Mapping 映射
概念
Mapping 类似于数据库中的表定义,作用如下:
- 定义索引中的字段名称
- 定义字段的数据类型
- 定义字段倒排索引的相关配置
字段的数据类型
| 简单类型 | Text | 文本类型,支持分词检索 | | —- | —- | —- | | | Keyword | 关键字类型,不支持分词检索 | | | Date | 时间类型 | | | Integer | 整型 | | | Floating | 浮点型 | | | Boolean | 布尔型 | | | IPv4 & IPv6 | IP地址 | | 复杂类型 | 对象类型 / 嵌套类型 | 对象 | | 特殊类型 | geo_point | 地图坐标 | | | geo_shape | 地图坐标 | | | percolator | 地图坐标 |
Dynamic Mapping
在写入文档的时候,如果索引不存在,会自动创建索引,Dynamic Mapping的机制使得我们无需手动定义 Mapping,Elasticsearch会根据文档信息推断出字段的类型。
如果将 Dynamic 设置为 true 时,一旦有新增字段的文档写入,Mapping 也会同时更新。
如果将 Dynamic 设置为 false 时,Mapping 不会被更新,新增的字段也将无法被索引,但是新增的字段信息依然会出现在_source中。
而如果已有字段定义,写入不同的数据类型的时候,也不会触发 Mapping 字段定义的更新,即不支持修改字段定义,如果希望对已定义字段进行修改,则需要通过 Reindex API,重建索引。
设置 Dynamic Mapping
PUT {索引名称}{"mapping": {"_doc": {"dynamic": "false"}}}
| true | false | strict | |
|---|---|---|---|
| 文档可以索引 | YES | YES | NO |
| 字段可以索引 | YES | NO | NO |
| Mapping被更新 | YES | NO | NO |
能否更改 Mapping 字段类型,存在两种情况:
- 新增字段
- Dynamic 设为 true 时,一旦由新增字段的文档写入,Mapping也同时被更新。
- Dynamic 设为 false 时,Mapping 不会被更新,新增字段的数据无法被索引,但信息会出现在 _source。
- Dynamic 设为 Strict时,文档写入失败。
- 对已有字段,一旦已有数据写入,就不宰支持修改字段的定义
- Lucene 实现的倒排索引,一旦生成,就不允许修改,如果希望改变字段类型,必须 Reindex API,重建索引。
类型自动识别
| Json 类型 | Elasticsearch 类型 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 字符串 | - 匹配日期格式,设置成Data - 匹配数字格式设置为 float或者long,该选项默认关闭 - 设置为 Text,并增加 keyword 子字段 |
||||||||
| 布尔值 | boolean | ||||||||
| 浮点数 | float | ||||||||
| 整数 | long | ||||||||
| 对象 | Object | ||||||||
| 数组 | 由第一个非空数组的类型决定 | ||||||||
| 空值 | 忽略 |
定义 Mapping
PUT {索引名称}{"mappings": {"properties": {"{字段}": {"type": "text","index": true,"index_options":"docs","null_value": false,"copy_to": "new_field"}}}}
| 字段参数 | 描述 |
|---|---|
| type | 字段类型 |
| index | 是否能被索引,默认 true |
| index_options | 倒排索引记录级别 默认 docs 级别, text类型默认 postions 级别 - docs:记录 doc id - freqs:记录 doc id 和 term frequencies - position:记录 doc id / term frequencies / term position - offsets:记录 doc id / term frequencies / term position / character offects |
| null_value | 是否允许实现对NULL值索引,默认 “NULL”,备注:只有 keyword 类型支持 |
| copy_to | 将当前字段拷贝到指定目标字段,copy_to的目标字段不会出现在搜索结果集中 |
建议
- 参考API手册
- 为了减少输入的工作量,减少出错概率,可以依照以下步骤
- 创建一个临时的 index,写入一些样本数据
- 通过访问 Mapping API 获得该临时文件的动态 Mapping 定义
- 修改后使用该配置创建你的 Mapping 定义
- 删除临时索引
查看 Mapping 定义
GET /{index_name}/_mapping
多字段类型特性
查询很少是简单一句话的 match 匹配查询。通常我们需要用相同或不同的字符串查询一个或多个字段,也就是说,需要对多个查询语句以及它们相关度评分进行合理的合并。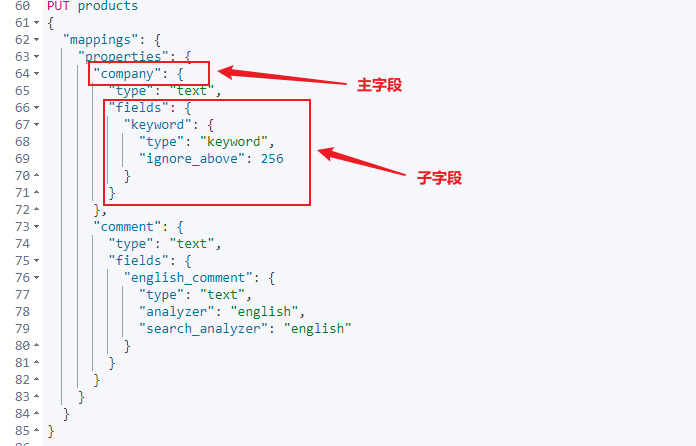
PUT products{"mappings": {"properties": {"company": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"comment": {"type": "text","fields": {"english_comment": {"type": "text","analyzer": "english","search_analyzer": "english"}}}}}}
