现阶段数据库架构梳理
1.1 数据库物理指标
- 阿里云 RDS MySQL 实例(一主一从)
- 主,8核 16GB。从,4核 600MB
- 主,支持峰值指标 IOPS 8000,连接数4000(业务高峰期实际使用峰值 IOPS 800,连接数 150,使用到峰值的 10%) 。从,支持IOPS 峰值 300,连接数 150。
- 存储空间 250GB(已使用 165GB)
上周RDS运行周报
| 数据库运行周报 | |||
|---|---|---|---|
| 1. 核心指标平均值统计 | |||
| 平均CPU使用率 | 平均IOPS | 平均TPS/QPS | |
| 20% | 80 | 20/600 | |
| 2. 核心指标峰值及对应运行时段统计 | |||
| IOPS峰值 | TPS 峰值 | CPU 使用率峰值 | QPS 峰值 |
| 800 | 190 | 36 | 1700 |
| IOPS 峰值时段 | TPS 峰值时段 | CPU 使用率峰值时段 | QPS 峰值时段 |
| 01:30-01:40 | 6:00-7:00 | 6:00-07:00 | 20:30-21:00 |
| 3. 数据库数据磁盘占有量 | |||
| 磁盘总使用量为 165GB,上周数据量含日志表增长10GB,单纯业务数据增长小于1GB | |||
| 4. 总结 | |||
| 数据库运行平稳,CPU 使用率正常,峰值时段为业务高峰期,使用率未达到中位值。 从数据上看,硬件配置现阶段可以满足业务需求。其他核心指标也表现正常。 从架构上看,数据库存在单点故障风险,考虑到云数据库故障较低,已经做了物理备份容灾。 数据库风险在于业务代码中的慢SQL,要加强力度优化业务慢日志。 制定MySQL开发规范,培养开发人员开发习惯,避免业务中含有多Join,业务严重依赖SQL计算等坏习惯 |
1.2 表维度重要指标
1.2.1 执行耗时占据前 50% 占比的SQL统计
| SQL | 平均耗时(ms) | 总耗时占比 | 总耗时(ms) | 总执行次数 | 总扫描行数 | 所属代码仓库 | 所属业务 | 执行次数占比 |
|---|---|---|---|---|---|---|---|---|
| select t.category_id, qe. from ( select dd.template_id, sum( real_score ) as complete_score from ( select distinct a., ? * a.score_weight as real_score from z_mmc_base_control a inner join z_mmc_question b on a.template_id = b.template_id and a.chapter_id = b.chapter_id and a.question_id = b.question_id and a.terminal_flg = b.terminal_flg where b.complete_flg = ? and a.complete_flg_v = ? and a.visit_level = ? and a.gender_flg in ( ?,? ) ) dd group by dd.template_id ) qe left join z_qss_template t on qe.template_id = t.id | 61.95 | 10.33% | 6947407.04 | 112.1K | 42.1M | common-api | MMC 完成度计算 | 0.10% |
| select z_hosp_member.id, z_hosp_member.name, z_t_dept.name as dept_name, z_doc_info.job_rank, z_doc_info.about, z_doc_info.photo,z_dept.id as dept_id, z_hosp_member.hosp_id, t_sum, t_count, if(t_sum is not null and (t_count is null or t_count < t_sum),?,?) as reservable from z_hosp_member left join z_doc_info on z_hosp_member.id=z_doc_info.hosp_member_id left join z_hosp_member_dept on z_hosp_member.id=z_hosp_member_dept.hosp_member_id left join (select sum(reservation_count) as t_sum, doc_id from z_hosp_schedule where hosp_id = ? and ((date > ?) or (date = ? and time_from > ?)) and date < ? group by doc_id) tmp_schedule_sum on tmp_schedule_sum.doc_id=z_hosp_member.id left join (select count(*) as t_count, doc_id from z_mmc_reservation where hosp_id = ? and ((reserve_date > ?) or (reserve_date = ? and time_from > ?)) and reserve_date < ? and status = ? and schedule_id <> ? group by doc_id) tmp_reservation_count on tmp_reservation_count.doc_id=z_hosp_member.id left join z_dept on z_dept.id = z_hosp_member_dept.dept_id left join z_t_dept on z_t_dept.id = z_dept.t_dept_id inner join z_mmc_hosp_center on z_hosp_member.hosp_id = z_mmc_hosp_center.hosp_id inner join z_mmc_doc_center on z_mmc_hosp_center.id = z_mmc_doc_center.center_id and z_hosp_member.id = z_mmc_doc_center.doc_id where (z_hosp_member.member_type = ?) and (z_hosp_member.status = ?) and (z_hosp_member.hosp_id = ?) and z_doc_info.is_app_display = ? and z_doc_info.job_rank in (?, ?, ?, ?) and z_hosp_member.id in (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,? | 74.3 | 9.51% | 6395333.28 | 86.1K | 14.0G | api.zz-med.com | MMC 管家 获取医院下的医生列表。 | 0.08% |
| select sum( real_score ) as complete_score from ( select distinct a., ? a.score_weight as real_score from z_mmc_base_control a inner join z_mmc_question b on a.template_id = b.template_id and a.chapter_id = b.chapter_id and a.question_id = b.question_id and a.terminal_flg = b.terminal_flg where b.complete_flg = ? and a.complete_flg_v = ? and a.visit_level = ? and a.gender_flg in ( ?,? ) and b.terminal_flg = ? ) dd | 43.22 | 5.86% | 3939913.31 | 91.2K | 30.3M | common-api | MMC完成度分数计算 | 0.08% |
| select sum(reservation_count) as t_sum, dept_id from z_hosp_schedule where ((date > ?) or (date = ? and time_from > ?)) and date < ? and hosp_id = ? and doc_id = ? group by dept_id | 39 | 4.99% | 3356881.85 | 86.1K | 8.1G | api.zz-med.com | B端管家获取医院下的医生列表 | 0.08% |
| select * from z_qss_template where id in ( select c.template_id from z_mmc_control c left join z_qss_template t on c.template_id = t.id where c.visit_level =? and c.gender_flg in (?,?) and t.category_id =? group by c.template_id ) or id in (?, ?) order by sort desc | 48.87 | 4.75% | 3196084.31 | 65.4K | 7.6G | common-api | MMC 问卷获取章节列表, | 0.06% |
| select id from yandi_ai_record where record_id = ? and is_deleted = ? order by id desc limit ? | 76.65 | 3.52% | 2365035.84 | 30.9K | 3.9G | mmc-api | MMC医护工作站,患者就诊记录列表 | 0.03% |
select * from z_diabetes_user where (user_id = ?) limit ? |
18.48 | 3.18% | 2139856.77 | 115.8K | 1.9G | patient-api | B端控糖营-控糖营小程序 验证登录中间件 | 0.10% |
