分布式搜索潜在问题
搜索的机制
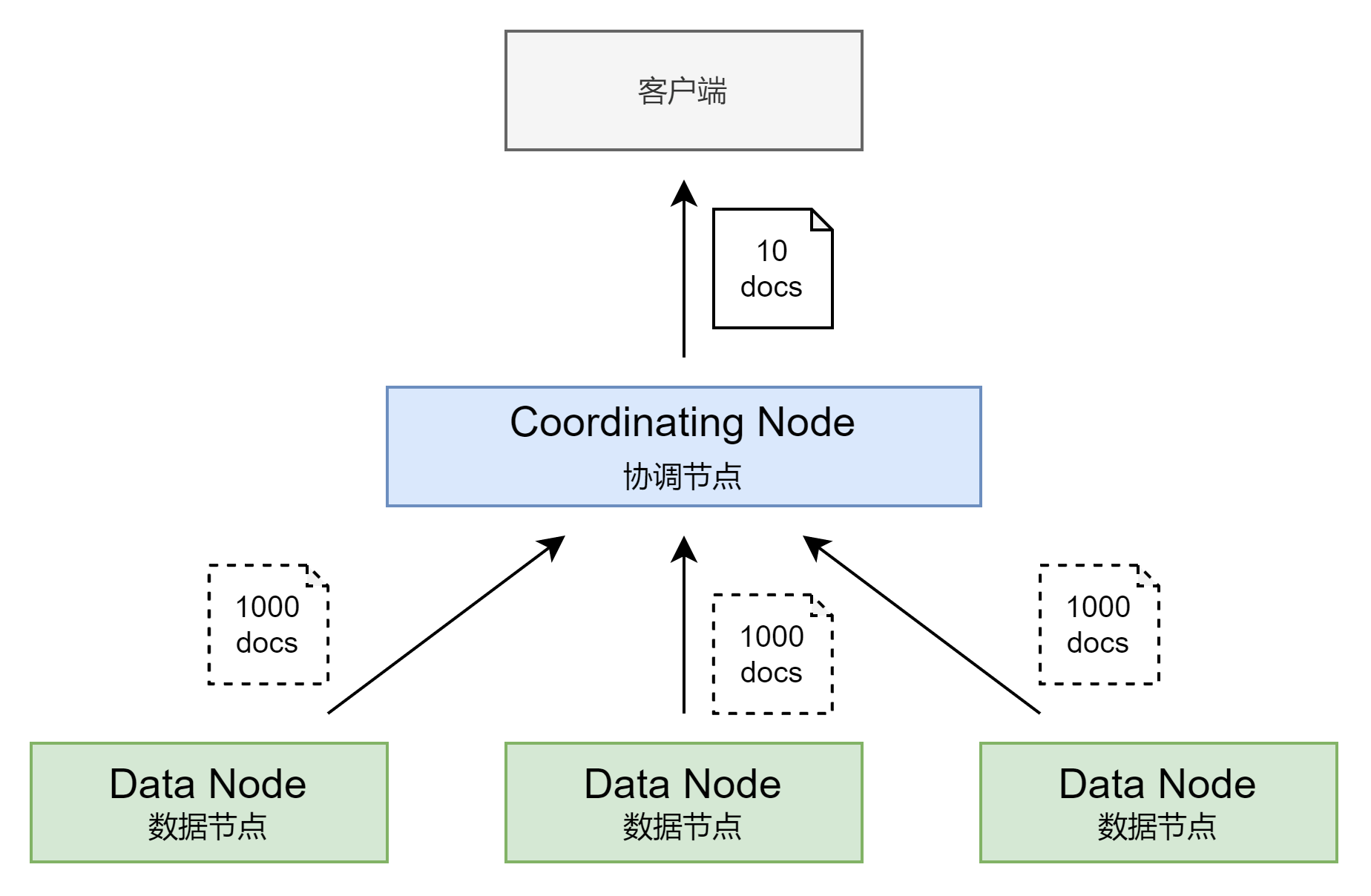
- Query 阶段
- 用户发出搜索请求到 Elasticsearch 节点。
- 节点收到请求后,会以 Coordinating 节点的身份,给其他选中分片节点发送查询请求。
- 被选中的分片节点执行查询,进行排序,每个分片都会返回 From + Size 个排序后的文档ID和排序值给 Coordinating 节点。
- Fetch 阶段

- 相关性算分不准
- 每个分片都基于自己的分片上的数据进行相关度计算。这回导致打分偏离的清空,特别是数据量很少的时候,相关性算分在分片之间是相对独立的。当文档总数很少的情况下,主分片数越多,相关性算分会越不准。
- 深度分页(性能问题)
- 当一个查询:from = 990,size = 10。会在每个分片上都获取 1000 个文档。页数越深,占用内存越多。为了避免深度分页带来的内存开销。ES 有一个设定,默认限定到 100000 个文档。即 from 或 size 大于等于 1000,Elasticsearch 默认返回异常。
- 最终协调节点需要处理:节点数 * (from + size)数据。
解决相关性算分不准
- 数据量不大的时候,可以将主分片数设为1,当数量足够大时,只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差
使用 DFS Query Then Fetch
不支持指定页数,只能往下翻
- 第一步搜索需要指定 sort,并且保证值是唯一的(可以通过加入 _id 保证唯一性)
- 使用上一次,最后一个文档的 sort 值进行查询 ``` DELETE users POST users/_doc {“name”:”user1”,”age”:10}
POST users/_doc {“name”:”user2”,”age”:20}
POST users/_doc {“name”:”user3”,”age”:30}
POST users/_doc {“name”:”user4”,”age”:40}
POST /users/_search { “size”: 1, “query”: { “match_all” : { } }, “sort”: [ {“age”: “desc”}, {“_id”: “asc”} ] }
POST /users/_search { “size”: 1, “query”: { “match_all” : { } },
# 最后一个排序的 sort 值"search_after": [40,"aX9gr38BTR_twj_8RDhr"],"sort": [{"age": "desc"},{"_id": "asc"}]
}
<a name="UAA2z"></a>## Scroll API 解决深度分页不要把 scroll 用于实时请求,它主要用于大数据量的场景。例如:将一个索引的内容索引到另一个不同配置的新索引中。scroll 是在 Elasticsearch 中建立一份有限时间的快照,通过游标进行分页的一种技术,一旦建立,新增更改的数据将不会体现在快照中。
users:索引名称
5m:快照建立的时间
POST /users/_search?scroll=5m { “size”: 1, “query”: { “match_all” : { } } }
POST /_search/scroll { “scroll” : “1m”, “scroll_id” : “DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAWAWbWdoQXR2d3ZUd2kzSThwVTh4bVE0QQ==” }
