index dive
有时候使用索引执行查询时会有许多单点区间,比如使用 IN 语句就很容易产生非常多的单点区间,比如下边这个查询(下边查询语句中的…表示还有很多参数):
SELECT FROM order_exp WHERE order_no IN (‘aa1’, ‘aa2’, ‘aa3’, … , ‘zzz’);
很显然,这个查询可能使用到的索引就是 idx_order_no,由于这个索引并不是唯一二级索引,所以并不能确定一个单点区间对应的二级索引记录的条数有多少,需要我们去计算。就是先获取索引对应的 B+树的区间最左记录和区间最右记录,然后再计算这两条记录之间有多少记录(记录条数少的时候可以做到精确计算,多的时候只能估算)。MySQL 把这种通过直接访问索引对应的 B+树来计算某个范围区间对应的索引记录条数的方式称之为 *index dive。
有零星几个单点区间的话,使用 index dive 的方式去计算这些单点区间对应的记录数也不是什么问题,如果 IN 语句里 20000 个参数怎么办?
这就意味着 MySQL 的查询优化器为了计算这些单点区间对应的索引记录条数,要进行 20000 次 index dive 操作,这性能损耗就很大,搞不好计算这些单点区间对应的索引记录条数的成本比直接全表扫描的成本都大了。MySQL 考虑到了这种情况,所以提供了一个系统变量 eq_range_index_dive_limit,我们看一下在MySQL 5.7.21 中这个系统变量的默认值:
show variables like '%dive%';
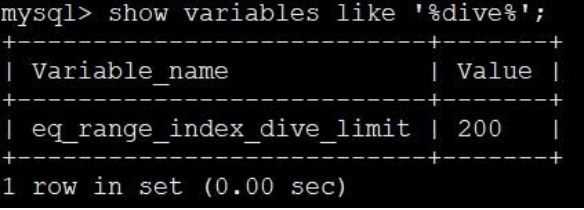
也就是说如果我们的 IN 语句中的参数个数小于 200 个的话,将使用 index dive 的方式计算各个单点区间对应的记录条数,如果大于或等于 200 个的话,可就不能使用 index dive 了,要使用所谓的索引统计数据来进行估算。
MySQL 也会为表中的每一个索引维护一份统计数据,查看某个表中索引的统计数据可以使用 SHOW INDEX FROM 表名的语法,比如我们查看一下 order_exp 的各个索引的统计数据可以这么写:
show index from order_exp;
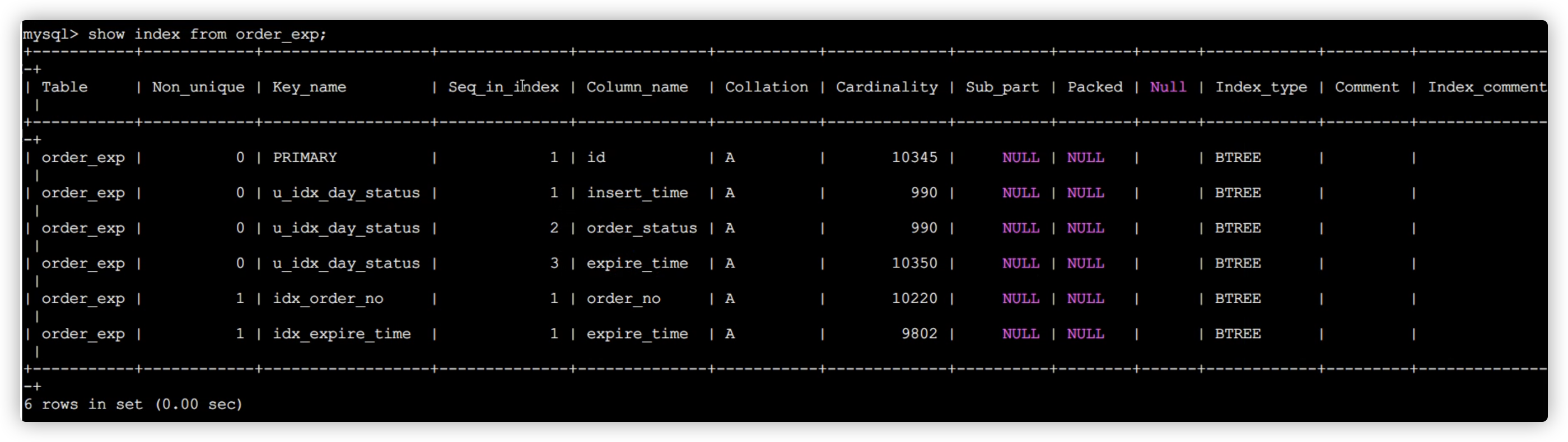
- Table 索引所属表的名称。
- Non_unique 索引列的值是否是唯一的,聚簇索引和唯一二级索引的该列值为 0,普通二级索引该列值为 1。
- Key_name 索引的名称。
- Seq_in_index 索引列在索引中的位置,从 1 开始计数。比如对于联合索引u_idx_day_status,来说,
insert_time,order_status,expire_time对应的位置分别是 1、2、3。 - Column_name 索引列的名称。
- Collation 索引列中的值是按照何种排序方式存放的,值为 A 时代表升序存放,为 NULL 时代表降序存放。
- Cardinality 索引列中不重复值的数量。后边我们会重点看这个属性的。
- Sub_part 对于存储字符串或者字节串的列来说,有时候我们只想对这些串的前 n 个字符或字节建立索引,这个属性表示的就是那个 n 值。如果对完整的列建立索引的话,该属性的值就是 NULL。
