本文档来源于https://wmathor.com/index.php/archives/1455/。在此基础上整理修改而成。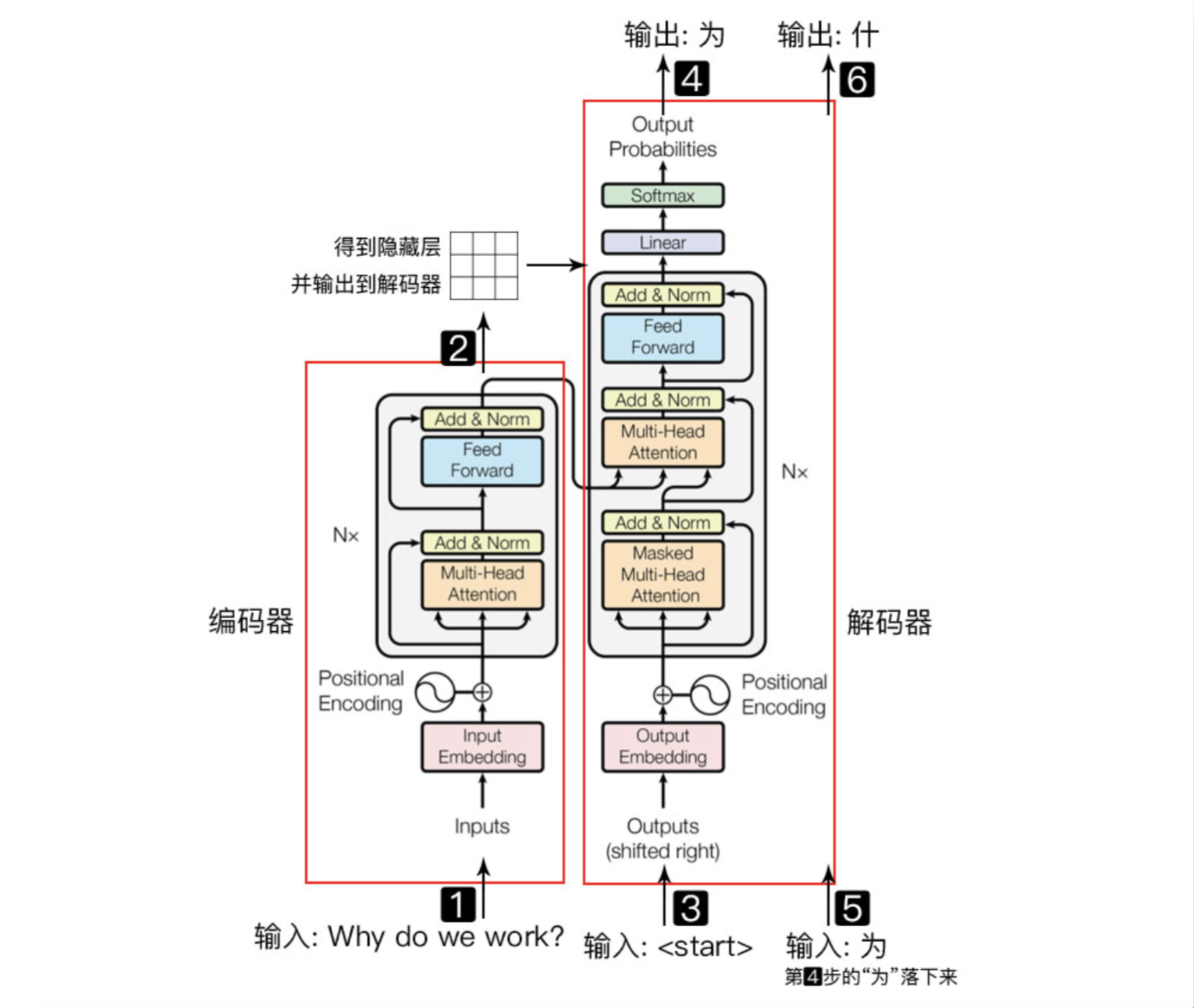
Encoder结构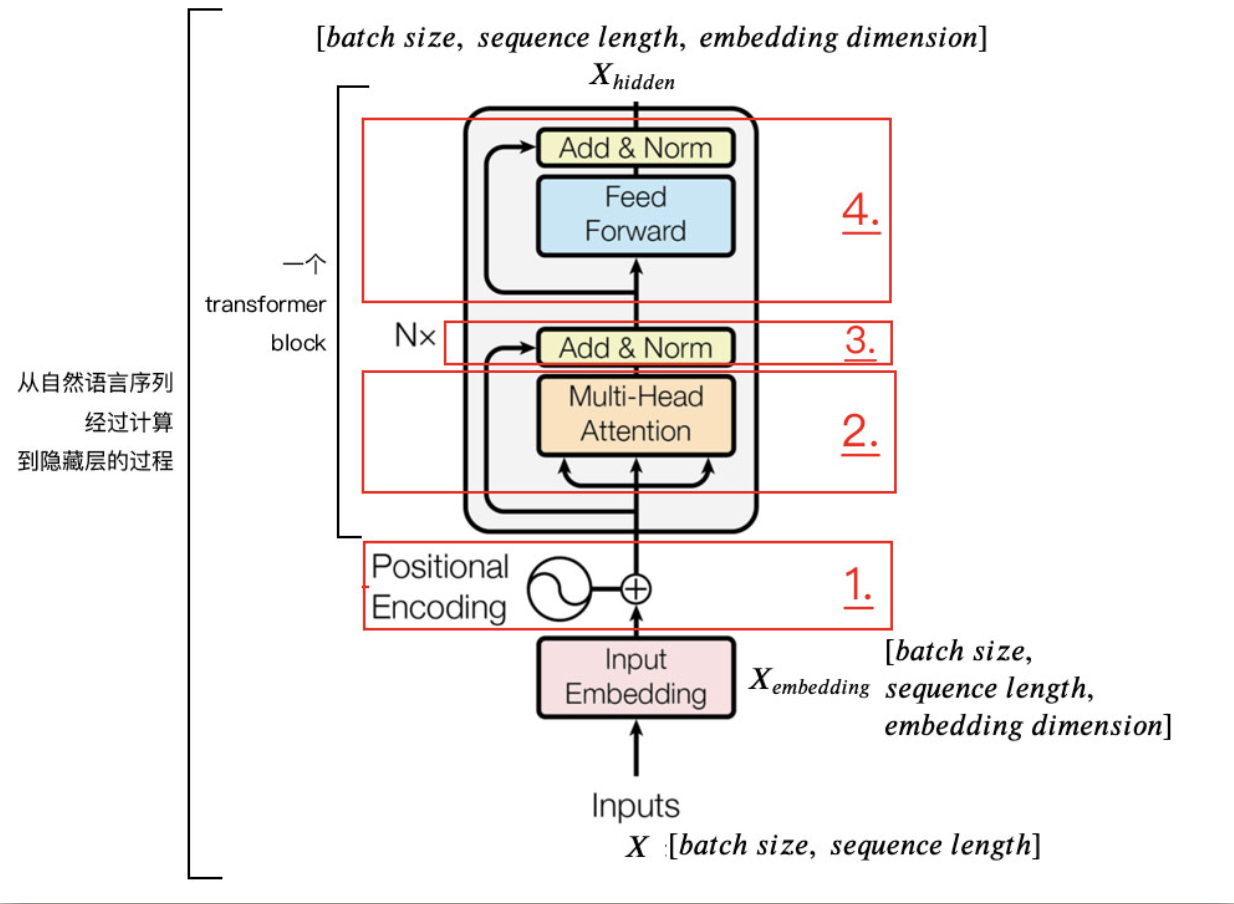
定义一些参数
d_model = 512 # Embedding Sized_ff = 2048 # FeedForward dimensiond_k = d_v = 64 # dimension of K(=Q), Vn_layers = 6 # number of Encoder of Decoder Layern_heads = 8 # number of heads in Multi-Head Attention
- Position Encoding

pos范围从[0,max_seq_len)
i范围从[0,embedding_dim/2)
class PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model) # [max_len, d_model]position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1]div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # [d_model/2]pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1) # [max_len, 1, d_model]self.register_buffer('pe', pe)def forward(self, x):'''x: [seq_len, batch_size, d_model]'''x = x + self.pe[:x.size(0), :]return self.dropout(x)
- Pad Mask
在Encoder和Decoder中都会mask。返回一个布尔类型的tensor。
def get_attn_pad_mask(seq_q, seq_k):'''seq_q: [batch_size, seq_len]seq_k: [batch_size, seq_len]seq_len could be src_len or it could be tgt_lenseq_len in seq_q and seq_len in seq_k maybe not equal'''batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# eq(zero) is PAD tokenpad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is maskedreturn pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
- Subsequence Mask
在Decoder中出现,主要是屏蔽未来时刻单词信息。np.triu()表示生成一个上对角线矩阵。k=1表示上移1个对角线。
