一、数据库的相关概念
1. 什么是数据库:
按照数据结构来组织、存储、管理数据的仓库(Database。
2.数据库管理系统
(Database Management System, 简写DBMS):专门用于数据管理的软件系统,位于操作系统和用户之间的数据管理系统
3.数据库系统:
DBMS,硬件/软件,应用程序,用户
DBMS应用场合
1)银行中客户,账户,交易信息存储
2)电商系统中商品、订单、客户信息存储
3)仓库关系统中的数据存储
……
重要概念(重点)
1)关系:规范的二维表
2)关系型数据库:使用关系模型的数据库 二维表表示数据、数据之间的联系关系型数据
用来处理结构化数据
3)实体:现实中可以区分的事物
4)元组:二维表中的一行,描述一个实体信息
5)属性:实体的某个数据特征
6)键:可以区分实体的属性、属性组合
7)主键:从键中选取一个,作为逻辑上唯一区分实体的依据
二、库管理
查看库:
show databases;
创建库:
- 语法:CREATE DATABASE 库名称 [字符集DEFAULT charset=utf8]
- 库的命名规则
可以使用数字、字母、下划线
不能使用纯数字
库名区分大小写
库名必须唯一
不能使用特殊字符和MySQL关键字
进入库/切换库
USE 库名称
查看库
- 查看当前库:
SELECT DATABASE; - 查看某个库建库的语句
SHOW CREATE DATABASE 库名; - 查看库中有哪些表
SHOW TABLES;
删除库
DROP DATABASE 库名
三、表管理(重点内容)
数据类型
- 数值类型
- 整数型:TINYINT, INT, BITINT
- 浮点数: DECIMAL(16, 2)
使用注意:整数要注意存储范围
浮点数要注意精度
- 字符类型
1)定长字符(CHAR)- 最大存储255个字符
- 定义长度后,如果数据不足,自动补充空格
- 超过长度无法存入
- 如果不设置长度,默认长度为1
2)变长字符(varchar)
- 最大存储65535个字节
- 实际存储空间根据实际数据进行分配
- 长度超过定义长度时无法存入
3)大文本类型(TEXT)
- 能存储超过65535字符的数据
- 最大可以存储4G的数据
- 枚举
- ENUM:从给定的几个值中选取1个
- SET: 从给定的值中选取1个或多个
- 日期时间类型
- 日期:DATE,范围’1000-01-01’~’9999-12-31;
- 时间:TIME
- 日期时间:DATETIME, 范围’1000-01-01 00:00:00’ ~ ‘9999-12-31 23:59:59’
- 时间戳类型:TIMESTAMP
创建表
1)建表之前,要进入库
2)建表语法
CREATE TABLE 表名称(
字段1 类型(长度) 约束,字段2 类型(长度) 约束,
……)[字符集];
查看表结构
1)查看表结构:DESC表名称;
2)查看建表语句:SHOW CREATE TABLE 表名
删除表
1)语法:DROP TABLE 表名
表记录管理(重点内容)
- 查询记录
- 语法格式
SELECT * FROM 表名 [WHERE 条件];
SELECT 字段1, 字段2…
FROM 表名 [WHERE 条件];
- 语法格式
表结构调整
- 添加表头字段
1)语法- 添加到表的最后一个字段
ALTER table 表名 ADD 字段名 类型(长度) - 添加到表的第一个字段
ALTER table 表名 ADD 字段名 类型(长度) first - 指定添加到某个字段后面
ALTER table 表名 ADD 字段名 类型(长度)
after 字段名称
- 添加到表的最后一个字段
- 修改表头字段
1)修改字段类型
ALTER TABLE 表名 modify 字段 类型(长度)
2)修改字段名称
ALTER TABLE 表名
change 旧字段名 新字段名 类型(长度) - 删除表头字段
1)语法:ALTER TABLE 表名 DROP 字段名
表内容调整
- 插入记录
1)所有字段都插入值
INSERT INTO 表名VALUES
(‘xxxxx’,’xxxxxx’,xxx…..);
查询:select * FROM 表名;
说明:values后面没有指定字段,表示插入所有值列表个数、顺序、类型要和表结构严格对应字符串类型必须要单引号引起来now()函数表示取数据库当前时间- 向表中插入指定字段值
语法:insert INTO 表(字段列表)
VALUES(值列表)
- 修改表内容
语法
UPDATE 表名SET 字段1 = 值1,字段2 = 值2,
…
WHERE 条件表达式; - 删除表内容
- 语法
DELETE FROM 表名 WHERE 条件表达式; - 特别注意
1)进行严格条件限定,如果不带条件删除所有
2)真实项目中,删除、修改数据之前一定要备份
四、结构化查询语言(SQL)
查询
- 带比较操作符的查询:>,<,>=,<=,<>(或!=)
- 逻辑运算符:AND,OR
- and: 多个条件同时满足
- or: 满足其中一个
- 范围比较
1)between…AND…: 在…和…之间(包含两边)
