本文仅实现Negative Sampling的Skip-gram模型。文档参考https://wmathor.com/index.php/archives/1435/。
- Skip-gram图示
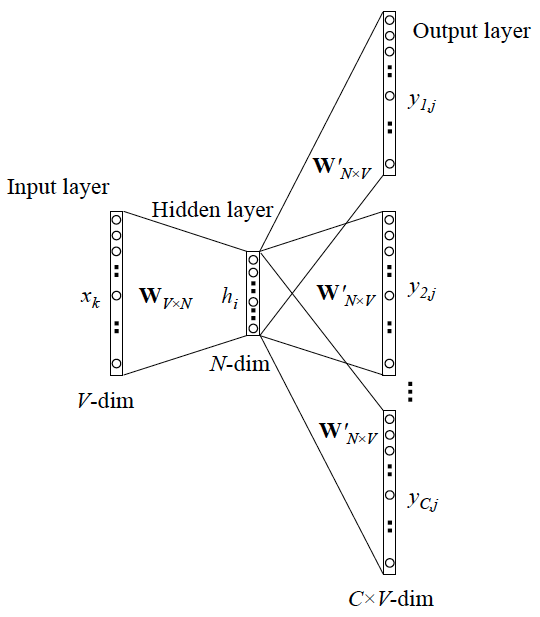

- Negative Sampling

- 代码
导包
import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.utils.data as tudfrom collections import Counterimport numpy as npimport randomimport scipyfrom sklearn.metrics.pairwise import cosine_similarityrandom.seed(1)np.random.seed(1)torch.manual_seed(1)C = 3 # context windowK = 15 # number of negative samplesepochs = 2MAX_VOCAB_SIZE = 10000EMBEDDING_SIZE = 100batch_size = 32lr = 0.2
处理数据
with open('text8.train.txt') as f:text = f.read() # 得到文本内容text = text.lower().split() # 分割成单词列表vocab_dict = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1)) # 得到单词字典表,key是单词,value是次数vocab_dict['<UNK>'] = len(text) - np.sum(list(vocab_dict.values())) # 把不常用的单词都编码为"<UNK>"word2idx = {word:i for i, word in enumerate(vocab_dict.keys())}idx2word = {i:word for i, word in enumerate(vocab_dict.keys())}word_counts = np.array([count for count in vocab_dict.values()], dtype=np.float32)word_freqs = word_counts / np.sum(word_counts)word_freqs = word_freqs ** (3./4.)class WordEmbeddingDataset(tud.Dataset):def __init__(self, text, word2idx, word_freqs):''' text: a list of words, all text from the training datasetword2idx: the dictionary from word to indexword_freqs: the frequency of each word'''super(WordEmbeddingDataset, self).__init__() # #通过父类初始化模型,然后重写两个方法self.text_encoded = [word2idx.get(word, word2idx['<UNK>']) for word in text] # 把单词数字化表示。如果不在词典中,也表示为unkself.text_encoded = torch.LongTensor(self.text_encoded) # nn.Embedding需要传入LongTensor类型self.word2idx = word2idxself.word_freqs = torch.Tensor(word_freqs)def __len__(self):return len(self.text_encoded) # 返回所有单词的总数,即item的总数def __getitem__(self, idx):''' 这个function返回以下数据用于训练- 中心词- 这个单词附近的positive word- 随机采样的K个单词作为negative word'''center_words = self.text_encoded[idx] # 取得中心词pos_indices = list(range(idx - C, idx)) + list(range(idx + 1, idx + C + 1)) # 先取得中心左右各C个词的索引pos_indices = [i % len(self.text_encoded) for i in pos_indices] # 为了避免索引越界,所以进行取余处理pos_words = self.text_encoded[pos_indices] # tensor(list)neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True)# torch.multinomial作用是对self.word_freqs做K * pos_words.shape[0]次取值,输出的是self.word_freqs对应的下标# 取样方式采用有放回的采样,并且self.word_freqs数值越大,取样概率越大# 每采样一个正确的单词(positive word),就采样K个错误的单词(negative word),pos_words.shape[0]是正确单词数量# while 循环是为了保证 neg_words中不能包含背景词while len(set(pos_indices.numpy().tolist()) & set(neg_words.numpy().tolist())) > 0:neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True)return center_words, pos_words, neg_wordsdataset = WordEmbeddingDataset(text, word2idx, word_freqs)dataloader = tud.DataLoader(dataset, batch_size, shuffle=True)
建立模型
注:对于任一一个词,它既有可能作为中心词出现,也有可能作为背景词出现,所以每个词需要用两个向量去表示。in_embed 训练出来的权重就是每个词作为中心词的权重。out_embed 训练出来的权重就是每个词作为背景词的权重。
class EmbeddingModel(nn.Module):def __init__(self, vocab_size, embed_size):super(EmbeddingModel, self).__init__()self.vocab_size = vocab_sizeself.embed_size = embed_sizeself.in_embed = nn.Embedding(self.vocab_size, self.embed_size)self.out_embed = nn.Embedding(self.vocab_size, self.embed_size)def forward(self, input_labels, pos_labels, neg_labels):''' input_labels: center words, [batch_size]pos_labels: positive words, [batch_size, (window_size * 2)]neg_labels:negative words, [batch_size, (window_size * 2 * K)]return: loss, [batch_size]'''input_embedding = self.in_embed(input_labels) # [batch_size, embed_size]pos_embedding = self.out_embed(pos_labels)# [batch_size, (window * 2), embed_size]neg_embedding = self.out_embed(neg_labels) # [batch_size, (window * 2 * K), embed_size]input_embedding = input_embedding.unsqueeze(2) # [batch_size, embed_size, 1]pos_dot = torch.bmm(pos_embedding, input_embedding) # [batch_size, (window * 2), 1]pos_dot = pos_dot.squeeze(2) # [batch_size, (window * 2)]neg_dot = torch.bmm(neg_embedding, -input_embedding) # [batch_size, (window * 2 * K), 1]neg_dot = neg_dot.squeeze(2) # batch_size, (window * 2 * K)]log_pos = F.logsigmoid(pos_dot).sum(1) # .sum()结果只为一个数,.sum(1)结果是一维的张量log_neg = F.logsigmoid(neg_dot).sum(1)loss = log_pos + log_negreturn -lossdef input_embedding(self):return self.in_embed.weight.detach().numpy()model = EmbeddingModel(MAX_VOCAB_SIZE, EMBEDDING_SIZE)optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
训练
for e in range(1):for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):input_labels = input_labels.long()pos_labels = pos_labels.long()neg_labels = neg_labels.long()optimizer.zero_grad()loss = model(input_labels, pos_labels, neg_labels).mean()loss.backward()optimizer.step()if i % 100 == 0:print('epoch', e, 'iteration', i, loss.item())embedding_weights = model.input_embedding()torch.save(model.state_dict(), "embedding-{}.th".format(EMBEDDING_SIZE))
应用:查找最相似的词
def find_nearest(word):index = word2idx[word]embedding = embedding_weights[index]cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])return [idx2word[i] for i in cos_dis.argsort()[:10]]

若有收获,就点个赞吧
0 人点赞
