现象描述
时间线及应对
- 8:41 应用 API 健康监控探针告警 patient-api 监控接口延时超过 3s
- 王永乐介入排查具体延迟原因
- 08:45 收到阿里云短信告警 RDS 数据库CPU平均负载 99.35 持续3分钟。
- 排查方向指向数据库负载过高
- 当时怀疑为 MySQL 慢 SQL 引起的 CPU 负载过高,引起后续正常业务 SQL 执行阻塞
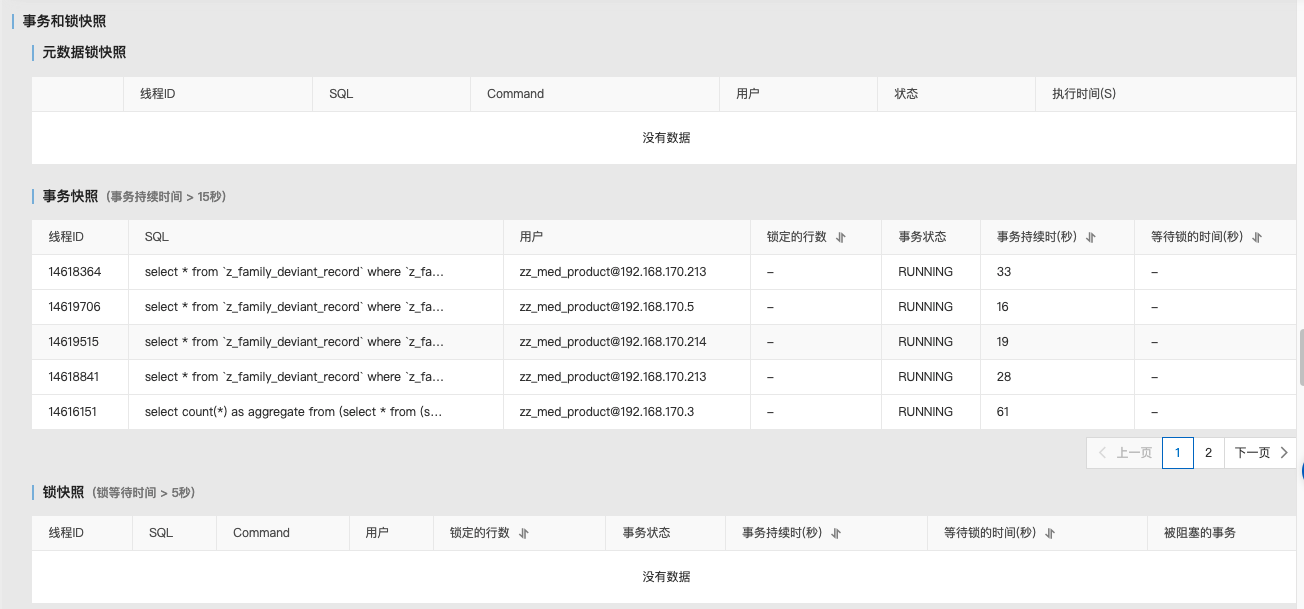
- 使用 MySQL 指令查询执行语句的线程,查看异常线程(time 等待较长的非 sleep 线程),进行 KILL 线程的操作
- 8:59 接受业务方反馈部分页面响应延迟较大
- 9:19 分数据库负载降低到正常值,业务恢复至正常响应速度
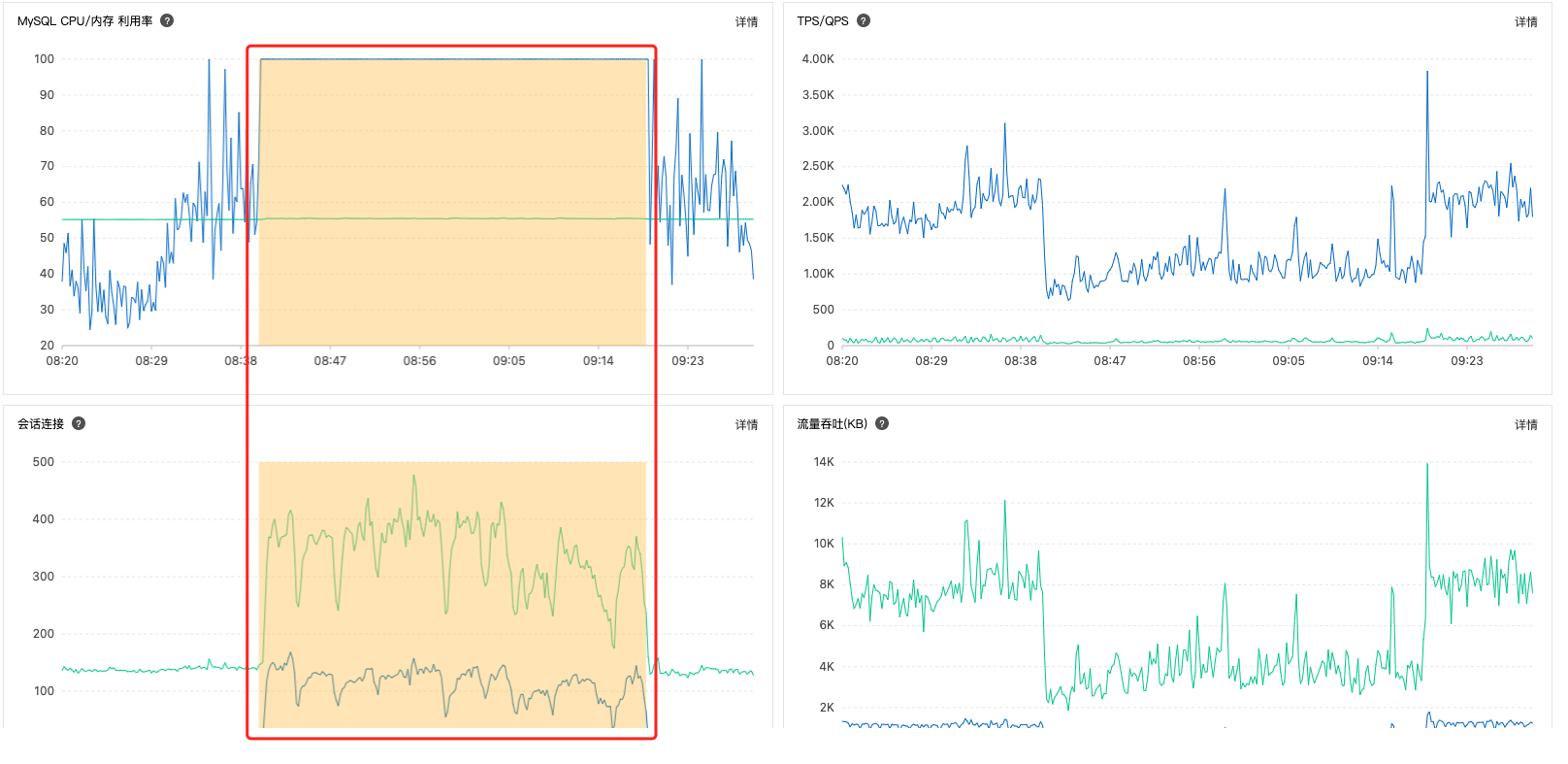
指标随时间变化曲线图
CPU、IOPS、会话连接和吞吐量曲线
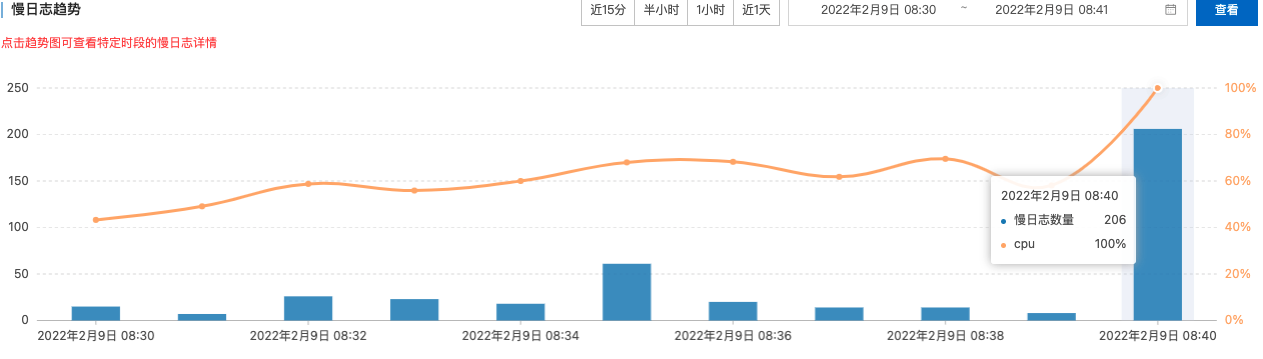
慢日志趋势图像