2)in/NOT in: 在/不在某个指定的范围
- 模糊查询
1)格式:where 字段 LIKE “通配字符”
2)通配符匹配
下划线(_): 匹配单个字符
百分号(%): 匹配任意个字符
3)注意事项:
模糊查询不精确匹配,速度较慢
尽量避免%前置
- 空值、非空判断
1)语法
判断空值:字段 IS NULL
判断非空:字段 IS NOT NULL
- ORDER BY: 排序
格式:order BY 字段 [ASC/DESC] ASC-升序 DESC-降序 - limit子句
1)作用:限制显示的笔数
2)格式
limit n 只显示前面n笔
limit m,n 从第m开始,总共显示n笔 - distinct子句
1)作用:去除重复数据
2)语法格式:SELECT DISTINCT(要去重的字段)FROM 表名 - 聚合函数
1)什么是聚合:不是直接查询表中的数据,
而是对数据进行总结,返回结果
2)聚合函数有:
max 求最大值MIN 求最小值AVG 求平均值SUM 求和COUNT 统计笔数-- 统计订单笔数SELECT COUNT(*) FROM orders;
说明:对某个字段调用聚合函数时,如果字段的值为空,不会参与聚合操作
- 分组:group BY
1)作用:对查询结果进行分组,通常和聚合函数
搭配使用
2)语法格式:group BY 字段-Having:对分组结果进行过滤
1)作用:对分组结果进行过滤,需要和group BY语句配合使用
2)语法格式
GROUP BY 分组字段 HAVING 过滤条件
说明:group by分组聚合的结果,只能用
having,不能用where,where只能用户表中有的字段作为条件时候
高级查询
- 子查询
1)定义:一个查询语句中嵌套另一个查询
2)说明:- 括号中的部分称为子查询
- 子查询可以返回一个值,也可以多个值根据外层查询的要求来决定
- 先执行子查询,将子查询的结果,作为外层查询的条件,再执行外层查询
- 子查询只执行一遍
3)使用子查询的情况:一个语句无法查出来,或者不方便查询出结果,使用子查询
- 联合查询
1)什么是联合查询:也叫连接查询,将多个表中的数据进行连接,得到一个查询结果集
2)什么情况下使用联合查询:当从一个表无法查询到所有想要的数据时,使用联合查询。
前提:联合的表之间一定要有逻辑上的关联性
SELECT a.表头字段1, a.表头字段2,
b.表头字段1, b.表头字段2
FROM 表1 a, 表2 b
WHERE a.表头关联字段= b.表头关联字段;
3)笛卡尔积(联合查询的理论依据)- 什么是笛卡尔积:两个集合的乘积,产生一个新的集合。表示两个集合所有的可能的组合情况
- 笛卡尔积和关系:笛卡尔积中,去掉没有意义或不存在的组合,就是关系(规范的二维表)
- 连接查询
- 内连接
(INNER Join):没有关联到的数据不显示 - 外连接
(OUTER Join):没有关联到的数据也要显示到结果集 - 左连接
以左边为基准,右表的数据进行关联
左表数据全部显示,右表中的字段
如果没有关联到,则显示NULL
LEFT JOIN 实现
SELECT a.表头字段1, a.表头字段2,
b.表头字段1, b.表头字段2
FROM表1名a LEFT JOIN表2名b
ON a.表头关联字段= b.表头关联字段; - 右连接:
以右边为基准,左表的数据进行关联
右表数据全部显示,左表中的字段
如果没有关联到,则显示NULL
right JOIN 实现
SELECT a.表头字段1, a.表头字段2,
b.表头字段1, b.表头字段2
FROM表1名aRIGHT JOIN表2名b
ON a.表头关联字段= b.表头关联字段;
- 内连接
约束(Constraint)
- 什么是约束:
数据必须遵循的规则 - 目的:
保证数据一致性、完整性
从数据库层面对数据进行安检; - 分类
1)非空约束- 定义:Not null,要求字段的值不能为空
- 语法:字段名称 类型(长度) NOT null
2)唯一约束
- 定义:unique,字段的值不能重复
- 语法:字段名称 类型(长度) unique
3)主键(PRIMARY KEY, 简写PK)
非空、唯一
- 定义:主键在表中唯一标识、区分一个实体非空、唯一
- 语法:字段名称 类型(长度) PRIMARY KEY
4)默认值(DEFAULT constraint)
- 定义:指定某个字段的默认值,如果新插入一笔数据没有对该字段赋值,系统会自动填入一个默认值
- 语法:字段名称 类型(长度) DEFAULT 值
5)自动增长(auto_increment)
- 定义:当字段被设置为自增长时,插入时不需要赋值,系统在原最大值的基础上自动加要求:要求这个字段必须是PK,或设置了unique约束)
- 语法:字段名称 类型(长度) auto_increment
6)外键约束(Foreign Key, 简称FK)
- 什么是外键:一种约束,建立外键的前提是:某个字段在当前表中不是PK,但在另外表(也称为”外表”)是主键
- 作用:保证被参照的实体一定存在(参照的完整性)
- 字段被设置外键约束后,影响有:
当插入一个在外表中不存在的实体是,报错