自定义分析器 Analyzer
虽然Elasticsearch带有一些现成的分析器,然而在分析器上Elasticsearch真正的强大之处在于,你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。
| 阶段 | 描述 |
|---|---|
| Character Filters | 针对原始文本处理,例如去除html |
| Tokenizer | 按照规则切分为单词 |
| Token Filter | 将切分的单词进行加工,小写,删除停用词,增加同义词等 |

字符过滤器 (character Filter)
在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符。可以配置多个 Character Filter 。会影响 Tokenizer 的 position 和 offset 信息。
官方字符过滤器
POST _analyze{"tokenizer":"keyword","char_filter":["html_strip"],"text": "<b>hello world</b>"}
POST _analyze{"tokenizer": "keyword","char_filter": [{"type" : "mapping","mappings" : [ "- => _"]}],"text": "123-456, I-test! test-990 650-555-1234"}
GET _analyze{"tokenizer": "keyword","char_filter": [{"type" : "pattern_replace","pattern" : "http://(.*)","replacement" : "$1"}],"text" : "http://www.elastic.co"}
分词器 (Tokenizer)
分词器可以将原始文本按照一定的规则,切分成词(term or token)
| 分词器 | 作用 |
|---|---|
| whitespace | 以空格方式进行分词 |
| standard | 使用 Unicode 文本分割算法 |
| uax_url_email | 对url和emai进行分词 |
| pattern | 正则表达式分词 |
| keyword | 不进行处理 |
| path hierarchy | 文件路径分词 |
POST _analyze{"tokenizer":"whitespace","text": "hello world"}
Token 过滤器 (Token Filter)
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化 Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)
| 过滤器 | 作用 |
|---|---|
| lowercaes | 转大小写 |
| stop | 删除停用词 |
| synonym | 添加同义词 |
POST _analyze{"tokenizer":"whitespace","filter": ["lowercaes", "stop"],"text": "hello world"}
自定义Analyzer
PUT {索引名称}{"settings": {"analysis": {"analyzer": {"自定义分词器名称": {"type": "custom","char_filter": ["自定义characterFilter名称"],"tokenizer": "自定义Tokenizer名称","filter": ["自定义filter名称", "stop"],}},"tokenizer": {"自定义Tokenizer名称": {"type": "pattern","pattern": "[.,!?]"}},"char_filter": {"自定义characterFilter名称": {"type" : "mapping","mappings" : [ "- => _"]}},"filter": {"自定义filter名称": {"type": "stop","stopwords": "_englis_"}}}}
PUT index_name/{"settings": {"analysis": {"filter": {"pinyin_filter": {"type" : "pinyin","keep_separate_first_letter" : false,"keep_full_pinyin" : false,"keep_joined_full_pinyin": true,"keep_original" : true,"limit_first_letter_length" : 16,"lowercase" : true,"remove_duplicated_term" : true,"none_chinese_pinyin_tokenize": false,"keep_none_chinese": true}},"analyzer": {"ik_synonym_pinyin": {"type": "custom","tokenizer": "ik_max_word","filter": ["pinyin_filter"]}}}},"mappings" : {"properties" : {"title" : {"type" : "text","analyzer": "ik_synonym_pinyin","search_analyzer": "ik_smart"}}}}
Index Template
