我们平时使用 INSERT 语句向表中插入的那些记录称之为用户数据,MySQL 只是作为一个软件来为我们来保管这些数据,提供方便的增删改查接口而已。但是每当我们向一个表中插入一条记录的时候,MySQL 先要校验一下插入语句对应的表存不存在,插入的列和表中的列是否符合,如果语法没有问题的话,还需要知道该表的聚簇索引和所有二级索引对应的根页面是哪个表空间的哪个页面,然后把记录插入对应索引的 B+树中。所以说,MySQL 除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,比方说:
某个表属于哪个表空间,表里边有多少列,表对应的每一个列的类型是什么, 该表有多少索引,每个索引对应哪几个字段,该索引对应的根页面在哪个表空间的哪个页面,该表有哪些外键,外键对应哪个表的哪些列,某个表空间对应文件系统上文件路径是什么。
上述这些数据并不是我们使用 INSERT 语句插入的用户数据,实际上是为了更好的管理我们这些用户数据而不得已引入的一些额外数据,这些数据也称为元数据。InnoDB 存储引擎特意定义了一些列的内部系统表(internal system table) 来记录这些这些元数据:
表名 描述
- SYS_TABLES整个 InnoDB 存储引擎中所有的表的信息
- SYS_COLUMNS 整个 InnoDB 存储引擎中所有的列的信息
- SYS_INDEXES 整个 InnoDB 存储引擎中所有的索引的信息
- SYS_FIELDS 整个 InnoDB 存储引擎中所有的索引对应的列的信息
- SYS_FOREIGN 整个 InnoDB 存储引擎中所有的外键的信息
- SYS_FOREIGN_COLS 整个 InnoDB 存储引擎中所有的外键对应列的信息
- SYS_TABLESPACES 整个 InnoDB 存储引擎中所有的表空间信息
- SYS_DATAFILES 整个 InnoDB 存储引擎中所有的表空间对应文件系统的文件路径信息
- SYS_VIRTUAL 整个 InnoDB 存储引擎中所有的虚拟生成列的信息
这些系统表也被称为数据字典,它们都是以B+树的形式保存在系统表空间的某些页面中,其中 SYS_TABLES、SYS_COLUMNS、SYS_INDEXES、SYS_FIELDS 这四个表尤其重要,称之为基本系统表。
