8b07a.svg) 。我们对所有图像仓库重复此过程,以构建二进制编码的检索数据库。
。我们对所有图像仓库重复此过程,以构建二进制编码的检索数据库。
进入检索阶段,我们对查询图像![[SPQ]Self-supervised Product Quantization - 图79](/uploads/projects/xhades@dnhkkp/b9226f08fb189b3eddcb0fb9a6809cde.svg) 应用相同的
应用相同的![[SPQ]Self-supervised Product Quantization - 图80](/uploads/projects/xhades@dnhkkp/80c2baf37893293186fe0c0f35a30bfe.svg) 和分割过程来提取出
和分割过程来提取出![[SPQ]Self-supervised Product Quantization - 图81](/uploads/projects/xhades@dnhkkp/60240617d22a97927bb2ddf2b9d2b030.svg) 和把它分割成子向量
和把它分割成子向量![[SPQ]Self-supervised Product Quantization - 图82](/uploads/projects/xhades@dnhkkp/07cc4ff52f05498ab82b9373b331c445.svg) 。利用欧几里德距离度量所有码本的子向量和每个码字之间的相似性,构造出一个预先计算的查找表。查询图和图库之间的距离计算是不对称的,通过这种方式来加速检索结果的计算。
。利用欧几里德距离度量所有码本的子向量和每个码字之间的相似性,构造出一个预先计算的查找表。查询图和图库之间的距离计算是不对称的,通过这种方式来加速检索结果的计算。
4.实验
4.1 数据集
为了评估SPQ的性能,我们在三个公共基准数据集上进行了综合实验,遵循最近无监督深度图像检索方法的实验方法[50,45,37]。
CIFAR-10[27]包含60000个图像,大小为32×32,共10个类别标签,每个类别有6000个图像。我们选择每个类5000个图像作为训练集,每个类100个图像作为查询集。整个50000张图像的训练集用于建立检索数据库。
FLICKR25K[19]由25000张从Flickr网站收集的不同分辨率的图像组成。每个图像都使用24个语义标签中的至少一个进行手动标注。我们随机选取2000幅图像作为查询集,利用剩余的23000幅图像建立检索数据库,其中5000幅图像用于训练。
NUS-WIDE[10]在81个唯一标签中有近270000个不同分辨率的图像,其中每个图像属于一个或多个标签。我们挑选出包含21个最常见类别的图像,对总共169643个类别进行实验。我们随机选择10500张图像作为训练集,每个类别至少500张,2100张图像作为查询集,每个类别至少100张,其余图像作为检索数据库。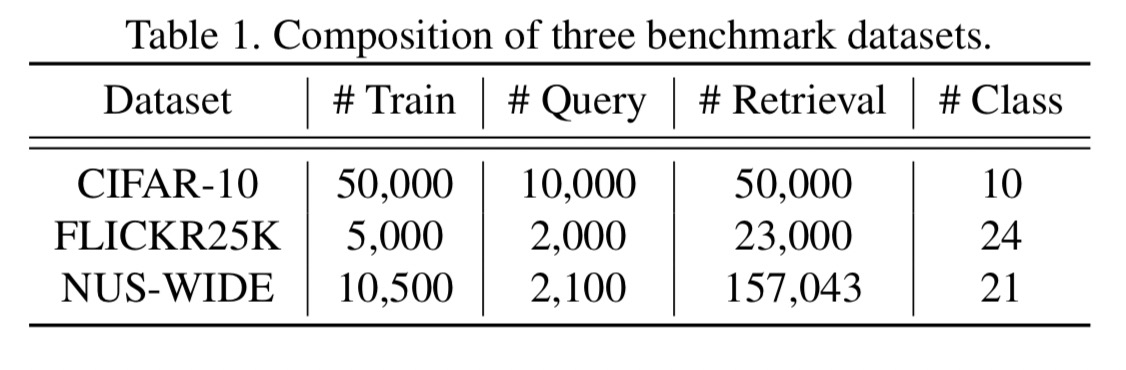
4.2 实验设置
评价指标。我们使用平均精度Average Precision(mAP)来评估检索性能。
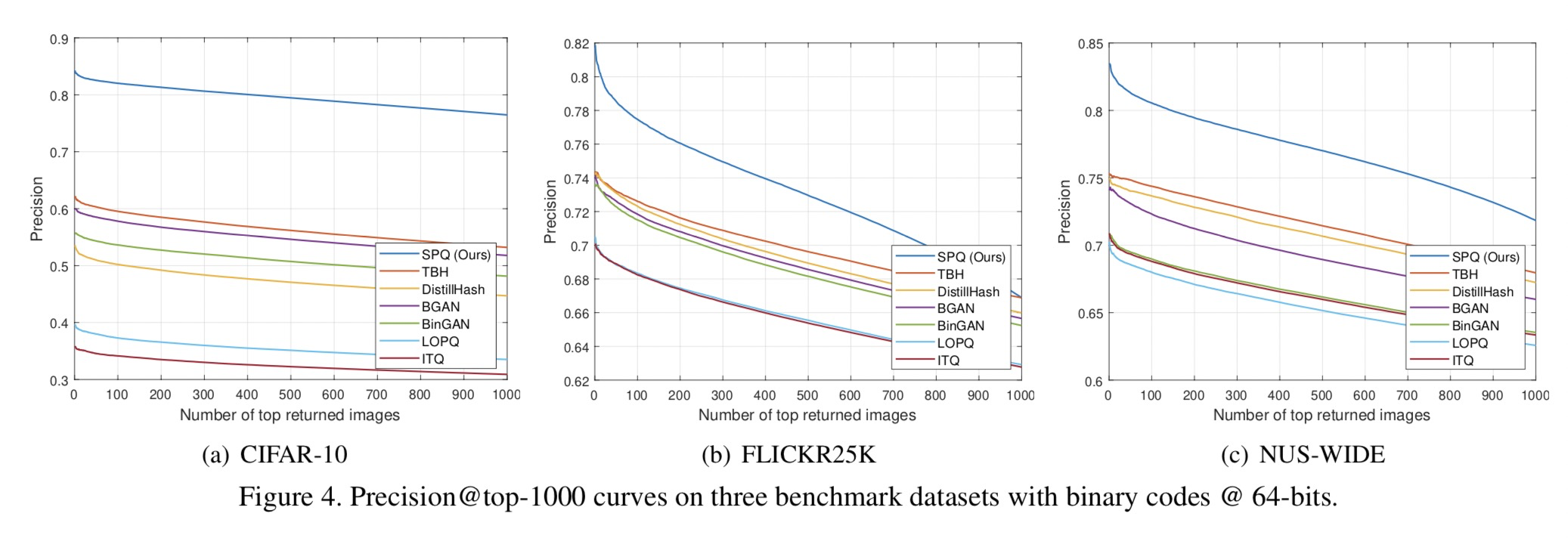
具体地说,在FLICKR25K和NUS-WIDE数据集上的多标签图像检索中,即使只有一个标签匹配,也会被认为是相关的。根据[37,45]中的评估方法,我们将分配给二进制代码的位数更改为{16,32,64},来测量检索方法的mAP分数,mAP@1000用于CIFAR-10数据集和mAP@5000,用于FLICKR25K和NUS范围的数据集。此外,通过使用不同算法的64位散列码,我们绘制了精度召回曲线(PR),以比较不同召回级别的精度,并报告1000个top返回样本的精度曲线(P@1,000)以对比正确检索的结果比率。
