前缀索引
有时候需要索引很长的字符列,这会让索引变得大且慢。一个策略是前面提 到过的模拟哈希索引。
模拟哈希索引:
order_exp 表中 order_note 字段很长,想把它作为一个索引,我们可以增加一个 order_not_hash 字段来存储 order_note 的哈希值,然后在 order_not_hash 上建立索引,相对于之前的索引速度会有明显提升,一个是对完整的 order_note做索引,而后者则是用整数哈希值做索引,显然数字的比较比字符串的匹配要高效得多。
但是缺陷也很明显:
1、需要额外维护 order_not_hash 字段;
2、哈希算法的选择决定了哈希冲突的概率,不良的哈希算法会导致重复值很多;
3、不支持范围查找。
还可以做些什么改进呢?还可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。但这样也会降低索引的选择性。一般情况下我们需 要保证某个列前缀的选择性也是足够高的,以满足查询性能。(尤其对于 BLOB、TEXT 或者很长的 VARCHAR 类型的列,应该使用前缀索引,因为 MySQL 不允许索引这些列的完整长度)。
诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便节约空间)。前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。换句话说,前缀的“基数”应该接近于完整列的“基数”。为了决定前缀的合适长度,可以找到最常见的值的表,然后和最常见的前缀列表进行比较。
首先找到最常见的值的列表:
SELECT COUNT(*) AS cnt,order_note FROM order_exp GROUP BY order_noteORDER BY cnt DESC LIMIT 20;
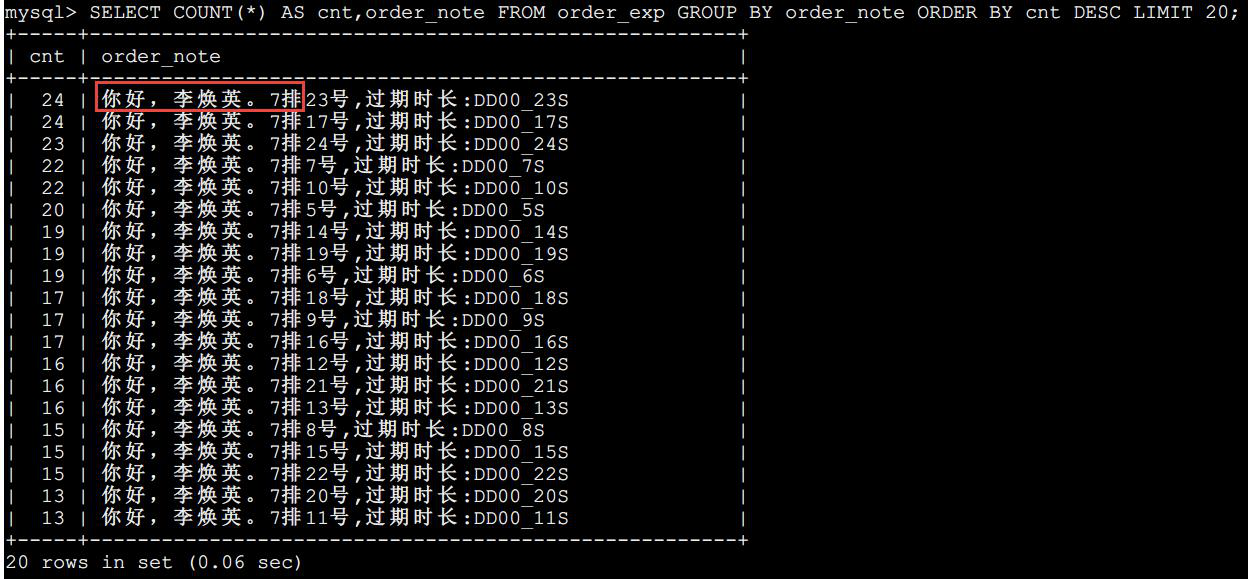
通过观察数据的分布,我们可以大胆的猜测,前 9 个字符的选择性不会太好,从第 10 个开始应该还不错。试一试:
SELECT COUNT(DISTINCT LEFT(order_note,3))/COUNT(*) AS sel3,COUNT(DISTINCT LEFT(order_note,4))/COUNT(*)AS sel4,COUNT(DISTINCT LEFT(order_note,5))/COUNT(*) AS sel5,COUNT(DISTINCT LEFT(order_note, 6))/COUNT(*) As sel6,COUNT(DISTINCT