当删除外表中已经被参照的实体,报错 - 创建外键语法:
字段名称 类型(长度) ,
— 所有字段定义完成后
CONSTRAINT 外键名称 FOREIGN KEY(当前表字段)REFERENCES 外表(字段名)
7)通过修改字段方式添加约束
通过修改表定义语句添加约束
alter table表名add primary key(表头字段); — 添加主键
alter table 表名modify id int autoincrement; — 添加自增长
alter table表名modify status int default 0; — 添加默认值0
alter table 表名modify tel_no varchar(32) unique; — 添加唯一约束
alter table 表名add CONSTRAINT fk表头字段— 添加外键约束
FOREIGN KEY(表头字段)
REFERENCES 引用副键所在表名(主键表头字段);
索引(重点)
概述
- 什么是索引:
提高查询效率的一种技术 - 原理:
根据某一列(字段)进行分段、排序,通过避免全表扫描提高查询效率
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表,
索引的原理:就是把无序的数据变成有序的查询
1.把创建了索引的列的内容进行排序
2.对排序结果生成倒排表
3.在倒排表内容上拼上数据地址链
4.在查询的时候,先拿到倒排表内容,再再取出数据地址链,,从而拿到具体数据
- 索引分类
1)普通索引、唯一索引
普通索引:MySQL基本类型,字段值可以重复
唯一索引:字段的值不能重复(可以为空)
2)单列索引、组合索引联合索引
单列索引:一个索引只包含一个字段
组合索引:一个索引包含多个字段(建议不要超过5个字段)
最左前缀法则(所和命中联合索引中的索引列)
- 3)聚集索引、非聚集索引
聚集索引(Cluster Index): 索引的键值顺序和数据顺序是一致的
非聚集索引:索引的键值顺序和数据顺序不一致的 - 4)全文索引
进行查询的时候,数据源可能来自于不同的字段或者不同的表。比如去百度中查询数据,来自于网页的标题或者网页的内容。MyISAM存储引擎支持全文索引。在实际生产环境中,并并不会使用MySQL提供的MylSAM存储引擎的全文索引功能来是实现全文查找。而是会使用第三方的搜索引擎中间件比如ElasticSearch、 Solr。
创建索引
- 语法:建表语句( 字段1,字段2……index(需添加索引字段)| UNIQUE(需添加索引字段)| PRIMARY KEY)
- 删除索引
- 语法:drop INDEX 索引名称 ON 表名称;
- 修改表的方式添加索引
- 语法: CREATE 索引类型 索引名称 ON 表(字段)
- 索引的优缺点
- 优点
提高查询效率
唯一索引能够保证数据的唯一性
可能提高分组、排序的效率 - 缺点
降低增、删、改的效率(调整索引结构的开销)
对表中的数据进行增删改操作,需要调整索引结构
需要增加额外的存储空间- 索引使用注意事项
- 总体原则
在合适的字段上,建立合适的索引
索引不能太多,过多的索引会降低增删改效率 - 适合使用索引的情况
在经常进行查询、排序、分组的字段上建立索引
数据分布比较均匀、连续的字段,适合建立索引
查询操作较多的表,适合建立索引 - 不适合建立索引的情况
数据量太少的表不适合建立索引
增删改操作较多的表,不适合建立较多的索引
某个字段取值范围很少,不适合建索引
某个字段很少用作查询、排序、分组,不适合建索引
二进制字段不适合建立索引- 索引失效的SQL语句
索引失效:表中有索引,但是查询时候没有使用
- 索引失效的SQL语句
- 没有使用索引字段作为条件,会导致放弃使用索引
- 条件判断中使用了<>符号,会导致放弃使用索引
- 条件判断语句中使用了null值判断,会导致放弃使用索引
- 模糊查询%前置,会导致放弃使用索引
- 对字段做运算,会导致放弃使用索引
索引的数据结构
线性表顺序存储结构
链式存储结构、单向链表、双向链表
栈和队列
顺序栈、链栈、顺序队列、链式队列
串String
定长串、动态串
数组和广义表
一维数组、多维数组、广义表
树
二叉树、平衡二叉树、完全二叉树、红黑树、B树、B+树
1.线性表:
线性的维护数据的顺序
对于线性表来说,有两种数据结构来支撑:
- 线性顺序表:相邻两个数据的逻辑关系和物理位置是相同的。
- 线性链式表:相邻两个数据的逻辑关系和物理存放位置没有关系。数据是有先后的逻辑关系,但是数据的物理存储位置并不连续。
- 单向链表:能够通过当前结,点找到下一个节点的位置,以此来维护链表的逻辑关系
结点结构:
数据内容+下一个数据的指针
- 双向链表:能够通过当前结点找到_上一个或下一个节点的位置,双向都可找。
结点结构:上一个数据的指针+数据内容+下一个数据的指针
顺序表和链式表的区别:
- 数组:进行数据的查询性能(可以通过数组的索引/下标):时间复杂度(比较次数)/空间复杂度(算法需要使用多少个变量空间)
数组的查询性能非常好:时间复杂度是O(1)。
数组的增删性能是非常差的
- 链表:查询的性能是非常差的: 时间复杂度是0(n).
