7.2.1 为何要处理数据倾斜(Data Skew)
什么是数据倾斜?
对 Spark/Hadoop 这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一部分(如 Spark 或 Kafka 的一个 Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
如果数据倾斜没有解决,完全没有可能进行性能调优,其他所有的调优手段都是一个笑话。数据倾斜是最能体现一个 spark 大数据工程师水平的性能调优问题。
数据倾斜如果能够解决的话,代表对 spark 运行机制了如指掌。数据倾斜俩大直接致命后果:
- 数据倾斜直接会导致一种情况:Out Of Memory。
- 运行速度慢,特别慢,非常慢,极端的慢,不可接受的慢。
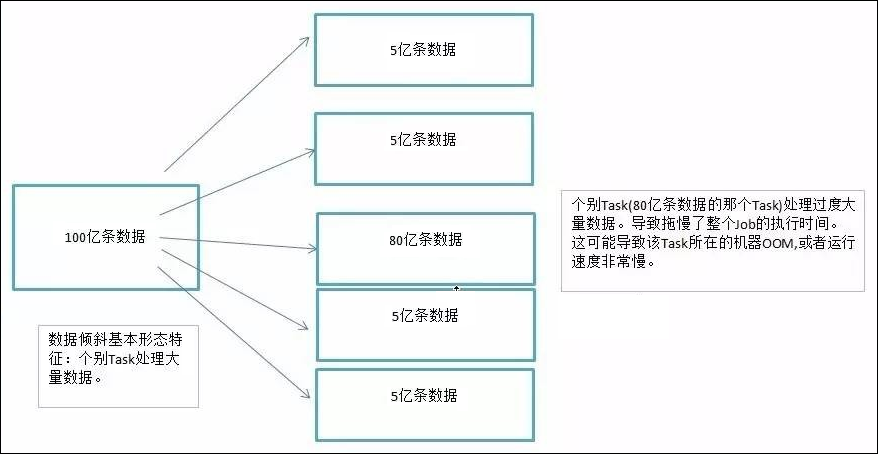
我们以 100 亿条数据为列子。个别 Task(80 亿条数据的那个 Task) 处理过度大量数据。导致拖慢了整个 Job 的执行时间。这可能导致该 Task 所在的机器 OOM,或者运行速度非常慢。
数据倾斜是如何造成的呢?
在 Shuffle 阶段。同样 Key 的数据条数太多了。导致了某个 key(上图中的 80 亿条) 所在的 Task 数据量太大了。远远超过其他 Task 所处理的数据量。而这样的场景太常见了。二八定律可以证实这种场景。
搞定数据倾斜需要:
- 搞定 shuffle
- 搞定业务场景
- 搞定 cpu core 的使用情况
- 搞定 OOM 的根本原因等
所以搞定了数据倾斜需要对至少以上的原理了如指掌。所以搞定数据倾斜是关键中的关键。
一个经验结论是:一般情况下,OOM 的原因都是数据倾斜**。某个 task 任务数据量太大,GC 的压力就很大。这比不了 Kafka,因为 kafka 的内存是不经过 JVM 的,是基于 Linux 内核的 Page。
数据倾斜的原理很简单:在进行 shuffle 的时候,必须将各个节点上相同的 key 拉取到某个节点上的一个 task 来进行处理,比如按照 key 进行聚合或 join 等操作。此时如果某个 key 对应的数据量特别大的话,就会发生数据倾斜。比如大部分 key 对应 10 条数据,但是个别 key 却对应了 100 万条数据,那么大部分 task 可能就只会分配到 10 条数据,然后 1 秒钟就运行完了;但是个别 task 可能分配到了 100 万数据,要运行一两个小时。因此,整个 Spark 作业的运行进度是由运行时间最长的那个 task 决定的。
因此出现数据倾斜的时候,Spark 作业看起来会运行得非常缓慢,甚至可能因为某个 task 处理的数据量过大导致内存溢出。
下图就是一个很清晰的例子:hello 这个 key,在三个节点上对应了总共 7 条数据,这些数据都会被拉取到同一个 task 中进行处理;而 world 和 you 这两个 key 分别才对应 1 条数据,所以另外两个 task 只要分别处理 1 条数据即可。此时第一个 task 的运行时间可能是另外两个 task 的 7 倍,而整个 stage 的运行速度也由运行最慢的那个 task 所决定。
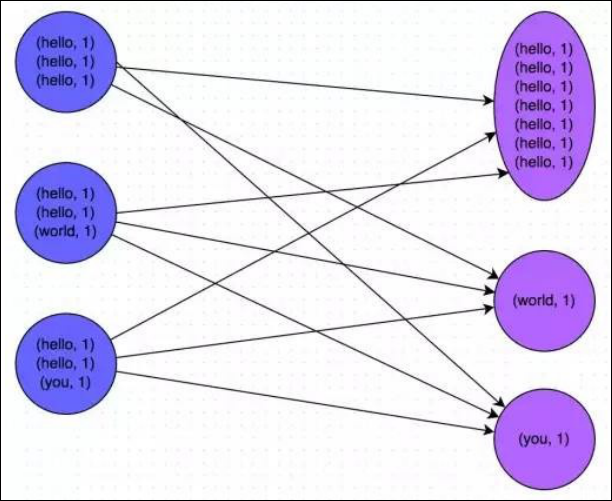
由于同一个 Stage 内的所有 Task 执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同 Task 之间耗时的差异主要由该 Task 所处理的数据量决定。
7.2.2 如何定位导致数据倾斜的代码
数据倾斜只会发生在 shuffle 过程中。这里给大家罗列一些常用的并且可能会触发 shuffle 操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition 等。出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。
某个 task 执行特别慢的情况
首先要看的,就是数据倾斜发生在第几个 stage 中。
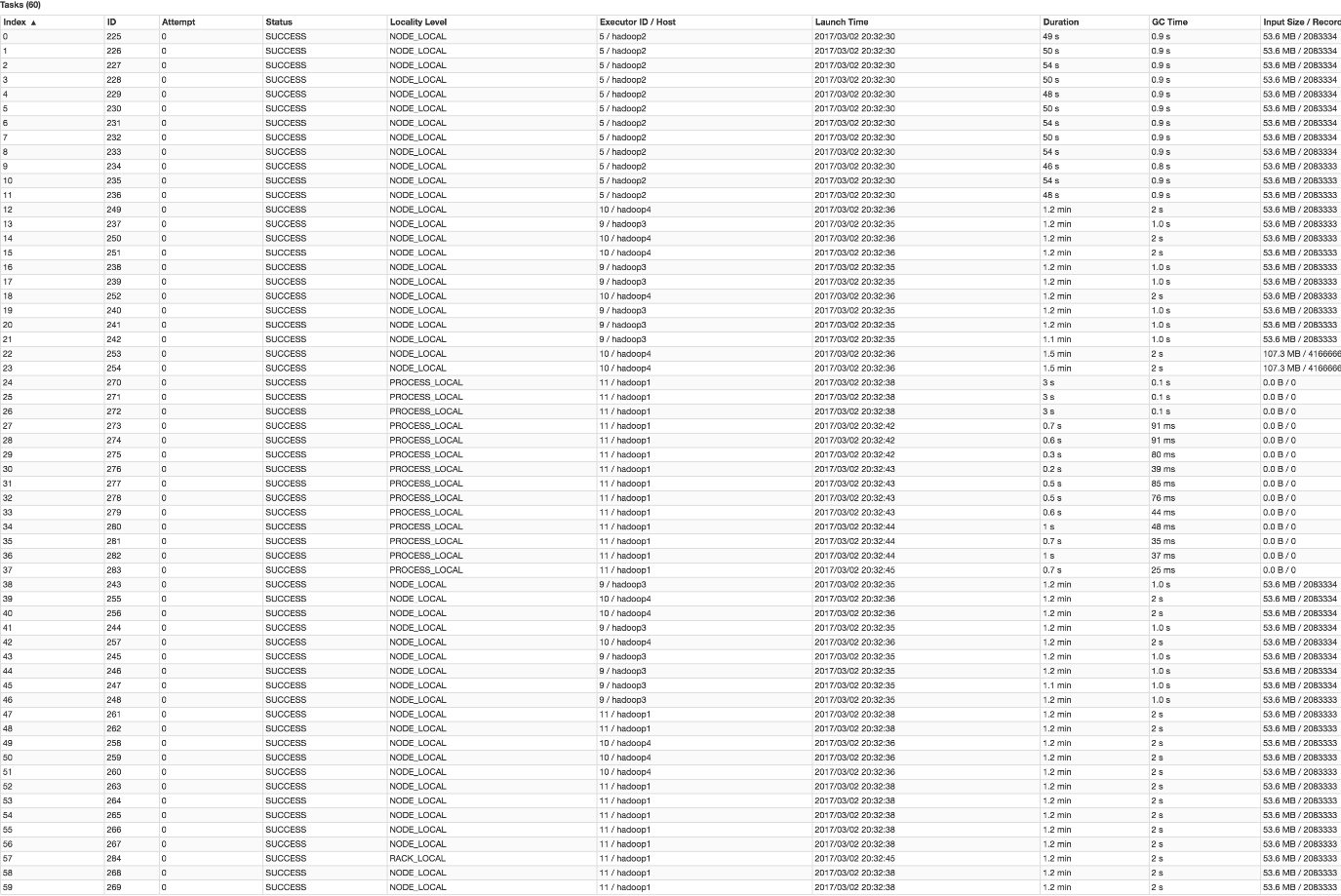
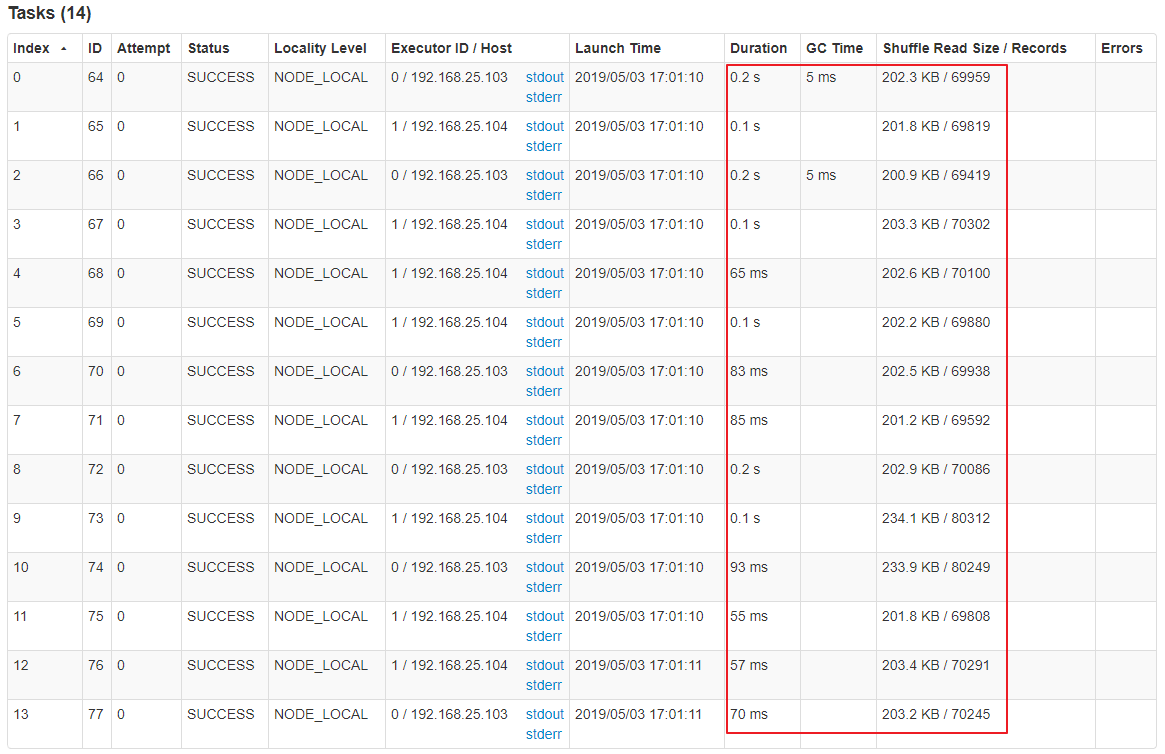
可以通过 Spark Web UI 来查看当前运行到了第几个 stage,看一下当前这个 stage 各个 task 分配的数据量,从而进一步确定是不是 task 分配的数据不均匀导致了数据倾斜。
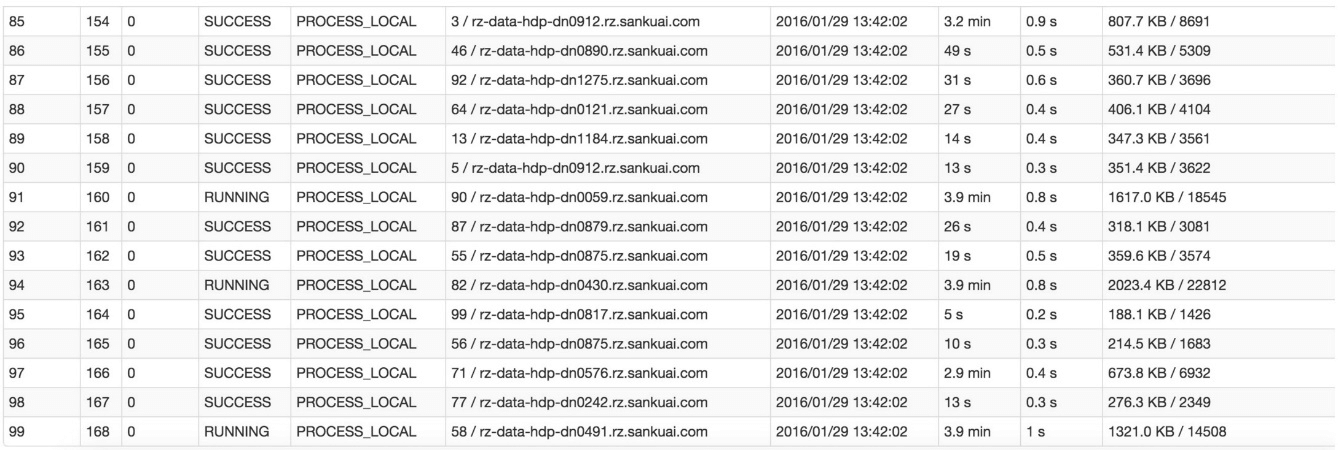
比如下图中,倒数第三列显示了每个 task 的运行时间。明显可以看到,有的 task 运行特别快,只需要几秒钟就可以运行完;而有的 task 运行特别慢,需要几分钟才能运行完,此时单从运行时间上看就已经能够确定发生数据倾斜了。此外,倒数第一列显示了每个 task 处理的数据量,明显可以看到,运行时间特别短的 task 只需要处理几百 KB 的数据即可,而运行时间特别长的 task 需要处理几千 KB 的数据,处理的数据量差了 10 倍。此时更加能够确定是发生了数据倾斜。
知道数据倾斜发生在哪一个 stage 之后,接着我们就需要根据 stage 划分原理,推算出来发生倾斜的那个 stage 对应代码中的哪一部分,这部分代码中肯定会有一个 shuffle 类算子。精准推算 stage 与代码的对应关系,这里介绍一个相对简单实用的推算方法:只要看到 Spark 代码中出现了一个 shuffle 类算子或者是 Spark SQL 的 SQL 语句中出现了会导致 shuffle 的语句(比如 group by 语句),那么就可以判定,以那个地方为界限划分出了前后两个 stage。
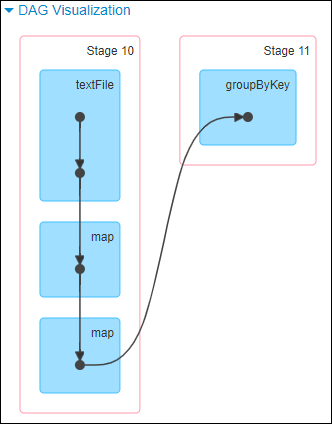
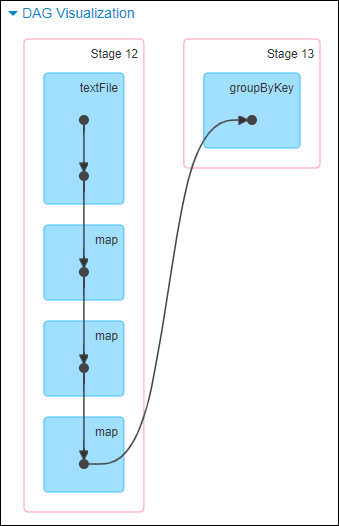
这里我们就以 Spark 最基础的入门程序 — 单词计数来举例,如何用最简单的方法大致推算出一个 stage 对应的代码。如下示例,在整个代码中,只有一个 reduceByKey 是会发生 shuffle 的算子,因此就可以认为,以这个算子为界限,会划分出前后两个 stage。
stage0,主要是执行从 textFile 到 map 操作,以及执行 shuffle write 操作。shuffle write 操作,我们可以简单理解为对 pairs RDD 中的数据进行分区操作,每个 task 处理的数据中,相同的 key 会写入同一个磁盘文件内。
stage1,主要是执行从 reduceByKey 到 collect 操作,stage1 的各个 task 一开始运行,就会首先执行 shuffle read 操作。执行 shuffle read 操作的 task,会从 stage0 的各个 task 所在节点拉取属于自己处理的那些 key,然后对同一个 key 进行全局性的聚合或 join 等操作,在这里就是对 key 的 value 值进行累加。stage1 在执行完 reduceByKey 算子之后,就计算出了最终的 wordCounts RDD,然后会执行 collect 算子,将所有数据拉取到 Driver 上,供我们遍历和打印输出。
示例代码:
val conf = new SparkConf()val sc = new SparkContext(conf)val lines = sc.textFile("hdfs://...")val words = lines.flatMap(_.split(" "))val pairs = words.map((_, 1))val wordCounts = pairs.reduceByKey(_ + _)wordCounts.collect().foreach(println(_))
通过对单词计数程序的分析,希望能够让大家了解最基本的 stage 划分的原理,以及 stage 划分后 shuffle 操作是如何在两个 stage 的边界处执行的。然后我们就知道如何快速定位出发生数据倾斜的 stage 对应代码的哪一个部分了。比如我们在 Spark Web UI 或者本地 log 中发现,stage1 的某几个 task 执行得特别慢,判定 stage1 出现了数据倾斜,那么就可以回到代码中定位出 stage1 主要包括了 reduceByKey 这个 shuffle 类算子,此时基本就可以确定是由 reduceByKey 算子导致的数据倾斜问题。比如某个单词出现了 100 万次,其他单词才出现 10 次,那么 stage1 的某个 task 就要处理 100 万数据,整个 stage 的速度就会被这个 task 拖慢。
某个 task 莫名其妙内存溢出的情况
这种情况下去定位出问题的代码就比较容易了。我们建议直接看 yarn-client 模式下本地 log 的异常栈,或者是通过 YARN 查看 yarn-cluster 模式下的 log 中的异常栈。一般来说,通过异常栈信息就可以定位到你的代码中哪一行发生了内存溢出。然后在那行代码附近找找,一般也会有 shuffle 类算子,此时很可能就是这个算子导致了数据倾斜。
但是大家要注意的是,不能单纯靠偶然的内存溢出就判定发生了数据倾斜。因为自己编写的代码的 bug,以及偶然出现的数据异常,也可能会导致内存溢出。因此还是要按照上面所讲的方法,通过 Spark Web UI 查看报错的那个 stage 的各个 task 的运行时间以及分配的数据量,才能确定是否是由于数据倾斜才导致了这次内存溢出。
查看导致数据倾斜的 key 的数据分布情况
