CDC 是什么
CDC 是 Change Data Capture(数据库变更捕获) 的缩写,目前我们所说的 CDC 主要是捕获数据库的变更,但广义上的 Flink CDC 是捕获数据变更记录。Flink CDC Connectors 集成了 Debezium 作为引擎来捕捉数据变化,,当前 CDC 的应用场景主要分为以下三个:
- 数据同步:主要用于备份,容灾
- 数据分发:发送数据到下游系统/数据源
- 数据采集:数仓/数据湖的数据集成及 ETL
CDC 的实现原理
CDC 实现机制大致可以分为两类:
- 基于查询的 CDC
查询 CDC 即每次主动查询数据库,通过数据库中的更新时间或者版本号,在下游与上次获取的数据做对比,判断数据是否同步及是否需要同步,主要用于离线调度的批处理。这种方式的
- 优点
- 不涉及数据库底层的特性
- 实现比较通用
- 缺点
- 实时性不高,批处理存在天然的延迟
- 数据一致性无法保证,不能确保跟踪到每一条数据
- 频繁查询对数据库的压力过大
- 需要侵入业务,如需要增加更新时间
- 基于日志的 CDC
基于日志的 CDC 即是通过触发器(Tiger) 或者日志(binlog) 实现,当数据源发生变动是,可以实时捕捉,下游可以基于数据库底层协议。订阅消费这些事件以及在ETL时重放数据变动操作
- 优点
- 实时性高,可实时消费 binlog
- 保证数据一致性,binlog 记录了数据库所有的变动
- 无需入侵业务,业务解耦,无需更改业务模型
- 缺点
- 有一定的学习&运维成本,需要部署数据库的事件接收和解析器(例如 Debezium、Canal 等)
- 目前对一些冷门的数据库不支持
基于查询的 CDC 与 基于日志的 CDC 功能差异点对比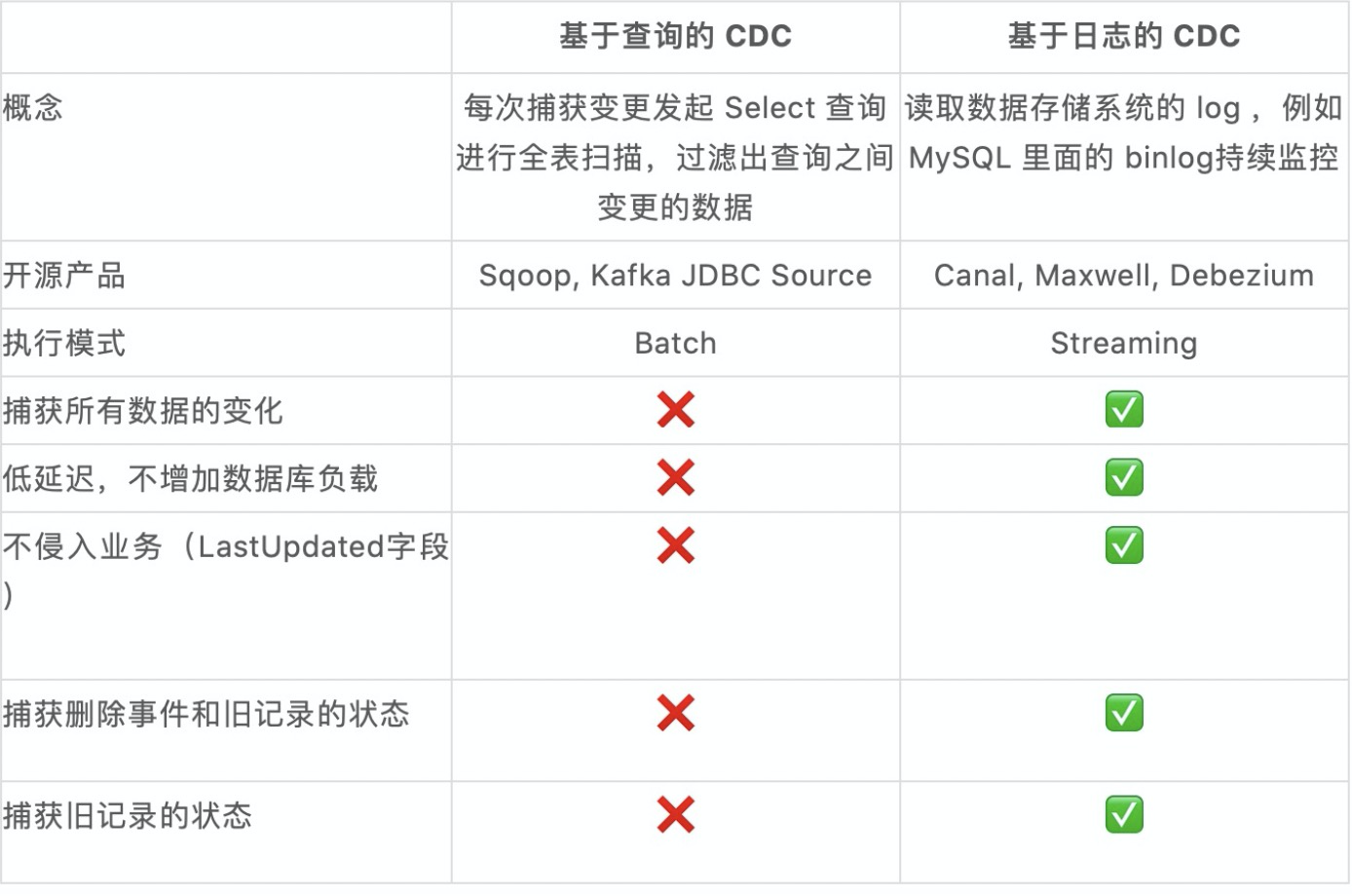
从上图功能点对比可知选择 日志 CDC 的原因有以下几点
- 能够捕获所有数据的变化,捕获完整的变更记录。在异地容灾,数据备份等场景中得到广泛应用,如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失