<a name="c0ujl"></a># 生产环境集群配置优化<a name="GS76K"></a>## 集群配置- 静态配置文件尽量简洁:按照文档配置所有相关系统参数。elasticsearch.yml 配置文件中尽量只写必备参数。其他设置项可以通过 API 动态进行设定,动态设定分 transient 和 persistent 两种,都会覆盖elasticsearch.yml 中的设置。- Transient 在集群重启后丢失- Persistent 在集群重启后不会丢失- 单个集群不要跨数据中心进行部署(不要使用 WAN)- 节点之间的 hops 越少越好- 如果有多块网卡,最好将 transport 和 http 绑定到不同的网卡,并设置不同的防火墙规则- 按需为 Coordinating Node 或 Ingest Node 配置负载均衡。- 建议使用中等配置的机器,不建议使用过于强劲的硬件配置- 不建议在一台服务器上允许多个节点<a name="By7Gt"></a>## JVM 设置- 应避免修改默认配置,配置文件:`config/jvm.options`- 将内存 Xms 和 Xmx 设置成一样,避免 和 heap resize 时发生停顿。- Xmx 设置不要超过物理内存的 50%;单个节点上,最大内存建议不要超过 32G 内存。- 生产环境,JVM 必须使用 Server 模式- 关闭 JVM Swapping<a name="iDH8I"></a>## 容量规划- 选择合理的硬件,数据节点尽可能使用 SSD- 搜索等性能要求高的常见,建议 SSD,按照 1:16 的比例配置内存和硬盘- 日志类和查询并发低的常见,可以考虑使用机械硬盘存储,按照 1:48-1:96 的比例配置内存和硬盘- 单节点数据建议控制在 2TB 以内,最大不建议超过 5TB<a name="FszG9"></a>## 优化分片- 避免过多的分片,一个查询需要访问每个分片,分片过多,会导致不必要的查询开销- 结合应用场景,控制单个分片的尺寸,搜索类应用 20GB,日志类应用 40GB- 使用基于时间序列的索引,将只读的索引进行 Merge 索引合并,减少 segment 数量<a name="AIunm"></a>## 关闭 Dynamic Indexes```yamlPUT _cluster/settings{"persistent": {"action.auto_create_index": false}}
PUT _cluster/settings{"persistent": {"action.auto_create_index": "logstash-*,.kibana*"}}
提高集群写入性能
ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性,写入数据,一般不要盲目修改。一切优化都要基于高质量的数据建模。
- 客户端通过 BULK 批量操作,减少服务器的 IO 开销
- 降低 IO 操作:
- 使用 ES 自动生成文档id,如果是自定义id,ES 会检查冲突
- 降低 refresh 操作频率,通过降低数据实时性换取性能
- 减少 translog 实时落盘操作,通过降低数据安全性换取性能
- 降低 CPU 和存储开销
- 减少不必要的分词
- 避免不必要的 doc_values
- 文档的字段尽量保证相同顺序,可以提高文档的压缩率
- 尽可能做到写入和分片的负载,实现水平扩展(分片均衡分配)
- 热点数据过于集中,可能会产生性能问题
- 调整 Bulk 线程池和队列
关闭无用的功能
```jsonmy_index:索引名称
not_serach_field:字段名称
PUT my_index { “mappings”: { “properties”: { “not_serach_field”: { “index”: false } } } }
```json# my_index:索引名称# not_norms_field:字段名称PUT my_index {"mappings": {"properties": {"not_norms_field": {"norms": false}}}}
# my_index:索引名称# field_name:字段名称PUT my_index {"mappings": {"properties": {"field_name": {"index_options": "docs"}}}}
PUT my_index {"mappings": {"dynamic": false}}
性能取舍
PUT my_index{"settings": {"number_of_replicas": 0}}
