1. 依赖
<!-- server --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>1.3.1</version></dependency><!-- client --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.3.1</version></dependency>
2. 基础API
核心对象:DDL操作
HBaseAdmin,DML操作HTable
2.1 获取Configuration
public static Configuration configuration;static {configuration = HBaseConfiguration.create();// 设置zk地址configuration.set("hbase.zookeeper.quorum","hadoop101,hadoop102,hadoop103");configuration.set("hbase.zookeeper.property.clientPort","2181");}
2.2 判断表是否存在
/*** 1. 判断表是否存在** @param tableName 表名* @return* @throws IOException*/public static boolean isTableExist(String tableName) throws IOException {//在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象// 方式一:// Connection connection = ConnectionFactory.createConnection(configuration);// HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();// 方式二:HBaseAdmin admin = new HBaseAdmin(configuration);boolean isExist = admin.tableExists(tableName);return isExist;}
2.3 创建表
/*** 2. 创建表** @param tableName 表名* @param columnFamily 多个列族*/public static void createTable(String tableName, String... columnFamily) throws IOException {HBaseAdmin admin = new HBaseAdmin(configuration);// 首先判断表是否存在if (isTableExist(tableName)) {System.out.println("表" + tableName + "已存在");System.exit(0);}else {// 创建表属性对象,表名需要转字节HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));// 创建多个列族for (String cf : columnFamily) {hTableDescriptor.addFamily(new HColumnDescriptor(cf));}// 根据对表的配置,创建表admin.createTable(hTableDescriptor);System.out.println("表" + tableName + "创建成功!");}}
2.4 删除表
/*** 3. 删除表** @param tableName 表名* @throws IOException*/public static void dropTable(String tableName) throws IOException {HBaseAdmin admin = new HBaseAdmin(configuration);if (isTableExist(tableName)) {// 先disable才能删除掉admin.disableTable(tableName);admin.deleteTable(TableName.valueOf(tableName));System.out.println("表" + tableName + "删除成功!");} else {System.out.println("表" + tableName + "不存在!");}}
2.5 插入数据
/*** 4. 插入数据** @param tableName 表名* @param rowKey rowkey* @param columnFamily 列族* @param column 列* @param value 值*/public static void addRowData(String tableName, String rowKey, String columnFamily, String column, String value) throws IOException {// 创建HTable对象HTable hTable = new HTable(configuration, tableName);// 通过rowkey构建Put对象Put put = new Put(Bytes.toBytes(rowKey));// 向Put对象中组装数据put.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));hTable.put(put);hTable.close();System.out.println("插入数据成功");}
2.6 删除多行数据