select u.user_id, u.wechat_name, u.headimage, r.type, r.ranking_num, r.task_complete_num, r.rise from z_diabetes_ranking as r left join z_diabetes_user as u on u.user_id = r.user_id where r.hosp_id = ? and r.type = ? and r.ranking_month = ? and r.is_deleted = ? and u.is_deleted = ? order by r.ranking_num asc limit ? |
107.9 | 2.67% | 1795026.18 | 16.6K | 461.8M | patient-api | B端控糖营用户排行榜,首页包含排行榜的业务 | 0.01% |
select * from z_diabetes_user where user_id = ? order by id desc limit ? |
13.33 | 2.56% | 1719972.47 | 129.0K | 1.3G | patient-api | B端控糖营,根据token获取用户基本信息 | 0.11% |
select u.id as user_id, u.cell, b.is_quality, u.barcode as bar_code, u.name, u.bday, u.sex, v.visit_level, s.visit_year as blood,gp.created_at,r3.visit_at,p.complete_b from z_visit_records as r inner join ( select r1.id,r1.visit_at from ( select * from z_visit_records where user_id in (select distinct user_id from z_mmc_user_barcode where hosp_id =? and dept_id =? ) and type =? and hosp_id =? and dept_id =? order by visit_at desc) r1 group by user_id order by r1.visit_at desc)as r3 on r.id = r3.id left join z_user_visit_his as v on r.visit_id = v.id left join z_user as u on r.user_id = u.id left join z_user_hosp_group as gp on r.user_id = gp.user_id left join z_mmc_user_barcode as b on u.id = b.user_id and b.hosp_id = ? and b.manage_id = ? left join z_mmc_complete as p on p.user_id = v.user_id and p.visit_level = v.visit_level and p.category_id = ? left join z_mmc_blood_sugar as s on r.user_id = s.user_id and s.visit_year = ? where r.visit_id != ? and r.type = ? and b.manage_id = ? order by r.visit_at desc, r.id desc limit ? offset ? |
41.59 | 2.22% | 1492892.47 | 35.9K | 703.2M | mmc-api | MMC业务,医护工作站首页 | 0.03% |
select * from new_doc_group as d left join new_group_role as g on g.id = d.group_id where d.doc_id = ? and d.company_id = ? |
1.11 | 1.94% | 1306331.05 | 1.2M | 1.7G | mmc-api | MMC业务,医护工作站,获取医生菜单权限 | 1.03% |
据以上数据分析,执行耗时高占比业务主要在 MMC B 端 MMC-Site。包括首页患者列表,患者就诊列表,医生菜单权限,完成度通用计算。而 B 端主要执行耗时占比在控糖营登录中间件以及首页访问上。用统计数据结合实际场景,发现执行耗时占比分布合理,没有异常,少量 SQL 存在优化空间。
1.2.2 优化策略
根据数据分析,要改善的方向如下。
- 执行耗时高占比的SQL中本身有可以优化的空间
- 首页数据真实反映用户访问流量,考虑将首页数据,作为热数据库缓存,查询先走缓存,不直接落到 DB 层
- 每周动态统计SQL执行耗时数据,结合历史数据,可以预估未来流量的增长,提早做准备
- B 端和 C 端共库,未来考虑拆分 B 端和 C 端数据,从而未来如果 C 端流量增长过快,不会影响 B 端数据库的使用来保证 B 端业务稳定,这是一项长期的工作,会占用较多开发的人力和时间。
现阶段数据库架构掣肘
2.1 现阶段数据库架构