这 4 个表是表中之表,那这 4 个表的元数据去哪里获取呢?只能把这 4 个表的元数据,就是它们有哪些列、哪些索引等信息硬编码到代码中,然后 InnoDB 的又拿出一个固定的页面来记录这 4 个表的聚簇索引和二级索引对应的 B+树位置,这个页面就是页号为 7 的页面 Data Dictionary Header,类型为 SYS,记录了数据字典的头部信息。除了这 4 个表的 5 个索引的根页面信息外,这个页号为 7 的页面还记录了整个 InnoDB 存储引擎的一些全局属性,比如 Row ID。
数据字典头部信息中有个 Max Row ID 字段,我们说过如果我们不显式的为表定义主键,而且表中也没有 UNIQUE 索引,那么 InnoDB 存储引擎会默认为我们生成一个名为 row_id 的列作为主键。因为它是主键,所以每条记录的 row_id 列的值不能重复。
原则上只要一个表中的 row_id 列不重复就可以了,也就是说表 a 和表 b 拥有一样的 row_id 列也没啥关系,不过 InnoDB 只提供了这个 Max Row ID 字段, 不论哪个拥有 row_id 列的表插入一条记录时,该记录的 row_id 列的值就是 Max Row ID 对应的值,然后再把 Max Row ID 对应的值加 1,也就是说这个 Max Row ID 是全局共享的。
用户是不能直接访问 InnoDB 的这些内部系统表的,除非你直接去解析系统表空间对应文件系统上的文件。不过 InnoDB 考虑到查看这些表的内容可能有助于大家分析问题,所以在系统数据库 information_schema 中提供了一些以innodb_sys 开头的表: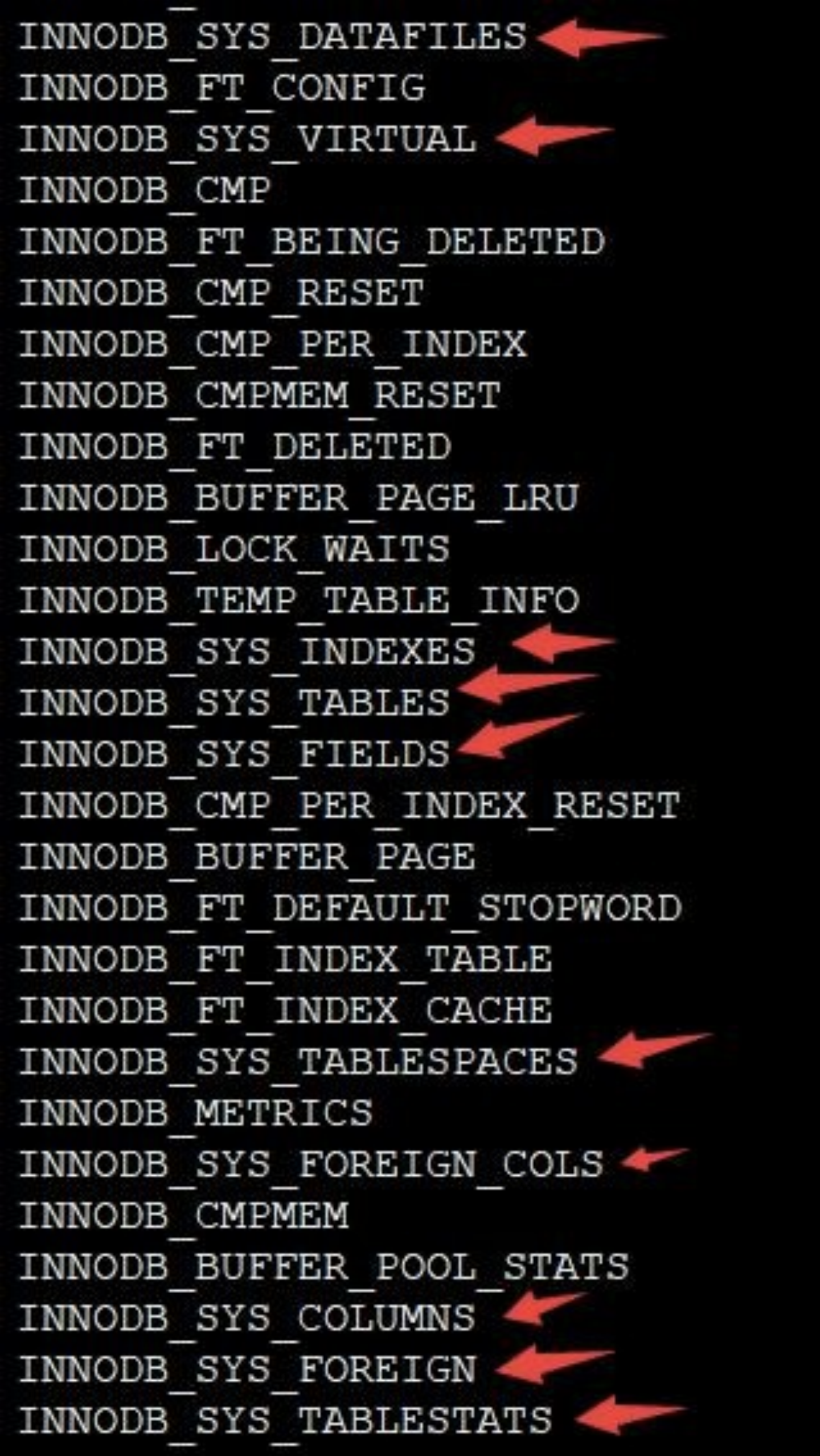
在information_schema 数据库中的这些以INNODB_SYS 开头的表并不是真正的内部系统表(内部系统表就是我们上边唠叨的以 SYS 开头的那些表),而是在存储引擎启动时读取这些以 SYS 开头的系统表,然后填充到这些以 INNODB_SYS 开头的表中。

若有收获,就点个赞吧
0 人点赞