- 每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤,拥有更高的效率和性能,具有低延迟,不增加数据库负载的优势
- 无需入侵业务,业务解耦,无需更改业务模型
- 捕获删除事件和捕获旧记录的状态,在查询 CDC 中,周期的查询无法感知中间数据是否删除
常用的 CDC 比较
1.功能上
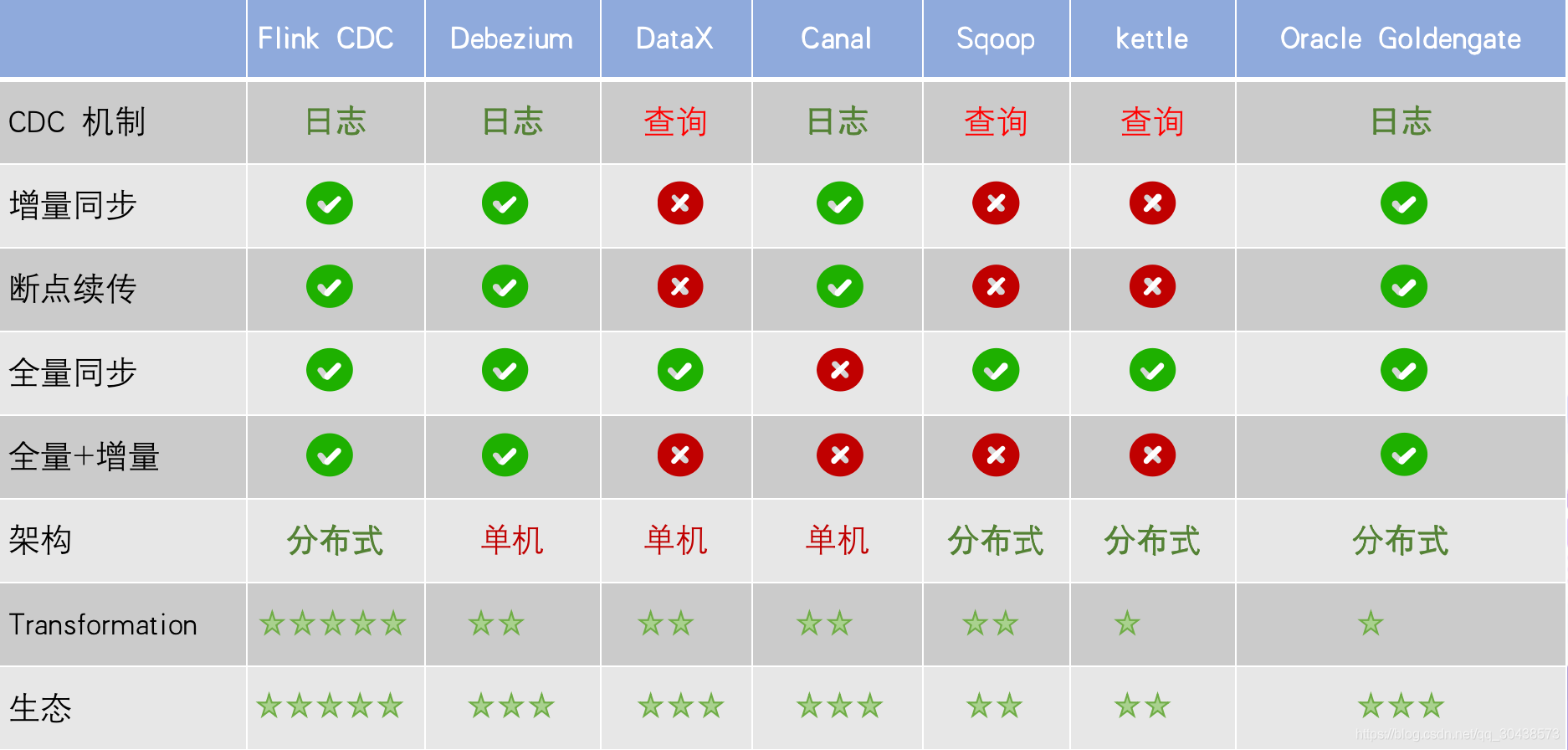
- 增量同步
- 基于日志的 CDC 可以很容易做到增量同步
- 基于查询的 CDC 很难做到增量同步 CDC
- 全量同步: 查询 CDC 和日志 CDC都支持,除了cancal
- 全量 + 增量:只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
- 架构:架构能力分为分布式与单机,不当当对比他们的水平扩展能力,还需要对比大数据场景下分布式接入能力,如当下游是 Hive,HDFS时 CDC的接入能力,上图看出 FLink CDC能很好的支持