我们对三种基线方法进行分类以进行比较。具体而言,
(1)基于哈希的无深度学习的浅层方法:LSH[7],SH[43],ITQ[15],以及基于乘积量化的方法:PQ[23],OPQ[13]LOPQ[24],
(2)深度半无监督方法:DeepBit[30],GreedyHash[41],DVB[36],蒸馏哈希[45],TBH[37],
(3)深度真正无监督方法:SGH[11],HashGAN[14],BinGAN[50],BGAN[39]。“半”和“真实”表示是否使用预训练模型权重。办监督条件和真实训练条件均可应用于SPQ;然而,我们采用真正的无监督模型,该模型的优点是不需要人工监督。
为了评估浅层和深层半无监督方法,我们采用AlexNet[28]或VGG16[38]的ImageNet预训练模型权重,利用![[SPQ]Self-supervised Product Quantization - 图84](/uploads/projects/xhades@dnhkkp/c3f88c320e068ef2aeb51126bf7eac77.svg) 特征层,并遵循[45,36,37]的实验设置。由于这些模型只接受固定大小的输入,我们需要将所有图像的大小调整为224×224,使用的方法是对小图像进行放大,对大图像进行下采样。在评估深度真正无监督方法(包括SPQ),
特征层,并遵循[45,36,37]的实验设置。由于这些模型只接受固定大小的输入,我们需要将所有图像的大小调整为224×224,使用的方法是对小图像进行放大,对大图像进行下采样。在评估深度真正无监督方法(包括SPQ),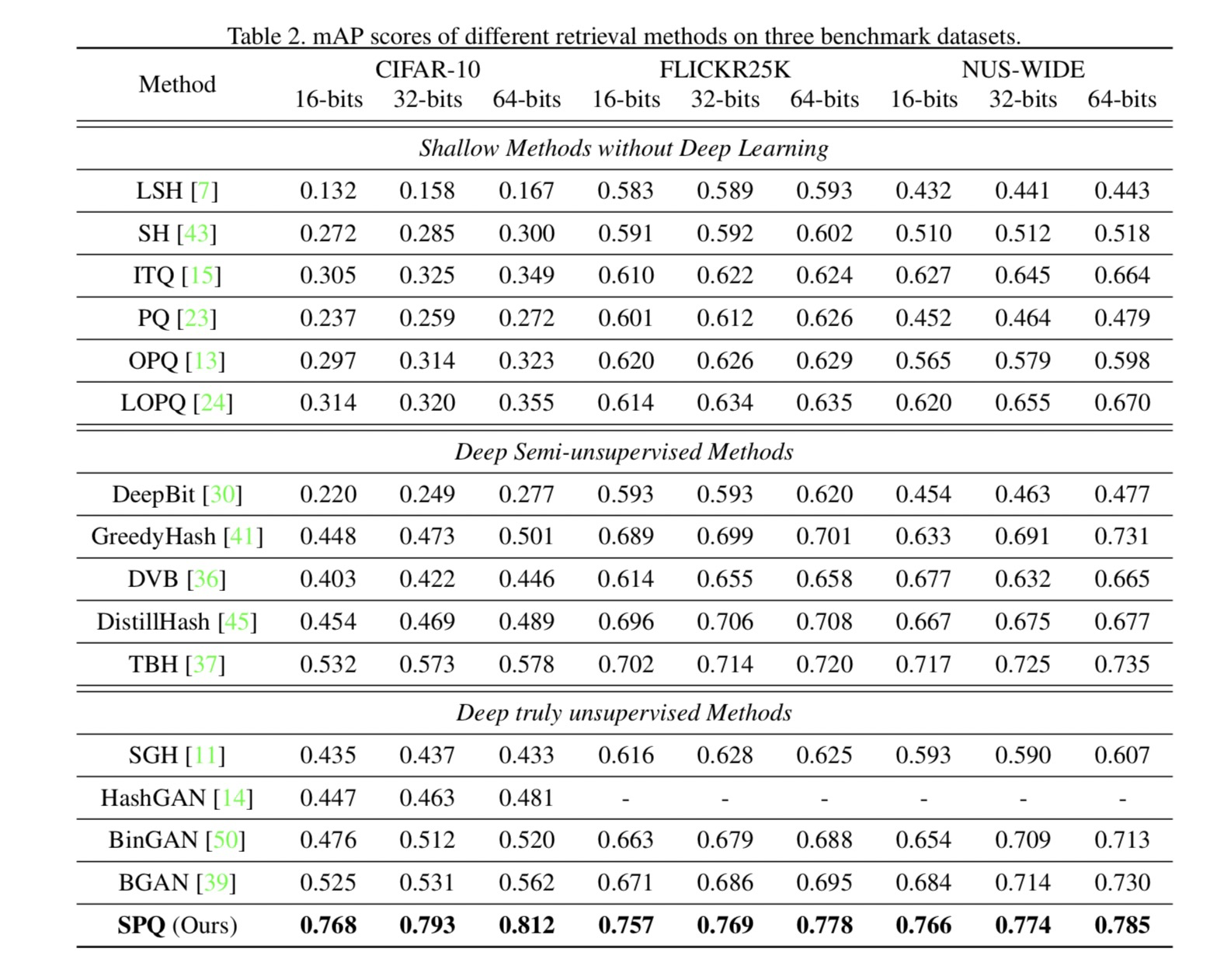
为了计算简单,为了简单起见,使用FLICKR25K和NUS-WIDE数据集的相同大小图像,并使用CIFAR-10的原始分辨率图像来减少计算压力。
SPQ实现基于Pytork和NVIDIA Tesla V100 32GB Tensor Core GPU。根据最近的自监督学习研究[8,6]中的观察结果,我们将基线网络架构设置为FLICKR25K和NUS范围数据集的标准ResNet50[18]。对于具有更小图像的CIFAR-10数据集,我们将基线设置为标准ResNet18[18],并将滤波器的数量修改为与ResNet50相同。
对于网络训练,我们采用Adam[25],使用余弦调度衰减学习率,而不需要重新启动[33],并将批量大小![[SPQ]Self-supervised Product Quantization - 图86](/uploads/projects/xhades@dnhkkp/f3979587db11ae3728be7b8a2ebb0ecc.svg) 设置为256。我们将子向量
设置为256。我们将子向量![[SPQ]Self-supervised Product Quantization - 图87](/uploads/projects/xhades@dnhkkp/675ba2cc93a46d9151328a37186d9537.svg) 和码字
和码字![[SPQ]Self-supervised Product Quantization - 图88](/uploads/projects/xhades@dnhkkp/c1a1a61735149082f63390ec125df475.svg) 的维数固定为
的维数固定为![[SPQ]Self-supervised Product Quantization - 图89](/uploads/projects/xhades@dnhkkp/4b7bf7eb0418d6a368f9a8c623b38c71.svg) ,将码字数固定为
