SQL和MySQL学习
主要参考:《MySQL笔记》
file:///G:/A%E6%96%87%E6%A1%A3/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%BA%90/MySQL%E7%AC%94%E8%AE%B0.pdf
Navicat官方文件
file:///E:/Program%20Files/PremiumSoft/Navicat%20Premium%2015/navicat.pdf
安装MYSQL:
MySQL 安装 | 菜鸟教程 (runoob.com)
https://www.cnblogs.com/zhif97/p/13207155.html
Navicat激活码NAVD-JWHX-3UWG-WCXN
忘记MySQL密码 解决方法:在mysql表下,新建查询并执行:update user set authentication_string=password(‘新密码’) where user=’root’;
mysql 8.0密码修改方式:ALTERUSER’root’@’localhost’IDENTIFIEDWITHmysql_native_passwordBY’你的密码’;
重点模块:
SQL语句中的 分组查询、连接查询
索引
语句优化
启动MySQL服务:命令行net start mysql
mysql登录命令 mysql -h ip -P 端口 -u 用户名 -p
显示所有数据库:show databases
进入指定的数据库:use 数据库名
查看某个系统变量:SHOW VARIABLES like ‘变量名’;
单行注释:#注释文字
单行注释:— 注释文字 ,注意, 这里需要加空格
多行注释:/ 注释文字 /
SQL语言分类
DQL(Data Query Language):数据查询语言 select 相关语句
DML(Data Manipulate Language):数据操作语言 insert 、update、delete 语句
DDL(Data Define Languge):数据定义语言 create、drop、alter 语句
TCL(Transaction Control Language):事务控制语言 set autocommit=0、start transaction、savepoint、commit、rollback
数据类型:整数、浮点、字符串、日期
整数:有符号类型、无符号类型 unsigned
类型(n)说明: 无论N等于多少,int永远占4个字节 N表示的是显示宽度,不足的用0补足,超过的无视长度而直接显示整个数字,
但这要整型设置了 unsigned zerofill才有效(p.69页)
浮点数p.71页
浮点型和定点型可以用类型名称后加(M,D)来表示,M表示该值的总共长度,D表示小数点后面的长 度,M和D又称为精度和标度。
float和double在不指定精度时,默认会按照实际的精度来显示,而DECIMAL在不指定精度时,默认整 数为10,小数为0。
decimal采用的是四舍五入, decimal插入的数据超过精度之后会触发警告
float和double采用的是四舍六 入五成双
DDL常见操作
建库 drop database if exists 旧库名; create database 新库名;
建表 create table 表名( 字段名1 类型[(宽度)] [约束条件] [comment ‘字段说明’],
查看建表语句:show create table 表名
设置主键、外键、unique key
auto_increment:标识该字段的值自动增长 (整数类型,而且为主键)
复制表
只复制表结构 create table 表名 like 被复制的表名
复制表结构+数据: create table 表名 [as] select
删除列 alter table 表名 drop column 列名;
DML常见操作:数据操作语言(增删改)
增:批量插入有2种方式
insert into test2 values (100,101,102),(200,201,202),(300,301,302);
insert into 表 [(字段,字段)] 数据来源select语句;
改:update test1 set a = 1,b=2;
删:delete from
p.101
drop,truncate,delete区别:truncate与不带where的delete :只删除数据,而不删除表的结构(定义)
drop (删除表):删除内容和定义,释放空间,简单来说就是把整个表去掉
truncate (清空表中的数据):删除内容、释放空间但不删除定义(保留表的数据结构),
delete (删除表中的数据)
查询
区间查询 :列名(闭区间) BETWEEN A AND B
空值查询需要使用IS NULL或者IS NOT NULL,其他查询运算符对NULL值无效
(建议创建表的时候,尽量设置表的字段不能为空,给字段设置一个默认值)
limit 用来限制select查询返回的行数,常用于分页等操作。 limit [offset,] count;