增删性能非常好
2.栈、队列、串、广义表
- 栈:先进后出,有顺序栈、链式栈
- 队列:先进先出,有顺序队列、链式队列
- 串:String定长串、StringBuffer/Stringbuilder动态串
- 广义表:更加灵活的多维数组,可以在不同的元素中创建不同的维度的数组。
3.树
查找树的查找性能是明显比线性表的性能要好,那么接下来我们就要学习这么几种树:
1) 多叉树
非二叉树
2) 二叉树
一个结点最多只能有2个子结点,可以是0、1、2子结点。
满二叉树:
高度为h,由2h-1个节点构成的二叉树称为满二叉树。即除叶子节点外所有节点都有二个分支
完全二叉树:
完全二叉树是由满二叉树而引出来的,若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数(即1~h-1层为一个满二叉树),第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。堆一般都是用完全二叉树来实现的。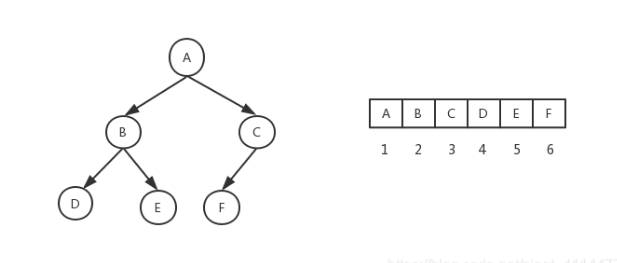
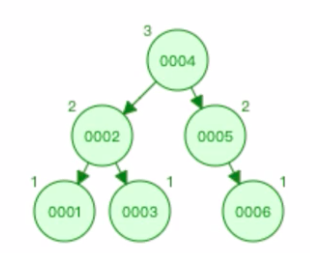
3) 二叉查找树
二叉查找树的查找性能是ok的,查询性能跟树的高度有关,树的高度又根你插,入数据的顺序有关系。特点:二叉树的根结点的数值是比所有左子树的结点的数值大,比右子树的几点的数值小。这样的规律同样满足于他的所有子树。
4) 平衡二叉树(理想概念树)
我们知道二叉查找树不能非常智能的维护树的高度,因此二叉查找树在某些情况下查询性能是不ok的,此时平衡二叉树就出现了。
特点:平衡二叉树中的树及其所有子树都应满足:左子树和右子树的深度差不能超过1
如果平衡二叉树不满足这个特点,那么平衡二叉树要进行自己旋转,如何自己旋转:
左旋、右旋、双向(先左后右、先右后左)
为了排除动态查找表中不同的数据排列方式对算法性能的影响,需要考虑在不会破坏二叉排序树本身结构的前提下,将二叉排序树转化为平衡二叉树.
例如,使用上一节的算法在对查找表{13,24,37,90,53}构建二叉排序树时, 当插入13和24时,二叉排序树此时还是平衡二叉树: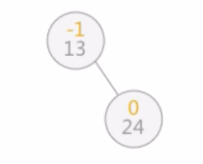
当继续插入37时,生成的二叉排序树如图3(a),平衡二叉树的结构被破坏,此时只需要对二叉排序树做“旋转”操作(如图3 (b) ),即整棵树以结点24为根结点,二叉排序树的结构没有破坏,同时将该树转化为了平衡二叉树: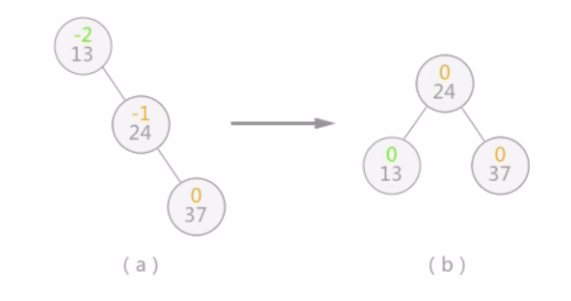
当二叉排序树的平衡性被打破时,就如同扁担的两头出现了一头重一 -头轻的现象,如图3a)所示,此时只需要改变扁担的支撑点(树的树根),就能使其重新归为平衡。实际上图中的(b)是对(a) 的二叉树做了一个向左逆时针旋转的操作。
继续插入90和53后,二叉排序树如下图(a)所示,导致二叉树中结点24和37的平衡因子的绝对值大于1,3整棵树的平衡被打破。
此时,需要做两步操作:
1.如图(b)所示,将结点53和90整体向右顺时针旋转,使本该以90为根结点的子树改为以结点53为根结点;
2.如图(c)所示,将以结点37为根结,点的子树向左逆时针旋转,使本该以37为根结点的子树,改为以结点53为根结点;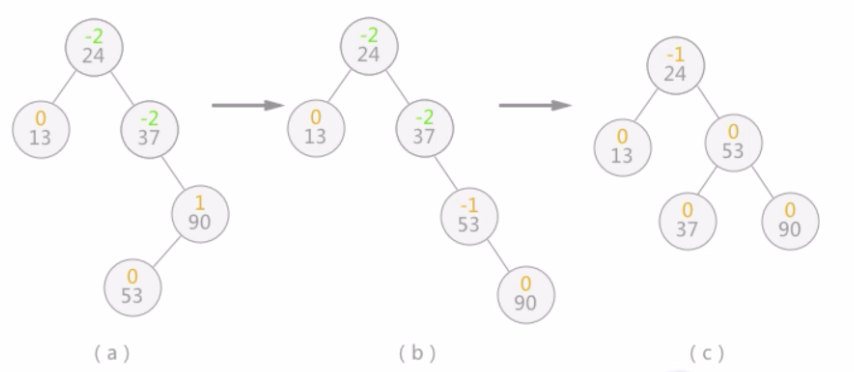