,将码字数固定为![[SPQ]Self-supervised Product Quantization - 图90](/uploads/projects/xhades@dnhkkp/ca1b5cfc314e7d91714800ba4bb114aa.svg) 。因此码本的数量
。因此码本的数量![[SPQ]Self-supervised Product Quantization - 图91](/uploads/projects/xhades@dnhkkp/356c222cf42dcbfe23b997b0be22e03a.svg) 需要设置成
需要设置成![[SPQ]Self-supervised Product Quantization - 图92](/uploads/projects/xhades@dnhkkp/3a769d738a8e291960e2b14395d096e2.svg) ,因为
,因为![[SPQ]Self-supervised Product Quantization - 图93](/uploads/projects/xhades@dnhkkp/5e152f5aca2af662d9c3db919052bbdf.svg) 位需要用来得到{16,32,64}位二进制码,参数
位需要用来得到{16,32,64}位二进制码,参数![[SPQ]Self-supervised Product Quantization - 图94](/uploads/projects/xhades@dnhkkp/2e1b6f35862b2cc34bef9b0ac4f41188.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图95](/uploads/projects/xhades@dnhkkp/7df4670fbb87da1d23d82fe8ab8287e4.svg) 分别设置为5和0.5。使用Kornia[12]库进行数据增强,每个转换的应用概率与[8]中的设置相同。
分别设置为5和0.5。使用Kornia[12]库进行数据增强,每个转换的应用概率与[8]中的设置相同。
4.3 结果
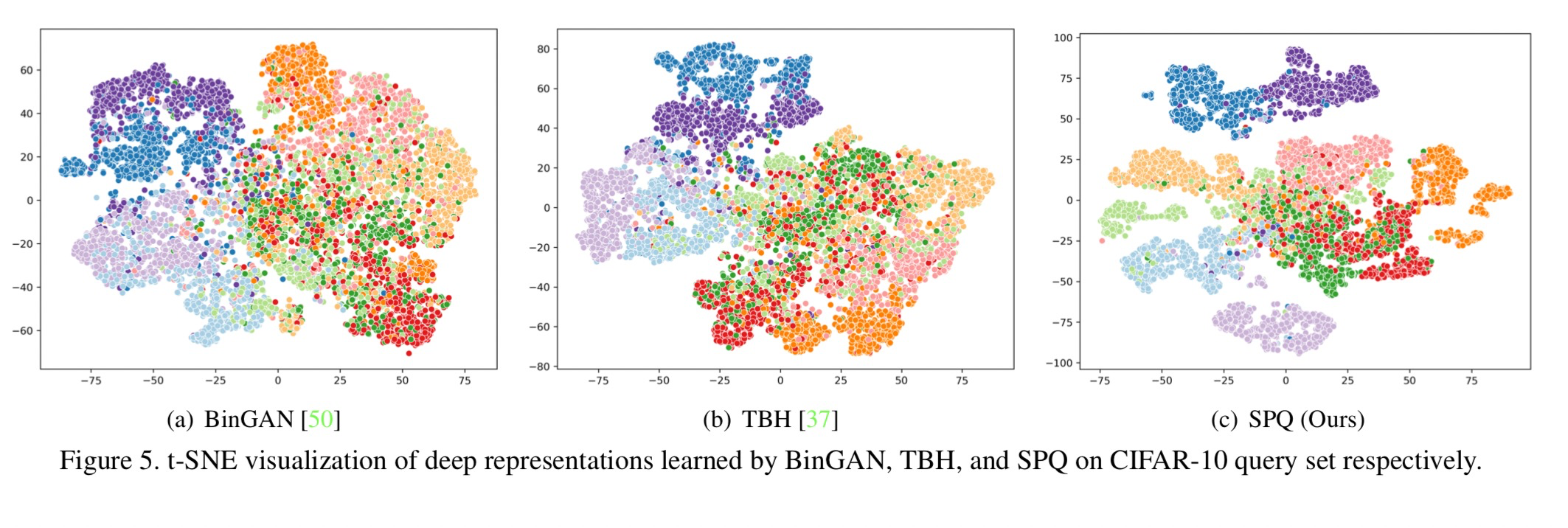
表2列出了三种不同图像检索数据集上的mAP结果,表明SPQ在每个比特长度上都明显优于所有比较方法。此外,参考图3和图4,SPQ被证明是最理想的检索系统。
首先,比较了最佳浅层法LOPQ[24],SPQ显示性能改善超过在CIFAR10、FLICKR25K和NUS-WIDE在平均检索精度mAP上,分别有46%、13%和11.6%的提升。CIFAR-10差异更显著的原因是,浅层方法涉及不必要的放大过程,以利用ImageNet预训练的深部特征。与浅层方法相比,SPQ的优势在于可以适应各种合适的神经结构,用于特征提取和端到端学习。
其次,与最佳深度半无监督方法TBH[37]相比,SPQ在CIFAR-10、FLICKR25K和NUS-WIDE上的平均mAP分数分别高出23%、4.6%和3.9%。即使在没有预先训练的模型权重等先验信息的情况下,SPQ也能通过比较训练样本的多个视图来很好地区分图像中的内容。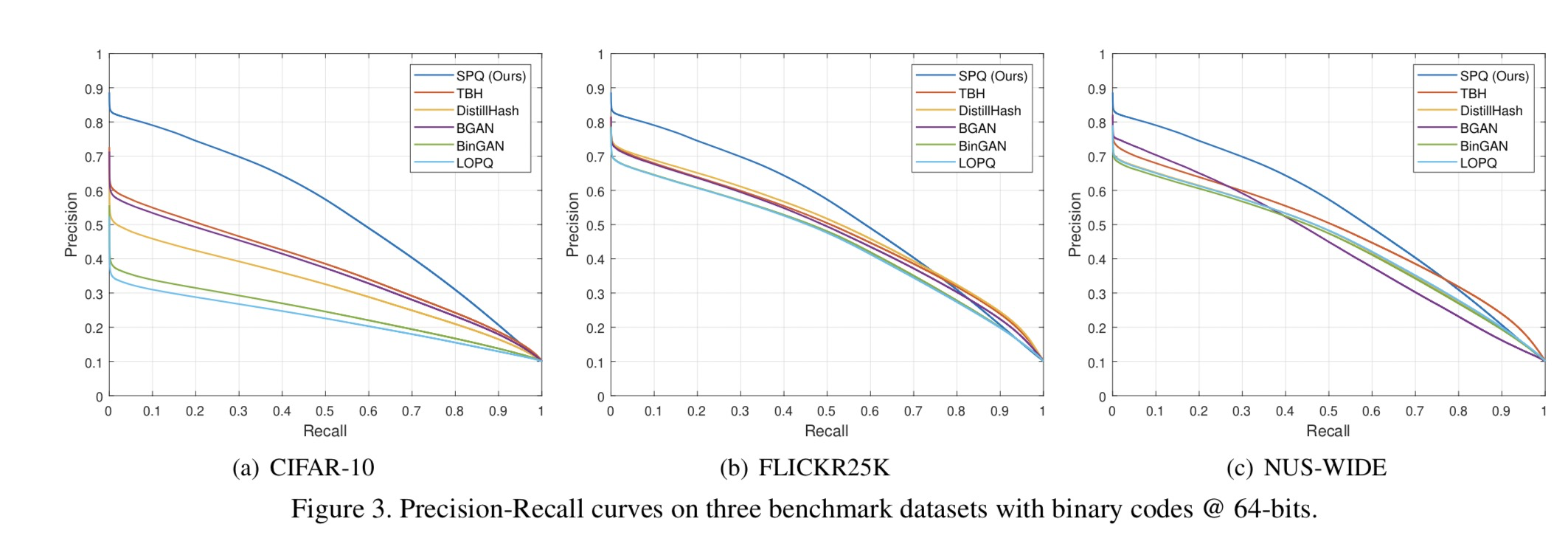
最后,即使使用真正的无监督设置,SPQ也能达到最先进的检索精度。具体来说,与以前基于散列的真正无监督方法不同,SPQ首次将可微乘积量化引入无监督图像检索系统。通过以自监督的方式考虑不同视图之间的交叉相似性,允许深度描述符和码字具有区分性。
4.4 分析
4.4.1
我们配置了五种SPQ变量进行研究:
(1)SPQ-C,通过比较将交叉量化对比学习替换为对比学习;
(2)SPQ-H,采用硬量化代替软量化,