知道了数据倾斜发生在哪里之后,通常需要分析一下那个执行了 shuffle 操作并且导致了数据倾斜的 RDD/Hive 表,查看一下其中 key 的分布情况。这主要是为之后选择哪一种技术方案提供依据。针对不同的 key 分布与不同的 shuffle 算子组合起来的各种情况,可能需要选择不同的技术方案来解决。
此时根据你执行操作的情况不同,可以有很多种查看 key 分布的方式:
- 如果是 Spark SQL 中的 group by、join 语句导致的数据倾斜,那么就查询一下 SQL 中使用的表的 key 分布情况。
- 如果是对 Spark RDD 执行 shuffle 算子导致的数据倾斜,那么可以在 Spark 作业中加入查看 key 分布的代码,比如
RDD.countByKey()。然后对统计出来的各个 key 出现的次数,collect/take 到客户端打印一下,就可以看到 key 的分布情况。
举例来说,对于上面所说的单词计数程序,如果确定了是 stage1 的 reduceByKey 算子导致了数据倾斜,那么就应该看看进行 reduceByKey 操作的 RDD 中的 key 分布情况,在这个例子中指的就是 pairs RDD 。如下示例,我们可以先对 pairs 采样 10% 的样本数据,然后使用 countByKey 算子统计出每个 key 出现的次数,最后在客户端遍历和打印样本数据中各个 key 的出现次数。
示例代码:
val sampledPairs = pairs.sample(false, 0.1)val sampledWordCounts = sampledPairs.countByKey()sampledWordCounts.foreach(println(_))
7.2.3 如何缓解 / 消除数据倾斜
7.2.3.1 尽量避免数据源的数据倾斜
数据源是 Kafka
以 Spark Stream 通过 DirectStream 方式读取 Kafka 数据为例。由于 Kafka 的每一个 Partition 对应 Spark 的一个 Task(Partition),所以 Kafka 内相关 Topic 的各 Partition 之间数据是否平衡**,直接决定 Spark 处理该数据时是否会产生数据倾斜。
Kafka 某一 Topic 内消息在不同 Partition 之间的分布,主要由 Producer 端所使用的 Partition 实现类决定。如果使用随机 Partitioner,则每条消息会随机发送到一个 Partition 中,从而从概率上来讲,各 Partition 间的数据会达到平衡。此时源 Stage(直接读取 Kafka 数据的 Stage)不会产生数据倾斜。
但很多时候,业务场景可能会要求将具备同一特征的数据顺序消费,此时就需要将具有相同特征的数据放于同一个 Partition 中。一个典型的场景是,需要将同一个用户相关的 PV 信息置于同一个 Partition 中。此时,如果产生了数据倾斜,则需要通过其它方式处理。
数据源是 Hive
**
导致数据倾斜的是 Hive 表。如果该 Hive 表中的数据本身很不均匀(比如某个 key 对应了 100 万数据,其他 key 才对应了 10 条数据),而且业务场景需要频繁使用 Spark 对 Hive 表执行某个分析操作,那么比较适合使用这种技术方案。
方案实现思路:此时可以评估一下,是否可以通过 Hive 来进行数据预处理(即通过 Hive ETL 预先对数据按照 key 进行聚合,或者是预先和其他表进行 join),然后在 Spark 作业中针对的数据源就不是原来的 Hive 表了,而是预处理后的 Hive 表。此时由于数据已经预先进行过聚合或 join 操作了,那么在 Spark 作业中也就不需要使用原先的 shuffle 类算子执行这类操作了。
方案实现原理:这种方案从根源上解决了数据倾斜,因为彻底避免了在 Spark 中执行 shuffle 类算子,那么肯定就不会有数据倾斜的问题了。但是这里也要提醒一下大家,这种方式属于治标不治本。因为毕竟数据本身就存在分布不均匀的问题,所以 Hive ETL 中进行 group by 或者 join 等 shuffle 操作时,还是会出现数据倾斜,导致 Hive ETL 的速度很慢。我们只是把数据倾斜的发生提前到了 Hive ETL 中,避免 Spark 程序发生数据倾斜而已。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark 作业的性能会大幅度提升。
方案缺点:治标不治本,Hive ETL 中还是会发生数据倾斜。
方案实践经验:在一些 Java 系统与 Spark 结合使用的项目中,会出现 Java 代码频繁调用 Spark 作业的场景,而且对 Spark 作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的 Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次 Java 调用 Spark 作业时,执行速度都会很快,能够提供更好的用户体验。
项目实践经验:在美团点评的交互式用户行为分析系统中使用了这种方案,该系统主要是允许用户通过 Java Web 系统提交数据分析统计任务,后端通过 Java 提交 Spark 作业进行数据分析统计。要求 Spark 作业速度必须要快,尽量在 10 分钟以内,否则速度太慢,用户体验会很差。所以我们将有些 Spark 作业的 shuffle 操作提前到了 Hive ETL 中,从而让 Spark 直接使用预处理的 Hive 中间表,尽可能地减少 Spark 的 shuffle 操作,大幅度提升了性能,将部分作业的性能提升了 6 倍以上。
7.2.3.2 调整并行度:分散同一个 Task 的不同 Key
方案适用场景:如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
方案实现思路:在对 RDD 执行 shuffle 算子时,给 shuffle 算子传入一个参数,比如 reduceByKey(1000),该参数就设置了这个 shuffle 算子执行时 shuffle read task 的数量。对于 Spark SQL 中的 shuffle 类语句,比如 group by、join 等,需要设置一个参数,即 spark.sql.shuffle.partitions,该参数代表了 shuffle read task 的并行度,该值默认是 200,对于很多场景来说都有点过小。
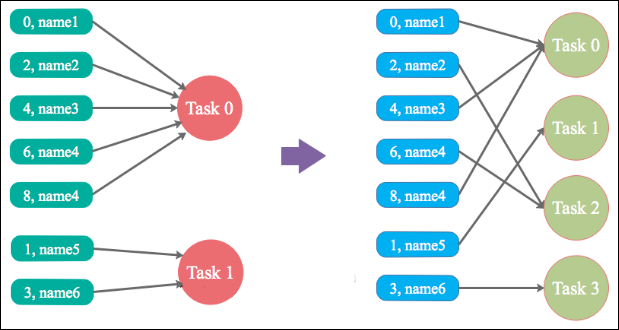
方案实现原理:增加 shuffle read task 的数量,可以让原本分配给一个 task 的多个 key 分配给多个 task,从而让每个 task 处理比原来更少的数据。举例来说,如果原本有 5 个 key,每个 key 对应 10 条数据,这 5 个 key 都是分配给一个 task 的,那么这个 task 就要处理 50 条数据。而增加了 shuffle read task 以后,每个 task 就分配到一个 key,即每个 task 就处理 10 条数据,那么自然每个 task 的执行时间都会变短了。具体原理如下图所示。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个 key 对应的数据量有 100 万,那么无论你的 task 数量增加到多少,这个对应着 100 万数据的 key 肯定还是会分配到一个 task 中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用最简单的方法缓解数据倾斜而已,或者是和其他方案结合起来使用。
方案实现理解:Spark 在做 Shuffle 时,默认使用 HashPartitioner(非 Hash Shuffle)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,从而造成数据倾斜。如果调整 Shuffle 时的并行度,使得原本被分配到同一 Task 的不同 Key 发配到不同 Task 上处理,则可降低原 Task 所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。
案例
**
现有一张测试数据集,内有 100 万条数据,每条数据有一个唯一的 id 值。现通过一些处理,使得 id 为 90 万之下的所有数据对 12 取模后余数为 8(即在 Shuffle 并行度为 12 时该数据集全部被 HashPartition 分配到第 8 个 Task),其它数据集 id 不变,从而使得 id 大于 90 万的数据在 Shuffle 时可被均匀分配到所有 Task 中,而 id 小于 90 万的数据全部分配到同一个 Task 中。处理过程如下:
Step1:准备原始数据。
原始数据格式:
20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http://www.booksky.org/BookDetail.aspx?BookID=1050804&Level=120111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http://www.bblianmeng.com/20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http://lib.scnu.edu.cn/............
