6.1 无监督学习概述
一般来说,无监督学习的使用频率低于有监督学习,因为它的最终结果通常难以评估好坏。这些挑战随着数据规模变大可能会加剧,例如高维空间中的聚类可能因为高维的属性而生成奇怪的聚类结果,这被称为维度灾难(curse of dimensionality)。维度灾难体现了这样一个事实:随着特征空间随着维度扩展,它变得越来越稀疏,这意味着随着维数的增加,填充此空间以获得具有统计意义的结果所需的数据会迅速增加。此外,高维度会带来更多噪音,这可能会使模型在噪音数据中训练从而导致奇怪的结果。
下面是一些可能的应用场景,这些模式可能会揭示数据中并不明显的主题、异常或分组:
- 查找数据中的异常:如果数据集中的大多数值都集中在一个较大的组中,而其外只有几个小组,则这些小组可能需要进一步研究。
- 主题建模:通过检查大量的文本,可以找到在这些不同文档中存在的共同主题。
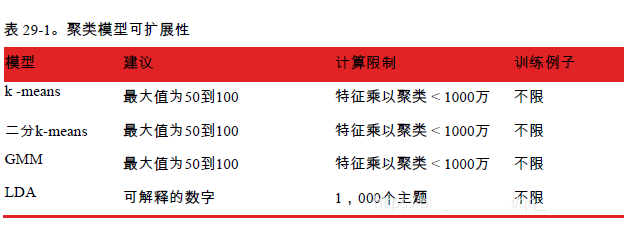
就像前面其他模型一样,模型扩展性限制非常重要:
先加载一些数值数据:
from pyspark.ml.feature import VectorAssemblerva = VectorAssembler()\.setInputCols(["Quantity", "UnitPrice"])\.setOutputCol("features")sales = va.transform(spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/data/retail-data/by-day/*.csv").limit(50).coalesce(1).where("Description IS NOT NULL"))sales.cache()
6.2 means
k-means 是最受欢迎的聚类算法之一。在此算法中,用户在数据集中随机选择数量为 k 的数据点作为处理聚类的聚类中心,未分配的点基于它们与这些聚类中心的相似度(以欧氏距离计算),然后被 “分配” 到离它们最近的聚类中。分配之后,再根据被分配到一个聚类的数据点再计算聚类的新中心(称为质心),并重复该过程,直到到达有限的迭代次数或直到收敛(即质心位置停止改变)。
这种方法并不一定合理,例如如果实际的一个聚类可能被错误地拆分为两个,仅仅是因为开始的时候选择了两个初始点,因此以不同方式选择初始点来多次执行 k-means 会取得比较好的效果。选择正确的聚类个数 k 是保证 kmeans 算法有效的一个关键,这也是一个难点。Spark k-means 的模型超参数就是 k,训练参数有以下几个:
- initMode:初始化模式是确定质心初始位置的算法,支持的选项为 random(随机初始化)和 k-means||(默认值)。后者是 k-means|| 的并行化变体,它的思想不是简单地选择随机初始化位置,而是选择具有良好分布的聚类中心,以产生更好的聚类。
- initSteps:k-means|| 模式初始化所需要的步数。必须大于 0,默认值是 2
- maxIter:迭代次数,改变这个值可能不会对最终结果改变很大,所以这不应该是你首先考虑调整的参数。默认 20。
- tol:该阈值指定质心改变小到该程度后,就认为模型已经优化的足够了,可以在迭代 maxIter 次之前停止运行。默认值为 0.0001。
此算法对这些参数通常是具有鲁棒性的,主要是一个均衡问题,运行更多的初始化步骤和迭代次数可能会生成更好的聚类,代价则是更长的训练时间:
from pyspark.ml.clustering import KMeanskm = KMeans().setK(5)print km.explainParams()kmModel = km.fit(sales)
k-means 包括可用于评估模型的摘要类,该类为 k-means 运行成功提供了一些常用的衡量标准,k-means 摘要包括有关创建聚类的信息以及聚类的相对大小(示例数)。还可以使用 computeCost 计算类内平方误差和,这可以帮助衡量聚类内数据点与每个聚类中心点相距有多近。k-means 的隐式目标是,基于给定的聚类数量 k 来最小化聚类内平方误差的和:
#in Pythonsummary = kmModel.summaryprint summary.clusterSizes # 中心点的数量kmModel.computeCost(sales)centers = kmModel.clusterCenters()print("Cluster Centers: ")for center in centers:print(center