(3)SPQ-Q,采用标准矢量量化,它不划分特征空间,直接利用整个特征向量构建码本,
(4)SPQ-S,利用预训练模型权重进行深度半无监督图像检索的SPQ,以及
(5)SPQ-V,利用VGG16网络架构作为基线。
如表3所示,我们可以观察到,SPQ的每个组成部分都充分有助于性能改进。与SPQ-C的比较证实了可考虑的比较交叉相似性而不是比较量化输出可以提供更有效的图像检索结果。从SPQ-H的结果来看,软量化更适合于学习码字。SPQ-Q的检索结果显示了与SPQ最大的性能差距,这说明乘积量化通过增加距离表示量来实现精确的搜索结果。值得注意的是,SPQ-S利用ImageNet预训练模型权重进行网络初始化,其性能优于真正的无监督SPQ。在这个观察中,我们可以看到,虽然SPQ表现出最好的检索准确无需任何人工指导,利用一些标签信息可以获得更好的检索结果。虽然SPQ-V不如基于ResNet的SPQ,但其性能仍优于现有的最新检索算法,这证明了基于PQ的自监督学习方案的优越性。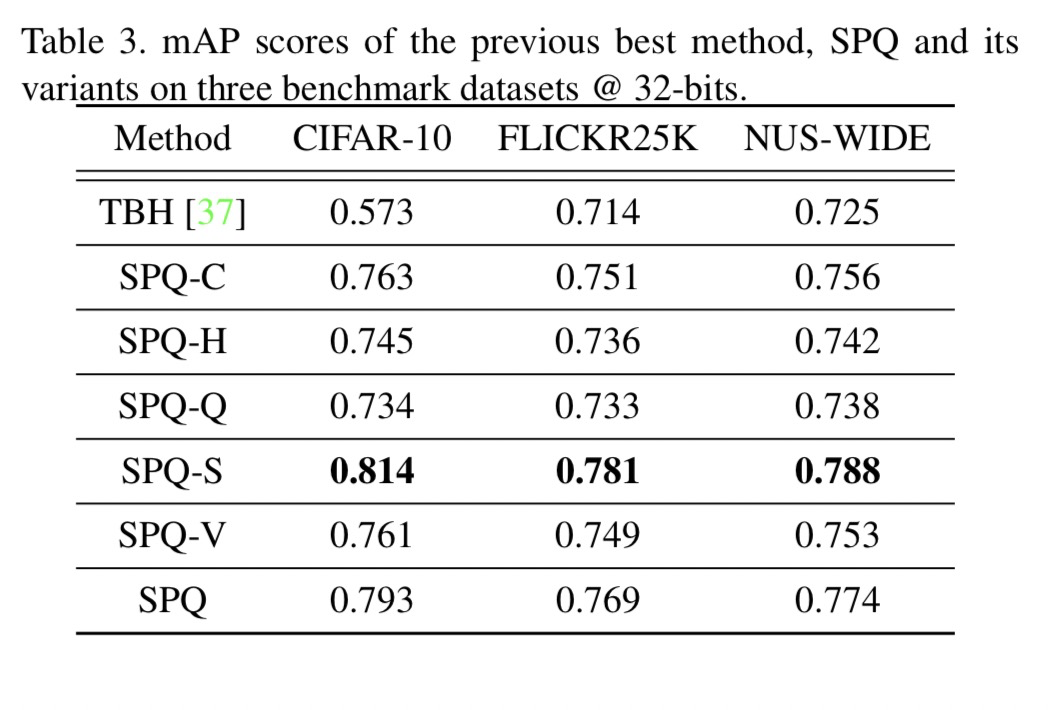
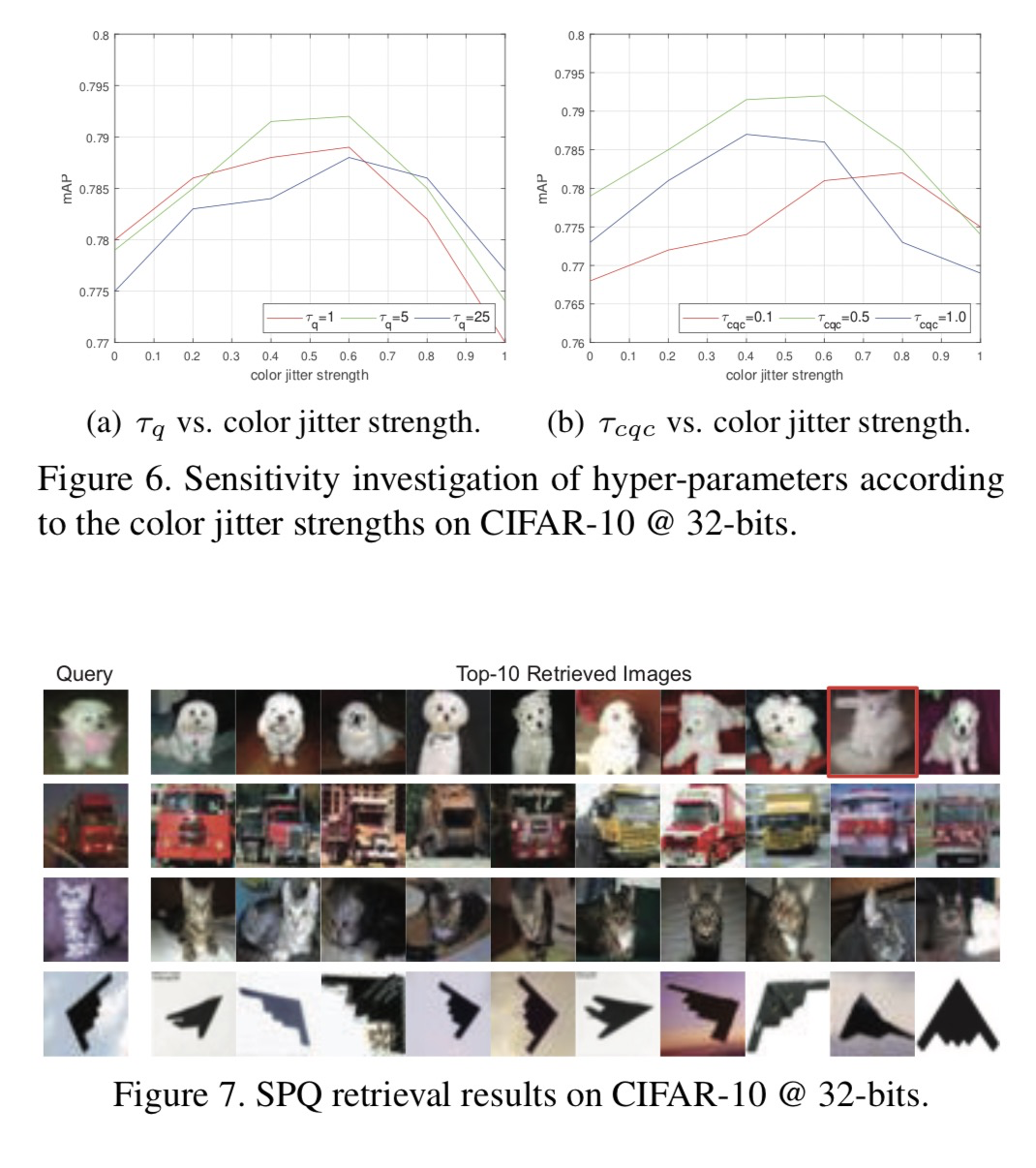
此外,我们根据图6中的颜色变化强度探索超参数(![[SPQ]Self-supervised Product Quantization - 图101](/uploads/projects/xhades@dnhkkp/5b0cf156c4c821146ca67919ef914546.svg) 和
和![[SPQ]Self-supervised Product Quantization - 图102](/uploads/projects/xhades@dnhkkp/d466d5c1193fb0b2c0da7af2807ce13e.svg) )灵敏度。一般来说,由于超参数的变化而导致的性能差异不显著;然而,颜色抖动强度的影响是显著的。因此,我们确认SPQ对超参数具有鲁棒性,输入数据准备是一个重要因素。
)灵敏度。一般来说,由于超参数的变化而导致的性能差异不显著;然而,颜色抖动强度的影响是显著的。因此,我们确认SPQ对超参数具有鲁棒性,输入数据准备是一个重要因素。
References
- [1] Relja Arandjelovic and Andrew Zisserman. All about vlad. In CVPR, pages 1578–1585, 2013. 4
- [2] ArtemBabenkoandVictorLempitsky.Additivequantization for extreme vector compression. In CVPR, pages 931–938, 2014. 1, 2
- [3] Artem Babenko and Victor Lempitsky. Tree quantization for large-scale similarity search and classification. In CVPR, pages 4240–4248, 2015. 1, 2
- [4] Yue Cao, Mingsheng Long, Jianmin Wang, Han Zhu, and Qingfu Wen. Deep quantization network for efficient image retrieval. In AAAI, 2016. 2
- [5] ZhangjieCao,MingshengLong,JianminWang,andPhilipS Yu. Hashnet: Deep learning to hash by continuation. In ICCV, pages 5608–5617, 2017. 2