降低 Refresh 的频率,通过增大 refresh_interval 的数值(默认为 1s,如果设置成 -1,会禁止自动 refresh),避免频繁的 refresh,生成过多的 segment 文件,降低搜索实时性。
增大静态配置参数 indices.memory.index_buffer_size (默认10%内存,超过自动触发 refresh)。
PUT my_index{"settings": {"index": {"refresh_interval": "30s"}}}
降低日志写磁盘的频率,牺牲容灾能力。
- translog.durability:默认 request,每个请求都落盘,设置成 async,异步写入
- translog.sync_interval:异步写入间隔时间
translog.flush_threshod_size:默认 512mb,可以适当调大,当 translog 超过该值,触发 flush
PUT my_index{"settings": {"translog": {"durability": "async","sync_interval": "30s"}}}
分片负载
设置合理的主分片数,确保均匀分布再所有数据节点上,通过
Index.routing.allocation.total_shards_per_node每个索引在每台节点上可分配的主分片数量。PUT my_index{"settings": {"routing": {"allocation": {"total_shards_per_node": 2}}}}
BULK 批量操作
客户端
- 单个 bulk 请求体的数据量不要太大,官方建议大约 5-15 MB
- 写入端的 bulk 请求超时需要足够长,建议 60s 以上
- 写入端尽量将数据轮询打到不同节点
服务器端
Elasticsearch 不等于关系型数据库,应尽可能构建非规范化数据结构,从而获取最佳的性能。
- 尽可能将数据先行计算,然后保存到 Elasticsearch 种,尽量避免查询时的 Script 计算
- 尽量使用 Filter Context,利用缓存机制,减少不必要的算分
- 严禁使用 * 开头通配符 Terms 查询,结合 profile,explain API 分析慢查询的问题,持续优化数据建模
- 聚合查询会消耗内存,特别是针对很大的数据集进行聚合运算,如果可以控制聚合的数量,就能减少内存的开销
```jsonPUT blogs/_doc/1{"title":"elasticsearch"}GET blogs/_search{"query": {"bool": {"must": [{"match": {"title": "elasticsearch"}}],"filter": {"script": {"script": {"source": "doc['title.keyword'].value.length()>5"}}}}}}
未优化前
GET blogs/_search { “query”: { “bool”: {
} } }"must": [{"match": {"title": "elasticsearch"}},{"range": {"publish_date": {"gte": 2017,"lte": 2019}}}]
优化后
GET blogs/_search { “query”: { “bool”: { “must”: [ {“match”: {“title”: “elasticsearch”}}, { “filter”: { “range”: { “publish_date”: { “gte”: 2017, “lte”: 2019 } } } } ] } } }
```jsonGET test/_search{"query": {"wildcard": {"title": {"value": "*elastic*"}}}}
force merge
当 Index 不再有写入操作的时候,建议对其进行 force merge,提升查询速度,减少内存开销。
# geonames:索引名称POST geonames/_forcemerge?max_num_segments=1
Merge 优化,降低最大分段大小,避免较大的分段继续参与 Merge,节省系统资源。(最终会有多个分段)