def get_attn_subsequence_mask(seq):'''seq: [batch_size, tgt_len]'''attn_shape = [seq.size(0), seq.size(1), seq.size(1)]subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrixsubsequence_mask = torch.from_numpy(subsequence_mask).byte()return subsequence_mask # [batch_size, tgt_len, tgt_len]
- ScaledDotProductAttention

将进行mask的部分赋值为-1e9,进行softmax之后变为0。
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V, attn_mask):'''Q: [batch_size, n_heads, len_q, d_k]K: [batch_size, n_heads, len_k, d_k]V: [batch_size, n_heads, len_v(=len_k), d_v]attn_mask: [batch_size, n_heads, seq_len, seq_len]'''scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.attn = nn.Softmax(dim=-1)(scores)context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]return context, attn
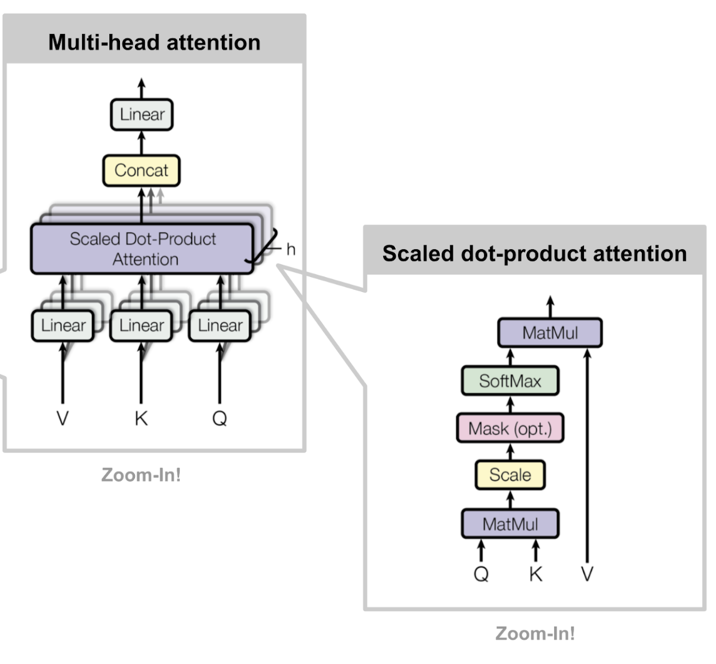
- MultiHeadAttention
定义多组Q,K,V矩阵,每组得到一个Z。
代码有三处会调用MultiHeadAttention。
Encoder Layer调用一次,传入的input_Q,input_K,input_V均为enc_inputs。
Decoder Layer调用两次,第一次传入的input_Q,input_K,input_V均为dec_inputs,第二次传入的分别是dec_outputs,enc_outputs,enc_outputs。
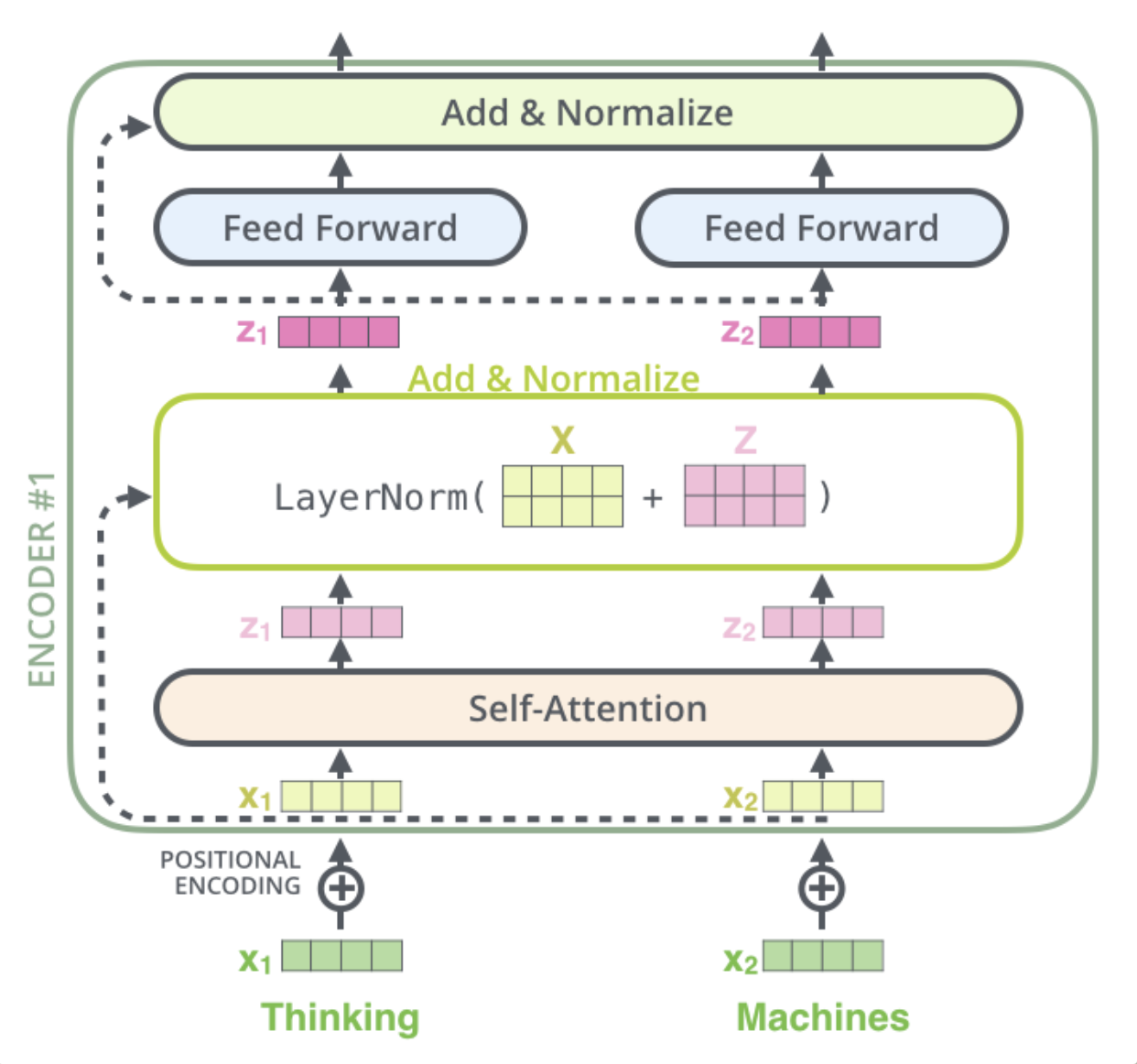
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)def forward(self, input_Q, input_K, input_V, attn_mask):'''input_Q: [batch_size, len_q, d_model]input_K: [batch_size, len_k, d_model]input_V: [batch_size, len_v(=len_k), d_model]attn_mask: [batch_size, seq_len, seq_len]'''residual, batch_size = input_Q, input_Q.size(0)# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]output = self.fc(context) # [batch_size, len_q, d_model]return nn.LayerNorm(d_model)(output + residual), attn
- FeedForward Layer
```python
class PoswiseFeedForwardNet(nn.Module):
def init(self):