/*** 5. 删除多行数据** @param tableName 表名* @param rows rowKey数组* @throws IOException*/public static void deleteMultiRow(String tableName, String... rows) throws IOException {HTable hTable = new HTable(configuration, tableName);ArrayList<Delete> deleteList = new ArrayList<>();for (String row : rows) {Delete delete = new Delete(Bytes.toBytes(row));deleteList.add(delete);}hTable.delete(deleteList);hTable.close();System.out.println("多行数据删除成功");}
2.7 查询所有数据
/*** 6. 获取所有数据** @param tableName 表名* @throws IOException*/public static void scanRows(String tableName) throws IOException {HTable hTable = new HTable(configuration, tableName);// 获取用于扫表的scan对象Scan scan = new Scan();// 使用HTable得到resultScanner实现类的对象,实际是个迭代器ResultScanner scanner = hTable.getScanner(scan);for (Result result : scanner) {// 获取所有的单元格Cell[] cells = result.rawCells();for (Cell cell : cells) {// 获取rowkeySystem.out.println("行键rowkey:" + Bytes.toString(CellUtil.cloneRow(cell)));// 获取列族System.out.println("列族:" + Bytes.toString(CellUtil.cloneFamily(cell)));// 获取列System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));}}}
2.8 获取某一行数据
/*** 7. 获取某一行数据** @param tableName 表名* @param rowKey rowKey* @throws IOException*/public static void getRow(String tableName, String rowKey) throws IOException {HTable hTbale = new HTable(configuration, tableName);Get get = new Get(Bytes.toBytes(rowKey));// 显示所有版本get.setMaxVersions();// 显示指定时间戳的版本// get.setTimeStamp()Result result = hTbale.get(get);for (Cell cell : result.rawCells()) {// 获取rowkeySystem.out.println("行键rowkey:" + Bytes.toString(CellUtil.cloneRow(cell)));// 获取列族System.out.println("列族:" + Bytes.toString(CellUtil.cloneFamily(cell)));// 获取列System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));}}
2.9 获取某一单元格数据
/*** 8. 获取某一行指定“列族:列”的数据,即获取某一个单元格的数据** @param tableName 表名* @param rowKey rowKey* @param columnFamily 列族* @param column 列*/public static void getCell(String tableName, String rowKey, String columnFamily, String column) throws IOException {HTable hTable = new HTable(configuration, tableName);Get get = new Get(Bytes.toBytes(rowKey));// 添加“列族:列”信息get.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(column));Result result = hTable.get(get);for (Cell cell : result.rawCells()) {// 获取rowkeySystem.out.println("行键rowkey:" + Bytes.toString(CellUtil.cloneRow(cell)));// 获取列族System.out.println("列族:" + Bytes.toString(CellUtil.cloneFamily(cell)));// 获取列System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));}}
2.10 过滤器
2.10.1 常用过滤器如下
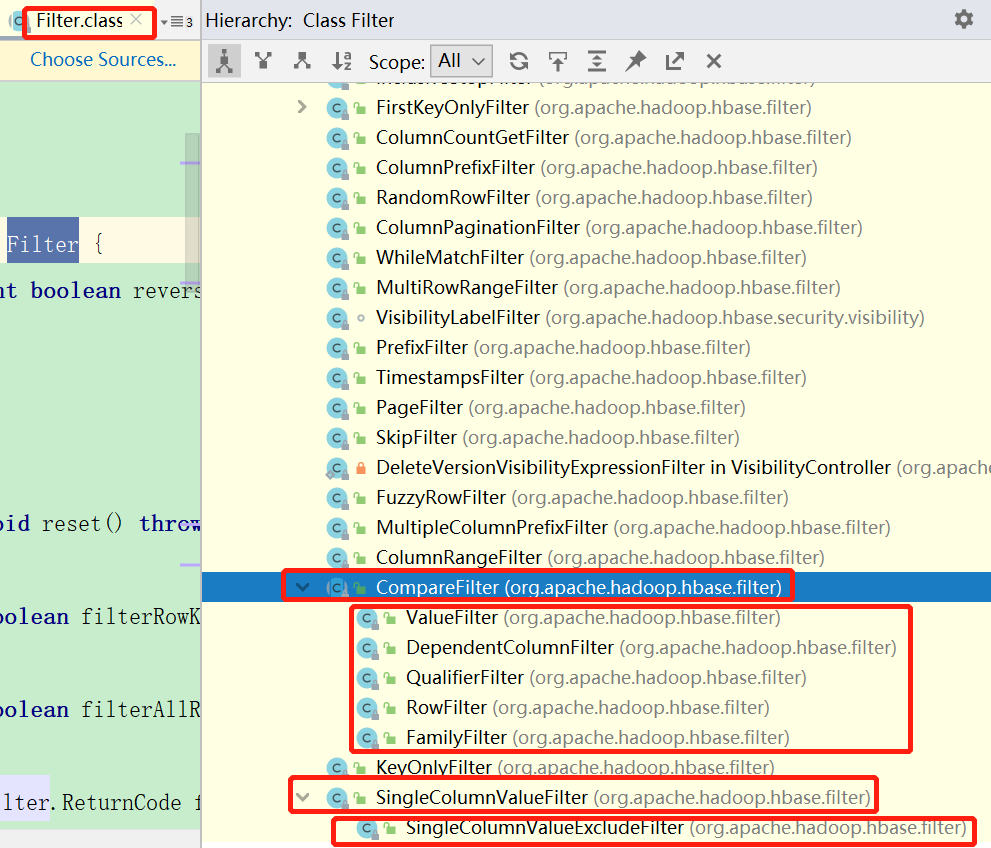