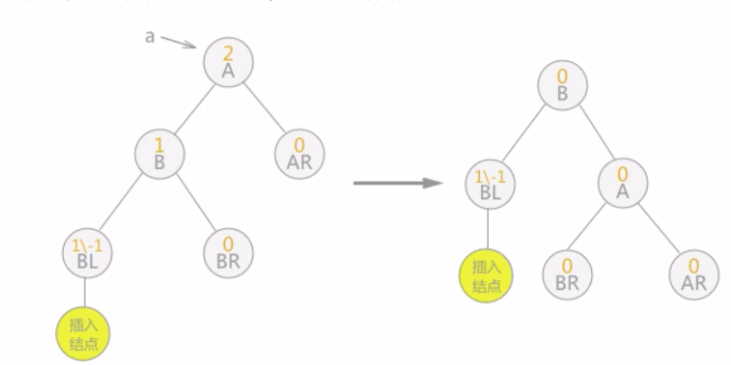
做完以上操作,即完成了由不平衡的二叉排序树转变为平衡二叉树。当平衡二叉树由于新增数据元素导致整棵树的平衡遭到破坏时,就需要根据实际情况做出适当的调整,假设距离插入结点最近的“不平衡因子”为a。则调整的规律可归纳为以下4种情况:
单向右旋平衡处理:若由于结点a的左子树为根结点的左子树上插入结点,导致结点a的平衡因子由1增至2,致使以a为根结点的子树失去平衡,则只需进行一次向右的顺时针旋转,如下图这种情况:
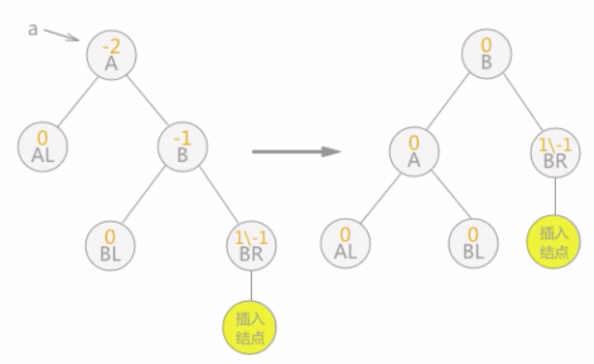
单向左旋平衡处理:如果由于结点a的右子树为根结点的右子树上插入结点,导致结点a的平衡因子由-1变为-2,则以a为根结点的子树需要进行一次向左的逆时针旋转,如下图这种情况:
双向旋转(先左后右)平衡处理:如果由于结点a的左子树为根结点的右子树上插入结点,导致结点a平衡因子由1增至2,致使以a为根结点的子树失去平衡,则需要进行两次旋转操作,如下图这种情况: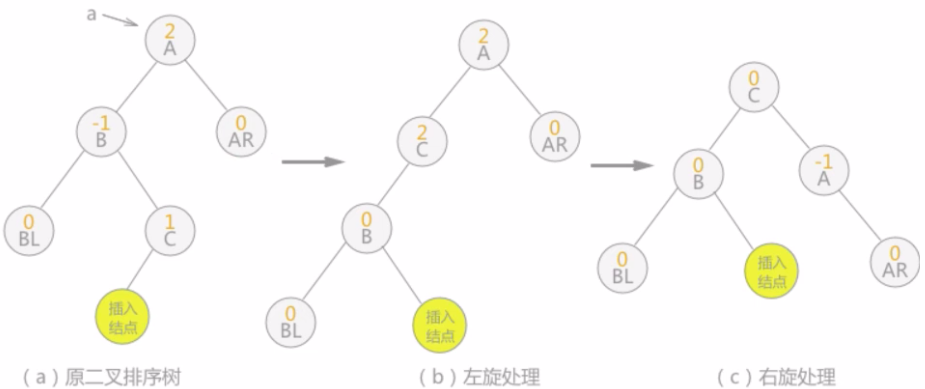
注意:上图中插入结点也可以为结点C的右孩子,则(b)中插入结点的位置还是结点C右孩子,,(c)中插入结点的位置为结点A的左孩子。
双向旋转(先右后左)平衡处理:如果由于结点a的右子树为根结点的左子树.上插入结点,导致结点a平衡因子由-1变为-2,致使以a为根结点的子树失去平衡,则需要进行两次旋转(先右旋后左旋)操作,如下图这种情况: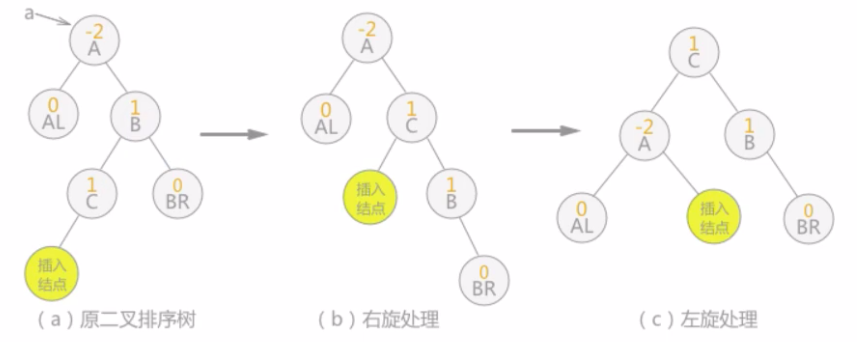
注意:上中插入结点也可以为结点C的右孩子,则(b)中插入结点的位置改为结点B的左孩子,(c)中插入结点的位置为结点B的左孩子。在对查找表{13,24,37,90,53}构建平衡二叉树时,由于符合第4条的规律,所以进行先右旋后左旋的处理,最终由不平衡的二叉排序树转变为平衡二叉树。
5) 红黑树(平衡二叉树的一种实现)
平衡二叉树为了维护树的平衡,在一旦不满足平衡的情况就要进行自旋,但是自旋会造成一定的系统开销。因此红黑树在自旋造成的系统开销和减少查询次数之间做了权衡。因此红黑树有时候并不是一颗平衡二叉树。
红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
性质1.结点是红色或黑色。
性质2.根结点是黑色。
性质3.不可能有连在一起的红色节点。
性质4.每个红色结点的两个子结点都是黑色。叶子结点都是黑色(nil-黑色的空节点)
这些约束强制了红黑树的关键性质:从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致,上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
红黑树已经是在查询性能上得到了优化,但索引依然没有使用红黑树作为数据结构来存储数据,因为红黑树在每一层上存放的数据内容是有限的,导致数据量一大,树的深度就变得非常大,于是查询性能非常差。因此索引没有使用红黑树。
6) B树
B树允许一个结点存放多个数据。这样可以使更小的树的深度来存放更多的数据。但是,,B树的一个结,点中到底能存放多少个数据,决定了树的深度。