- 数据处理(Transformmation):CDC 是否能方便的对数据做清洗,过滤,FLink CDC能通过 Sql 直接处理,但是像 Debezium,cancal 则需要通过模版或者脚本来实现,增加使用者的使用门槛及学习成本
- 生态:指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector
2.使用上
- 传统 CDC
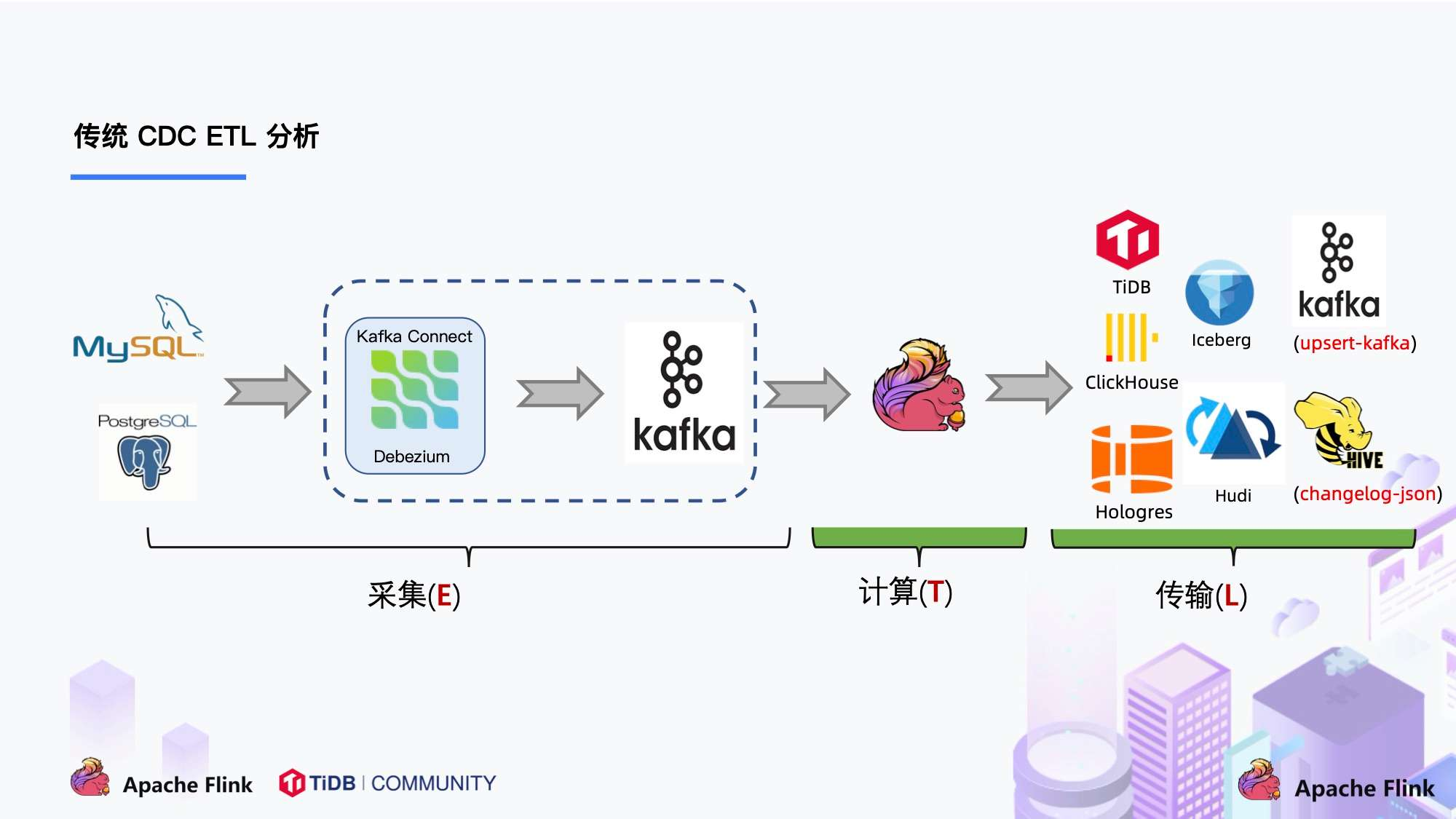
传统 CDC 在在 ETL 分析中主要负责数据库的数据采集的链路,国外常用的采集为 Debezium,而国内主要以阿里开源的 Canal 为主。图上可以看出主要的流程为 CDC 采集数据库数据 —> 写入 Kafka —> Flink 消费 Kafak —> 写入数据湖/数仓。以上链路可以看出在数据采集这一步的链路较长,越长的链路代表学习和运维成本较高。这时候有人就会想,那能不能通过 Flink 将途中虚线部分替换呢?