def forward(self, inputs):super(PoswiseFeedForwardNet, self).__init__()self.fc = nn.Sequential(nn.Linear(d_model, d_ff, bias=False),nn.ReLU(),nn.Linear(d_ff, d_model, bias=False))
''' inputs: [batch_size, seq_len, d_model] ''' residual = inputs output = self.fc(inputs) return nn.LayerNorm(d_model)(output + residual) # [batch_size, seq_len, d_model]
- Encoder Layer
```python
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
'''
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
Encoder
class Encoder(nn.Module): def __init__(self): super(Encoder, self).__init__() self.src_emb = nn.Embedding(src_vocab_size, d_model) self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) def forward(self, enc_inputs): ''' enc_inputs: [batch_size, src_len] ''' enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model] enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model] enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len] enc_self_attns = [] for layer in self.layers: # enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len] enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) enc_self_attns.append(enc_self_attn) return enc_outputs, enc_self_attnsEncoder整体结构

- Decoder整体结构
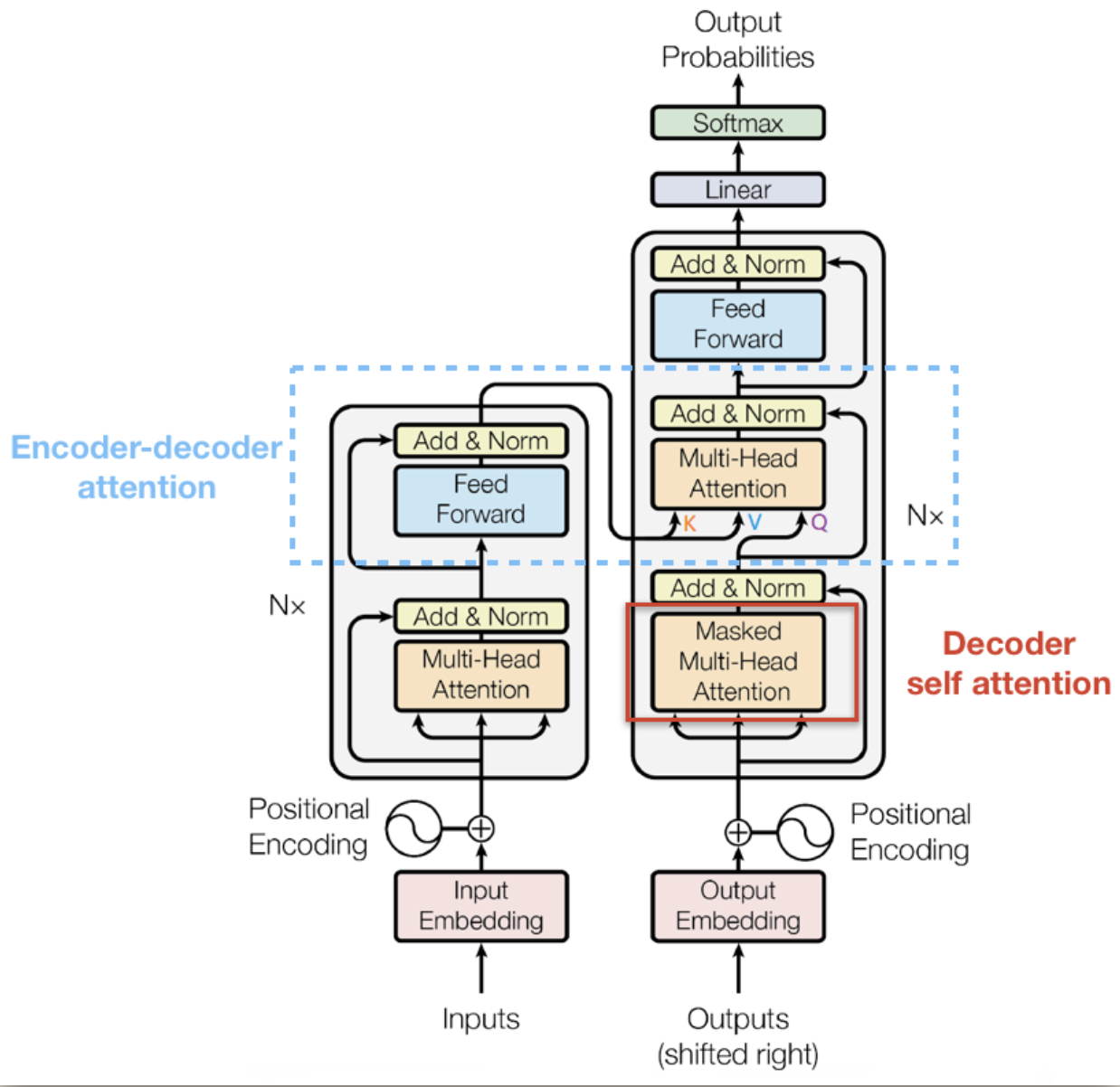
Decoder Layer
class DecoderLayer(nn.Module): def __init__(self): super(DecoderLayer, self).