通过数值计算,B树的一个结点最多只能存放15个数据,因此B树依然不能满足海量数据的查询性能优化。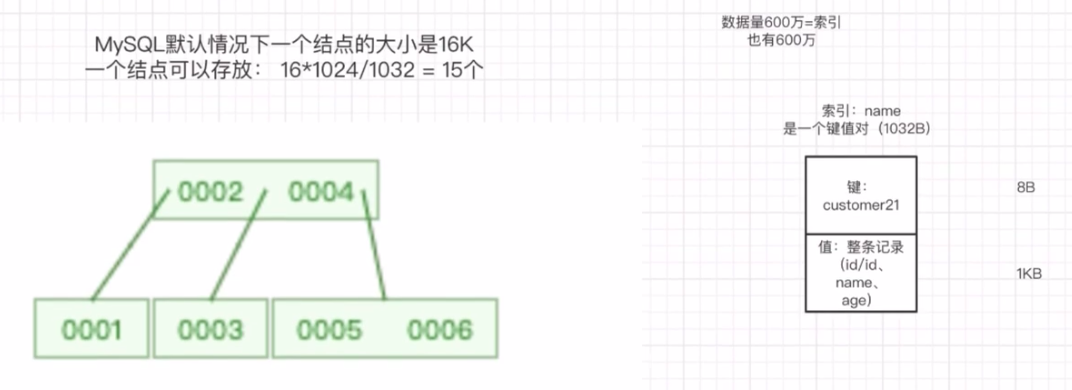
7) B+树
- 非叶子结点冗余了叶子结点中的键
- 叶子结点是从小到大、从左到右排列的
- 叶子结点之间提供了指针,提高了区间访问的性能
- 只有叶子结点存放数据,非叶子结点是不存放数据的,只存放键
8) 哈希表
使用哈希表来存取数据的性能是最快的,O(1),但是不支持范围查找(区间访问)
五、数据导入导出
1. 导出
1)show variables LIKE ‘secure_file%’;
结果:/var/lib/mysql-files/
导出只能导出到该目录
导入只能从该目录导入
2)语法
select查询语句
INTO outfile ‘文件路径’
fields terminated BY ‘字段分隔符’ ,
lines terminated BY ‘行分隔符’; \n
2. 导入
1)语法
LOAD data infile ‘备份文件路径’
INTO TABLE 表名称
fields terminated BY ‘,’
lines terminated BY ‘\n’;
— 如果要导入的表不为空,先删除表中数据,再执行导入
— 导入完成后,查询、确认
表的复制、重命名
- 表的复制
— 将 旧表数据、表结构全部复制到新表
CREATE TABLE 新表名
SELECT * FROM 旧表;
— 将旧表结构复制到新表
CREATE TABLE 新表
SELECT * FROM 旧表名WHERE false; —查询结果为空
备注:该方式不会将键的属性复制到新表中
- 表的重命名
— 将旧表重命名为新表
3.mysqldump工具
使用mysqldump工具直接导出为SQL文件,这其实是个备份工具,支持数据表及数据库的导出操作。
mysqldump -u 用户名 -p 数据库名 数据表名 > ‘文件路径’
会生成建表语句及数据插入语句。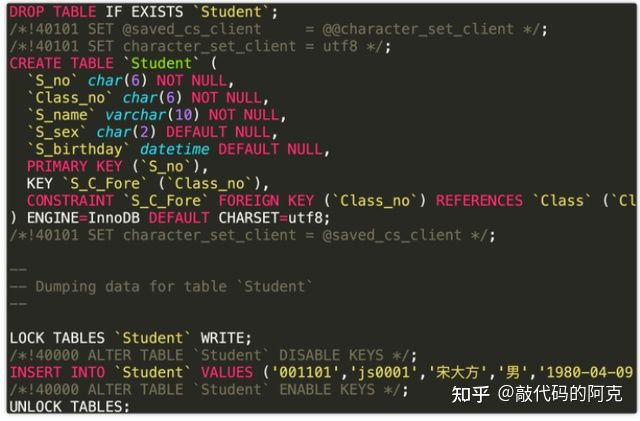
- 数据库转储
mysqldump -u 用户名 -p 数据库名 > ‘文件路径’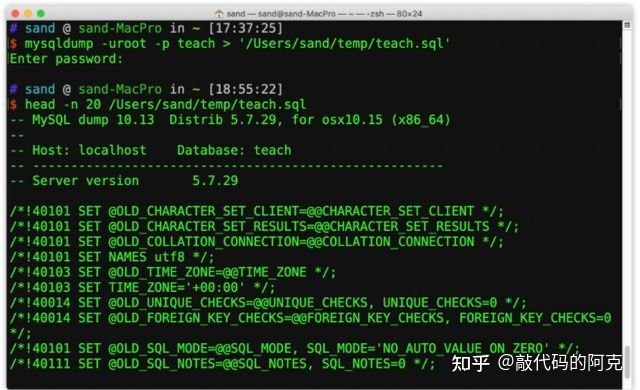
会自动生成数据库中所有表的建表语句以及数据插入语句。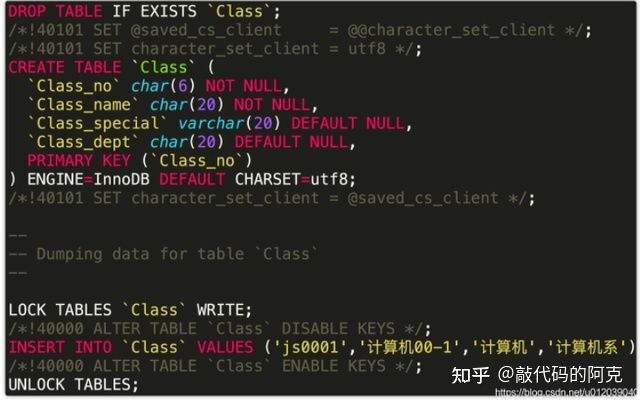
六、权限管理
1. 什么是权限:
用户可以执行操作的权利限制
2. 权限分类
- 1)用户类:
创建/删除/修改用的权限
给其他用户授权的权限 - 2) 库/表操作类:
建库/删库/修改库的权限
建表/删表/修改表的权限 - 3)数据操作类:
增删改查
3. 权限相关的表
- 1)user:
最重要的一个系统表,存储了用户、密码
以及用户所拥有的权限 - 2)db:
记录了库的授权信息 - 3)table_priv:
记录表的授权信息 - 4)column_priv:
记录对字段的授权信息
4. 权限操作
- 1)授予权限
- 语法:
GRANT 权限列表 ON 库名.表名
TO ‘用户名’@’客户端地址’
[identified BY ‘密码’]
[WITH GRANT option];