Index.merge.policy.segments_per_tier,默认为10,越小需要越多的合并操作Index.merge.policy.max_merged_segment,默认 5 GB,segment file 超过此大小以后,就不再参与后续的合并操作集群压力测试
目的:容量规划、性能优化、版本间性能比较、性能诊断、确定系统稳定性,考察系统功能极限和隐患。
压力测试的方法与步骤:制定测试计划(确定测试场景和测试数据集);脚本开发;测试环境搭建(不同的软硬件配置)、运行测试;分析比较结果。
测试目标测试集群的读写性能、做集群容量规划
- 对 Elasticsearch 配置参数进行修改,评估优化效果
- 修改 Mapping 和 Setting,对数据建模进行优化,并测试评估性能改进
- 测试 Elasticsearch 新版本,结合实际场景和老版本进行比较,评估是否进行升级
测试脚本
- Elasticsearch 本身提供了 REST API,所以,可以通过很多传统的性能测试工具
- Load Runner:商业软件,支持录制+重放+DSL
- JMeter:Apache 开源,Record & Play
- Gatling:开源,支持写 Scala 代码+DSL
- 专门为 Elasticsearch 设计的工具
- ES Pref & Elasticsearch-stress-test
- Elastic Rally
缓存的使用以及 Breaker 限制
缓存主要分类
Node Query Cache
保存的是 Segment 级缓存命中的结果。Segment 被合并后,缓存会失效。
每个节点都有一个 Node Query 缓存,采用 LRU算法,由该节点的所有 Shard 共享,只缓存 Filter Context 查询相关内容。通过静态配置,需要设置在每个 Data Node 上:
Node Level - indices.queries.cache.size: “10%”
Index Level - index.queries.cache.enabled: true
Shard Query Cache
分片 Refresh 时候,Shard Request Cache 会失效。如果 Shard 对应的数据频繁发生变化,该缓存的效率会很差。
缓存每个分片上的查询结果,只会缓存设置了 size=0 的查询结果。不会缓存 hits,但是会缓存 Aggregations 和 Suggestions,通过 LRU 算法,将整个 JSON 查询作为 Key,与 JSON 对象的顺序相关,通过静态配置:
indices.requests.cache.size: “1%”
Fielddata Cache
Segment 被合并后,会失效。
除了 Text 类型,默认都采用 doc_values。节约了内存。Text 类型的字段需要打开 Fileddata 才能对其进行聚合和排序,Text 经过分词,排序和聚合的效果不佳,建议不要轻易使用,通过静态配置:
可以控制 Indices.fielddata.cache.size,避免产生 GC(默认无限制)诊断内存状况
```json GET _cat/nodes?v
GET _nodes/stats/indices?pretty
GET _cat/nodes?v&h=name,queryCacheMemory,queryCacheEvictions,requestCacheMemory,requestCacheHitCount,request_cache.miss_count
GET _cat/nodes?h=name,port,segments.memory,segments.index_writer_memory,fielddata.memory_size,query_cache.memory_size,request_cache.memory_size&v