6.3 二分 k-means
二分 k-means 是 k-means 的变体,关键区别在于它不是通过自下而上(bottom-up)地聚类,而是自上而下(top-down)的聚类方法。它首先创建一个组,然后将该组再拆分成较小的组,以此类推,直到满足用户指定的 k 个组**。这通常是比 k-means 更快捷的方法,将得到与 k-means 不同的结果。模型超参数依然和 k-means 一样为 k,训练参数为以下两个:
- minDivisibleClusterSize:指定一个可分聚类中的最少的数据点数(如果大于等于 1.0)或数据点的最小比例(如果小于 1.0),当聚类中数据点数小于该值时,聚类就不可再分割了。默认值为 1.0,这意味着每个聚类中必须至少有一个点。
- maxIter:迭代次数,改变迭代次数可能不会对聚类的最终结果造成太大影响,所以这不应该是调参的首要选项。默认是 20。
该模型中的大多数参数都应进行调参以找到最佳结果,没有适用于所有数据集的规则。代码示例如下所示:
from pyspark.ml.clustering import BisectingKMeansbkm = BisectingKMeans().setK(5).setMaxIter(5)print bkm.explainParams()bkmModel = bkm.fit(sales)
二分 k-means 包括一个摘要类,可以使用它来评估模型。它和 k-means 摘要类大部分相同,包括有关创建的聚类信息以及聚类的相对大小(数据点数量):
summary = bkmModel.summaryprint summary.clusterSizes # 中心点的数量kmModel.computeCost(sales)centers = kmModel.clusterCenters()print("Cluster Centers: ")for center in centers:print(center)
6.4 高斯混合模型
高斯混合模型(Gaussian mixture models,GMM)是另一种流行的聚类算法,它的假设不同于二分 k-means 和 k-means 算法,这两种算法尝试通过降低数据点和聚类中心之间的距离平方和来对数据进行分组,而高斯混合模型假设每个聚类中的数据点符合高斯分布,这意味着数据点在聚类边缘(根据高斯分布)的可能性较小,而数据点在中心附近的概率更高**。每个高斯聚类的均值和标准差各不相同,可以是任意大小(因此可能是各不相同的椭圆形)。在训练过程中仍然需要用户指定聚类的 k 值。
一种简单理解高斯混合模型的方法是,它们就像 k-means 的软聚类版本(软聚类 soft clustering 即每个数据点可以划分到多个聚类中),而 k-means 创建硬聚类(即每个点仅在一个聚类中),高斯混合模型 GMM 依照概率而不是硬性边界进行聚类。高斯混合的模型超参数也为 k,训练参数为以下几个:
- maxIter:迭代次数,改变这个值可能不会对最终聚类结果有太大影响,所以它不应该是首先考虑调整的参数。默认为 100。
- tol:指定一个阈值来代表将模型优化到什么程度就够了,越小的阈值将需要更多的迭代次数作为代价(不会超过 maxIter),也可以得到更高的准确度。默认值为 0.01。
与 k-means 模型一样,这些训练参数一般不会受到聚类数量 k 的影响,代码示例如下所示:
from pyspark.ml.clustering import GaussianMixturegmm = GaussianMixture().setK(5)print gmm.explainParams()model = gmm.fit(sales)
与其他聚类算法一样,高斯混合模型包括一个摘要类来帮助模型评估,这包括创建的聚类信息,如高斯混合的权重、均值和协方差,这可以帮助进一步了解数据的隐藏信息:
# in Pythonsummary = model.summaryprint model.weightsmodel.gaussiansDF.show()summary.cluster.show()summary.clusterSizessummary.probability.show()
6.5 隐含狄利克雷分布(LDA)
隐含狄利克雷分布(LDA)是一种通常用于对文本文档执行主题建模的分层聚类模型。LDA 试图从与这些主题相关联的一系列文档和关键字中提取高层次的主题,然后它将每个文档解释为多个输入主题的组合。可以使用两种实现方案:在线 LDA(online LDA)和 EM 算法,一般来说当有更多的输入样本时,在线 LDA 表现得更好;当有较大的输入词库时,EM 优化器效果更好**。此方法还可以扩展到成百上千个主题。