- [6] MathildeCaron,IshanMisra,JulienMairal,PriyaGoyal,Pi- otr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. arXiv preprint arXiv:2006.09882, 2020. 2, 3, 4, 6
- [7] Moses S Charikar. Similarity estimation techniques from rounding algorithms. In STOC, pages 380–388, 2002. 1, 2, 5, 6
- [8] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. Arxiv, 2020. 2, 3, 4, 5, 6
- [9] Ting Chen, Yizhou Sun, Yue Shi, and Liangjie Hong. On sampling strategies for neural network-based collaborative filtering. In ACM SIGKDD, pages 767–776, 2017. 4
- [10] Tat-SengChua,JinhuiTang,RichangHong,HaojieLi,Zhip- ing Luo, and Yantao Zheng. Nus-wide: a real-world web im- age database from national university of singapore. In CIVR, page 48. ACM, 2009. 5
- [11] Bo Dai, Ruiqi Guo, Sanjiv Kumar, Niao He, and Le Song. Stochastic generative hashing. In ICML, 2017. 2, 3, 5, 6
- [12] et al. E. Riba. A survey on kornia: an open source differen- tiable computer vision library for pytorch. 2020. 6
- [13] Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. Opti- mized product quantization for approximate nearest neigh- bor search. In CVPR, pages 2946–2953, 2013. 1, 2, 5, 6
- [14] Kamran Ghasedi Dizaji, Feng Zheng, Najmeh Sadoughi, Yanhua Yang, Cheng Deng, and Heng Huang. Unsuper- vised deep generative adversarial hashing network. In CVPR, pages 3664–3673, 2018. 2, 3, 5, 6
- [15] Yunchao Gong, Svetlana Lazebnik, Albert Gordo, and Flo- rent Perronnin. Iterative quantization: A procrustean ap- proach to learning binary codes for large-scale image re- trieval. PAMI, 35(12):2916–2929, 2012. 1, 2, 5, 6
