概述
DataSource 顾名思义就是数据源,Flink 官方提供了多种数据获取方式,用于帮助开发者简单的快速的构建输入流。
在 Flink 中 可以使用StreamExecutionEnvironment._getExecutionEnvironment_().addSource(SourceFunction) 来添加数据源,当然,你也可以通过自己定义 SourceFunction 来自自定义 source ,目前 Flink 提供两种自定义的SourceFunction :
- 非并行:定义 SourceFunction 实现非并行的 source
- 并行:通过实现ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source
内置Data Source
StreamExcutionEnvironment 已实现的数据源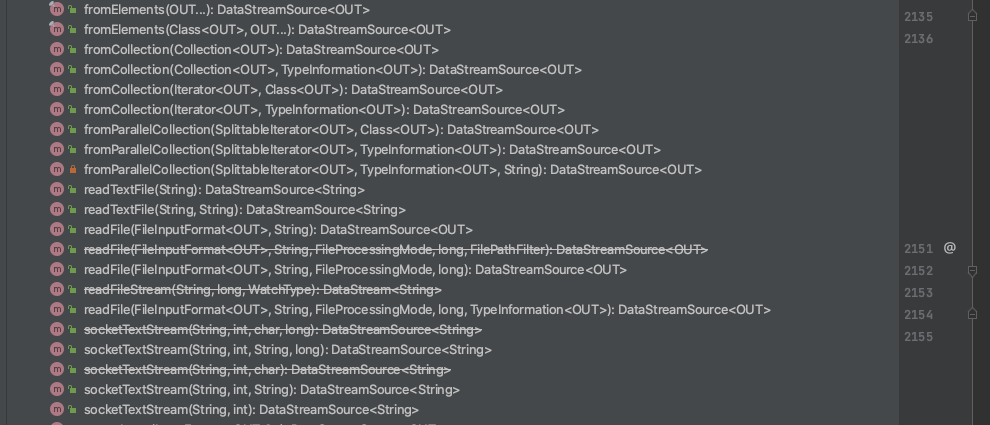
1.基于 Socket
socketTextStream 方法用于构建 Socket 的数据流,socketTextStream 有以下四个参数
- hostname: 主机名;
- port: 端口号,设置为 0 时,表示端口号自动分配;
- delimiter:分隔符,用于分隔每条记录的分隔符;
- maxRetry:程序的最大重试间隔,当 Socket 临时关闭时,程序的最大重试间隔,单位为秒。设置为 0 时表示不进行重试;设置为负值则表示一直重试
示例如下:
import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class socketTest throws Exception{public static void main(String[] args) {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> dataStream = env.socketTextStream("localhost", 9999,"/n",3); // 监听 localhost 的 9999 端口过来的数据,分隔符为"\n",最大重试间隔为3senv.print();env.excute("socketTest");}}
2.基于集合
Flink 基于集合构建有几种方式,如下:
fromCollection(Collection):基于集合构建,集合中的所有元素必须是同一类型。fromElements(T …): 基于元素构建,从给定的对象序列中创建数据流。所有对象类型必须相同。fromCollection(Iterator, Class):从一个迭代器中创建数据流,Iterator 为迭代器,Class 指定了该迭代器返回元素的类型。fromParallelCollection(SplittableIterator, Class): 从一个迭代器中创建并行数据流,SplittableIterator 是迭代器的抽象基类,它用于将原始迭代器的值拆分到多个不相交的迭代器中,Class 指定了该迭代器返回元素的类型。generateSequence(from, to):创建一个生成指定区间范围内的数字序列的并行数据流。
使用示例如下:
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.util.NumberSequenceIterator;import java.util.*;public class collectionTest {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 基于集合构建,集合中的所有元素必须是同一类型。DataStream<Integer> ds1 = env.fromCollection(Arrays.asList(1,2,3,4,5,6));ds1.print();// 基于元素构建,从给定的对象序列中创建数据流。所有对象类型必须相同DataStream<Integer> ds2 = env.fromElements(1,2,3,4,5,6);ds2.print();// 从一个迭代器中创建数据流,Iterator 为迭代器,Class 指定了该迭代器返回元素的类型。DataStream<Integer> ds3 = env.fromCollection(new testIterator(),BasicTypeInfo.INT_TYPE_INFO);ds3.print();// 从一个迭代器中创建并行数据流,SplittableIterator 是迭代器的抽象基类,它用于将原始迭代器的值拆分到多个不相交的迭代器中,Class 指定了该迭代器返回元素的类型。DataStream<Long> ds4 = env.fromParallelCollection(new NumberSequenceIterator(1L,10L),BasicTypeInfo.LONG_TYPE_INFO);ds4.print();//创建一个生成指定区间范围内的数字序列的并行数据流。DataStream<Long> ds5 = env.generateSequence(1,100);ds5.print();env.execute("collectionTest");}}
testIterator 为自己定义的迭代器,我们以产生0-10区间内的数据为例,需要注意的是这里的自定义迭代器除了实现 Iterator 接口外,还需要实现序列化接口 Serializable 否则会抛出序列化失败异常(xxx is not serializable):
import java.io.Serializable;import java.util.Iterator;public class testIterator implements Iterator<Integer>, Serializable {private Integer i = 0;@Overridepublic boolean hasNext() {return i<10;}@Overridepublic Integer next() {i++;return i;}}
3.基于文件
readTextFile(filePath): 读取符合 TextInputFormat 规范的文本文件,并将其作为字符串返回。readTextFile(String filePath, String charsetName): filePath 文件名称,charsetName:读取文件的字符集名称,如UTF-8readFile(fileInputFormat, path):按照指定格式读取文件。readFile(inputFormat, filePath, watchType, interval, typeInformation):按照指定格式周期性的读取文件。其中各个参数的含义如下:- inputFormat:输入的数据流格式。
- filePath:文件路径,可以是本地文件系统上的路径,也可以是 HDFS 上的文件路径。
- watchType:读取方式,它有两个可选值
- FileProcessingMode.PROCESS_ONCE :指定路径上的数据只读取一次,然后退出;