<a name="Vmozd"></a>## 常见的内存问题- Segments 个数过多,导致 full GC- 现象:集群整体响应缓慢,也没有特别多的数据读写,但是发现节点在持续进行 Full GC- 分析:查看 Elasticsearch 的内存使用,发现 segments.memory 占用很大空间- 解决:通过 force merge,把 segments 合并成一个。- 建议:对于不再写入和更新的索引,可以将其设置成制度。同时,进行 force merge 操作。如果问题依然存在,则需要考虑扩容。此外,对索引进行 force merge,还可以减少对 global_ordinals 数据结构的构建,减少对 fielddata cache 的开销。---- Field data cache 过大,导致 full GC- 现象:集群整体响应缓慢,也没有特别多的数据读写,但是发现节点在持续进行 Full GC- 分析:查看 Elasticsearch 的内存使用,发现 fielddata.memory.size 占用很大空间。同时,数据不存在写入和更新,也执行过 segments merge。- 解决:将 fielddata.memory.size 设小,重启节点,堆内存恢复正常- 建议:Field data cache 的构建比较重,ES 不会主动释放,所以这个值应该设置的保守一些,如果业务上确实有所需要,可以通过增加节点,扩容解决。---- 复杂的嵌套聚合,导致集群 full GC- 现象:节点响应缓慢,持续进行 Full GC- 分析:导出 Dump 分析。发现内存中由大量 bucket 对象,查看日志,发现复杂的嵌套聚合- 解决:优化聚合- 建议:在大量数据集上进行嵌套聚合查询,需要很大的堆内存来完成。如果业务场景确实需要。则需要增加硬件进行扩展。同时,为了避免这类查询影响整个集群,需要设置 Circuit Break 和 search.max_buckets 的数值。<a name="jG73S"></a>### Circuit Break- Parent circuit breaker:设置所有的熔断器可以使用的内存的总量- Fielddata circuit breaker:加载 fielddata 所需要的内存- Request circuit breaker:防止每个请求级数据结构超过一定的内存(例如聚合计算的内存)- In flight circuit breaker:Request 中的断路器- Accounting request circuit breaker:请求结束后不能释放的对象所占用的内存```jsonGET /_nodes/stats/breaker?
Tripped 大于 0, 说明有过熔断
Limit size 与 estimated size 约接近,越可能引发熔断
千万不要触发了熔断,就盲目调大参数,有可能会导致集群出问 题,也不因该盲目调小,需要进行评估
建议将集群升级到 7.x,更好的 Circuit Breaker 实现机制
增加了 indices.breaker.total.use_real_memory 配置项,可以更加精准的分析内存状况,避免 OOM
运维工具
节点上出现了高内存占用,可以执行清除缓存的操作,这个操作会影响集群的性能,但是会避免你的集群出现 OOM 的问题。
POST _cache/clear
当你想移除一个节点,或者对一个机器进行维护。同时你又不希望集群的颜色变黄或者变红。
PUT _cluster/settings{"transient": {"cluster.routing.allocation.exclude._ip":"192.168.9.220"}}
将分片从一个节点移动到另一个节点,使用场景:当一个数据节点上由过多的Hot Shards:可以通过手动分配分片到特定的节点解决。
POST _cluster/reroute{"commands": [{"move": {"index": "index_name","shard": 0,"from_node": "node_name_1","to_node": "node_name_2"}}]}
设置各类 Circuit Breaker。避免 OOM 的发生。
PUT _cluster/settings{"persistent": {"indices.breaker.total.limit":"40%"}}
重启一个节点
POST _flush/synced

若有收获,就点个赞吧
0 人点赞