- [16] Robert M. Gray and David L. Neuhoff. Quantization. IEEE Transactions on Information Theory, 44(6):2325– 2383, 1998. 1
- [17] Kaiming He, Fang Wen, and Jian Sun. K-means hashing: An affinity-preserving quantization method for learning binary compact codes. In CVPR, pages 2938–2945, 2013. 1, 2
- [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016. 3, 6
- [19] Mark J Huiskes and Michael S Lew. The mir flickr retrieval evaluation. In ICMR, pages 39–43, 2008. 5
- [20] Himalaya Jain, Joaquin Zepeda, Patrick Pe ́rez, and Re ́mi Gribonval. Subic: A supervised, structured binary code for image search. In ICCV, pages 833–842, 2017. 2
- [21] Young Kyun Jang and Nam Ik Cho. Generalized product quantization network for semi-supervised image retrieval. In CVPR, 2020. 2, 4
- [22] Young Kyun Jang, Dong-ju Jeong, Seok Hee Lee, and Nam Ik Cho. Deep clustering and block hashing network for face image retrieval. In ACCV, pages 325–339. Springer, 2018. 2
- [23] HerveJegou,MatthijsDouze,andCordeliaSchmid.Product quantization for nearest neighbor search. PAMI, 33(1):117– 128, 2010. 1, 2, 5, 6
- [24] Yannis Kalantidis and Yannis Avrithis. Locally optimized product quantization for approximate nearest neigh- bor search. In CVPR, pages 2321–2328, 2014. 1, 2, 5, 6
- [25] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. 2015. 6
- [26] BenjaminKleinandLiorWolf.End-to-endsupervisedprod- uct quantization for image search and retrieval. In CVPR, pages 5041–5050, 2019. 2
- [27] Alex Krizhevsky et al. Learning multiple layers of features from tiny images. 2009. 5
- [28] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural net- works. In NeurIPS, pages 1097–1105, 2012. 3, 5
