简介
定位
- 数据处理流程的调度系统和统一管理系统
- 解决数据流程之间本身的依赖
- 运维友好,部署简单
- 高可用、易扩展
- 功能丰富,支持数据处理常见组件
- 低学习成本
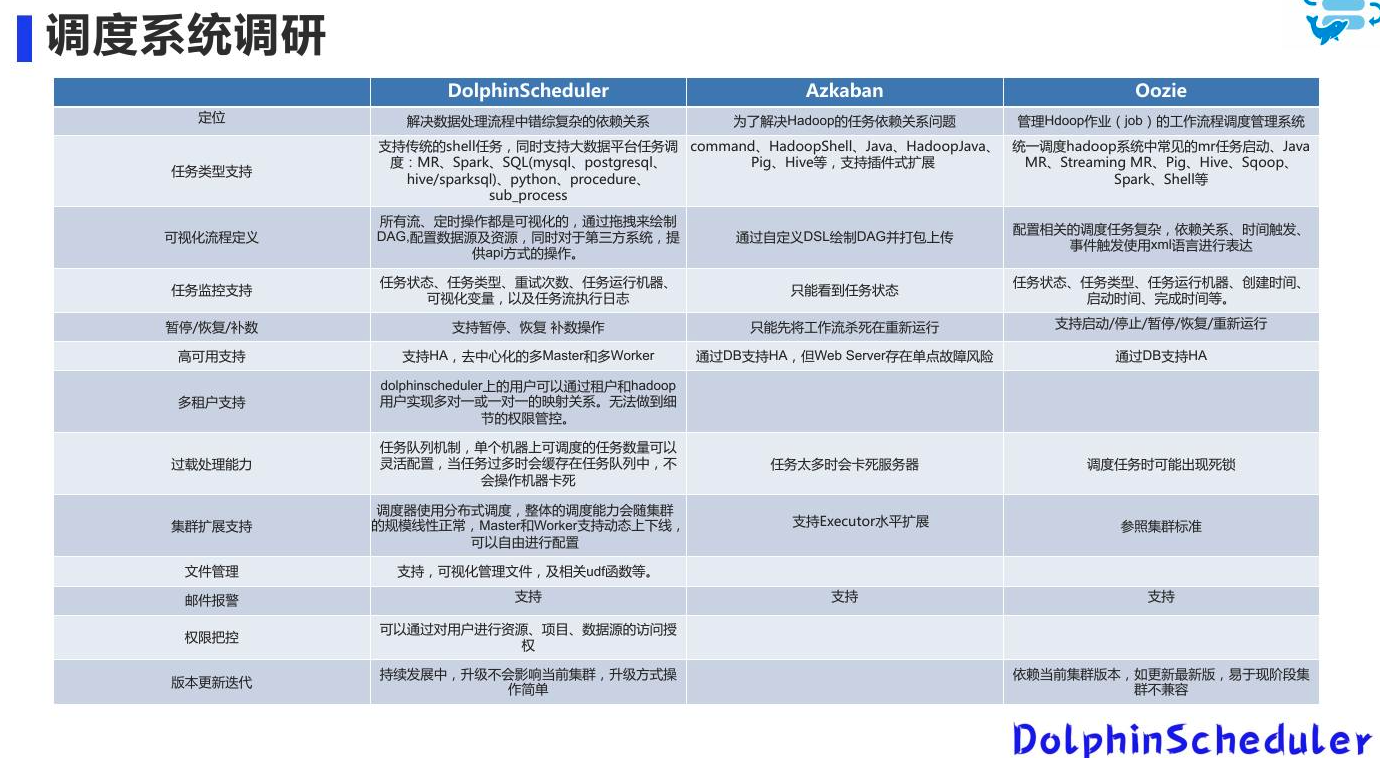
系统选型对比
| 指标 | airflow | dolphin-scheduler |
|---|---|---|
| 任务类型 | bash、python、第三方 provider packages(开放拓展能力) 通过第三方服务支持市面上绝大部分组件 |
shell、subprocess、存储过程、sql、spark、flink、datax、python、mapreduce 支持市面上绝大部分大数据的组件 |
| 后端架构 | celery + redis + database 组件分为 worker、scheduler、server 和前端 UI |
api-server、Master-Worker 集群、Task Queue、zookeeper、database |