数据说明:
==========数据格式==========访问时间 用户id 查询词 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/==========数据注意==========其中用户 ID 是根据用户使用浏览器访问搜索引擎时的 Cookie 信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户 ID。数据字段之间用“\t”进行分割。
Step2:给原始数据增加 ID 属性。
处理原理:将 RDD 通过 zipWithIndex** 实现 ID 添加,将 RDD 以制表符分割并转换为 ArrayBuffer,然后通过 mkString 将数据以 Text 输出。
将原始数据上传到到 HDFS 上:
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put ./source.txt /
通过 spark-shell 加载原始数据并转换输出:
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source.txt")scala> val sourceWithIndexRdd = sourceRdd.zipWithIndex.map(tuple => {val array = scala.collection.mutable.ArrayBuffer[String](); array++=(tuple._1.split("\t")); tuple._2.toString +=: array; array.toArray})scala> sourceWithIndexRdd.map(_.mkString("\t")).saveAsTextFile("hdfs://hadoop102:9000/source_index")
HDFS 上查看转换后的结果:
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -ls /source_index
Step3:通过 spark-shell 加载新的数据并进行对应处理。
// 加载添加了id的原始数据scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source_index")sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/source_index MapPartitionsRDD[1] at textFile at <console>:24// 新建一个 case 类代表数据集scala> case class brower(id: Int, time: Long, uid: String, keyword: String, url_rank: Int, click_num: Int, click_url: String) extends Serializabledefined class brower// 通过 case 类创建 Datasetscala> val ds = sourceRdd.map(_.split("\t")).map(attr => brower(attr(0).toInt, attr(1).toLong, attr(2), attr(3), attr(4).toInt, attr(5).toInt, attr(6))).toDSds: org.apache.spark.sql.Dataset[brower] = [id: int, time: bigint ... 5 more fields]// 注册一个临时表scala> ds.createOrReplaceTempView("sourceTable")// 执行新的查询scala> val newSource = spark.sql("SELECT CASE WHEN id < 900000 THEN (8 + (CAST (RAND() * 50000 AS bigint)) * 12 ) ELSE id END, time, uid, keyword, url_rank, click_num, click_url FROM sourceTable")newSource: org.apache.spark.sql.DataFrame = [CASE WHEN (id < 900000) THEN (CAST(8 AS BIGINT) + (CAST((rand(-5486683549522524104) * CAST(50000 AS DOUBLE)) AS BIGINT) * CAST(12 AS BIGINT))) ELSE CAST(id AS BIGINT) END: bigint, time: bigint ... 5 more fields]// 将 900000 之前的 ID 设定为 12 取余为 8 的 ID 集,当并行度为 12 时,会通过 hash 分区器分区到第 8 个任务// 输出新的测试数据scala> newSource.rdd.map(_.mkString("\t")).saveAsTextFile("hdfs://hadoop102:9000/test_data")
Step4:通过上述处理,一份可能造成后续数据倾斜的测试数据已经准备好。
接下来,使用 Spark 读取该测试数据,并通过 groupByKey(12)** 对 id 分组处理,且 Shuffle 并行度为 12。代码如下:
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/test_data/p*")sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/test_data/p* MapPartitionsRDD[1] at textFile at <console>:24scala> val kvRdd = sourceRdd.map(x => { val parm = x.split("\t"); (parm(0).trim().toInt, parm(1).trim()) })kvRdd: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[2] at map at <console>:26scala> kvRdd.groupByKey(12).countres0: Long = 150000scala> :quit
本次实验所使用集群节点数为 3,每个节点可被 Yarn 使用的 CPU 核数为 3,内存为 2GB。在 Spark-shell 中进行提交。
GroupBy Stage 的 Task 状态如下图所示,Task 8 处理的记录数为 90 万,远大于(9 倍于)其它 11 个 Task 处理的 10 万记录。而 Task 8 所耗费的时间为 1 秒,远高于其它 11 个 Task 的平均时间。整个 Stage 的时间也为 1 秒,该时间主要由最慢的 Task 8 决定。数据之间处理的比例最大为 105 倍。
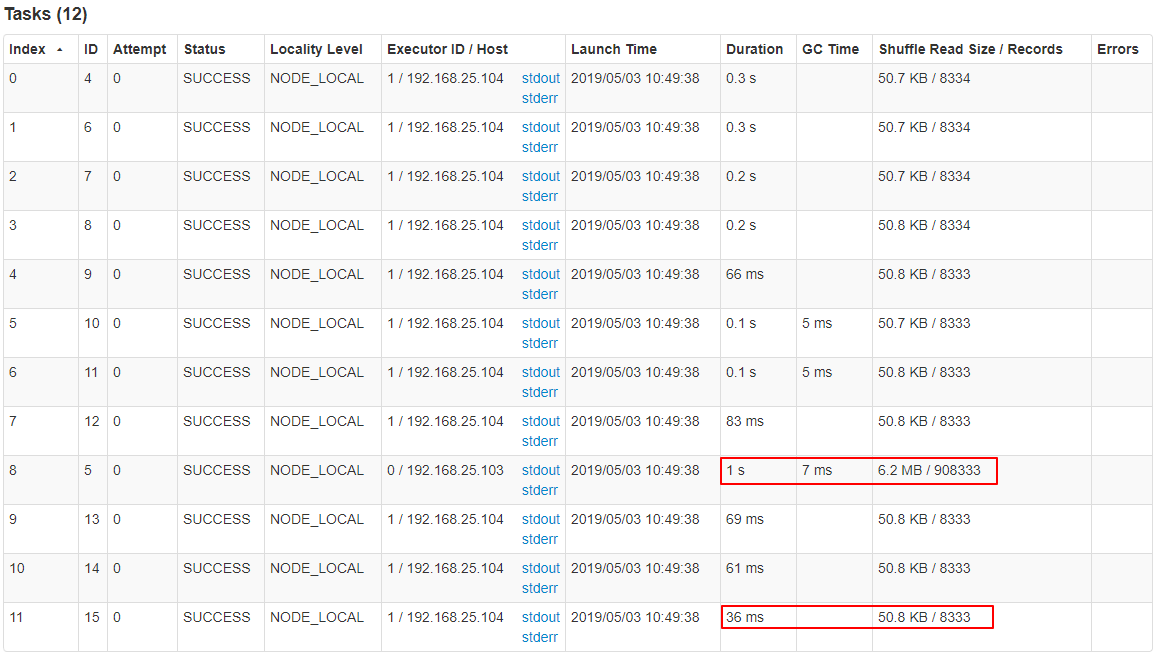
在这种情况下,可以通过调整 Shuffle 并行度,使得原来被分配到同一个 Task(即该例中的 Task 8)的不同 Key 分配到不同 Task,从而降低 Task 8 所需处理的数据量,缓解数据倾斜。
通过 groupByKey(17) 将 Shuffle 并行度调整为 17,重新提交到 Spark。新的 Job 的 GroupBy Stage 所有 Task 状态如下图所示。
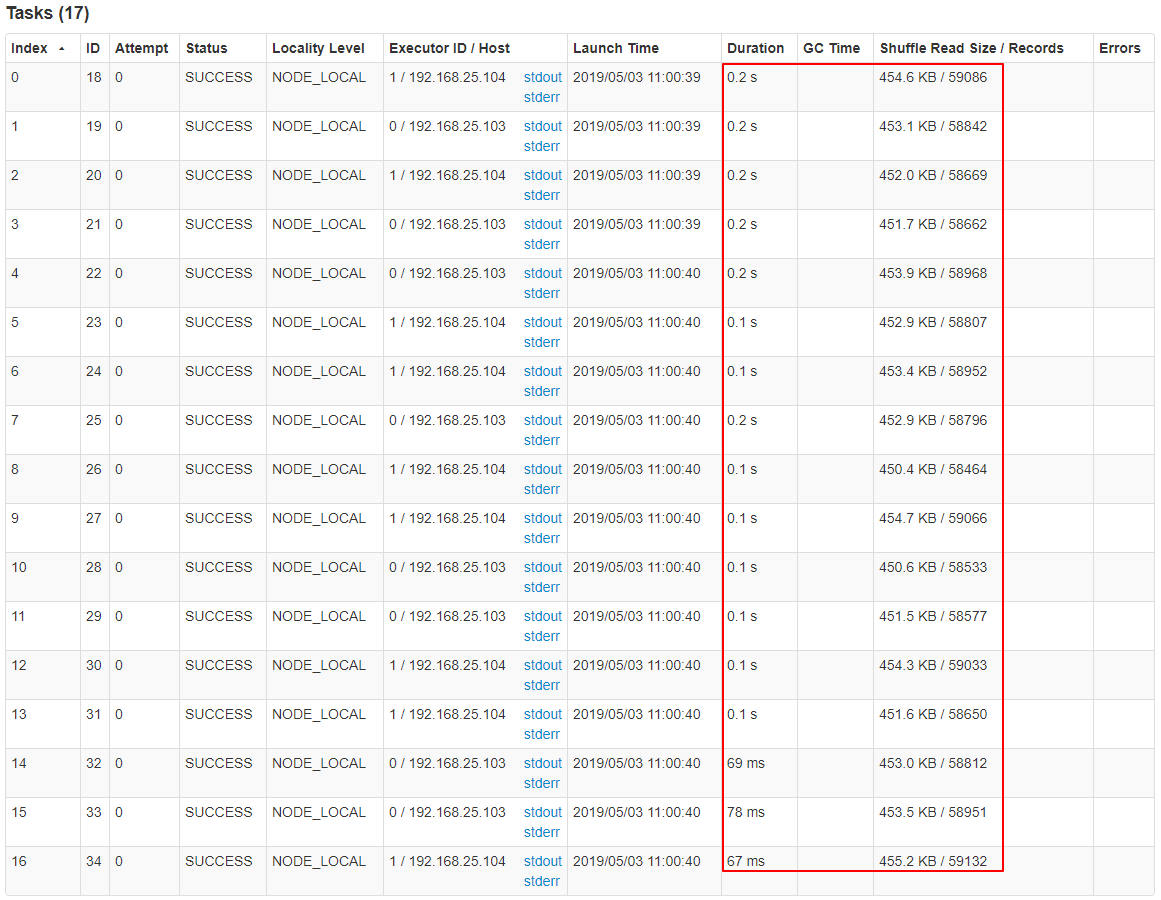
从上图可知,相比以上次一计算,目前每一个计算的数据都比较平均,数据之间的最大比例基本为 1:1,总体时间降到了 0.8 秒。
在这种场景下,调整并行度,并不意味着一定要增加并行度,也可能是减小并行度。如果通过 groupByKey(7) 将 Shuffle 并行度调整为 7,重新提交到 Spark。新 Job 的 GroupBy Stage 的所有 Task 状态如下图所示。
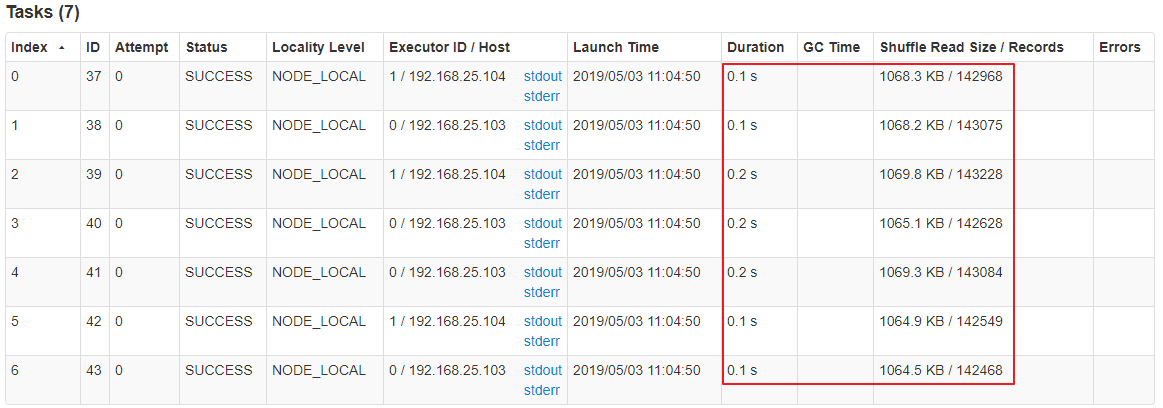
从上图可见,处理记录数都比较平均。
总结:
- 适用场景:大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
- 解决方案:调整并行度。一般是增大并行度,但有时如本例减小并行度也可达到效果。
- 方案优点:实现简单,可在需要 Shuffle 的操作算子上直接设置并行度或者使用
spark.default.parallelism设置。如果是 Spark SQL,还可通过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。 - 方案缺点:适用场景少,只能将分配到同一 Task 的不同 Key 分散开,但对于同一 Key 倾斜严重的情况该方法并不适用。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
7.2.3.3 自定义 Partitioner
方案原理:使用自定义的 Partitioner(默认为 HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task。
案例
**
以上述数据集为例,继续将并发度设置为 12,但是在 groupByKey 算子上,使用自定义的 Partitioner,实现如下:
class CustomerPartitioner(numParts: Int) extends org.apache.spark.Partitioner {// 覆盖分区数override def numPartitions: Int = numParts// 覆盖分区号获取函数override def getPartition(key: Any): Int = {val id: Int = key.toString.toIntif (id <= 900000)return new java.util.Random().nextInt(100) % 12elsereturn id % 12}}
执行如下代码:
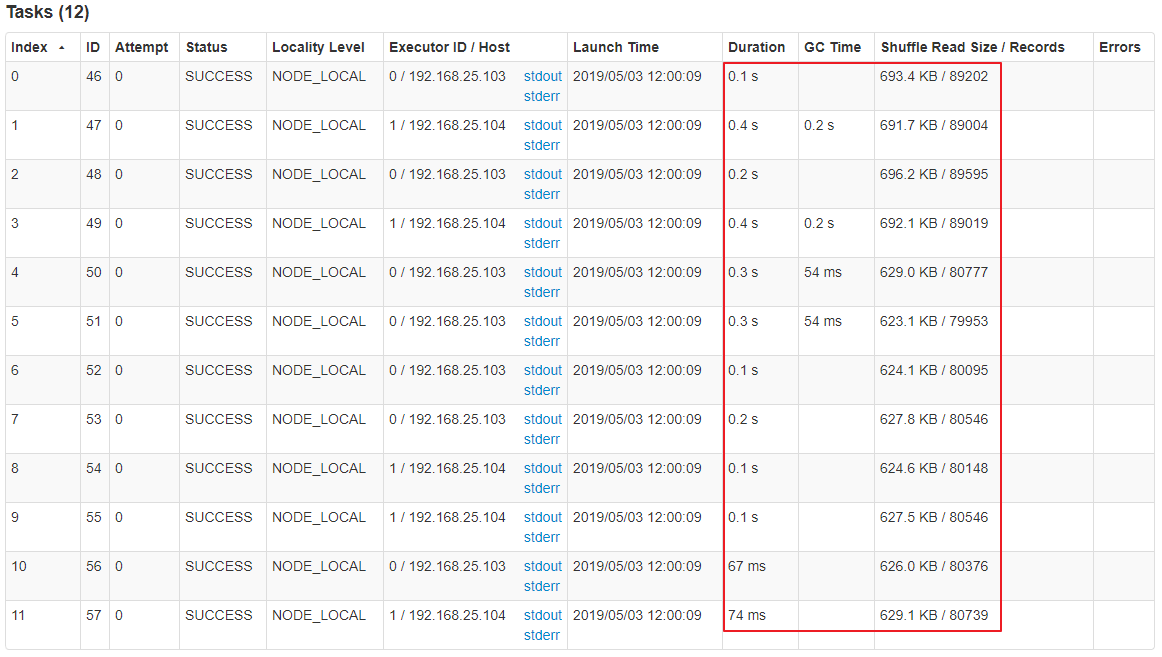
scala> :paste// Entering paste mode (ctrl-D to finish)class CustomerPartitioner(numParts: Int) extends org.apache.spark.Partitioner {// 覆盖分区数override def numPartitions: Int = numParts// 覆盖分区号获取函数override def getPartition(key: Any): Int = {val id: Int = key.toString.toIntif (id <= 900000)return new java.util.Random().nextInt(100) % 12elsereturn id % 12}}// Exiting paste mode, now interpreting.defined class CustomerPartitionerscala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/test_data/p*")sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://hadoop102:9000/test_data/p* MapPartitionsRDD[10] at textFile at <console>:24scala> val kvRdd = sourceRdd.map(x =>{ val parm=x.split("\t");(parm(0).trim().toInt, parm(1).trim()) })kvRdd: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[11] at map at <console>:26scala> kvRdd.groupByKey(new CustomerPartitioner(12)).countres5: Long = 565650scala> :quit
由下图可见,使用自定义 Partition 后,各 Task 所处理的数据集大小相当。
总结**:
- 方案适用场景:大量不同的 Key 被分配到了相同的 Task 造成该 Task 数据量过大。
- 解决方案:使用自定义的 Partitioner 实现类代替默认的 HashPartitioner,尽量将所有不同的 Key 均匀分配到不同的 Task 中。
- 方案优点:不影响原有的并行度设计。如果改变并行度,后续 Stage 的并行度也会默认改变,可能会影响后续 Stage。
- 方案缺点:适用场景有限,只能将不同 Key 分散开,对于同一 Key 对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的 Partitioner,不够灵活。
7.2.3.4 将 Reduce side Join 转变为 Map side Join
方案适用场景:在对 RDD 使用 join 类操作,或者是在 Spark SQL 中使用 join 语句时,而且 join 操作中的一个 RDD 或表的数据量比较小(比如几百 M 或者一两 G),比较适用此方案。
方案实现思路:不使用 join 算子进行连接操作,而使用 Broadcast 变量与 map 类算子实现 join 操作,进而完全规避掉 shuffle 类的操作,彻底避免数据倾斜的发生和出现。将较小 RDD 中的数据直接通过 collect 算子拉取到 Driver 端的内存中来,然后对其创建一个 Broadcast 变量;接着对另外一个 RDD 执行 map 类算子,在算子函数内,从 Broadcast 变量中获取较小 RDD 的全量数据,与当前 RDD 的每一条数据按照连接 key 进行比对,如果连接 key 相同的话,那么就将两个 RDD 的数据用你需要的方式连接起来。
方案实现原理:普通的 join 是会走 shuffle 过程的,而一旦 shuffle,就相当于会将相同 key 的数据拉取到一个 shuffle read task 中再进行 join,此时就是 reduce join。但是如果一个 RDD 是比较小的,则可以采用广播小 RDD 全量数据 +map 算子来实现与 join 同样的效果,也就是 map join,此时就不会发生 shuffle 操作,也就不会发生数据倾斜。具体原理如下图所示。
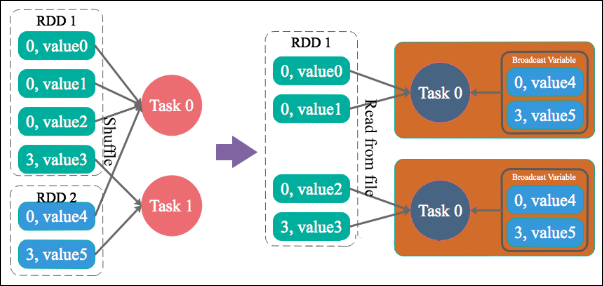
方案优点:对 join 操作导致的数据倾斜,效果非常好,因为根本就不会发生 shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,Driver 和每个 Executor 内存中都会驻留一份小 RDD 的全量数据。如果我们广播出去的 RDD 数据比较大,比如 10G 以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。
案例 1
Step1:准备数据。**
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source_index/p*")scala> val kvRdd = sourceRdd.map(x => { val parm = x.split("\t"); (parm(0).trim().toInt, x) } )scala> kvRdd.firstres6: (Int, String) = (0,0 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/)scala> val kvRdd2 = kvRdd.map(x => { if(x._1 < 900001) (900001, x._2) else x } )scala> kvRdd2.firstres7: (Int, String) = (900001,0 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/)scala> kvRdd2.map(x => x._1 + "," + x._2).saveAsTextFile("hdfs://hadoop102:9000/big_data/")scala> val joinRdd2 = kvRdd.filter(_._1 > 900000)scala> joinRdd2.firstres9: (Int, String) = (900001,900001 20111230093140 5d880d73e96fc08b294999ef87b778ab 凰图腾 4 1 http://www.youku.com/show_page/id_z85090998867b11e0a046.html)scala> joinRdd2.map(x => x._1 + "," + x._2).saveAsTextFile("hdfs://hadoop102:9000/small_data/")
Step2:测试与修正。
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/big_data/p*")scala> val sourceRdd2 = sc.textFile("hdfs://hadoop102:9000/small_data/p*")scala> val joinRdd = sourceRdd.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })scala> val joinRdd2 = sourceRdd2.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })scala> joinRdd.join(joinRdd2).count
通过如下 DAG 图可见,直接通过将 joinRdd(大数据集)和 joinRdd2(小数据集)进行 join 计算,如下:
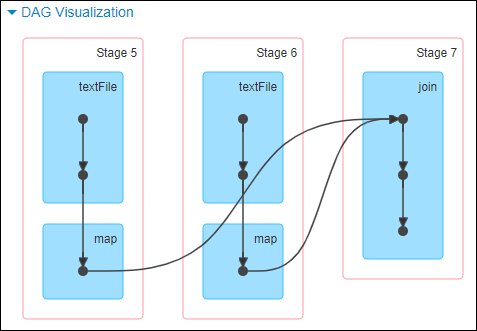
从下图可见,出现数据倾斜。

通过广播变量修正后:
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/big_data/p*")scala> val sourceRdd2 = sc.textFile("hdfs://hadoop102:9000/small_data/p*")scala> val joinRdd = sourceRdd.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })scala> val joinRdd2 = sourceRdd2.map(x => { val parm = x.split(","); (parm(0).trim().toInt, parm(1).trim) })scala> val broadcastVar = sc.broadcast(joinRdd2.collectAsMap) // 把分散的 RDD 转换为 Scala 的集合类型scala> joinRdd.map(x => (x._1, (x._2, broadcastVar.value.getOrElse(x._1, "")))).count
通过如下 DAG 图可见,通过广播变量 + Map 完成了相同的工作(没有发生 shuffle):
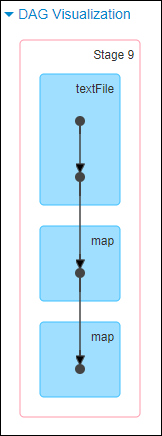
从下图可见,没有出现数据倾斜。

案例 2
Step1:通过如下 SQL 创建一张具有倾斜 Key 且总记录数为 1.5 亿的大表 test。**
INSERT OVERWRITE TABLE testSELECT CAST(CASE WHEN id < 980000000 THEN (95000000 + (CAST (RAND() * 4 AS INT) + 1) * 48 )ELSE CAST(id/10 AS INT) END AS STRING),nameFROM student_externalWHERE id BETWEEN 900000000 AND 1050000000;
使用如下 SQL 创建一张数据分布均匀且总记录数为 50 万的小表 test_new:
NSERT OVERWRITE TABLE test_newSELECT CAST(CAST(id/10 AS INT) AS STRING),nameFROM student_delta_externalWHERE id BETWEEN 950000000 AND 950500000;
Step2:直接通过 **Spark Thrift Server** 提交如下 SQL 将表 test 与表 test_new 进行 Join 并将 Join 结果存于表 test_join 中。
INSERT OVERWRITE TABLE test_joinSELECT test_new.id, test_new.nameFROM testJOIN test_newON test.id = test_new.id;
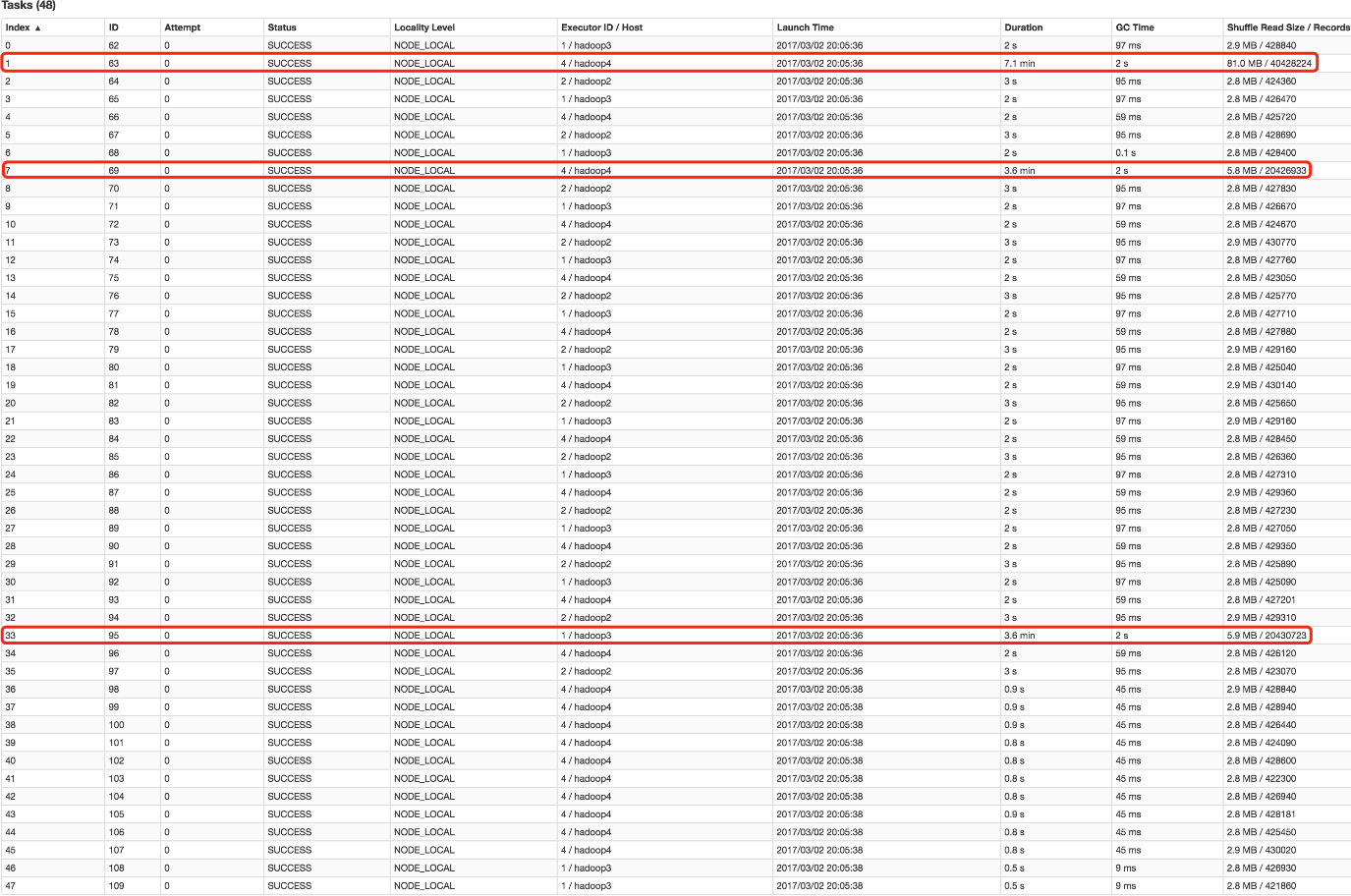
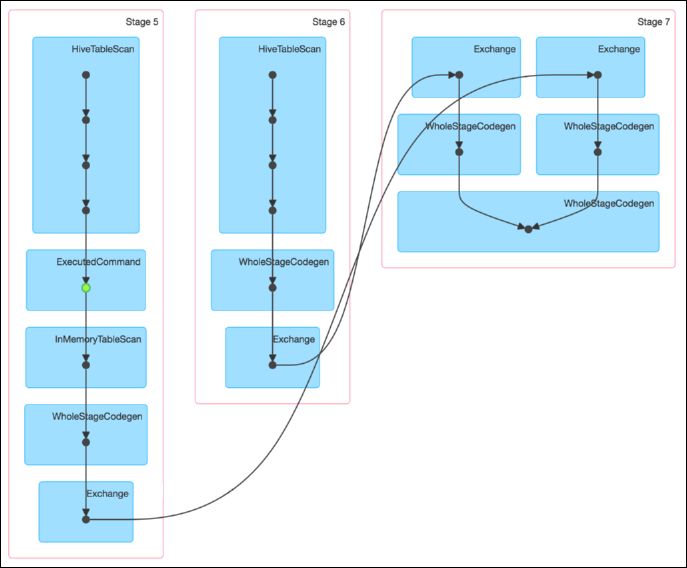
该 SQL 对应的 DAG 如下图所示。从该图可见,该执行过程总共分为三个 Stage,前两个用于从 Hive 中读取数据,同时二者进行 Shuffle,通过最后一个 Stage 进行 Join 并将结果写入表 test_join 中。
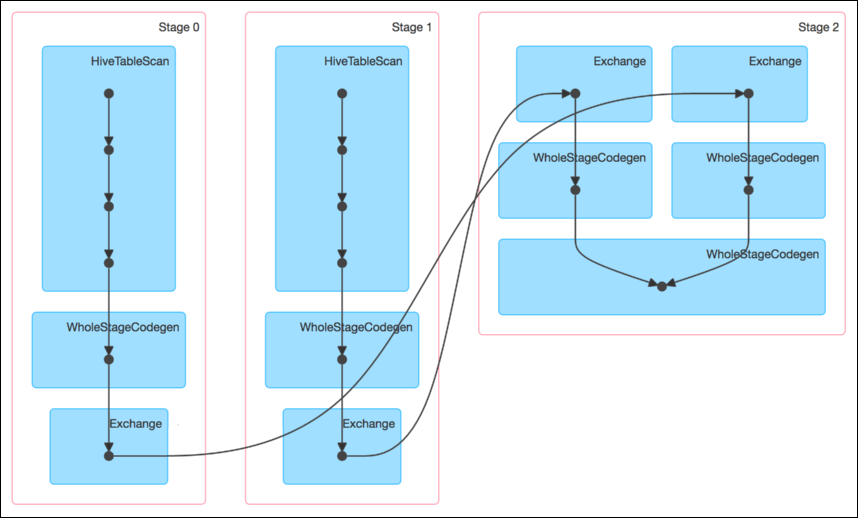
从下图可见,最近 Join Stage 各 Task 处理的数据倾斜严重,处理数据量最大的 Task 耗时 7.1 分钟,远高于其它无数据倾斜的 Task 约 2s 秒的耗时。
Step3:接下来,尝试通过 **Broadcast 实现 Map 侧 Join,实现 Map 侧 Join 的方法,并直接通过 CACHE TABLE test_new** 将小表 test_new 进行 cache。现通过如下 SQL 进行 Join。
**
CACHE TABLE test_new;INSERT OVERWRITE TABLE test_joinSELECT test_new.id, test_new.nameFROM testJOIN test_newON test.id = test_new.id;
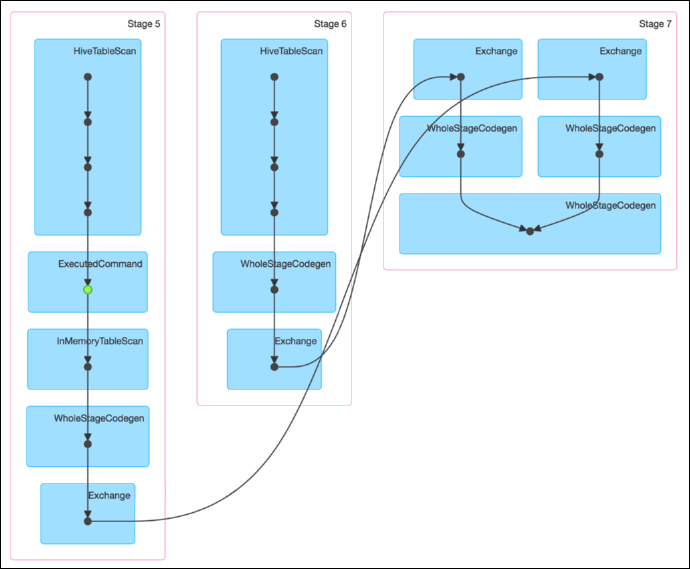
通过如下 DAG 图可见,该操作仍分为三个 Stage,且仍然有 Shuffle 存在,唯一不同的是,小表的读取不再直接扫描 Hive 表,而是扫描内存中缓存的表。
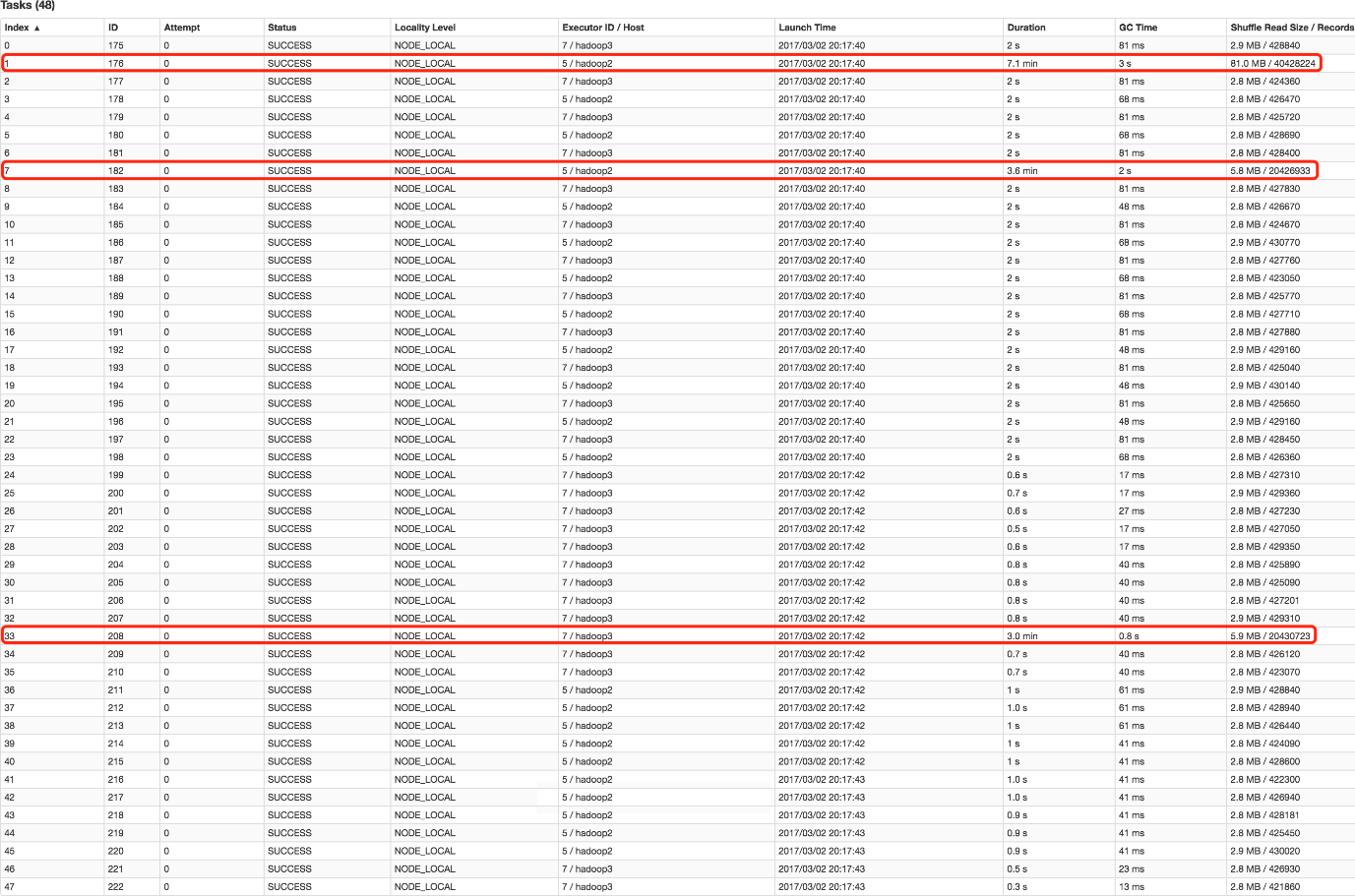
并且数据倾斜仍然存在。如下图所示,最慢的 Task 耗时为 7.1 分钟,远高于其它 Task 的约 2 秒。
Step4:正确的使用 Broadcast 实现 Map 侧 Join 的方式是,通过 **SET spark.sql.autoBroadcastJoinThreshold=104857600 **将 Broadcast 的阈值设置得足够大。
再次通过如下 SQL 进行 Join。
**
SET spark.sql.autoBroadcastJoinThreshold=104857600;INSERT OVERWRITE TABLE test_joinSELECT test_new.id, test_new.nameFROM testJOIN test_newON test.id = test_new.id;
通过如下 DAG 图可见,该方案只包含一个 Stage。
并且从下图可见,各 Task 耗时相当,无明显数据倾斜现象。并且总耗时为 1.5 分钟,远低于 Reduce 侧 Join 的 7.3 分钟。
总结:
方案适用场景:参与 Join 的一边数据集足够小,可被加载进 Driver 并通过 Broadcast 方法广播到各个 Executor 中。
方案优点:避免了 Shuffle,彻底消除了数据倾斜产生的条件,可极大提升性能。
方案缺点:要求参与 Join 的一侧数据集足够小,并且主要适用于 Join 的场景,不适合聚合的场景,适用条件有限。
7.2.3.5 两阶段聚合(局部聚合 + 全局聚合)
方案适用场景:对 RDD 执行 reduceByKey 等聚合类 shuffle 算子或者在 Spark SQL 中使用 group by 语句进行分组聚合时,比较适用这种方案。
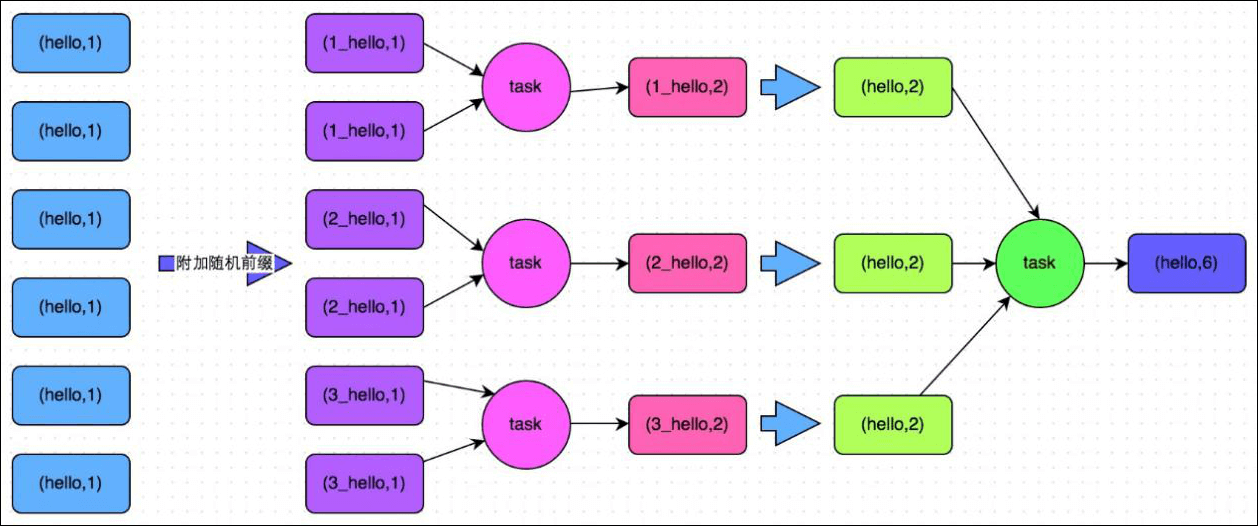
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个 key 都打上一个随机数,比如 10 以内的随机数,此时原先一样的 key 就变成不一样的了,比如 (hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成 (1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行 reduceByKey 等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了 (1_hello, 2) (2_hello, 2)。然后将各个 key 的前缀给去掉,就会变成 (hello,2) (hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如 (hello, 4)。
方案实现原理:将原本相同的 key 通过附加随机前缀的方式,变成多个不同的 key,就可以让原本被一个 task 处理的数据分散到多个 task 上去做局部聚合,进而解决单个 task 处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
方案优点:对于聚合类的 shuffle 操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将 Spark 作业的性能提升数倍以上。
方案缺点:仅仅适用于聚合类的 shuffle 操作,适用范围相对较窄。如果是 join 类的 shuffle 操作,还得用其他的解决方案。
对应代码:
// 第一步,给 RDD 中的每个 key 都打上一个随机前缀。JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(new PairFunction<Tuple2<Long,Long>, String, Long>() {private static final long serialVersionUID = 1L;@Overridepublic Tuple2<String, Long> call(Tuple2<Long, Long> tuple)throws Exception {Random random = new Random();int prefix = random.nextInt(10);return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);}});// 第二步,对打上随机前缀的 key 进行局部聚合。JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(new Function2<Long, Long, Long>() {private static final long serialVersionUID = 1L;@Overridepublic Long call(Long v1, Long v2) throws Exception {return v1 + v2;}});// 第三步,去除 RDD 中每个 key 的随机前缀。JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(new PairFunction<Tuple2<String,Long>, Long, Long>() {private static final long serialVersionUID = 1L;@Overridepublic Tuple2<Long, Long> call(Tuple2<String, Long> tuple)throws Exception {long originalKey = Long.valueOf(tuple._1.split("_")[1]);return new Tuple2<Long, Long>(originalKey, tuple._2);}});// 第四步,对去除了随机前缀的 RDD 进行全局聚合。JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(new Function2<Long, Long, Long>() {private static final long serialVersionUID = 1L;@Overridepublic Long call(Long v1, Long v2) throws Exception {return v1 + v2;}});