- [29] QiLi,ZhenanSun,RanHe,andTieniuTan.Deepsupervised discrete hashing. In NeurIPS, pages 2482–2491, 2017. 2
- [30] Kevin Lin, Jiwen Lu, Chu-Song Chen, and Jie Zhou. Learn- ing compact binary descriptors with unsupervised deep neu- ral networks. In CVPR, pages 1183–1192, 2016. 2, 3, 5, 6
- [31] Bin Liu, Yue Cao, Mingsheng Long, Jianmin Wang, and Jingdong Wang. Deep triplet quantization. ACMMM, 2018. 2
- [32] Wei Liu, Cun Mu, Sanjiv Kumar, and Shih-Fu Chang. Dis- crete graph hashing. In NeurIPS, pages 3419–3427, 2014. 1, 2
- [33] Ilya Loshchilov and Frank Hutter. Sgdr: Stochas- tic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016. 6
- [34] Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(Nov):2579–2605, 2008. 8
- [35] Stanislav Morozov and Artem Babenko. Unsupervised neu- ral quantization for compressed-domain similarity search. In ICCV, pages 3036–3045, 2019. 2, 3
- [36] Yuming Shen, Li Liu, and Ling Shao. Unsupervised bi- nary representation learning with deep variational networks. IJCV, 127(11-12):1614–1628, 2019. 2, 3, 5, 6
- [37] Yuming Shen, Jie Qin, Jiaxin Chen, Mengyang Yu, Li Liu, Fan Zhu, Fumin Shen, and Ling Shao. Auto-encoding twin- bottleneck hashing. In CVPR, pages 2818–2827, 2020. 2, 3, 5,6,7,8
- [38] Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition. ICLR, 2015. 3, 5
- [39] Jingkuan Song. Binary generative adversarial networks for image retrieval. In AAAI, 2017. 2, 3, 5, 6
- [40] Aravind Srinivas, Michael Laskin, and Pieter Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. arXiv preprint arXiv:2004.04136, 2020. 2, 3, 4