趋势特征
- 8:40 分 CPU 负载达到 100%
- 慢 SQL 数量同时上升
- 会话连接数同时上升
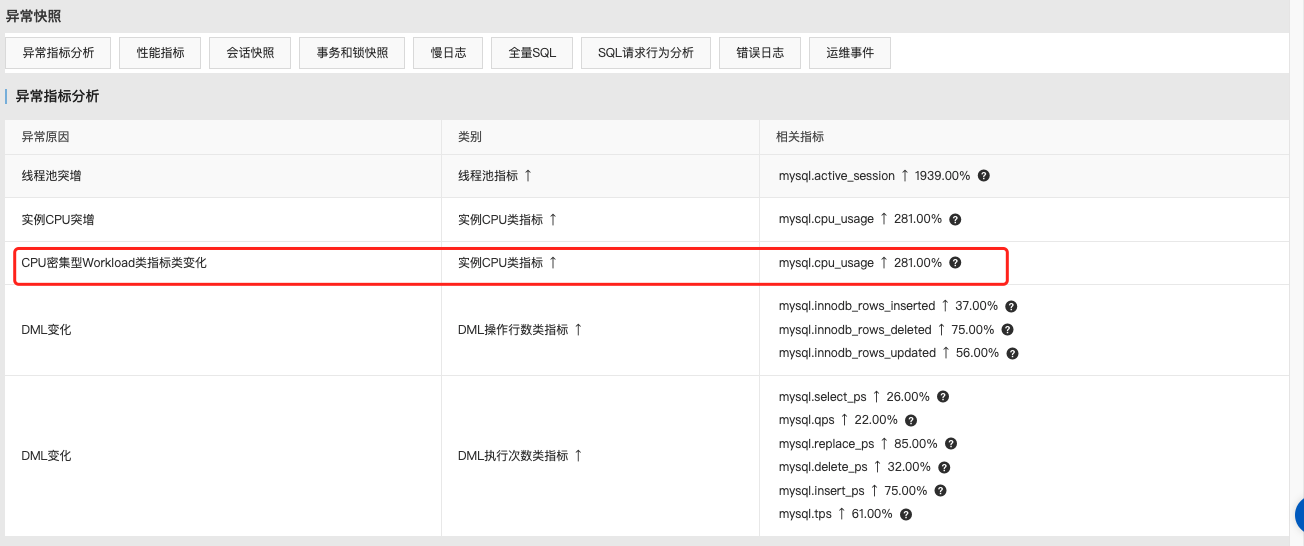
阿里云 RDS 诊断工具参考
应用访问趋势
2.7 至 2.9 三日 08:33 ~ 08:50 应用访问量统计对比
访问量统计基于 nginx 访问日志对每个应用的 URL 访问统计
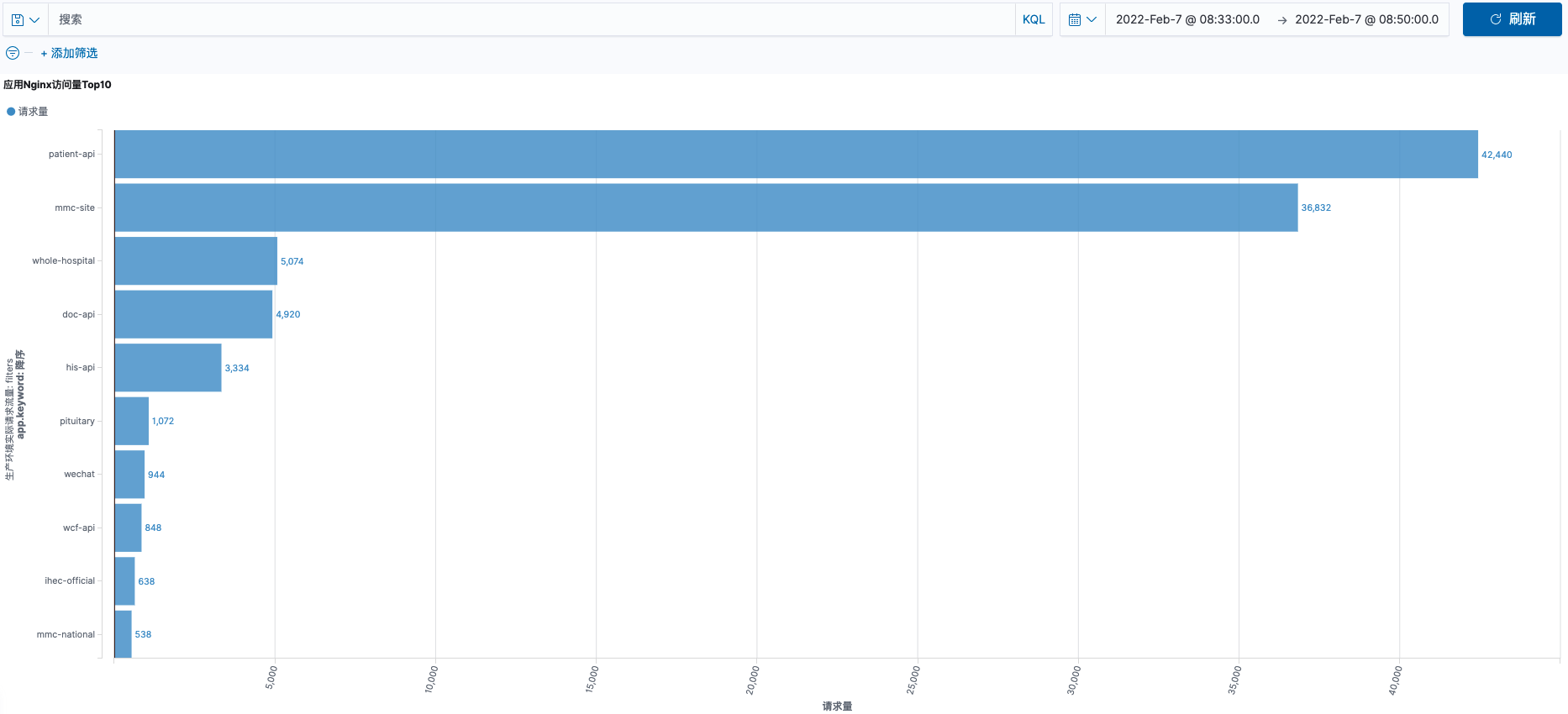
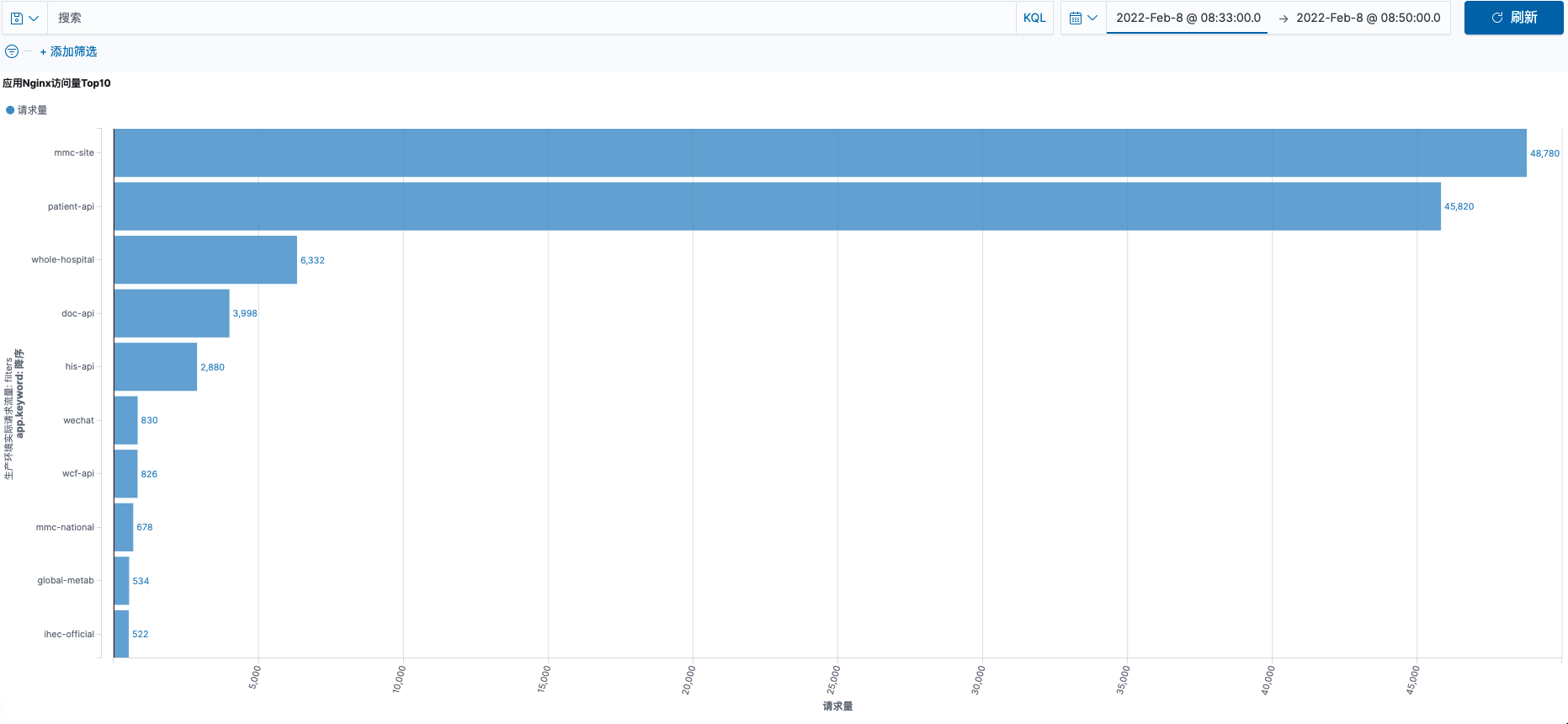
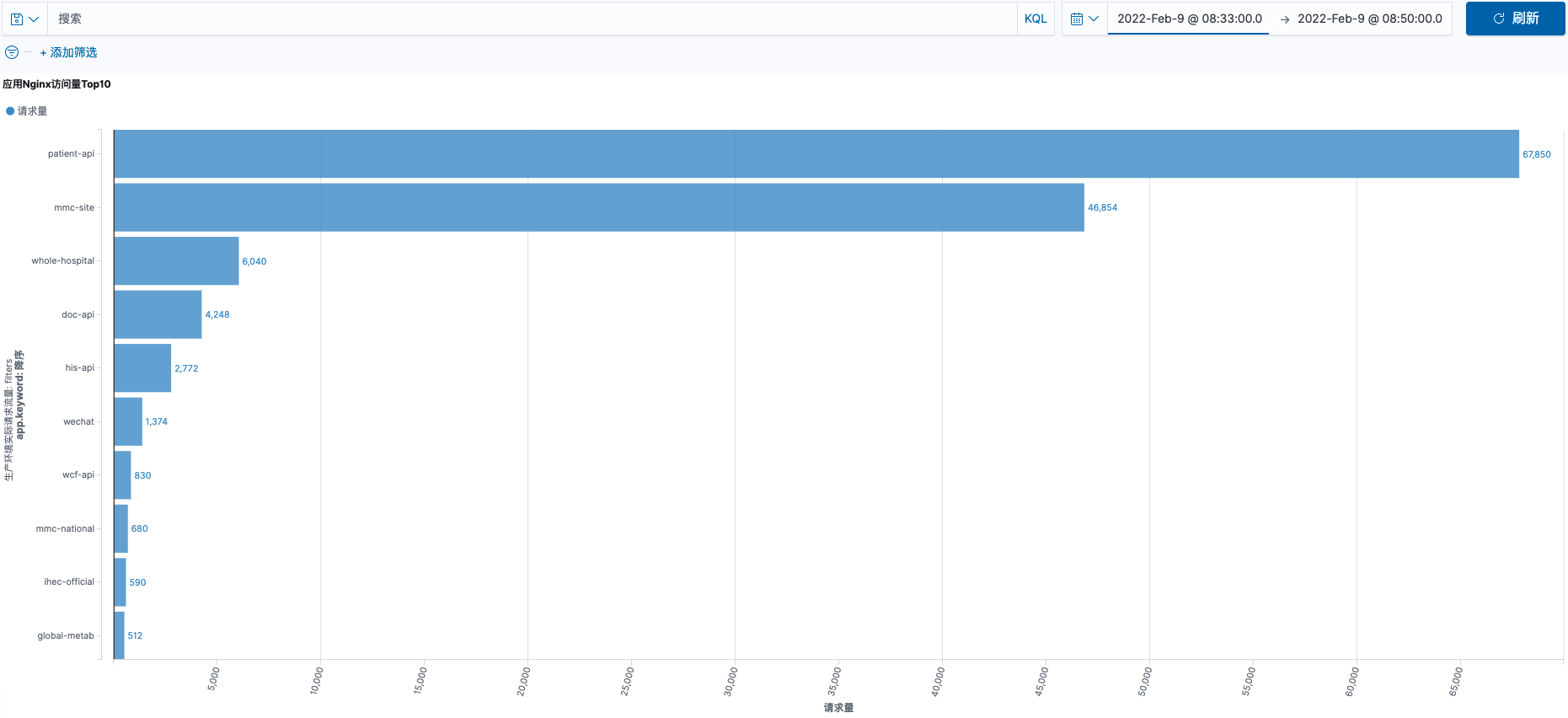
从上图访问量趋势图对比看出。
2.9 日 patient-api 访问量比 2.7、2.8 平均增长 40 % 以上。与MySQL 会话连接增长趋势相同。
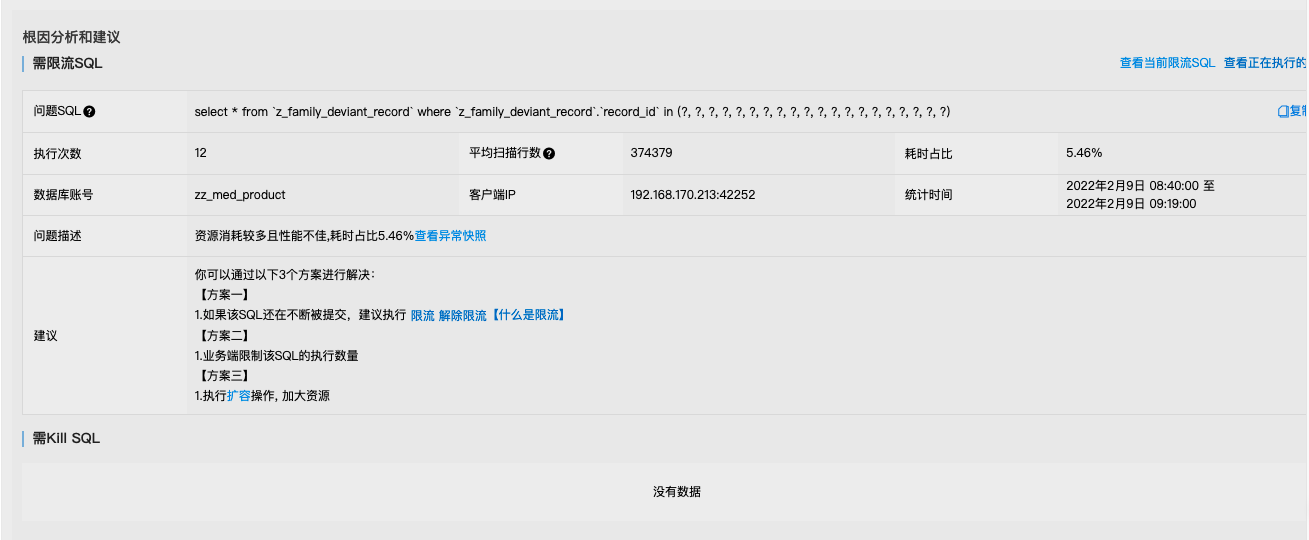
慢日志执行时长 Top sql