刷新权限生效
flush privileges; - 说明
权限列表:表示授予哪些权限
ALL privileges: 所有权限
select: 只授予查询权限
select,insert: 授予查询、插入权限
库名.表名:
. -所有库下的所有表
bank.*-bank库下所有表
bank.acct-bank库下的acct表授权
客户端
%: 表示所有的客户端(任意机器)
localhost: 表示只能从本机登录
192.168.1.5: 表示只能从指定的IP机器登录
identified BY ‘密码’:设置用户密码
WITH GRANT option:用户是否有授权的权限
- 语法:
- 2)吊销权限
- 语法:
REVOKE 权限列表 ON 库名.表名
FROM ‘用户名’@’客户端地址;
- 语法:
- 3)查看权限
- 查看自己权限:show grants;
- 查看别人的权限:show grants FOR ‘Tom’@’%’;
5. 锁(理解)
- 概念:对某个范围的控制(操作)权
- 目的:解决两个或多个工作单元并发操作数据引发的问题
- 分类
- 锁类型
读锁(共享锁):select操作加锁,可以进行数据读取,但是不能写入
写锁(排它锁):insert/update/delete时加锁,加锁后的数据不能读、写
- 锁粒度(锁定范围)
行级锁(细粒度):锁定一行,并发效率高,资源消耗多
表级锁(粗粒度):锁定一个表,并发效率低,资源消耗少
七、数据库事务(重点)
1. 什么是事务:
指数据库执行的一组操作(增删改)
要么全都执行,要么全都不执行
2. 作用:
保证数据的一致性、完整性
3. 事务的特点(ACID特性)(重点)
1)原子性(Atomicity):
一个事务是不可分割的整体,要么全都执行,要么全都不执行
2)一致性(Consistency):
事务执行完成后,数据库从一个一致性状态变成下一个一致性状态
3)隔离性(Isolation):
不同的事务不会相互影响
4)持久性(Durability):
一旦事务提交,对数据库的修改会被持久保存到磁盘中
5)如何操作事务
- 启动事务
显式启动:start TRANSACTION;
隐式启动:执行insert,update,delete操作 - 提交事务:commit;
- 回滚:rollback;
6)使用事务的情况及先决条件
- 先决条件:InnoDB存储引擎支持事务
- 使用事务的情况:
一个操作涉及一组SQL语句(增删改语句)
需要这一组操作完成后,保证数据的一致性、完整性
7)事务对效率的影响:
事务降低数据库的性能原因是为了保证数据的一致性、事务的隔离性,事务需要对数据进行加锁;如果有其它事务需要操作这部分加锁的数据,必须等待上一个事务结束(提交、回滚)
8)事务对哪些语句起作用
SQL语句按照功能可以分为4类:
- 数据查询语言(DQL): 查询数据,不会修改数据
- 数据定义语句(DDL):定义库/表/索引
- 数据操作语言(DML):对数据进行增、删、改(数据库事务只对这一类语言起作用)
- 数据控制语言(DCL): 授权/吊销权限,事务管理
八、存储引擎
1. 什么是存储引擎:
表的物理实现方式,由于物理实现不一样,决定不同存储引擎类型的技术特性不一样,例如:存储机制,索引机制,锁定方式
2. 查看存储引擎