- [41] Shupeng Su, Chao Zhang, Kai Han, and Yonghong Tian. Greedy hash: Towards fast optimization for accurate hash coding in cnn. In NeurIPS, pages 798–807, 2018. 2, 5, 6
- [42] Jingdong Wang, Ting Zhang, Nicu Sebe, Heng Tao Shen, et al. A survey on learning to hash. PAMI, 40(4):769–790, 2017. 1, 2
- [43] Yair Weiss, Antonio Torralba, and Rob Fergus. Spectral hashing. In NeurIPS, pages 1753–1760, 2009. 1, 2, 5, 6
- [44] Rongkai Xia, Yan Pan, Hanjiang Lai, Cong Liu, and Shuicheng Yan. Supervised hashing for image retrieval via image representation learning. In AAAI, 2014. 2
- [45] Erkun Yang, Tongliang Liu, Cheng Deng, Wei Liu, and Dacheng Tao. Distillhash: Unsupervised deep hashing by distilling data pairs. In CVPR, pages 2946–2955, 2019. 2, 5, 6
- [46] Tan Yu, Jingjing Meng, Chen Fang, Hailin Jin, and Junsong Yuan. Product quantization network for fast visual search. IJCV, pages 1–19, 2020. 2, 4
- [47] Li Yuan, Tao Wang, Xiaopeng Zhang, Francis EH Tay, Ze- qun Jie, Wei Liu, and Jiashi Feng. Central similarity quan- tization for efficient image and video retrieval. In CVPR, pages 3083–3092, 2020. 2
- [48] TingZhang,ChaoDu,andJingdongWang.Compositequan- tization for approximate nearest neighbor search. In ICML, volume 2, page 3, 2014. 1, 2
- [49] Ting Zhang, Guo-Jun Qi, Jinhui Tang, and Jingdong Wang. Sparse composite quantization. In CVPR, pages 4548–4556, 2015. 1, 2
[50] Maciej Zieba, Piotr Semberecki, Tarek El-Gaaly, and Tomasz Trzcinski. Bingan: Learning compact binary de- scriptors with a regularized gan. In NeurIPS, pages 3608– 3618, 2018. 2, 3, 5, 6, 8
<br /> <br />
论文代码

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}