LEFT(order_note, 7))/COUNT(*) As sel7,COUNT(DISTINCT LEFT(order_note, 8))/COUNT(*) As sel8,COUNT(DISTINCT LEFT(order_note, 9))/COUNT(*) As sel9,COUNT(DISTINCT LEFT(order_note, 10))/COUNT(*) As sel10,COUNT(DISTINCT LEFT(order_note, 11))/COUNT(*) As sel11,COUNT(DISTINCT LEFT(order_note, 12))/COUNT(*) As sel12,COUNT(DISTINCT LEFT(order_note, 13))/COUNT(*) As sel13,COUNT(DISTINCT LEFT(order_note, 14))/COUNT(*) As sel14,COUNT(DISTINCT LEFT(order_note, 15))/COUNT(*) As sel15,COUNT(DISTINCT order_note)/COUNT(*) As total FROM order_exp;
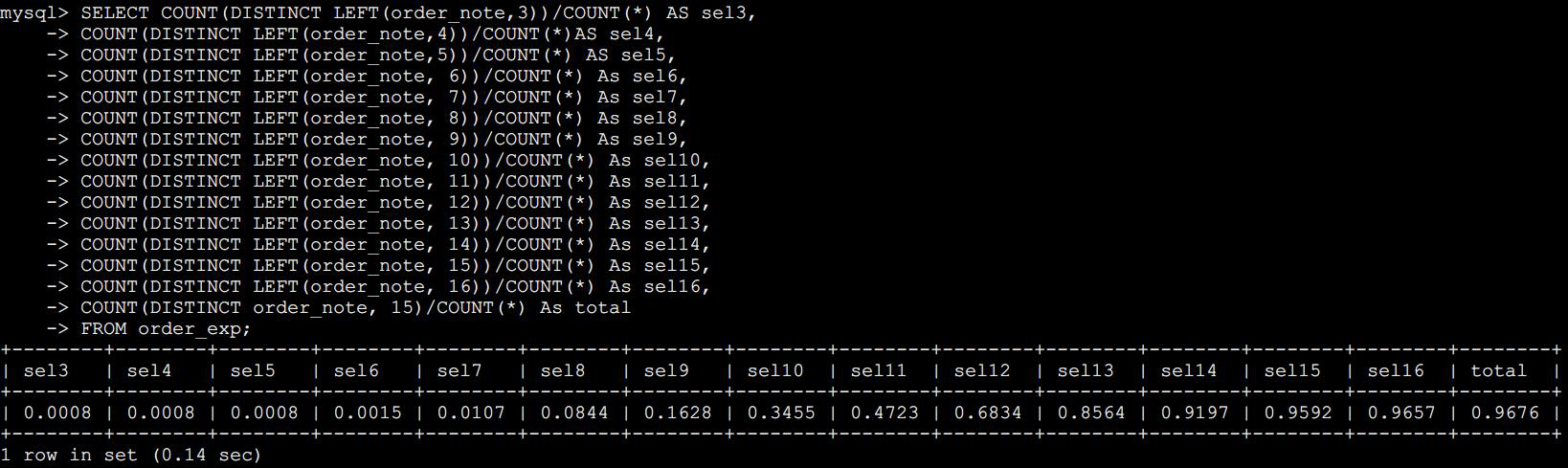
可以看见,从第 10 个开始选择性的增加值很高,随着前缀字符的越来越多,选择度也在不断上升,但是增长到 第 15 时,已经和第 14 没太大差别了,选择性提升的幅度已经很小了,都非常接近整个列的选择性了。
那么针对这个字段做前缀索引的话,从第 13 到第 15 都是不错的选择,甚至第 12 也不是不能考虑。当然不找到最常见的值的列表,直接计算前缀字符选择性也是可以的。
在上面的示例中,已经找到了合适的前缀长度,如何创建前缀索引:
:::tips
ALTER TABLE order_exp ADD KEY (order_note(14));
:::
建立前缀索引后查询语句并不需要更改:
select from order_exp where order_note = ‘xxxx’ ;
前缀索引是一种能使索引更小、更快的有效办法,但另一方面也有其缺点。MySQL 无法使用前缀索引做 ORDER BY 和 GROUP BY,也无法使用前缀索引做覆盖扫描。
有时候*后缀索引 (suffix index)也有用途(例如,找到某个域名的所有电子邮件地址)。MySQL 原生并不支持反向索引,但是可以把字符串反转后存储,并基于此建立前缀索引。可以通过触发器或者应用程序自行处理来维护索引。

若有收获,就点个赞吧
0 人点赞