__init__() self.dec_self_attn = MultiHeadAttention() self.dec_enc_attn = MultiHeadAttention() self.pos_ffn = PoswiseFeedForwardNet() def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): ''' dec_inputs: [batch_size, tgt_len, d_model] enc_outputs: [batch_size, src_len, d_model] dec_self_attn_mask: [batch_size, tgt_len, tgt_len] dec_enc_attn_mask: [batch_size, tgt_len, src_len] ''' # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len] dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len] dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask) dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model] return dec_outputs, dec_self_attn, dec_enc_attnDecoder
class Decoder(nn.Module): def __init__(self): super(Decoder, self).__init__() self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) self.pos_emb = PositionalEncoding(d_model) self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs, enc_inputs, enc_outputs): ''' dec_inputs: [batch_size, tgt_len] enc_intpus: [batch_size, src_len] enc_outputs: [batsh_size, src_len, d_model] ''' dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model] dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model] dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len] dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len, tgt_len] dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0) # [batch_size, tgt_len, tgt_len] dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len] dec_self_attns, dec_enc_attns = [], [] for layer in self.layers: # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len] dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask) dec_self_attns.append(dec_self_attn) dec_enc_attns.append(dec_enc_attn) return dec_outputs, dec_self_attns, dec_enc_attnsTransformers
