
1. Protocol Independent Multicast(协议无关组播)特征
- IP 协议号「103」,支持 IPv4/IPv6
- 通过组播地址「224.0.0.13」封装 Hello 报文,TTL = 1
- PIM 协议是需要依靠单播路由表形成的
- PIM DM 适合相对主机密集、范围较小的网络
- PIM DM 适合相对主机分散、范围较大的网络
- PIM-SM 也可以实现 PIM-SM 域内的 Anycost RP,达到共享组播源信息的目的
- PIM 路由器
- 叶路由器:与主机相连
- 第一跳路由器:与树根相连
- 中间路由器:组播转发路径的路由器
- PIM 路由表项转发规则
- 如果存在(S,G),则通过(S,G)路由表进行转发
- 如果只存在(,G),则先依照(,G)路由表创建(S,G)路由表项,再由(S,G)路由表转发
- PIM 路由表
适用于组播网络相对密集、较小的网络(因为 PIM DM 会认为全网所有位置都可能存在主机,会将组播报文泛洪到整个网络),并且对设备资源消耗较大。使用 “退(push)” 的方式获取组播流
- PIM DM 中,(S,G)表项用来转发组播流
- PIM DM 中,叶路由器上的(,G)表项作为(S,G)表项的父项。(,G)表项表项 oiflist 下有主机需要组播流
PIM DM 主要通过扩散、剪枝、嫁接构建 SPT,最终将整个网络修剪为一棵树
PIM 路由器之间每「30s」交互 Hello 消息,发现 PIM 邻居并维护邻居关系(只有邻居关系建立成功后,PIM 路由器才能接收其他 PIM 协议报文)
- 封装 Hello 消息的 IP 报文源地址是本地接口地址,目的地址为「224.0.0.13」,TTL = 1
- Hello Message 中的参数协商
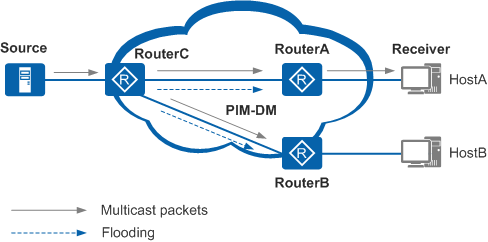
- 当树根生效后,组播流会扩散至所有建立了 PIM 邻居的路由器。PIM 路由器收到组播流后,将根据单播路由表进行组播源的 RPF 检查,检查通过则创建(S,G)路由表
3)剪枝(Prune)/Join
Prune 操作从叶路由器开始,从下游向上游逐跳剪枝(周期性)
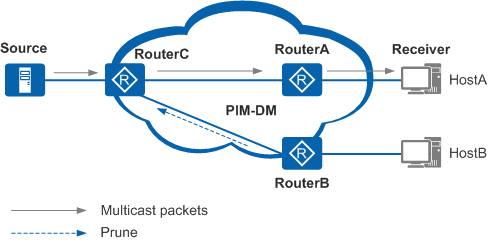
- Prune 是叶路由器没有主机的情况下,向上游通告进行剪枝操作,但在共享网络上需要等待「3s」的 Prune 延迟
- 叶路由器的下游接口如果没有组播流的需求,会向上游路由器发送 Prune 消息,通知上游路由器关闭向本设备转发组播流。上游设备收到 Prune 消息后,将(S,G)路由表中对于该叶路由器的 ofilist 删除,并启动 Prune 定时器,默认「180s」。当定时器超时后恢复接口的组播流转发(组播流又重新进行扩散和 Prune)
- 如果在共享网络(以太网)有多台叶路由器时,当某台叶路由器发送了 Prune 消息,上游路由器不会立马进行 Prune,而需要等待一个 LAN_Delay + Overried-Interval 的否决剪枝时间「3s」,如果有叶路由器回复 Join 消息 prune 覆盖,则不进行 Prune(因为所有运行了 PIM 的路由器都会侦听「224.0.0.13」,所以其他设备也会收到 Prune 消息,在收到消息后立马会回复 Join 消息进行覆盖)
4)嫁接(Graft)
Graft 操作从叶路由器开始,一直蔓延到拥有组播流的 PIM 路由器
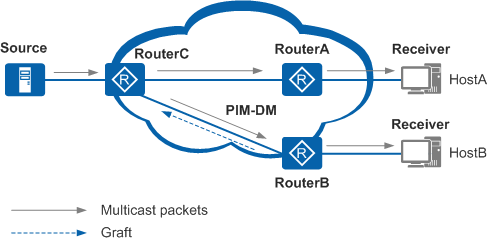
- Graft 是在 Prune 定时器超时之前,请求上游路由器恢复组播流的转发,如果在「3s」内没有收到 Graft Ack 消息,则进行重传