SELECT *FROM `z_family_deviant_record`WHERE `z_family_deviant_record`.`record_id` IN (5599308, 5651935, 5653026, 5653875, 5655952, 5661085, 5662096, 5662998, 5721775, 5731263, 5733009, 5733788, 5741551, 5741554, 5742705, 5789197, 5791081, 5797530, 5814975, 5815836, 5868389)
SELECT count(*) AS aggregateFROM (SELECT *FROM (SELECT `user_id`, `measure_at`, `bg`FROM `z_bg`WHERE `product_id` IN (17)AND `dept_id` = 245172AND `measure_type` IN (1, 2)AND `measure_at` BETWEEN '20210101000000' AND '20211231235959'ORDER BY `measure_at` DESC) tmpGROUP BY `tmp`.`user_id`) sINNER JOIN `z_user` `u` ON `u`.`id` = `s`.`user_id`WHERE `u`.`status` IN (1, 2)AND `u`.`is_del` = 0
SELECT count(DISTINCT r1.user_id) AS cntFROM z_visit_records r1INNER JOIN z_mmc_user_barcode b1ON r1.hosp_id = b1.hosp_idAND r1.dept_id = b1.dept_idAND r1.user_id = b1.user_idWHERE r1.hosp_id = 12374AND b1.dept_id = 13162AND r1.type = 0AND b1.plan_id = 1
