- 论文题目
Deep contextualized word representations
- feature-based和fine-tuning
feature-based是在大规模语料上训练语言模型,训练完毕得到语言模型用作embedding,构造task-specific模型,采用有label的语料训练模型,将语言模型参数固定。Elmo属于feature-based。
fine-tuning是在大规模语料上训练语言模型,在语言模型基础上添加少量神经网络层完成下游任务。语言模型的参数不固定。
- 双向语言模型

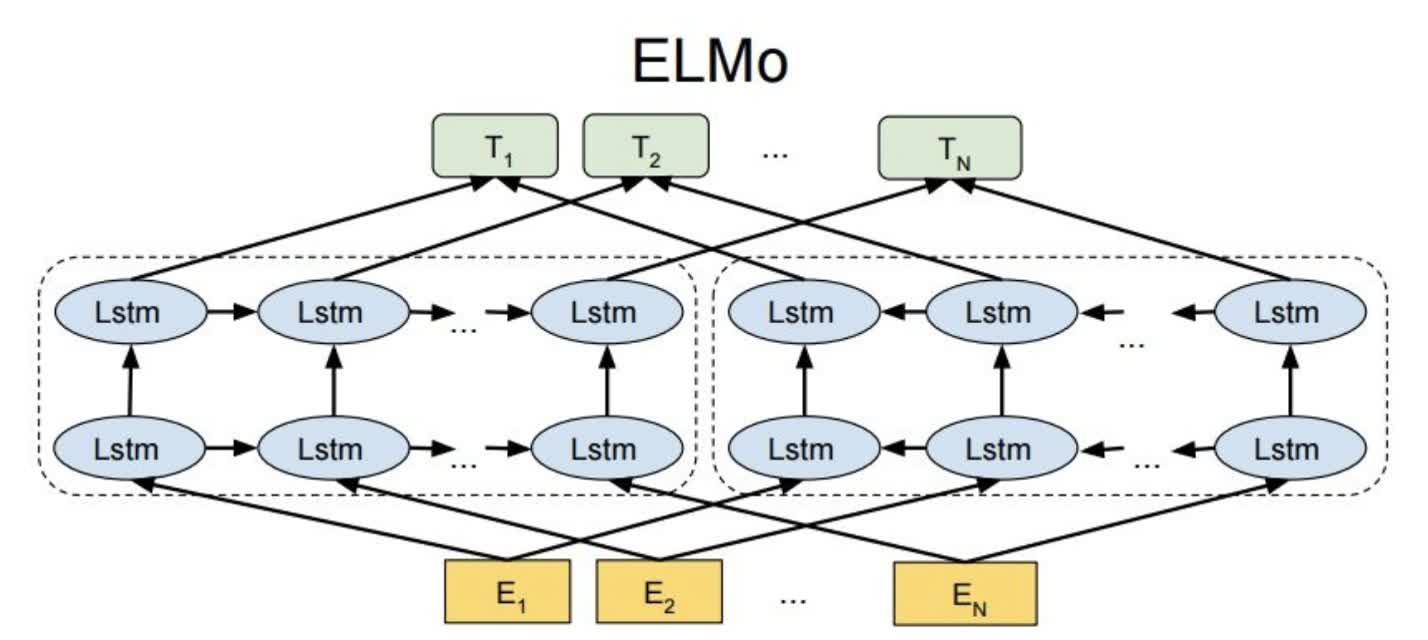
- 损失函数

- 使用Elmo

每层的forward和backward的hidden_layer进行concat。
concat的vector乘以学习到的weight。
最后的向量进行求和。
获取预训练的embedding。
freeze预训练模型的weights,进行下游任务。

若有收获,就点个赞吧
0 人点赞