| HA | 通过 celery + redis 保证应用的 HA 通过数据库本身 HA 保证数据库层面的HA |
zk + spring-boot 系列 通过 zk 支持分布式能力 通过数据库本身 HA 保证数据库层面的HA |
| 运维 | 集群部署较 dolphinScheduler稍微复杂 | 部署简单 容易添加节点 |
| 调度 | 不支持暂停和恢复(需要先 kill 任务再重跑) | 支持暂停、恢复 |
| 自定义任务类型 | 支持 | 支持 |
| UI | 界面支持一些简单的搜索和任务触发,还有日志查看和配置等功能。DAG通过 python 代码定义。 | 可通过拖拽来定义 DAG |
| 任务运行状态 | 支持可视化查看与统计 支持日期直接在 web 端查看 |
任务状态详细 支持可视化查看与统计 支持日期直接在 web 端查看 |
| 其他 | 租户隔离、项目视图、参数传递、数据质量 |
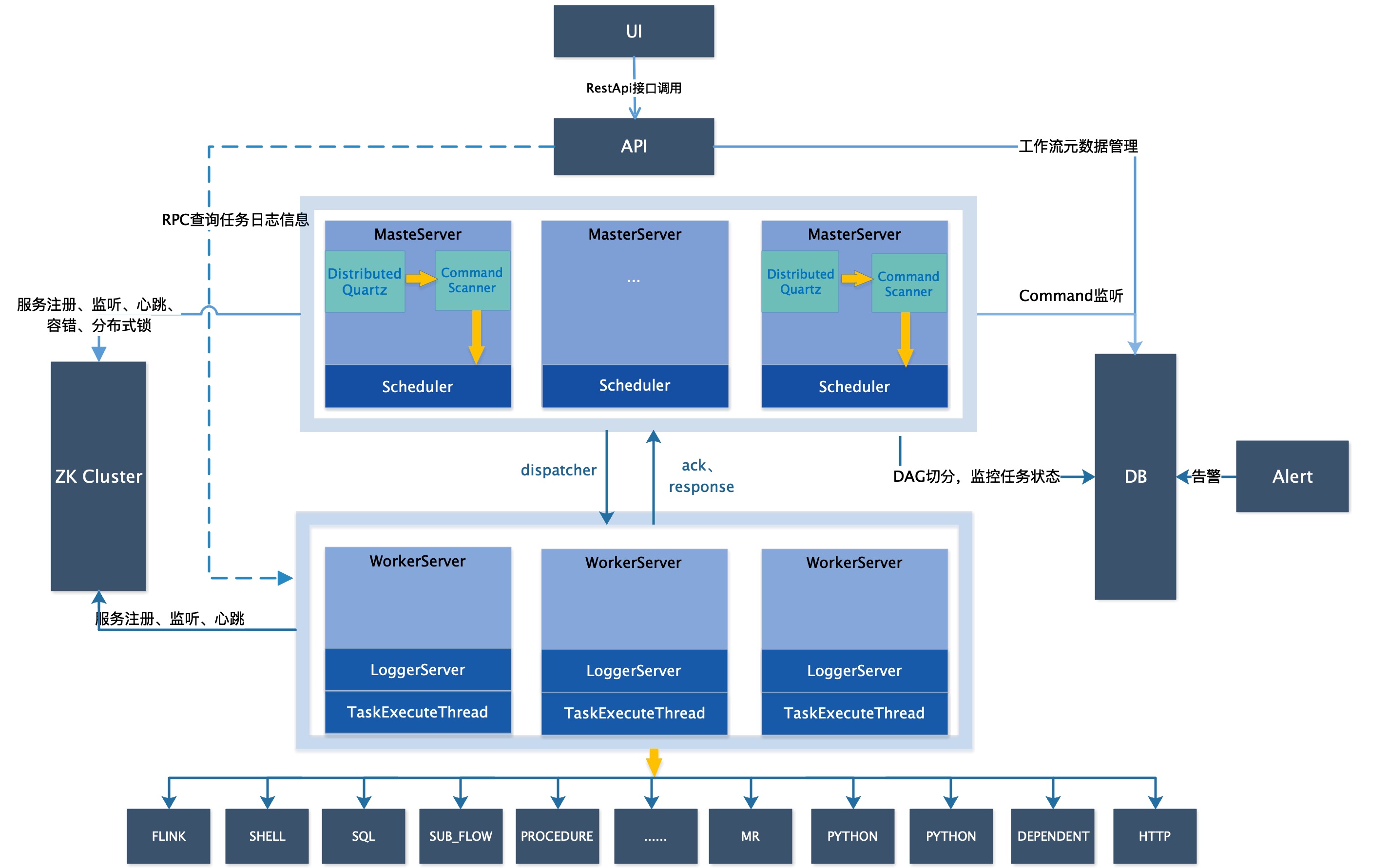
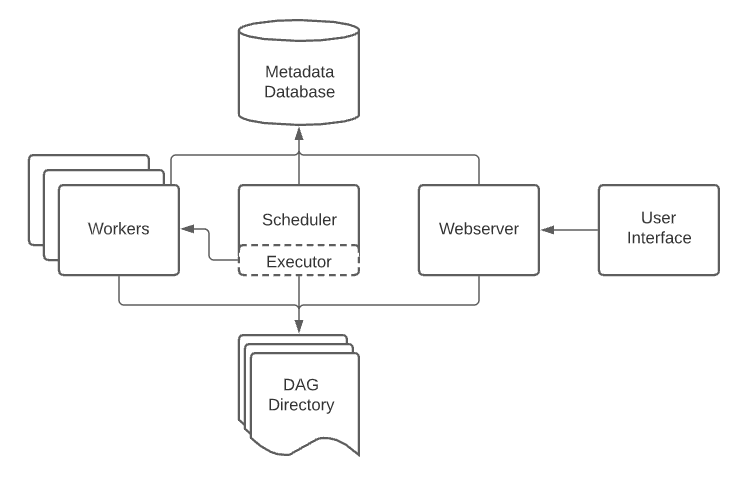
架构
DS 架构图如下
Airflow 架构图如下
最佳实践
deployment
- 依托 K8s 集群的调度和扩展能力,以集群方式部署在 K8s 上
- worker 节点必须要有 Linux 包发行版管理能力,必须提前安装好对应版本 python 和其他任务执行时依赖的组件、编程语言、开发框架、计算框架
- worker必须要持久化,且必须考虑并做好支持 python 生态下 pip requirements.txt 包管理持久化
- 资源监控必须暴露并展现在 Grafana,并做好监控告警接入钉钉
- 依赖容器启动的数据库时,必须按照规定备份频次做好数据备份工作
用户与权限管理
- 必须仅授予指定管理员的用户管理权限(创建用户、修改用户、删除用户)
- 必须仅授予项目创建权限到指定人员的账户上
- 必须以最小粒度对用户授予项目、资源、数据源及命名空间的权限
项目管理
- 按照大业务领域划分为 SaaS 和 MMC
- 项目内的数据处理流程必须要按照业务归属,创建在对应的项目下
- 创建数据处理流程,流程命名必须要体现工作流的作用,一定要使用中文命名,体现业务上下文
工作流定义操作手册

若有收获,就点个赞吧
0 人点赞