- Packed 索引列如何被压缩,NULL 值表示未被压缩。这个属性我们暂时不了解,可以先忽略掉。
- Null 该索引列是否允许存储 NULL 值。
- Index_type 使用索引的类型,我们最常见的就是 BTREE,其实也就是 B+树索引。
- Comment 索引列注释信息。
- Index_comment索引注释信息。
- Cardinality 属性,Cardinality 直译过来就是基数的意思,表示索引列中不重复值的个数。比如对于一个一万行记录的表来说,某个索引列的 Cardinality 属性是 10000,那意味着该列中没有重复的值,如果 Cardinality 属性是 1 的话,就意味着该列的值全部是重复的。不过需要注意的是,对于 InnoDB 存储引擎来说, 使用 SHOW INDEX 语句展示出来的某个索引列的 Cardinality 属性是一个估计值, 并不是精确的。
前边说道,当 IN 语句中的参数个数大于或等于系统变量eq_range_index_dive_limit 的值的话,就不会使用 index dive 的方式计算各个单点区间对应的索引记录条数,而是使用索引统计数据,这里所指的索引统计数据指的是这两个值:
使用SHOW TABLE STATUS 展示出的Rows 值,也就是一个表中有多少条记录。使用 SHOW INDEX 语句展示出的 Cardinality 属性。
结合上一个 Rows 统计数据,我们可以针对索引列,计算出平均一个值重复多少次。
一个值的重复次数 ≈ Rows ÷ Cardinality
以 order_exp 表的 idx_order_no 索引为例,它的 Rows 值是 10350,它对应的 Cardinality 值是 10220,所以我们可以计算 order_no 列平均单个值的重复次数就是:
10350÷ 10220≈ 1.012(条)
此时再看上边那条查询语句:
SELECT * FROM order_exp WHERE order_no IN ('aa1', 'aa2', 'aa3', ... , 'zzz');
假设 IN 语句中有 20000 个参数的话,就直接使用统计数据来估算这些参数需要单点区间对应的记录条数了,每个参数大约对应 1.012 条记录,所以总共需要回表的记录数就是:
20000 x 1.012= 21,730
使用统计数据来计算单点区间对应的索引记录条数比index dive 的方式简单, 但是它的致命弱点就是:不精确!。使用统计数据算出来的查询成本与实际所需 的成本可能相差非常大。
:::tips
大 家 需 要 注 意 一 下 , 在 MySQL 5.7.3 以 及 之 前 的 版 本 中 , eq_range_index_dive_limit 的默认值为 10,之后的版本默认值为 200。所以如果大家采用的是 5.7.3 以及之前的版本的话,很容易采用索引统计数据而不是 index dive 的方式来计算查询成本。当你的查询中使用到了 IN 查询,但是却实际没有用到索引,就应该考虑一下是不是由于 eq_range_index_dive_limit 值太小导致的。
:::

若有收获,就点个赞吧
0 人点赞