- FileProcessingMode.PROCESS_CONTINUOUSLY:路径进行定期地扫描和读取。 设置这个值需要注意当文件被修改时,其所有的内容 (包含原有的内容和新增的内容) 都将被重新处理,因此这会打破 Flink 的 exactly-once 语义。
- interval:定期扫描的时间间隔(以毫秒为单位)。
- typeInformation:输入流中元素的类型
使用示例:
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;import org.apache.flink.api.java.io.TextInputFormat;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.core.fs.Path;import static org.apache.flink.streaming.api.functions.source.FileProcessingMode.PROCESS_CONTINUOUSLY;public class readFileTest {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 读取为本地文件DataStream<String> fileStream = env.readFile(new TextInputFormat(new Path(myFilePath) //获取数据流格式,myFilePath //文件路径,PROCESS_CONTINUOUSLY //读取方式,100 //定期扫描的时间间隔,这里设置为100毫秒,BasicTypeInfo.STRING_TYPE_INFO //输入流中元素的类型);fileStream.print();env.execute("readFileTest");}}
自定义source
如果想自定义 source 需要怎么做?
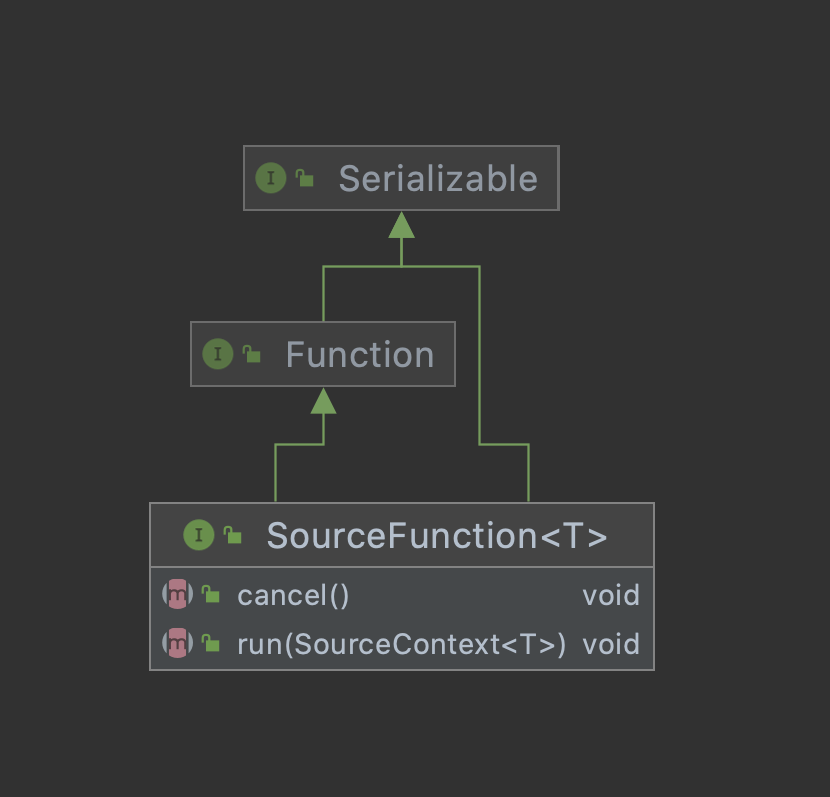
自定义 source 首先需要去了解下SourceFunction 接口了,它继承自一个标记接口(空接口)Function。
下图可以看到 SourceFunction 定义了两个接口方法:
- run:启动一个 source,即对接一个外部数据源然后发送元素形成 stream(大部分情况下会通过在该方法里运行一个 while 循环的形式来产生 stream)
- cancle:取消一个 source,也即将 run 中的循环 emit 元素的行为终止
话不多说,上代码:
import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.functions.source.SourceFunction;public class mySourceFunction {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Integer> mySource = env.addSource(new SourceFunction<Integer>() {private Integer count = 0;private volatile boolean isRunning = true;@Overridepublic void run(SourceContext<Integer> ctx) throws Exception {while(isRunning && count<=100){// 通过collect将输入发送出去ctx.collect(count);count++;}}@Overridepublic void cancel() {isRunning=false;}});mySource.print();env.execute("mySourceFunction");}}