1)查看MySQL支持的存储引擎:show engines;
2)查看某个表的存储引擎
show CREATE TABLE 表名称;
3)修改表的存储引擎
ALTER TABLE 表名称 engine = 引擎名称;
3.常用存储引擎
- InnoDB(MySQL5.5及以后的版本默认)
聚簇索引
把索引和数据存放在一个文件中,通过找到索引后就能直接在索引树上的叶子结点中获得完整的数据。
- 特点:支持事务、支持行级锁、支持外键、共享表空间
- 文件构成:.frm: 表的结构、索引,.ibd: 表的数据
如果权限不够,使用sudo -i 进入root用户,进入上面的目录查看 - 什么时候选用InnoDB:
更新(增删改)操作密集的表;要求支持数据库事务、外键;自动灾备和恢复;要求支持自动增长(auto_increment)字段;
- MyISAM
非聚簇索引
把索引和数据存放在两个文件中,查找到索引后还要去另一个文件中找数据,性能会慢一些。
- 特点:支持表级锁定,支持全文索引;不支持事务、外键、行锁定独占表空间;该类存储引擎容易损坏,所以灾备、恢复性能不佳
- 文件构成:.frm -表结 .myd -数据 *.myi -表索引
- 适用场合:查询请求较多;数据一致性要求较低;没有外键约束要求;
- Memory
- 特点:表结构存与磁盘,数据存在内存中 服务器重启或断电后,表中的数据丢失
- 文件:*.frm -表结构
- 使用场合:数据量小;数据需要快速访问;数据丢失不会造成损失;
SELECT
C.COLUMN_NAME AS ‘字段名’,
C.COLUMN_TYPE AS ‘数据类型’,
C.IS_NULLABLE AS ‘允许为空’,
C.COLUMN_KEY AS ‘键类型’,
C.EXTRA AS ‘自增属性’,
C.CHARACTER_SET_NAME AS ‘编码名称’,
C.COLUMN_COMMENT AS ‘字段说明’
FROM
COLUMNS C
INNER JOIN TABLES T ON C.TABLE_SCHEMA = T.TABLE_SCHEMAAND C.TABLE_NAME = T.TABLE_NAME
WHERE T.TABLE_SCHEMA = ‘库名’ and T.table_name=’表名’
<a name="hDH9x"></a>### 删除重复的数据```sqlDELETEFROM表名WHEREid NOT IN (SELECTdt.minnoFROM(SELECTMIN(id) AS minnoFROM表名GROUP BY分组字段名) dt)
替换
UPDATE 表名 SET 字段名=REPLACE(字段名,'str1','str2') WHERE 条件
navicat数据库导出对照表
针对74字段1574条数据的对比
| format | Time consuming | size |
|---|---|---|
| .txt | 3.26s | 3.26MB |
| .csv | 3.20s | 3.26MB |
| .xls | 3,43s | 4.37MB |
| .xlsx | 3.77s | 0.8MB |
| .xml | 3.41s | 5.59MB |
| .json | 3.16s | 6.21MB |

若有收获,就点个赞吧
0 人点赞