SELECTcount(DISTINCT ( u.id )) AS AGGREGATEFROM(SELECT*FROM( SELECT * FROM z_visit_records WHERE dept_id = 12053 AND hosp_id = 11370 AND ( type = 0 OR type = 9 ) ORDER BY visit_at DESC ) AS r1GROUP BYr1.user_id) AS vINNER JOIN `z_user` AS `u` ON `v`.`user_id` = `u`.`id`INNER JOIN `z_mmc_user_barcode` AS `mub` ON `mub`.`user_id` = `v`.`user_id`AND `mub`.`hosp_id` = 11370AND `mub`.`dept_id` = 12053AND `mub`.`manage_id` = 1LEFT JOIN `xd_family_deviant_record_last` AS `ab` ON `ab`.`user_id` = `u`.`id`LEFT JOIN (SELECTap.id,ap.user_idFROMx_appointments AS apJOIN x_order_goods AS og ON ap.order_goods_id = og.idJOIN x_products AS p ON og.product_id = p.idWHEREp.alias_name = 'M90'AND ap.end_date >= '2022-02-09 08:35:09') AS apo ON `apo`.`user_id` = `u`.`id`WHERE(instr( u.NAME, '赵金菊' ) > 0OR u.id IN ( SELECT user_id FROM z_wechat_user WHERE instr( nickname, '赵金菊' ) > 0 ))
总结
原因分析
- 慢 SQL和连接数增加同时叠加造成的 CPU 负载过高,对后续正常业务 SQL 造成阻塞
- 老的性能差的统计的 SQL,仍然在代码中,平时显现不出来,会在 CPU 负载较高时,引起坏的效应
- 慢日志存在于日常 SQL 中没有完全清理
修复手段
针对本次的修复
- 日志排查到的慢 SQL,执行时长占比较高,上版已修复一次,有部分业务未完全移除依赖。已安排修复,计划于今天上线。(patient-api 项目)
- 其他日志中执行频率较高的 SQL 已对表索引进行优化。(添加了 x_user_logins 表的针对业务场景查询的索引, x_social_users 添加索引)
- 出现在本次慢日志明细中的 SQL。逐个排查,针对性给出优化或误判的建议。
未来计划
- 按照慢日志的各指标,例如扫描行数,执行时长,是否锁表。给出当日扫描的慢 SQL 必须当日上线的指标规范,确保慢 SQL 的影响可控。
- 对开发加强宣讲慢 SQL 的优化手段,以及慢SQL 的危害,引导开发尽量不要写出影响线程业务性能的 SQL。如业务需求中涉及到的复杂业务,积极寻找其他手段代替复杂 SQL 的写法。
- 针对现阶段统计需求,做出针对性的方案。例如,使用 ETL 后的数据来分析等。
- 后端的数据库架构升级。例如,读写分离等业内常见高可用及其他优化手段。

若有收获,就点个赞吧
0 人点赞