前面说到 SourceFunction 实现的数据源是不具备并行度的,如果想实现并行度的输入流,则需要实现 ParallelSourceFunction 或 RichParallelSourceFunction 接口。
所以这里需要注意使用SourceFunction实现的数据源,在DataStream 上不能调用 setParallelism(n) 方法,否则会抛出如下异常:Exception in thread "main" java.lang.IllegalArgumentException: The parallelism of non parallel operator must be 1. ParallelSourceFunction 或 RichParallelSourceFunction 接口,其与 SourceFunction 的关系如下图: 的关系如下图:
ParallelSourceFunction 或 RichParallelSourceFunction 接口,其与 SourceFunction 的关系如下图: 的关系如下图: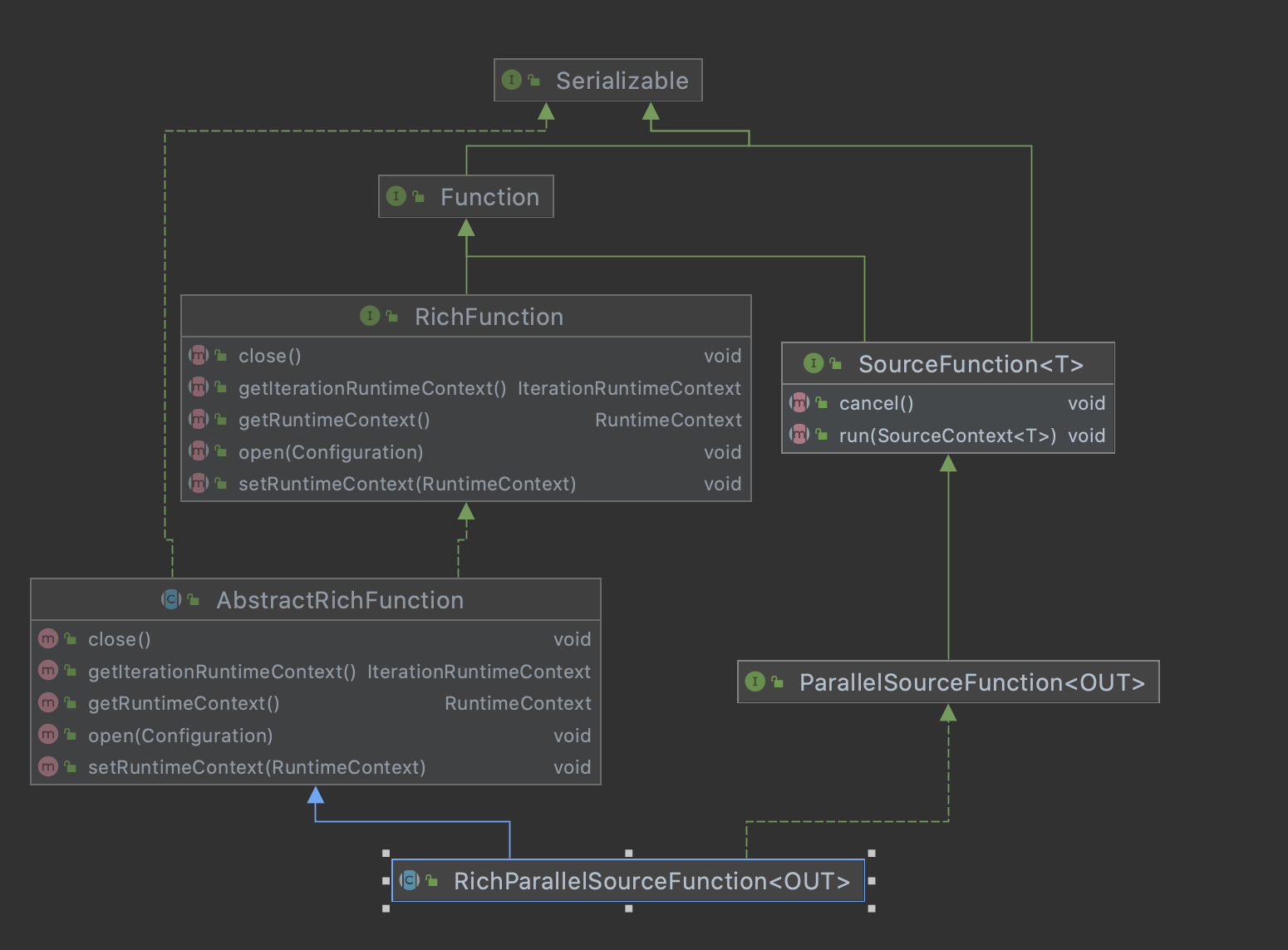
ParallelSourceFunction 继承了 SourceFunction 接口,但是他没有其他额外的方法,仅仅只是用接口表明了自己是可以并行执行的 stream data source
AbstractRichFunction 只有默认的生命周期方法 open() 和 close() 的空实现
RichParallelSourceFunction 实现了ParallelSourceFunction 同时继承了AbstractRichFunction,所以其既有并行度的功能,也有生命周期的功能
Flink 内置连接器
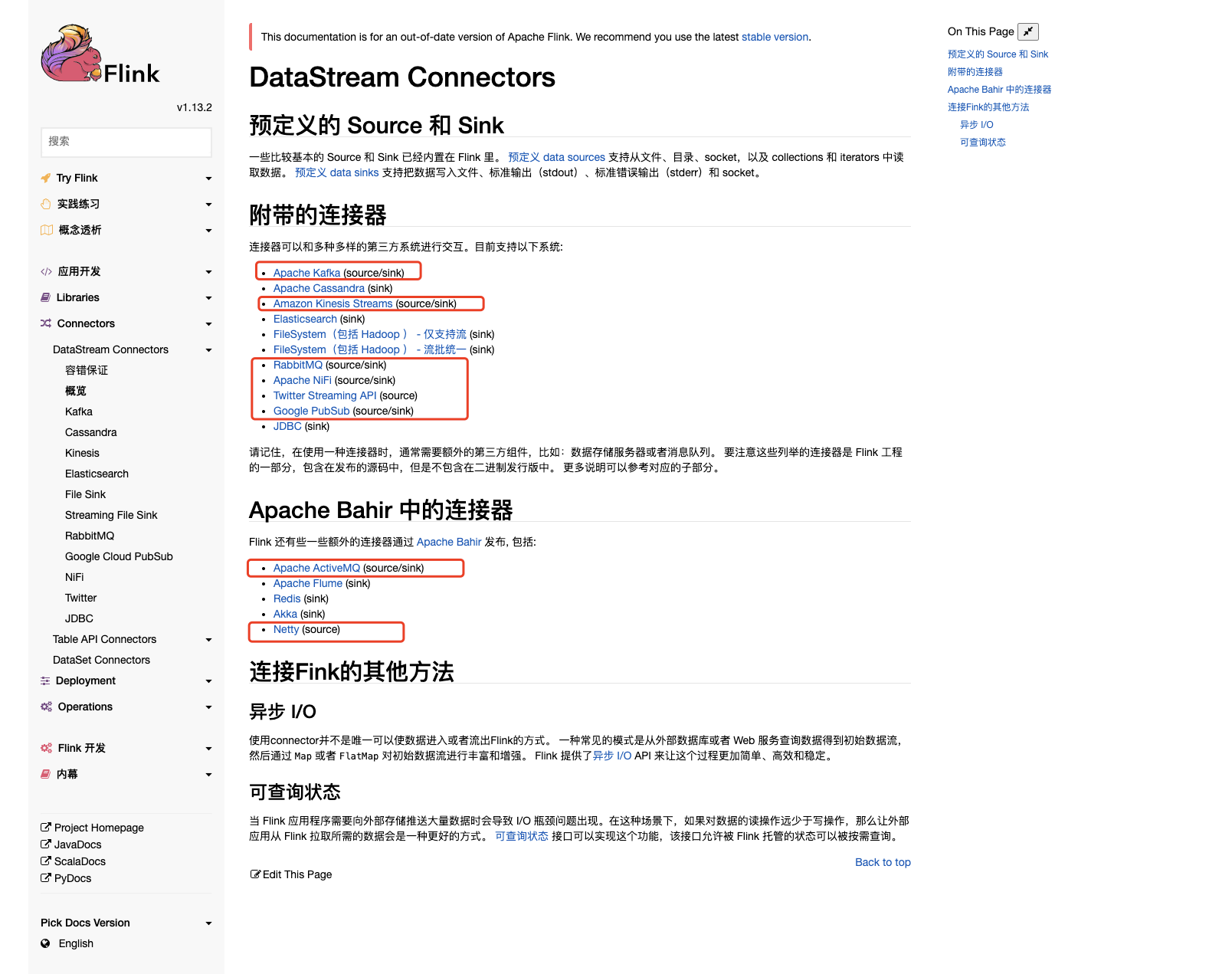
Flink 已经实现了多种连接器,用于满足大多数的数据收集场景。当前内置连接器的支持情况如下:
- Apache Kafka (支持 source 和 sink)
- Apache Cassandra (sink)
- Amazon Kinesis Streams (source/sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache NiFi (source/sink)
- Twitter Streaming API (source)
- Google PubSub (source/sink)
除了上述的连接器外,你还可以通过 Apache Bahir 的连接器扩展 Flink。Apache Bahir 旨在为分布式数据分析系统 (如 Spark,Flink) 等提供功能上的扩展,当前其支持的与 Flink 相关的连接器如下:
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
目前比较常用的 source 连接器是 kafka connection ,所以,这里我们以 kafka 为例,写一个自定义连接器
Kafka 连接器 Demo
Kafka 依赖