offset:表示偏移量,通俗点讲就是跳过多少行,offset可以省略,
分组查询group by
where是在分组(聚合)前对记录进行筛选,而having是在分组结束后的结果里筛选,最后返回整个 sql的查询结果。
,分组中select后面的列只能有2种: 1. 出现在group by后面的列 2. 使用聚合函数的列
MySQL 流程控制函数
case 搜索语句,类似于java中的if..else if..else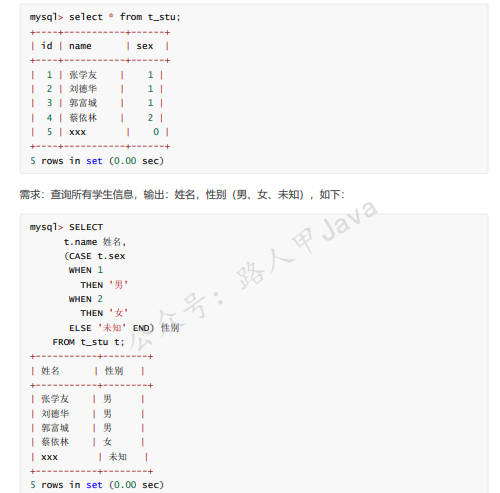
连接查询
笛卡尔积:有两个集合A和B,笛卡尔积表示A集合中的元素和B集合中的元素任意相互关联 产生的所有可能的结果。 相当于循环遍历两个集 合中的元素,任意组合
内连接:
select 字段 from 表1 (inner)join 表2 on 连接条件;
或 select 字段 from 表1, 表2 [where 关联条件];
外连接
外连接查询结果为主表中所有记录。如果从表中有和它匹配的,则显示匹配的值,这部分相当于内连接 查询出来的结果;
如果从表中没有和它匹配的,则显示null。
最终:外连接查询结果 = 内连接的结果 + 主表中有的而内连接结果中没有的记录。
Block Nested Loop
子查询
分类: 标量子查询(结果集只有一行一列) 一般搭配着单行单列操作符使用 >、<�、>=、<=、=、<>、!=
列子查询(结果集只有一列多行) 一般搭配着多行操作符使用如IN,ANY,ALL
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)
select后面的子查询:子查询位于select后面的,仅仅支持标量子查询。
from后面的子查询: 将子查询的结果集充当一张表,要求必须起别名,否者这个表找不到。
NULL
任何值和NULL使用运算符(>、<�、>=、<=、!=、<>)或者(in、not in、any/some、all), 返回值都为NULL
当IN和NULL比较时,无法查询出为NULL的记录 ,
当NOT IN 后面有NULL值时,不论什么情况下,整个sql的查询结果都为空 ,
判断是否为空只能用IS NULL、IS NOT NULL ,
count(字段)无法统计字段为NULL的值,
count(*)可以统计所有数据,不论字段的数据是否为NULL
当字段为主键的时候,字段会自动设置为not null。
当字段为主键的时候,字段会自动设置为not null
事务详解p.203
事物的特性:ACID
原子性:
一致性
隔离性
持久性
索引
索引是依靠某些数据结构和算法来组织数据,最终引 导用户快速检索出所需要的数据。
p.282
p.296
创建索引create [unique] index 索引名称 on 表名(列名[(length)]);
查看索引 show index from 表名
使用索引的一些建议p.316
1. 在区分度高的字段上面建立索引可以有效的使用索引,区分度太低,无法有效的利用索引,可能需 要扫描所有数据页,此时和不使用索引差不多
2. 联合索引注意最左匹配原则:必须按照从左到右的顺序匹配,mysql会一直向右匹配直到遇到范围 查询(>、<�、between、like)就停止匹配,
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立 (a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可 以任意调整
3. 查询记录的时候,少使用*,尽量去利用索引覆盖,可以减少回表操作,提升效率
4. 有些查询可以采用联合索引,进而使用到索引下推(IPC),也可以减少回表操作,提升效率
5. 禁止对索引字段使用函数、运算符操作,会使索引失效
6. 字符串字段和数字比较的时候会使索引无效
7. 模糊查询’%值%’会使索引无效,变为全表扫描,
但是’值%’这种可以有效利用索引
8. 排序中尽量使用到索引字段,这样可以减少排序,提升查询效率
11.4 刘小成老师讲课
mysql
事务和锁
事务分类:扁平、链式、嵌套、分布式
锁 乐观锁和悲观锁
11.12 MYSQL高可用
高可用方案
RPO:
RTO:
Proxy
配置中心
拆分:分库分表
备份
MYSQL MGR
11.17 MySQL监控体系
关键指标:QPS,COM_XX,Transction,R/W,Table_Cache,Tread_Cache,Connection,Qcache
监控工具:Innotop,Nagios
SQL优化
字段:适度原则;避免使用NULL;varchar与char;
表:合适的主键;避免宽表;避免太多关联;大字段
反范式:冗余
索引:B+树,Hash
工具:explain
索引:
速度:cache>内存>主线>硬盘
分页:
Tips:
表的设计:适当的冗余
11.18
高级特性
字符集
character set
caliation
trigger触发器
online schema change
视图:又是SQL又是表;具有屏蔽作用
partition分区 :按时间、range分区
大规模运维:

若有收获,就点个赞吧
0 人点赞
