一.介绍
Apache Flink 是一个分布式的计算框架,对有界流(批处理)和无界流(流处理)数据进行有状态的计算
1.有界流和无界流
有界流
- 有定义流的开始,也有定义的结束。
- 可以在摄取所有数据后进行计算
- 所有数据可以被排序,无需有序摄取数据
- 有界流通常为批处理
无界流
- 有定义的开始,没有定义的结束
- 数据需要在获取后立即执行计算
- 数据需要有序,以便推断结果的完整性
2.数据的计算模型
批计算:对定义的时间范围内的数据进行计算,批计算需要支持高吞吐、高效处理
流计算:只要数据一直产生,就一直计算,流计算一般需要低延迟,Exactly-once保证
Flink 特性
- 同时支持高吞吐,低延迟,高性能
- 支持事件时间 (Event Time) ,接入时间(Ingestion Time) ,处理时间(Processing Time)
- 支持有状态的 Exactly-once 语义
- 支持高度灵活的 Window 窗口
- 支持轻量级分布式快照(Snapshop)实现的容错
- 支持带反压的连续流模型
- 在 JVM 内部实现了自己的内存管理
- 支持程序自动优化: 避免特定情况下 Shuffle、 排序等昂贵操作, 中间结果有必要进行缓存
FLink 整体结构
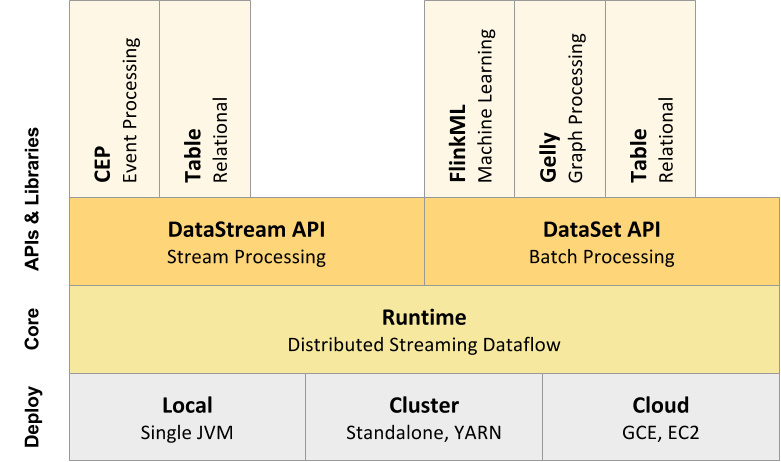
自下而上
- 部署:Flink 支持本地模式,能在独立集群模式或者被 Yarn 和 Mesos 管理,也支持上云
- 运行:FLink是分布式流式数据引擎,意味着每条数据都一次事件的模式处理
- API:DataStream、DataSet、Table、SQL API。
- 扩展:Flink 还包括用于复杂事件处理,机器学习,图形处理和 Apache Storm 兼容性的专用代码库。
Flink API
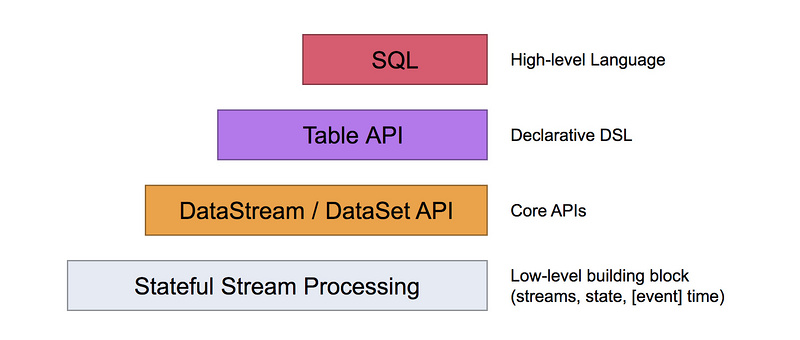
- 最底层的提供了有状态流,将过程函数(Peocess Function) 嵌入到 DataStream API 中,允许用户在一个或多个数据源中灵活处理数据,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
- DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
- Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。

若有收获,就点个赞吧
0 人点赞
