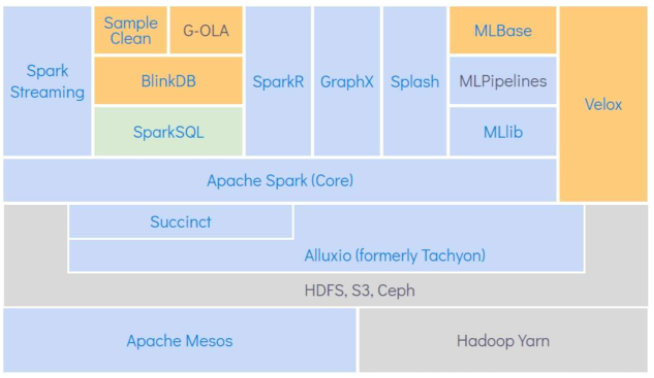
1.1 Spark与BDAS
AMP实验室将其称为伯克利数据分析栈(Berkeley Data Analytics Stack, BDAS),
1.2 Databricks
Databricks创始人团队中很多都是Spark项目的Committer,在一定程度上,该公司可以影响Spark的发展方向。

1.3 如何通过GitHub向Spark贡献代码
通过GitHub的Pull Request功能,向Spark贡献代码。步骤如下。
(1)Fork Spark项目到自己账号下。
(2)创建一个自己用于修改的分支。
(3)将当前的代码仓库切换到mybranch分支。
(4)修改代码。修改完成后,commit到mybranch分支。
(5)处理冲突,提交Pull Request。
如果Spark Committer认可了你的Pull Request,那么具有写权限的Committer就会将你的Pull Request合并到Spark的master分支上。
1.4 如何选择Spark编程语言
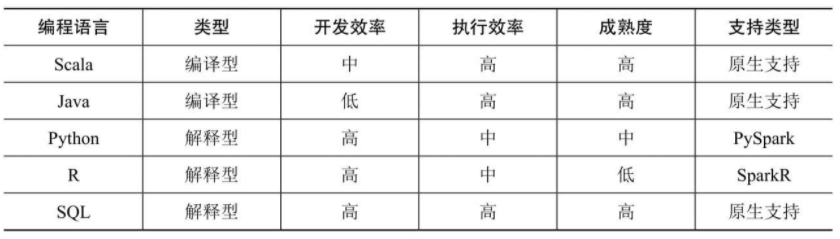
Spark开发语言对比
Java开发效率无疑是最低的,此外Python与R语言本身也支持函数式编程,但由于其执行原理是计算任务在每个节点安装的Python或R的环境中执行,结果通过管道输出给Spark Worker,因此效率要比Scala与Java低。用Spark SQL解决问题是最优选择。
1.5 函数式编程思想
函数式编程属于声明式编程,与其相对的是命令式编程,命令式编程是按照“程序是一系列改变状态的命令”来建模的一种建模风格,而函数式编程思想是“程序是表达式和变换,以数学方程的形式建立模型,并且尽可能避免可变状态”。
命令式编程将计算机程序看成动作的序列,程序运行的过程就是求解的过程,而函数式编程则是从结果入手,用户通过函数定义了从最初输入到最终输出的映射关系,从这个角度上来说,用户编写代码描述了用户的最终结果(我想要什么),而并不关心(或者说不需要关心)求解过程,因此函数式编程绝对不会去操作某个具体的值。
这类似于用户编写的代码:
select class_no, count(*) from student_info group by class_no;
SQL是很典型的声明式编程,用户只需要告诉SQL引擎统计每个班的人数,至于底层是怎么执行的,用户不需要关心。
相对于高阶函数,函数式语言一般会提供一些低阶函数用于构建整个流程,这些低阶函数都是无副作用的,非常适合并行计算。高阶函数可以让用户专注于业务逻辑,而不需要去费心构建整个数据流。
函数式还有很多特性:
- 没有变量
- 低阶函数与核心数据结构
- 惰性求值
- 函数记忆
- 副作用很少
函数式编程思想在Spark上的体现:
- 函数式编程接口
- 惰性求值
- 容错

若有收获,就点个赞吧
0 人点赞