案例
**
scala> val sourceRdd = sc.textFile("hdfs://hadoop102:9000/source_index/p*", 13)scala> val kvRdd = sourceRdd.map(x => { val parm = x.split("\t"); (parm(0).trim().toInt, parm(4).trim().toInt) })scala> val kvRdd2 = kvRdd.map(x=> { if (x._1 > 20000) (20001, x._2) else x })scala> kvRdd2.groupByKey().count
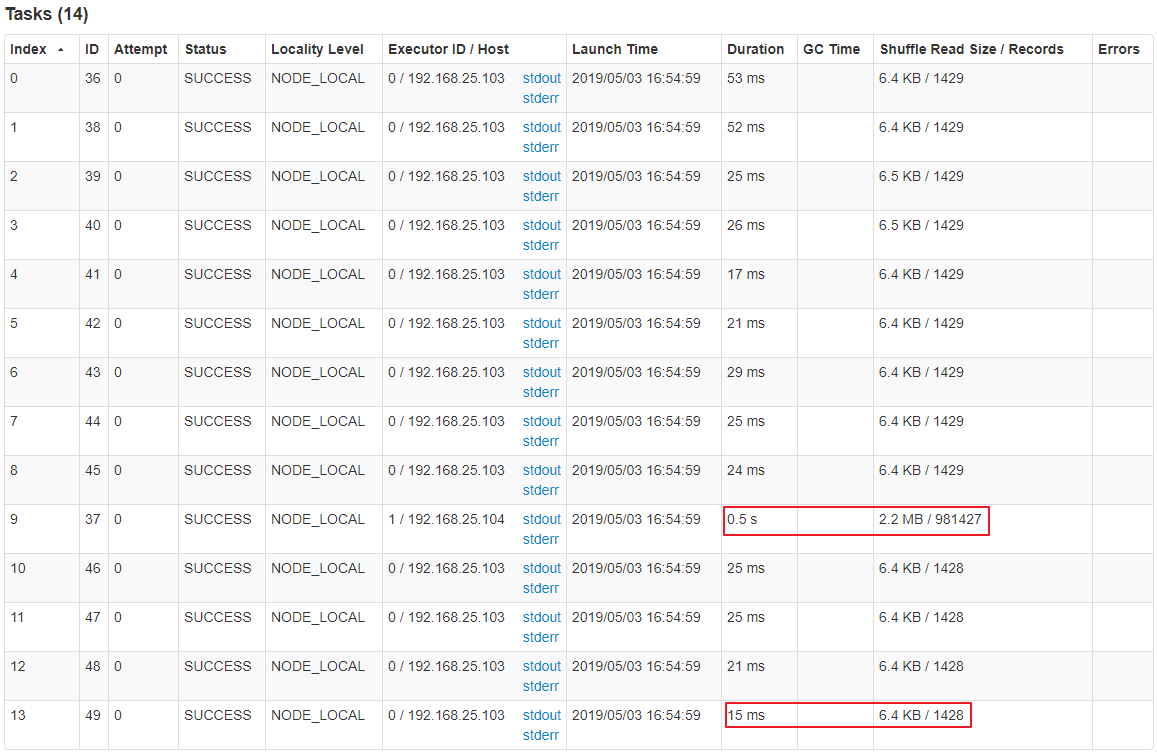
直接 groupByKey 数据倾斜,查看 DAG 图 如下:
查看各个任务的运行时间:
通过广播变量修正后:
scala> val kvRdd3 = kvRdd2.map(x => {if (x._1 == 20001) (x._1 + scala.util.Random.nextInt(100), x._2) else x })scala> kvRdd3.groupByKey().count
查看 DAG 图 如下:
查看各个任务的运行时间:
发现时间都比较均匀,没有出现数据倾斜。
7.2.3.6 为倾斜的 key 增加随机前 / 后缀
方案原理:为数据量特别大的 Key 增加随机前 / 后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一侧的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜 Key 如何加前缀,都能与之正常 Join。
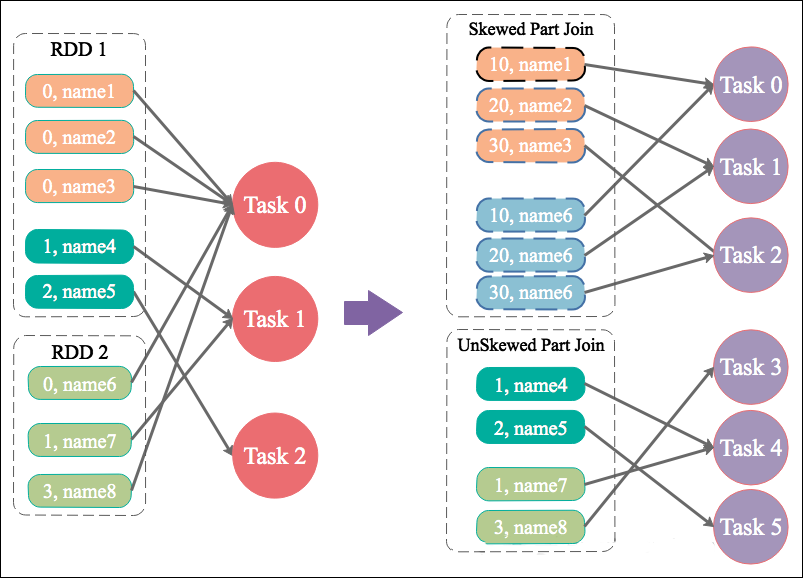
案例
通过如下 SQL,将 id 为 9 亿到 9.08 亿共 800 万条数据的 id 转为 9500048 或者 9500096,其它数据的 id 除以 100 取整。从而该数据集中,id 为 9500048 和 9500096 的数据各 400 万,其它 id 对应的数据记录数均为 100 条。这些数据存于名为 test 的表中。对于另外一张小表 test_new,取出 50 万条数据,并将 id(递增且唯一)除以 100 取整,使得所有 id 都对应 100 条数据。
NSERT OVERWRITE TABLE testSELECT CAST(CASE WHEN id < 908000000 THEN (9500000 + (CAST (RAND() * 2 AS INT) + 1) * 48 )ELSE CAST(id/100 AS INT) END AS STRING),nameFROM student_externalWHERE id BETWEEN 900000000 AND 1050000000;INSERT OVERWRITE TABLE test_newSELECT CAST(CAST(id/100 AS INT) AS STRING),nameFROM student_delta_externalWHERE id BETWEEN 950000000 AND 950500000;
通过如下代码,读取 test 表对应的文件夹内的数据并转换为 JavaPairRDD 存于 leftRDD 中,同样读取 test 表对应的数据存于 rightRDD 中。通过 RDD 的 join 算子对 leftRDD 与 rightRDD 进行 Join,并指定并行度为 48。
public class SparkDataSkew{public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setAppName("DemoSparkDataFrameWithSkewedBigTableDirect");sparkConf.set("spark.default.parallelism", parallelism + "");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test/").mapToPair((String row) -> {String[] str = row.split(",");return new Tuple2<String, String>(str[0], str[1]);});JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test_new/").mapToPair((String row) -> {String[] str = row.split(",");return new Tuple2<String, String>(str[0], str[1]);});leftRDD.join(rightRDD, parallelism).mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1(), tuple._2()._2())).foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {AtomicInteger atomicInteger = new AtomicInteger();iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());});javaSparkContext.stop();javaSparkContext.close();}}
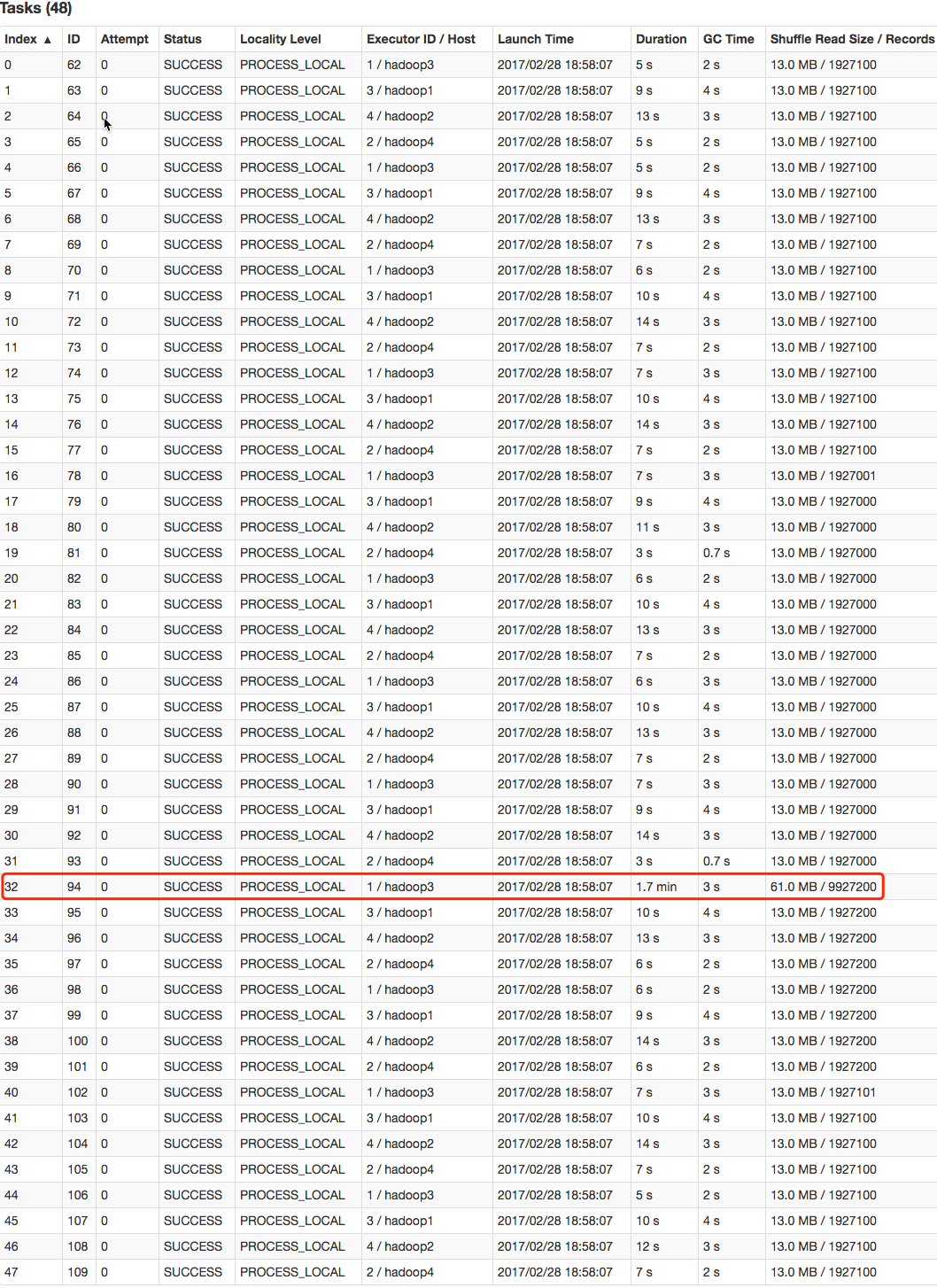
从下图可看出,整个 Join 耗时 1 分 54 秒,其中 Join Stage 耗时 1.7 分钟。

通过分析 Join Stage 的所有 Task 可知,在其它 Task 所处理记录数为 192.71 万的同时 Task 32 的处理的记录数为 992.72 万,故它耗时为 1.7 分钟,远高于其它 Task 的约 10 秒。这与上文准备数据集时,将 id 为 9500048 为 9500096 对应的数据量设置非常大,其它 id 对应的数据集非常均匀相符合。
现通过如下操作,实现倾斜 Key 的分散处理:
- 将 leftRDD 中倾斜的 key(即 9500048 与 9500096)对应的数据单独过滤出来,且加上 1 到 24 的随机前缀,并将前缀与原数据用逗号分隔(以方便之后去掉前缀)形成单独的 leftSkewRDD。
- 将 rightRDD 中倾斜 key 对应的数据抽取出来,并通过 flatMap 操作将该数据集中每条数据均转换为 24 条数据(每条分别加上 1 到 24 的随机前缀),形成单独的 rightSkewRDD。
- 将 leftSkewRDD 与 rightSkewRDD 进行 Join,并将并行度设置为 48,且在 Join 过程中将随机前缀去掉,得到倾斜数据集的 Join 结果 skewedJoinRDD。
- 将 leftRDD 中不包含倾斜 Key 的数据抽取出来作为单独的 leftUnSkewRDD。
- 对 leftUnSkewRDD 与原始的 rightRDD 进行 Join,并行度也设置为 48,得到 Join 结果 unskewedJoinRDD。
- 通过 union 算子将 skewedJoinRDD 与 unskewedJoinRDD 进行合并,从而得到完整的 Join 结果集。
具体实现代码如下:
public class SparkDataSkew{public static void main(String[] args) {int parallelism = 48;SparkConf sparkConf = new SparkConf();sparkConf.setAppName("SolveDataSkewWithRandomPrefix");sparkConf.set("spark.default.parallelism", parallelism + "");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test/").mapToPair((String row) -> {String[] str = row.split(",");return new Tuple2<String, String>(str[0], str[1]);});JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test_new/").mapToPair((String row) -> {String[] str = row.split(",");return new Tuple2<String, String>(str[0], str[1]);});String[] skewedKeyArray = new String[]{"9500048", "9500096"};Set<String> skewedKeySet = new HashSet<String>();List<String> addList = new ArrayList<String>();for(int i = 1; i <=24; i++) {addList.add(i + "");}for(String key : skewedKeyArray) {skewedKeySet.add(key);}Broadcast<Set<String>> skewedKeys = javaSparkContext.broadcast(skewedKeySet);Broadcast<List<String>> addListKeys = javaSparkContext.broadcast(addList);JavaPairRDD<String, String> leftSkewRDD = leftRDD.filter((Tuple2<String, String> tuple) -> skewedKeys.value().contains(tuple._1())).mapToPair((Tuple2<String, String> tuple) -> new Tuple2<String, String>((new Random().nextInt(24) + 1) + "," + tuple._1(), tuple._2()));JavaPairRDD<String, String> rightSkewRDD = rightRDD.filter((Tuple2<String, String> tuple) -> skewedKeys.value().contains(tuple._1())).flatMapToPair((Tuple2<String, String> tuple) -> addListKeys.value().stream().map((String i) -> new Tuple2<String, String>( i + "," + tuple._1(), tuple._2())).collect(Collectors.toList()).iterator());JavaPairRDD<String, String> skewedJoinRDD = leftSkewRDD.join(rightSkewRDD, parallelism).mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1().split(",")[1], tuple._2()._2()));JavaPairRDD<String, String> leftUnSkewRDD = leftRDD.filter((Tuple2<String, String> tuple) -> !skewedKeys.value().contains(tuple._1()));JavaPairRDD<String, String> unskewedJoinRDD = leftUnSkewRDD.join(rightRDD, parallelism).mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1(), tuple._2()._2()));skewedJoinRDD.union(unskewedJoinRDD).foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {AtomicInteger atomicInteger = new AtomicInteger();iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());});javaSparkContext.stop();javaSparkContext.close();}}
从下图可看出,整个 Join 耗时 58 秒,其中 Join Stage 耗时 33 秒。

通过分析 Join Stage 的所有 Task 可知:
- 由于 Join 分倾斜数据集 Join 和非倾斜数据集 Join,而各 Join 的并行度均为 48,故总的并行度为 96。
- 由于提交任务时,设置的 Executor 个数为 4,每个 Executor 的 core 数为 12,故可用 Core 数为 48,所以前 48 个 Task 同时启动(其 Launch 时间相同),后 48 个 Task 的启动时间各不相同(等待前面的 Task 结束才开始)。
- 由于倾斜 Key 被加上随机前缀,原本相同的 Key 变为不同的 Key,被分散到不同的 Task 处理,故在所有 Task 中,未发现所处理数据集明显高于其它 Task 的情况。
实际上,由于倾斜 Key 与非倾斜 Key 的操作完全独立,可并行进行。而本实验受限于可用总核数为 48,可同时运行的总 Task 数为 48,故而该方案只是将总耗时减少一半(效率提升一倍)。如果资源充足,可并发执行 Task 数增多,该方案的优点将更为明显。在实际项目中,该方案往往可提升数倍至 10 倍的效率。
总结:
- 方案适用场景:两张表都比较大,无法使用 Map 侧 Join。其中一个 RDD 有少数几个 Key 的数据量过大,另外一个 RDD 的 Key 分布较为均匀。
- 方案解决方案:将有数据倾斜的 RDD 中倾斜 Key 对应的数据集单独抽取出来加上随机前缀,另外一个 RDD 每条数据分别与随机前缀结合形成新的 RDD(相当于将其数据增到到原来的 N 倍,N 即为随机前缀的总个数),然后将二者 Join 并去掉前缀。然后将不包含倾斜 Key 的剩余数据进行 Join。最后将两次 Join 的结果集通过 union 合并,即可得到全部 Join 结果。
- 方案优点:相对于 Map 侧 Join,更能适应大数据集的 Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
- 方案缺点:如果倾斜 Key 非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜 Key 与非倾斜 Key 分开处理,需要扫描数据集两遍,增加了开销。
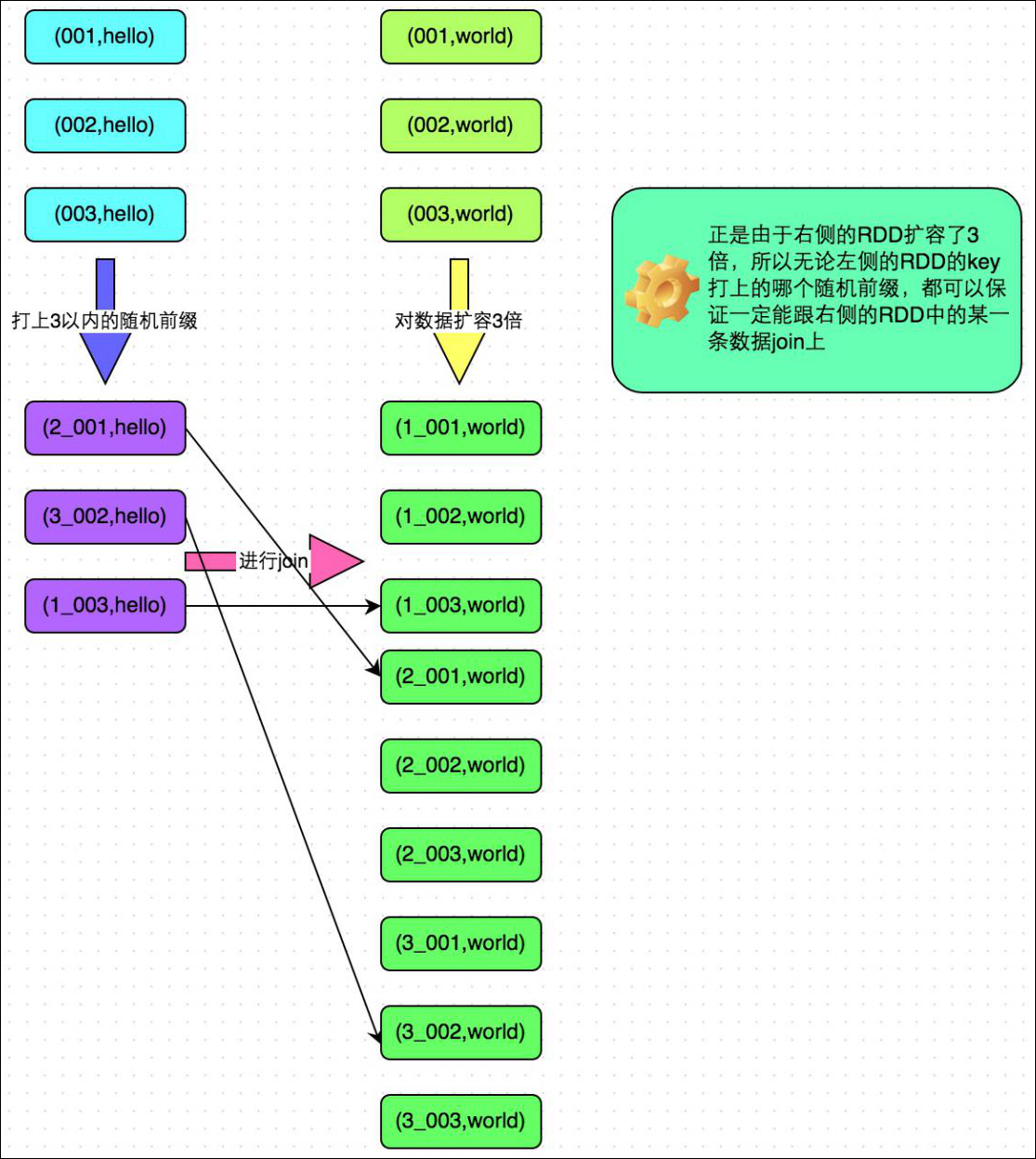
7.2.3.7 使用随机前缀和扩容 RDD 进行 join(大表随机添加 N 种随机前缀,小表扩大 N 倍)
方案适用场景:在进行 join 操作时,如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍)。
方案实现思路:该方案的实现思路基本和 “解决方案 6” 类似,首先查看 RDD/Hive 表中的数据分布情况,找到那个造成数据倾斜的 RDD/Hive 表,比如有多个 key 都对应了超过 1 万条数据。然后将该 RDD 的每条数据都打上一个 n 以内的随机前缀;同时对另外一个正常的 RDD 进行扩容,将每条数据都扩容成 n 条数据,扩容出来的每条数据都依次打上一个 0~n 的前缀;最后将两个处理后的 RDD 进行 join 即可。
方案实现原理:将原先一样的 key 通过附加随机前缀变成不一样的 key,然后就可以将这些处理后的 “不同 key” 分散到多个 task 中去处理,而不是让一个 task 处理大量的相同 key。该方案与 “解决方案 6” 的不同之处就在于,上一种方案是尽量只对少数倾斜 key 对应的数据进行特殊处理,由于处理过程需要扩容 RDD,因此上一种方案扩容 RDD 后对内存的占用并不大;而这一种方案是针对有大量倾斜 key 的情况,没法将部分 key 拆分出来进行单独处理,因此**只能对整个 RDD 进行数据扩容,对内存资源要求很高**。
方案优点:对 join 类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
方案缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个 RDD 进行扩容,对内存资源要求很高。
方案实践经验:曾经开发一个数据需求的时候,发现一个 join 导致了数据倾斜。优化之前,作业的执行时间大约是 60 分钟左右;使用该方案优化之后,执行时间缩短到 10 分钟左右,性能提升了 6 倍。
代码示例:
// 首先将其中一个 key 分布相对较为均匀的 RDD 膨胀 100 倍。JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {private static final long serialVersionUID = 1L;@Overridepublic Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)throws Exception {List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();for(int i = 0; i < 100; i++) {list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));}return list;}});// 其次,将另一个有数据倾斜 key 的 RDD,每条数据都打上 100 以内的随机前缀。JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(new PairFunction<Tuple2<Long,String>, String, String>() {private static final long serialVersionUID = 1L;@Overridepublic Tuple2<String, String> call(Tuple2<Long, String> tuple)throws Exception {Random random = new Random();int prefix = random.nextInt(100);return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);}});// 将两个处理后的 RDD 进行 join 即可。JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
案例
**
这里给出示例代码,读者可参考上文中分拆出少数倾斜 Key 添加随机前缀的方法,自行测试。
public class SparkDataSkew {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setAppName("ResolveDataSkewWithNAndRandom");sparkConf.set("spark.default.parallelism", parallelism + "");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test/").mapToPair((String row) -> {String[] str = row.split(",");return new Tuple2<String, String>(str[0], str[1]);});JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop102:9000/apps/hive/warehouse/default/test_new/").mapToPair((String row) -> {String[] str = row.split(",");return new Tuple2<String, String>(str[0], str[1]);});List<String> addList = new ArrayList<String>();for(int i = 1; i <=48; i++) {addList.add(i + "");}Broadcast<List<String>> addListKeys = javaSparkContext.broadcast(addList);JavaPairRDD<String, String> leftRandomRDD = leftRDD.mapToPair((Tuple2<String, String> tuple) -> new Tuple2<String, String>(new Random().nextInt(48) + "," + tuple._1(), tuple._2()));JavaPairRDD<String, String> rightNewRDD = rightRDD.flatMapToPair((Tuple2<String, String> tuple) -> addListKeys.value().stream().map((String i) -> new Tuple2<String, String>( i + "," + tuple._1(), tuple._2())).collect(Collectors.toList()).iterator());JavaPairRDD<String, String> joinRDD = leftRandomRDD.join(rightNewRDD, parallelism).mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1().split(",")[1], tuple._2()._2()));joinRDD.foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {AtomicInteger atomicInteger = new AtomicInteger();iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());});javaSparkContext.stop();javaSparkContext.close();}}
总结:
- 方案适用场景:一个数据集存在的倾斜 Key 比较多,另外一个数据集数据分布比较均匀。
- 方案优点:对大部分场景都适用,效果不错。
- 方案缺点:需要将一个数据集整体扩大 N 倍,会增加资源消耗。
- 方案总结:对于数据倾斜,并无一个统一的一劳永逸的方法。更多的时候,是结合数据特点(数据集大小,倾斜 Key 的多少等)综合使用上文所述的多种方法。
7.2.3.8 采样倾斜 key 并分拆 join 操作
方案适用场景:两个 RDD/Hive 表进行 join 的时候,如果数据量都比较大,无法采用 “解决方案 5”,那么此时可以看一下两个 RDD/Hive 表中的 key 分布情况。如果出现数据倾斜,是因为其中某一个 RDD/Hive 表中的少数几个 key 的数据量过大,而另一个 RDD/Hive 表中的所有 key 都分布比较均匀,那么采用这个解决方案是比较合适的。
方案实现思路:对包含少数几个数据量过大的 key 的那个 RDD,通过 sample 算子采样出一份样本来,然后统计一下每个 key 的数量,计算出来数据量最大的是哪几个 key。然后将这几个 key 对应的数据从原来的 RDD 中拆分出来,形成一个单独的 RDD,并给每个 key 都打上 n 以内的随机数作为前缀,而不会导致倾斜的大部分 key 形成另外一个 RDD;接着将需要 join 的另一个 RDD,也过滤出来那几个倾斜 key 对应的数据并形成一个单独的 RDD,将每条数据膨胀成 n 条数据,这 n 条数据都按顺序附加一个 0~n 的前缀,不会导致倾斜的大部分 key 也形成另外一个 RDD;再将附加了随机前缀的独立 RDD 与另一个膨胀 n 倍的独立 RDD 进行 join,此时就可以将原先相同的 key 打散成 n 份,分散到多个 task 中去进行 join 了;而另外两个普通的 RDD 就照常 join 即可;最后将两次 join 的结果使用 union 算子合并起来即可,就是最终的 join 结果。
方案实现原理:对于 join 导致的数据倾斜,如果只是某几个 key 导致了倾斜,可以将少数几个 key 分拆成独立 RDD,并附加随机前缀打散成 n 份去进行 join,此时这几个 key 对应的数据就不会集中在少数几个 task 上,而是分散到多个 task 进行 join 了。具体原理见下图。
方案优点:对于 join 导致的数据倾斜,如果只是某几个 key 导致了倾斜,采用该方式可以用最有效的方式打散 key 进行 join。而且只需要针对少数倾斜 key 对应的数据进行扩容 n 倍,不需要对全量数据进行扩容。避免了占用过多内存。
方案缺点:如果导致倾斜的 key 特别多的话,比如成千上万个 key 都导致数据倾斜,那么这种方式也不适合。
7.2.3.9 过滤少数导致倾斜的 key
方案适用场景:如果发现导致倾斜的 key 就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如 99% 的 key 就对应 10 条数据,但是只有一个 key 对应了 100 万数据,从而导致了数据倾斜。
方案实现思路:如果我们判断那少数几个数据量特别多的 key,对作业的执行和计算结果不是特别重要的话,那么干脆就直接过滤掉那少数几个 key。比如,在 Spark SQL 中可以使用 where 子句过滤掉这些 key 或者在 Spark Core 中对 RDD 执行 filter 算子过滤掉这些 key。如果需要每次作业执行时,动态判定哪些 key 的数据量最多然后再进行过滤,那么可以使用 sample 算子对 RDD 进行采样,然后计算出每个 key 的数量,取数据量最多的 key 过滤掉即可。
方案实现原理:将导致数据倾斜的 key 给过滤掉之后,这些 key 就不会参与计算了,自然不可能产生数据倾斜。
方案优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
方案缺点:适用场景不多,大多数情况下,导致倾斜的 key 还是很多的,并不是只有少数几个。
方案实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天 Spark 作业在运行的时候突然 OOM 了,追查之后发现,是 Hive 表中的某一个 key 在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个 key 之后,直接在程序中将那些 key 给过滤掉。

若有收获,就点个赞吧
0 人点赞