答案是:有的! Flink 社区就基于这一点开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件
- Flink CDC
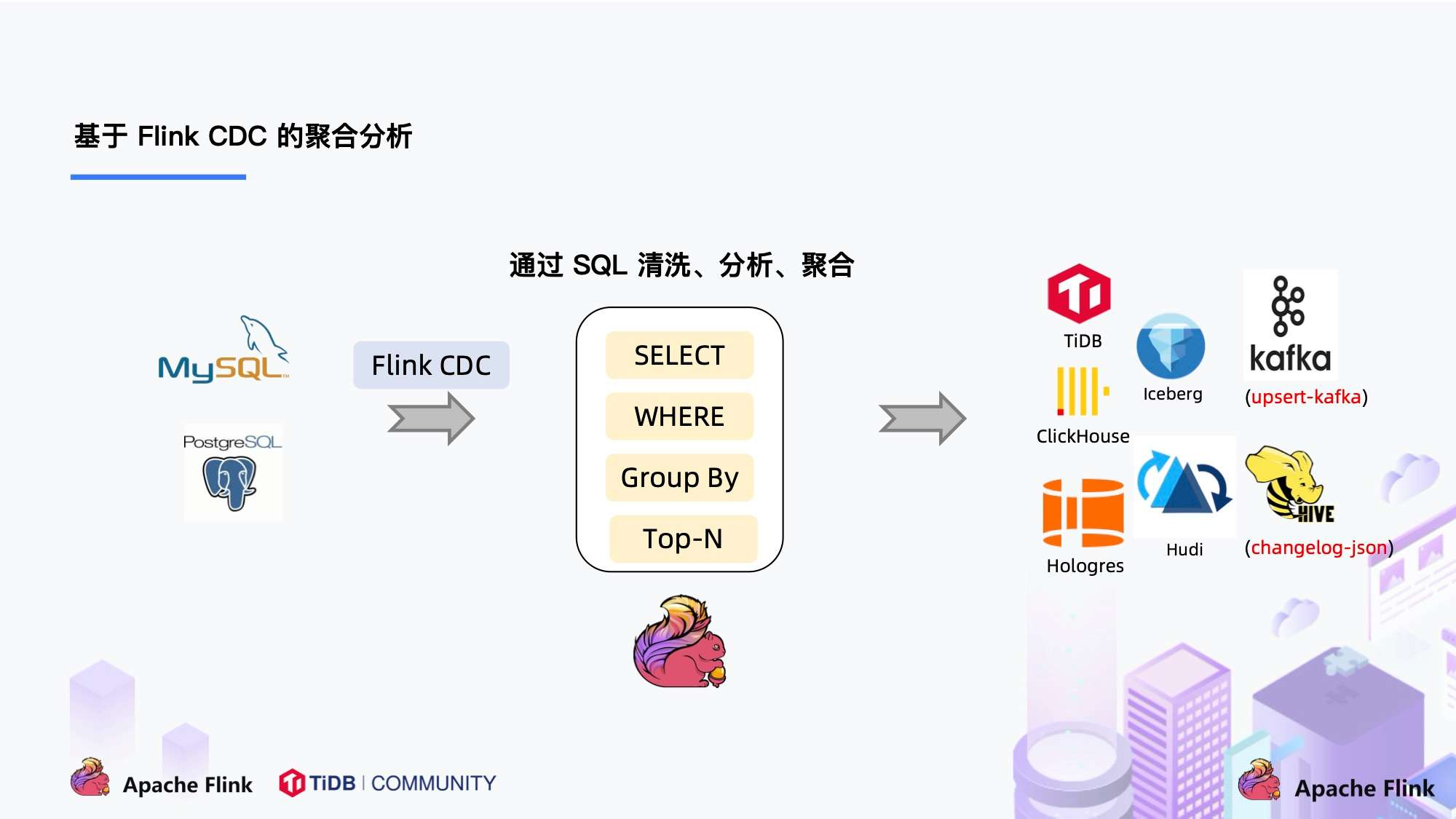
Flink CDC 替换了 Debezium + Kafka ,使用 Flink CDC ,除了组件更少了,另一个很大的优势是 用户可以通过 Flink SQL 直接对数据流做逻辑处理,使Flink SQL 实现采集,清洗,传输(ETL)一体化
flink-cdc-connectors 组件开源地址:
Flink CDC 原理

若有收获,就点个赞吧
0 人点赞