最后dec_logits维度为[batch, tgt_len, tgt_vocab_size],取概率最大的单词。
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
'''
# tensor to store decoder outputs
# outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
- 数据 ```python import math import torch import numpy as np import torch.nn as nn import torch.optim as optim import torch.utils.data as Data
S: Symbol that shows starting of decoding input
E: Symbol that shows starting of decoding output
P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
Padding Should be Zero
src_vocab = {‘P’ : 0, ‘ich’ : 1, ‘mochte’ : 2, ‘ein’ : 3, ‘bier’ : 4, ‘cola’ : 5} src_vocab_size = len(src_vocab)
tgt_vocab = {‘P’ : 0, ‘i’ : 1, ‘want’ : 2, ‘a’ : 3, ‘beer’ : 4, ‘coke’ : 5, ‘S’ : 6, ‘E’ : 7, ‘.’ : 8} idx2word = {i: w for i, w in enumerate(tgt_vocab)} tgt_vocab_size = len(tgt_vocab)
src_len = 5 # enc_input max sequence length tgt_len = 6 # dec_input(=dec_output) max sequence length
def make_data(sentences): enc_inputs, dec_inputs, dec_outputs = [], [], [] for i in range(len(sentences)): enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]] dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]] dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
class MyDataSet(Data.Dataset): def init(self, encinputs, decinputs, dec_outputs): super(MyDataSet, self).__init() self.enc_inputs = enc_inputs self.dec_inputs = dec_inputs self.dec_outputs = dec_outputs
def len(self): return self.enc_inputs.shape[0]