注意:使用 Kafka 连接器需要关注 Kafka 的版本,不同版本间所需的 Maven 依赖和开发时所调用的类均不相同,具体如下:
| Maven 依赖 | 自从哪个版本开始支持 | 消费者和生产者的类名称 | Kafka 版本 | 注意 |
|---|---|---|---|---|
| flink-connector-kafka-0.8_2.11 | 1.0.0 | FlinkKafkaConsumer08 FlinkKafkaProducer08 | 0.8.x | 这个连接器在内部使用 Kafka 的 SimpleConsumer API。偏移量由 Flink 提交给 ZK。 |
| flink-connector-kafka-0.9_2.11 | 1.0.0 | FlinkKafkaConsumer09 FlinkKafkaProducer09 | 0.9.x | 这个连接器使用新的 Kafka Consumer API |
| flink-connector-kafka-0.10_2.11 | 1.2.0 | FlinkKafkaConsumer010 FlinkKafkaProducer010 | 0.10.x | 这个连接器支持 带有时间戳的 Kafka 消息 ,用于生产和消费。 |
| flink-connector-kafka-0.11_2.11 | 1.4.0 | FlinkKafkaConsumer011 FlinkKafkaProducer011 | 0.11.x | Kafka 从 0.11.x 版本开始不支持 Scala 2.10。此连接器支持了 Kafka 事务性的消息传递 来为生产者提供 Exactly once 语义。 |
| flink-connector-kafka_2.11 | 1.7.0 | FlinkKafkaConsumer FlinkKafkaProducer | >= 1.0.0 | 这个通用的 Kafka 连接器尽力与 Kafka client 的最新版本保持同步。该连接器使用的 Kafka client 版本可能会在 Flink 版本之间发生变化。从 Flink 1.9 版本开始,它使用 Kafka 2.2.0 client。当前 Kafka 客户端向后兼容 0.10.0 或更高版本的 Kafka broker。 但是对于 Kafka 0.11.x 和 0.10.x 版本,我们建议你分别使用专用的 flink-connector-kafka-0.11_2.11 和 flink-connector-kafka-0.10_2.11 连接器。 |
Kafka 依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>1.12.1</version></dependency>
代码示例
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;import java.util.Properties;public class KafkaSourceDemo {public static final String broker_list = "localhost:9092";public static final String topic = "kafkaDemo";public static Properties properties;public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 指定Kafka的连接地址properties = new Properties();properties.setProperty("bootstrap.servers", broker_list);DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>(topic, new SimpleStringSchema(), properties));stream.print();env.execute("Kafka Source Demo");}}