现阶段应用为单体结构,数据库虽然为主从架构,但从库并没有应用到具体线上业务中。数据库是原始的单实例 RDS MySQL,没有架构可言,所有读写直接落到数据库。缓存使用 Redis,具体应用场景为 Laravel 框架自带的异步队列任务,利用 Redis 原子性实现的锁,经纬度计算距离,以及 HIS 部分将常用查询缓存到 Redis等场景。Redis的使用没有明显减低对数据库的访问压力。
现阶段的单体应用分层架构如下。
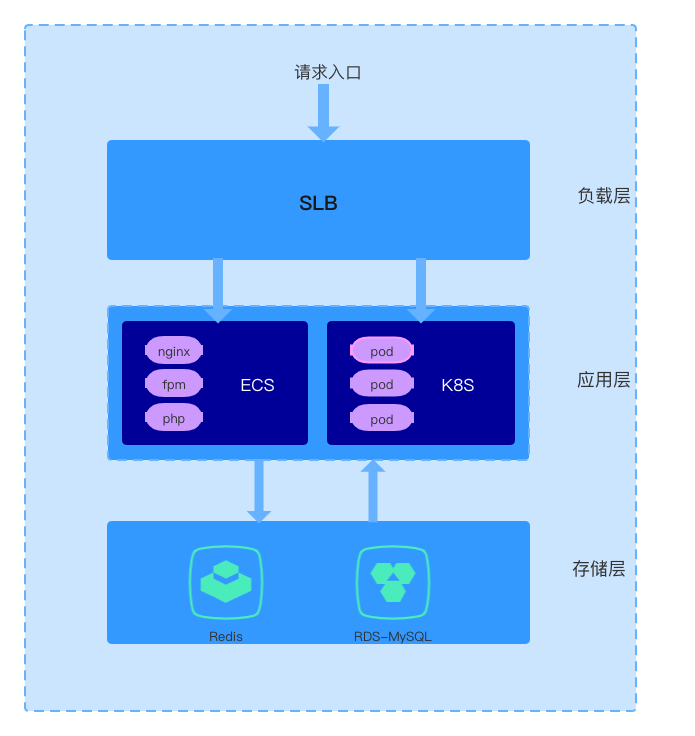
单体应用现阶段应对业务高速发展,适合团队,同时也兼顾了开发效率。暂不考虑进行服务化拆分。未来随着团队和业务的增长到一定程度再考虑。
2.2 数据库的掣肘
- 所有的应用数据查询和存储压力都集中在 RDS 上面,给 RDS 带来巨大压力。现阶段 RDS 在不考虑慢 SQL 影响下可以支持现阶段业务。
- 随着大表数据量的稳定增长(每周100万+),达到一定量级(亿级别)后会造成单表查询性能大幅减低。(每周统计 z_mmc_answer,z_mmc_answer_his 等大表的 QPS, TPS 等核心性能指标)
- C 端未来推广的带来的流量,大幅增加的 C 端业务流量可能导致高峰期B 端业务不稳定。
- 共库造成的表结构相互依赖和耦合,对未来拆分 B 端和 C 端数据库造成一定的困难
下一阶段数据库系统架构方案
3.1 下一阶段业务方向
根据公司目标,拓展 C 端,稳 B 端的策略,预测未来的外部流量会由 B 端逐渐转移到 C 端用户,而 C 端增长特点是快速,量大,需要规划指定出下一阶段数据库系统方案来规避 C 端流量增长带来的系统不稳定性风险。
现阶段 RDS 单实例架构,已经不能满足日益增长的业务数据和流量带来的压力,并且由于所有应用共库,相当于将所有的压力全部放在了数据库上,如果数据库故障,将直接导致线上服务停摆。(已经发生过慢 SQL 导致的线上业务停摆故障,影响时间 20 分支左右)。
3.2 应对方案
公司之前搭建了 TiDB 分布式数据库集群,考虑到将现有业务直接应用到 TiDB 上,成本巨大,并没有充分验证服务切换带来的风险,以及后续维护 TiDB 的成本不菲,所以现在阶段不直接将 TiDB 应用到 OLTP 业务场景下,仅维持其 OLAP 数据分析方面的应用。
3.2.1 RDS 升级
现在及下一阶段,数据库的读写分离能应用到业务端,是对系统现有性能的最合理提升。
调研市场行情并结合我们基础设施全部在阿里云上的场景,考察了阿里云上的各种云数据库,发现POLAR DB 比 RDS 更适合当前业务场景,且能显著提升数据库性能减轻单实例 RDS 访问压力,提升系统稳定性。
从以下几个方面来说明 POLAR DB 更适合当前业务。
| RDS | POLAR DB | |
|---|---|---|
| 数据库协议 | MySQL | 完全兼容MySQL |
| 读写分离 | 支持从节点,自动主从同步,主从可能延时 业务上主从分离需要增加中间件或者改造业务代码 |
原生的分布式主从架构,必须要一主一从 2个节点组成集群,官方宣称主从适合强一致性场景。PolarDB提供集群地址,应用程序连接该地址后即可对主节点和只读节点进行读写操作,读写请求会被自动转发,转发逻辑完全对使用者透明,可降低维护成本。 |
| 架构 | 计算和存储都在单台实例上进行 | 计算&存储分离架构,存储空间可以动态快速动态扩容 |
| 升级 | - | 支持从 RDS 一键升级至 POLAR DB |
| 成本 | 8核16GB 一节点,一年 20400 | 4 核16GB 两节点 一年 20400 |
| 数据存储 | 数据稳定增长,磁盘使用率快达到了 80%,磁盘扩容需要拷贝数据,本地SSD型RDS可能需要几个小时。 | 上限支持 100TB,动态扩容,按量付费。对于大容量的单表数据库查询性能比 RDS 提高了几倍。需要调研单表性能的容量上限 |
| 数据同步到 TiDB | DTS | DTS |
通过以上对比,POLARD DB 的主从分离无需额外运维的架构能给现阶段及下一阶段带来最大的便利和性能收益。RDS 迁移到 POLAR DB 没有其他额外负担,需要做的工作是,一键升级并修改线上各应用的数据库配置。升级可以选择周末,停服升级,影响时间较短(10分钟左右即可完成升级,线上配置修改耗时也较短)。
后续如果采用升级方案会给出具体的Polar DB 升级方案。
3.2.2 Redis 缓存热数据库或者访问量/执行耗时占比高的业务场景数据
根据执行耗时占比同比,数据库语句的执行耗时符合二八原则,少量的SQL占据了大部分执行时间。
每周自动化程序拉取阿里云数据库的执行耗时占比统计,根据情况,将热数据写入缓存。
对接口的业务代码进行改造,先走 Redis查询数据,减少对数据库的访问。
最后,要研究基于 TiDB 的分布式自建数据库能否应用到现有业务场景,如何适合,要指定什么时候适合迁移如何迁移到TiDB的**方案**。
数据库优化方案结论。
- 升级TiDB4.0后,py-report 项目切换至TiDB。
- RDS 保持现有架构,升级 Readonly 从库配置保持配置和主库硬件配置相同,避免硬件性能造成的主从延时较大,使用 MySQL proxy 中间件做代理,做主从分离架构。
- 每周监控数据增长,热数据,核心指标,单个单表的核心指标(QPS/TPS)。根据监控指标做硬件升级调整。

若有收获,就点个赞吧
0 人点赞