- 叶路由器已经和上游路由器完成 Prune 后,突然有新上线的主机需要组播流时。叶路由器向上游发送 Graft 消息,请求上游路由器恢复相应出接口的组播流转发,以实现新上线的主机快速得到组播流
5)状态刷新(State Refresh)
通过 State Refresh 周期性的刷新 Prune 定时器,为了避免已经被 Prune 的接口重新进行组播流转发
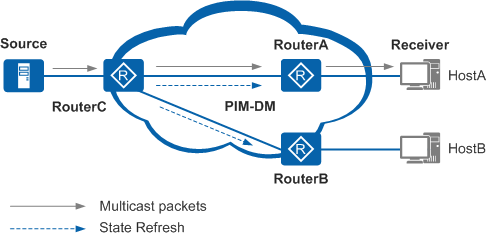
- 第一跳路由器会在第一次 Prune 后,周期性地每「60s」向全网扩散 State Refresh 消息,收到消息的 PIM 路由器会刷新 Prune 的定时器,达到一直抑制的目的(不再进行 Flooding —- Prune 的周期操作)
- 当叶路由器有新上线的主机时,通过 Graft 操作获取组播流
6)断言(Assert)
为了避免共享网络中有多个叶路由器同时转发组播流,造成的组播流重复
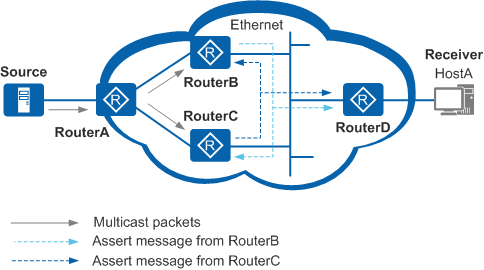
- Assert 选举
- 单播路由协议优先级高的转发组播流
- 组播源的 Cost 较小的转发组播流
- 下游接口 IP 地址大的转发组播流
- 叶路由器相互之间向目的地址「224.0.0.13」发送 Assert 消息,将 Assert 消息中的路由信息与自身的路由信息进行比较
适用于组播组成员规模相对较大、相对稀疏的网络。使用 “拉(pull)” 的方式获取组播流
- 组播源、第一跳路由器、RP、叶路由器(理解为传统供应链的关系)
- PIM SM 中 RP 是必须的设备,网络中所有 PIM 路由器都支持 RP 的位置
- 只要组播源能够将组播流转发到 RP 上,那么 RP 就可以通过 PRT 树,将组播流转发给接收者
- 通过 RP 的位置,叶路由器就可以根据接收者情况,通过 Join 消息倒着逐跳的形成 RPT 树
- 沿着 RPT 树转发组播流量,是根据组播 RP 的地址来做 RPF 检查(*,G)
沿着 SPT 树转发组播流量,是根据组播源的地址来做 RPF 检查(S,G)
1)RP 产生
① 静态 RP
允许静态 RP 和动态 RP 同时存在,但默认情况下静态 RP 优先级低于动态 RP
-
② C-BSR(Candidate-BSR)/C-RP(Candidate-RP)
BSR 用来收集全网所有 C-RP 的通告信息,并通过 PIM 报文泛洪到 PIM-SM 域内 RP 默认情况下为所有组服务
C-BSR 默认每「60s」发送一次 Bootstrap 报文,超时时间为「130s」;所有配置了 C-BSR 的设备都通过 Bootstrap 报文(PIM)在整网泛洪自己的信息,C-BSR 之间通过报文信息进行选举;BSR 将所有 C-RP 的信息汇总为 RP-Set 封装在 Bootstrap 报文中,进行全网泛洪。所有允许了 PIM SM 的设备通过 RP-Set 自行选出 RP
- C-RP 默认每「60s」发送一次 Advertisement报文,超时时间为「150s」;C-RP 通过 Advertisement 报文(单播)将候选信息发送给 BSR
- C-BSR 选举出 BSR 的规则
- 优先级值大的,成为 BSR[默认为 0]
- IP 地址大的,成为 BSR
- C-RP 选举出 RP 的规则
- 服务范围小的,将被选举为特定组的 RP[默认为 30]
- 优先级数值小的,成为RP[默认为 0]
- Hash 计算结果较大的,成为RP(组地址、哈希掩码、C-RP地址一起做 Hash 计算)
- IP 地址大的,成为RP
疑问:能不能没有 BSR,看上去 RP 都是 DR 自己选的,为什么还要 BSR 呢?直接让 RP 全网泛洪自己的信息不就好了吗?