def getitem(self, idx): return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
- 建模
```python
model = Transformer().cuda()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
训练
for epoch in range(30): for enc_inputs, dec_inputs, dec_outputs in loader: ''' enc_inputs: [batch_size, src_len] dec_inputs: [batch_size, tgt_len] dec_outputs: [batch_size, tgt_len] ''' enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda() # outputs: [batch_size * tgt_len, tgt_vocab_size] outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs) loss = criterion(outputs, dec_outputs.view(-1)) print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss)) optimizer.zero_grad() loss.backward() optimizer.step()测试 ```python def greedy_decoder(model, enc_input, start_symbol): enc_outputs, enc_self_attns = model.encoder(enc_input) dec_input = torch.zeros(1, tgt_len).type_as(enc_input.data) next_symbol = start_symbol for i in range(0, tgt_len):
dec_input[0][i] = next_symbol dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs) projected = model.projection(dec_outputs) prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1] next_word = prob.data[i] next_symbol = next_word.item()return dec_input
Test
encinputs, , = next(iter(loader)) greedy_dec_input = greedy_decoder(model, enc_inputs[0].view(1, -1), start_symbol=tgt_vocab[“S”]) predict, , , = model(enc_inputs[0].view(1, -1), greedy_dec_input) predict = predict.data.max(1, keepdim=True)[1] print(enc_inputs[0], ‘->’, [idx2word[n.item()] for n in predict.squeeze()]) ```

若有收获,就点个赞吧
0 人点赞