Docker 安装kafka
这里使用docker 安装 kafka 和 zk 当然你也可以在本地环境安装kafka
version: '3.7'services:zookeeper:image: wurstmeister/zookeepercontainer_name: zkvolumes:- ./data:/dataports:- 2182:2181kafka9094:image: wurstmeister/kafkacontainer_name: kafkaports:- 9092:9092environment:KAFKA_BROKER_ID: 0KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.1.60:9092KAFKA_CREATE_TOPICS: "kafeidou:2:0" #kafka启动后初始化一个有2个partition(分区)0个副本名叫kafeidou的topicKAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092volumes:- ./kafka-logs:/kafkadepends_on:- zookeeper
创建kafka topic
# docker 使用 kafka 可能遇到问题比较多,这里按照我的docker写的kafka 生成topicbin/kafka-topics.sh --create --zookeeper zookeeper:2181/--topic kafkaDemo --replication-factor 1 --partitions 1# 本地bin/kafka-topics.sh --create --zookeeper localhost:2181/--topic kafkaDemo --replication-factor 1 --partitions 1

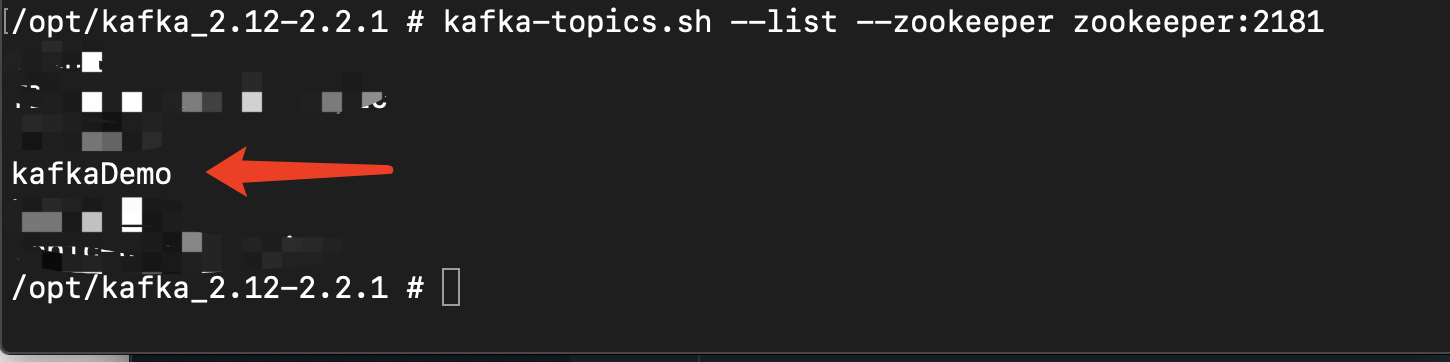
查看所有topic
# dockerbin/kafka-topics.sh --list --zookeeper zookeeper:2181# 本地bin/kafka-topics.sh --list --zookeeper localhost:2181
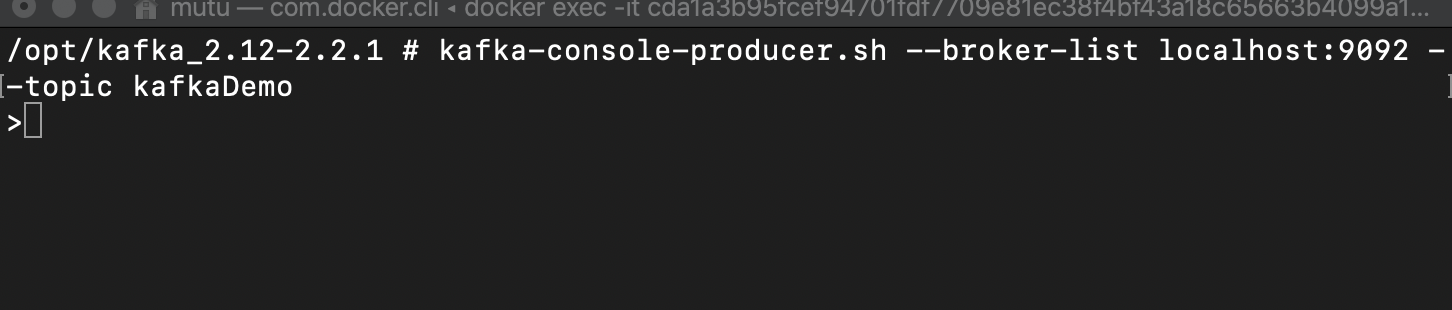
启动生产者
# dockerkafka-console-producer.sh --broker-list localhost:9092 --topic kafkaDemo# 本地kafka-console-producer.sh --broker-list localhost:9092 --topic kafkaDemo
测试demo
启动 KafkaSourceDemo ,在生产者中输入数据,看Idea 控制台的输出
kafka生产者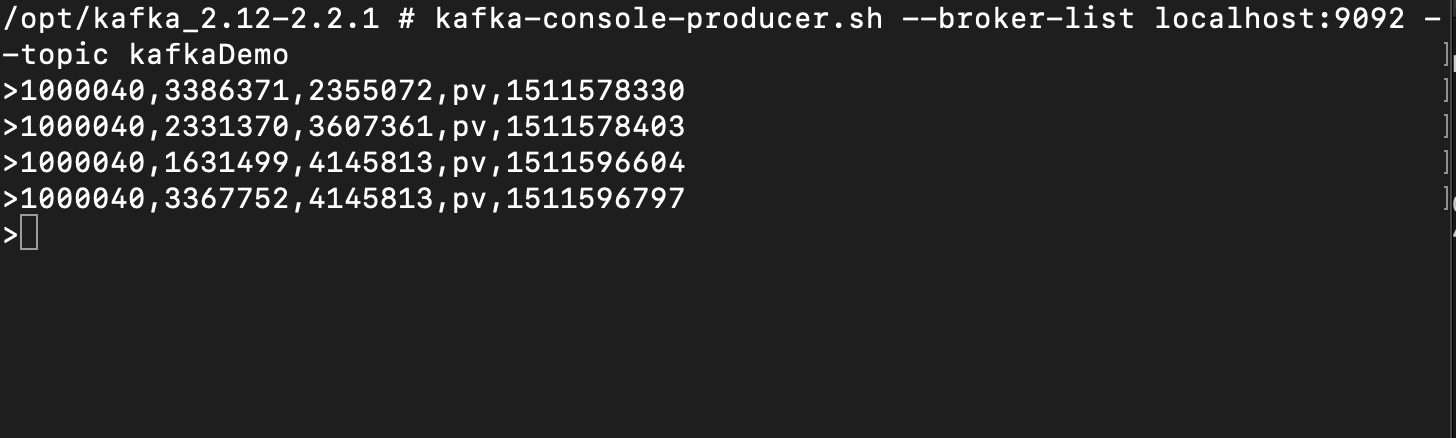
idea 输出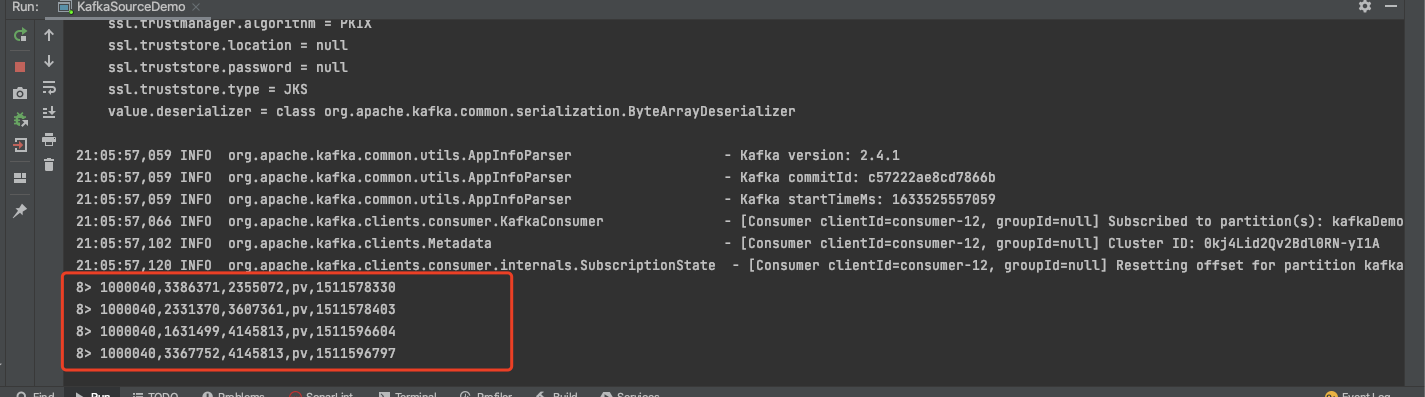
至此,kafka 连接器的测试完成。