候选 RP 将候选信息通过「UDP 496 端口」的 PIM-DM 强制泛洪至「224.0.1.39」
- MA(mapping agent,裁决者)侦听「224.0.1.39」,通过 IP 地址大的判定谁是 RP;通过「224.0.1.40」将 RP 的裁决信息通告给所有 PIM 路由器
- 未成为 RP 的候选 RP 每「60s」发送一次自己的候选信息,以刷新在 MA 保存的 C-RP 信息;MA 保存 C-RP 信息「181s」
2)DR 选举/RPF 形成
在同一个共享网络中,如果有多台 PIM 路由器,则相互交互 Hello 消息,通过 Hello 消息选举出 DR(DR 支持抢占)
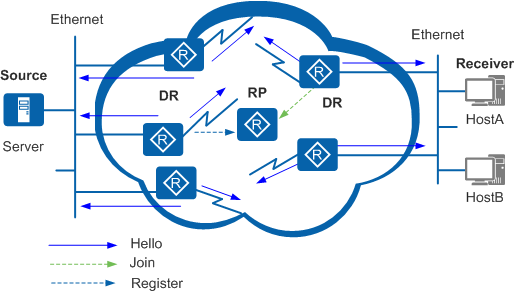
- 组播源测的 DR 负责向 RP 发送 Register 消息(组播源注册,生成 SPT 树)
- 接收者测的 DR 负责向 RP 发送 join 消息(向 RP 请求组播流,生成 RPT 树)
- DR 的选举规则
- Hello 报文中优先级数值大的,成为 DR「默认为 1」
- IP 地址大的,成为 DR
- 为被选举出的 PIM 路由器监听 hello 消息,如果「105s」没有收到 DR 的 Hello 消息,则认为 DR 失效,重新进行选举
- RPT 树的形成
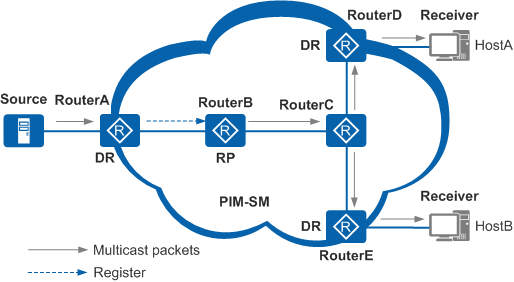
- Register 消息:目的是为了让 RP 知道组播源在哪
- Register Stop 消息:是一种平滑过渡的机制,目的是为了告知源 DR,已经知道了组播源的位置,不用再进行注册了
- 工作原理:
- 组播源将组播流发送给 DR,DR 将组播流封装进 IP 报文中(Register),向 RP 方向进行发送(作用是注册)
- RP 收到该单播报文后,进行解封装,发现报文中携带的是组播信息。此时 RP 就会逐跳向着组播源方向进行 RPF 检查,并发送 join 消息,从而形成一棵 SPT 树和(S,G)表项
- 当 RP 到 DP 沿路的所有 PIM 设备都通过了 RPF 检查并形成了 SPT 树后,组播流才可以沿着 SPT 树进行转发
- 只有 RP 收到组播流后,就会认为可以停止单播流量了,才向着 DR 发送 Register Stop 消息
4)SPT 切换 RP(Prune)
叶路由器对 RP 的 Prune,可以减小 RP 的负担
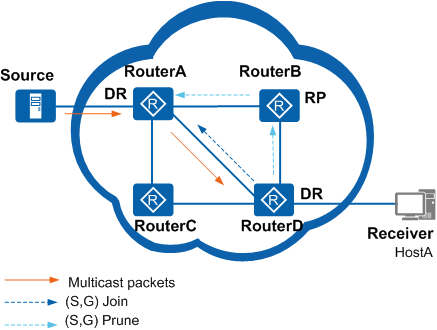
- 当叶路由器收到组播流量,就可以感知到组播源地址,于是针对组播源地址做 RPF 检查,然后向着组播源方向逐跳发送 join 消息,逐渐形成从叶路由器到源的 SPT 树和(S,G)表项
- 当形成了 SPT 树后,并且从 SPT 树收到组播流量。此时会沿着 RPT 树进行对 RP 的剪枝
- 最终所有流量都沿着 SPT 树进行转发
4. Anycost-RP
- RP 路径最优:组播源向距离最近的 RP 进行注册,建立路径最优的SPT;接收者向距离最近的 RP 发起加入,建立路径最优的 RPT
- RP 间的负载分担:每个 RP 上只需维护 PIM-SM 域内的部分源/组信息、转发部分的组播数据
- RP 间的冗余备份:当某 RP 失效后,原先在该 RP 上注册或加入的组播源或接收者会自动选择就近的 RP 进行注册或加入操作

若有收获,就点个赞吧
0 人点赞