要把文本数据输入进 LDA 中,首先要将其转化为数值格式,这可以通过 CountVectorizer 来实现。它的模型超参数为:
- k:用于指定从数据中提取的主题数量。默认值是 10,并且必须是整数。
- docConcentration:文档分布的浓度(Concentration)参数向量(通常称为 “alpha”),它是狄利克雷分布的参数,越大的值意味着越平滑(正则化程度更高)。如果未经用户设置,则 docConcentration 自动取值。如果设置为单值向量 [alpha],则 alpha 被重复复制到长度为 k 的向量中,docConcentration 向量的长度必须为 k。
- topicConcentration:主题分布的浓度参数向量,通常命名为 “beta” 或 “eta”,它是一个对称狄利克雷分布的参数。如果用户未设置,则 topicConcentration 将被自动设置。
训练参数有以下几个:
- maxIter:最大迭代次数,改变这个值可能对结果不会有多大影响,所以这不应该是首先考虑调整的参数。默认值 20。
- optimizer:指定是使用 EM 还是在线训练方法来优化 LDA 模型。默认为 online。
- learningDecay:学习率,即指数衰减率。应该介于 (0.5、1.0] 之间以保证渐近收敛。默认值为 0.51,仅适用于在线优化程序。
- learningOffset:一个正数值的学习参数,在前几次迭代中会递减。较大的值使前期迭代次数较少。默认值为 1024.0,仅适用于在线优化程序。
- optimizeDocConcentration:指示 docConcentration(文档主题分布的狄利克雷参数)是否在训练过程中进行优化。默认值为 true,但仅适用于在线优化程序。
- subsamplingRate:在微型批量梯度下降的每次迭代中采样的样本比例,范围是 (0、1]。默认值为 0.5,仅适用于在线优化程序。
- seed:该模型还支持指定一个随机种子,用于实验重现。
- checkpointInterval:和在分类算法中看到的一样,是用于设置检查点的参数。
LDA 支持的预测参数为 topicDistributionCol,即把每个文档的主题混合分布输出作为一列保存起来。代码示例如下所示:
from pyspark.ml.feature import Tokenizer, CountVectorizertkn = Tokenizer().setInputCol("Description").setOutputCol("DescOut")tokenized = tkn.transform(sales.drop("features"))cv = CountVectorizer()\.setInputCol("DescOut")\.setOutputCol("features")\.setVocabSize(500)\.setMinTF(0)\.setMinDF(0)\.setBinary(True)cvFitted = cv.fit(tokenized)prepped = cvFitted.transform(tokenized)from pyspark.ml.clustering import LDAlda = LDA().setK(10).setMaxIter(5)print lda.explainParams()model = lda.fit(prepped)
训练完模型后,将看到一些排名靠前的主题,返回单词的索引。必须使用训练的 CountVectorizerModel 来找到这些单词的真实语义,例如训练后发现的前 3 个相关主题是 hot、home、和 brown:
# in Pythonmodel.describeTopics(3).show()cvFitted.vocabulary
这种方法会产生所用词的详细信息以及特定单词的强调,这些有助于更好地理解潜在的主题。使用类似 API 其实有更多的评估方法,如对数似然(log likelihood)和困惑度(perplexity),这些工具的目标是帮助用户根据数据的分布情况优化主题的数量,应该将这些指标应用到一个保留集(**holdoutset)上,以减少模型的整体困惑度。另一种选择是以提高保留集的对数似然为目标的优化,可以通过将数据集传递到这两个函数来计算相应的指标值:model.logLikelihood 和 model.logPerplexity**。

若有收获,就点个赞吧
0 人点赞