自定义 Mysql 连接器
现在我们自定义一个 Mysql 连接器
前置依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.15</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.12</version><scope>provided</scope></dependency>
mysql 建表语句
CREATE TABLE `user_behavior` (`user_id` int NOT NULL,`item_id` int DEFAULT NULL,`category_id` int DEFAULT NULL,`behavior_type` varchar(255) DEFAULT NULL,`created_time` bigint DEFAULT NULL,`id` int NOT NULL AUTO_INCREMENT,PRIMARY KEY (`id`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=3869 DEFAULT CHARSET=utf8mb3
插入 Mysql 数据
这里只有部分数据,余下数据可以到我的百度网盘获取
INSERT INTO `user_behavior` (`user_id`, `item_id`, `category_id`, `behavior_type`, `created_time`, `id`) VALUES (1000040, 3849409, 4756105, 'pv', 1511578189, 1);INSERT INTO `user_behavior` (`user_id`, `item_id`, `category_id`, `behavior_type`, `created_time`, `id`) VALUES (1000040, 3386371, 2355072, 'pv', 1511578330, 2);INSERT INTO `user_behavior` (`user_id`, `item_id`, `category_id`, `behavior_type`, `created_time`, `id`) VALUES (1000040, 2331370, 3607361, 'pv', 1511578403, 3);INSERT INTO `user_behavior` (`user_id`, `item_id`, `category_id`, `behavior_type`, `created_time`, `id`) VALUES (1000040, 3381470, 4145813, 'pv', 1511596534, 4);
User_behavior 实体类
user_behavior 实体类用lombok ,具体使用可以参考这篇lombok使用
import lombok.Data;@Datapublic class UserBehavior {public int user_id;public int item_id;public int category_id;public String behavior_type;public Long timestamp;public UserBehavior(int user_id, int item_id, int category_id, String behavior_type, Long timestamp) {this.user_id = user_id;this.item_id = item_id;this.category_id = category_id;this.behavior_type = behavior_type;this.timestamp = timestamp;}}