Index Template 能够帮助你设定 Mappings 和 Settings,并按照一定的规则,自动匹配到新创建的索引之上。
- 模板仅在一个索引被新创建时,才会产生作用。修改模板不会影响已创建的索引
- 你可以设定多个索引模板,这些设置会被“merge”在一起
- 你可以指定“order”的值,控制“merging”的过程
PUT _template/template_name{"index_patterns": ["*"],"order": 0,"version": 1,"settings": {"number_of_shards": 1,"number_of_replicas": 1}}
索引被新创建时,会按照以下流程执行PUT _template/template_name{"index_patterns": ["test*"],"order": 1,"settings": {"number_of_shards": 1,"number_of_replicas": 2},"mappings": {"date_detection": false,"numeric_detection": true}}
- 应用 Elasticsearch 默认的 settings 和 mappings
- 应用 order 数值低的 Index Template 中的设定
- 应用 order 高的 Index Template 中的设定,之前的设定会被覆盖
- 应用创建索引时,用户所指定的 Settings 和 Mappings,并覆盖之前模板中的设定
Dynamic Template 动态模板
Dynamic Template 的作用是根据 Elasticsearch 识别的数据类型,结合字段名称,来动态设定字段类型,例如:
- 所有的字符串类型都设定成 Keyword,或者关闭 Keyword 字段
- is开头的字段都设置成 boolean
- long_ 开头的都设置成 long 类型
Dynamic Template 是定义在某个索引的Mappings 中的,template有一个名称,匹配规则是一个数组。
# my_index:索引名称# dynamic_templates:动态模板名称# strings_as_boolean / strings_as_keywords:模板规则名称PUT my_index{"mappings": {"dynamic_templates": [{"strings_as_boolean": {"match_mapping_type": "string","match":"is*","mapping": {"type": "boolean"}}},{"strings_as_keywords": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]}}
| 字段 | 名称 | 描述 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| match_mapping_type | 匹配映射类型 | 数据类型的匹配:boolean(布尔类型),date(日期),double(浮点型),long(长整型),object(对象类型),string(字符类型) | |||||||
| match | 匹配 | 匹配字段名称,允许*表示模糊匹配 | |||||||
| unmatch | 不匹配 | 不匹配字段名称,允许*表示模糊匹配 | |||||||
| path_match | 路径匹配 | 与match一致,但是可以映射匹配到子字段上 | |||||||
| path_unmatch | 路径不匹配 | 与unmatch一致,但是可以映射匹配到子字段上 |
索引重建
使用场景
- 索引的 Mappings 发生变更:字段类型变更,分词器及字典更新
- 索引的 Settings 发生变更:索引的主分片数发生改变
- 集群内,集群间需要做数据迁移
Update By Query
```jsonblogs:索引名称
POST blogs/_update_by_query {
}
<a name="wglnp"></a>## ReindexElasticsearch 不允许在原有 Mapping 上对字段类型进行修改,只能创建新的索引,并且设定正确的字段类型,再重新导入数据。```json# blogs:原索引名称# blogs_fix:新索引名称POST _reindex{"source": {"index": "blogs"},"dest": {"index": "blogs_fix"}}
使用场景
- 修改索引的主分片数
- 改变字段的Mapping 中的字段类型
- 集群内数据迁移 / 跨集群的数据迁移
OP Type
设置索引重建只会创建不存在的文档,文档如果已经存在,会导致版本冲突
# blogs:原索引名称# blogs_fix:新索引名称POST _reindex{"source": {"index": "blogs"},"dest": {"index": "blogs_fix","op_type": "create"}}
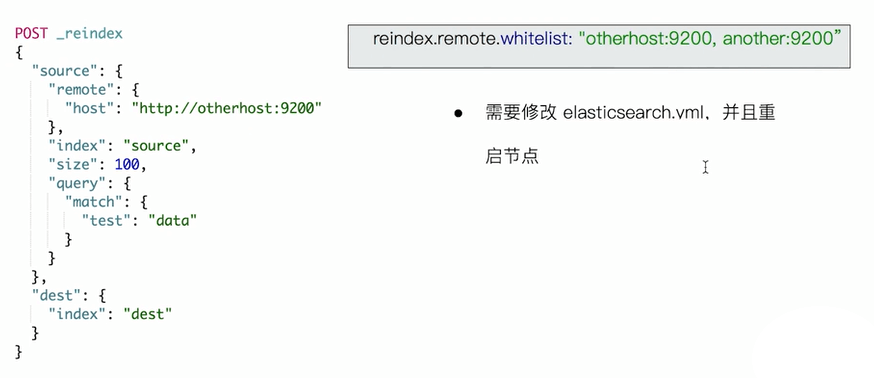

创建基于时间序列的索引
基于 Date Math 的方式,容易使用,但如果时间发生变化,需要重新部署代码
| 格式 | 最终生成索引 |
|---|---|
| logs-2022.03.26 | |
| logs-2022.03 | |
| logs-2022..7.29 |
# POST /<logs-{now/d}/_searchPOST /%3Clogs-%7Bnow%2Fd%7D%3E/_search# POST /<logs-{now/w}/_searchPOST /%3Clogs-%7Bnow%2Fw%7D%3E/_search

若有收获,就点个赞吧
0 人点赞