Mysql Source
自定义的 MysqlSource 继承 RichSourceFunction ,实现里面的 open、close、run、cancel(暂时不实现) 方法,并写一个mysql连接器(getConnection)
public class MysqlSource extends RichSourceFunction<UserBehavior> {PreparedStatement ps;private Connection connection;/*** open() 中建立连接,防止每次调用的时候都建立连接和释放连接* @param parameters* @throws Exception*/@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);connection = getConnection();String sql = "select * from user_behavior";ps = this.connection.prepareStatement(sql);}@Overridepublic void close() throws Exception {super.close();if(connection != null){connection.close();}if(ps != null) {ps.close();}}/*** DataStream 调用一次 run() 方法用来获取数据* @param ctx* @throws Exception*/@Overridepublic void run(SourceContext<UserBehavior> ctx) throws Exception {ResultSet resultSet = ps.executeQuery();while (resultSet.next()){UserBehavior userBehavior = new UserBehavior(resultSet.getInt("user_id"),resultSet.getInt("item_id"),resultSet.getInt("category_id"),resultSet.getString("behavior_type").trim(),resultSet.getLong("created_time"));ctx.collect(userBehavior);}}@Overridepublic void cancel() {}private static Connection getConnection() {Connection con = null;try {Class.forName("com.mysql.jdbc.Driver");con = DriverManager.getConnection("jdbc:mysql://localhost:3306/flink_learn?useUnicode=true&characterEncoding=UTF-8", "root", "12345678");} catch (ClassNotFoundException | SQLException e) {e.printStackTrace();}return con;}}

若有收获,就点个赞吧
0 人点赞