2.10.2 实例代码
Scan scan = new Scan();// 构建过滤器// 表示过滤出 RowKey 中有uid_"-"的子串的数据RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(uid + "_"));scan.setFilter(rowFilter);// 4. 获取数据ResultScanner resultScanner = table.getScanner(scan);
3. 整合MapReduce
3.1 环境准备
3.1.1 查看HBase的官方MapReduce任务的执行需要哪些jar
# maredcp --- MapReduce的jar包classpath路径$ bin/hbase mapredcp
3.1.2 环境变量的导入
3.1.2.1 临时生效(执行环境变量导入)
$ export HBASE_HOME=/opt/module/hbase
$ export HADOOP_HOME=/opt/module/hadoop-2.7.2
$ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`
3.1.2.2 永久生效
先在
/etc/profile配置export HBASE_HOME=/opt/module/hbase export PATH=$PATH:$HBASE_HOME/bin export HADOOP_HOME=/opt/module/hadoop-2.7.2然后在
hadoop-env.sh中增加如下配置(注意:在 for 循环之后配,目的是导入hadoop中增加对hbase的支持的jar包)export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*分发
/etc/profile、hadoop-env.sh3.1.3 重启hbase、hadoop(关闭顺序、启动倒序)
3.2 官方案例
3.2.1 案例一
统计
stu表中有多少行数据
# 注意:在/opt/module/hbase下执行,否则找不到lib/hbase-server-1.3.1.jar
$ /opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter stu
3.2.2 案例二
使用 MapReduce 将本地CSV数据导入到 HBase
- TSV数据如下
**.tsv**文件是以**\t**进行分割的文本文件**.csv**文件是以**,**进行分割的文本文件
1001 Apple Red
1002 Pear Yellow
1003 Pineapple Yellow
创建 Hbase 表(程序不会自动创建表)
create 'fruit','info'在 HDFS 中创建 input_fruit 文件夹并上传 fruit.tsv 文件
$ /opt/module/hadoop-2.7.2/bin/hdfs dfs -mkdir /input_fruit/ $ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put fruit.tsv /input_fruit/执行 MapReduce到HBase的fruit表中
/opt/module/hadoop-2.7.2/bin/yarn jar lib/hbase-server-1.3.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit hdfs://hadoop102:9000/input_fruit使用 scan 命令查看导入后的结果
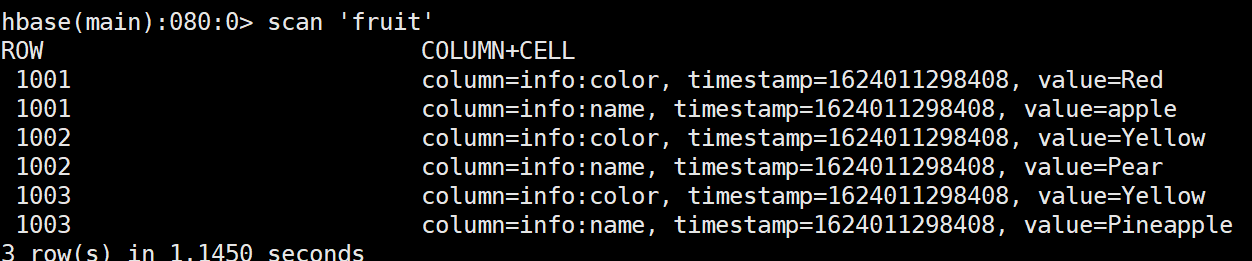
3.3 自定义HBase-MapReduce
3.3.1 案例一(HDFS-MR-HBase)
目标:实现将HDFS中的数据写入到HBase表中 读取HDFS中的tsv文件数据写入HBase使用 MapReduce 将本地CSV数据导入到 HBase
3.3.1.1 CSV数据(数据同官方案例二)
**.tsv**文件是以**\t**进行分割的文本文件
1001 Apple Red
1002 Pear Yellow
1003 Pineapple Yellow
3.3.1.2 创建 Hbase 表(程序不会自动创建表)
create 'fruit1','info'
3.3.1.3 Mapper类
package com.jshawn.hbase.mr1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 需求:HDFS-MR-HBASE案例
* mapper中不做任何操作,在reducer中再做
* @author JShawn 2021/6/18 18:53
*/
public class FruitMapper extends Mapper<LongWritable, Text, LongWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 直接写出
context.write(key,value);
}
}
3.3.1.4 Reducer类
不是继承Reducer,现在要写入HBase,所以继承TableReducer,而TableReducer实际就是Reducer
package com.jshawn.hbase.mr1;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
/**
* 需求:HDFS-MR-HBASE案例
* Reducer类:
* 注意:不是继承Reducer,现在要写入HBase,所以继承TableReducer,而TableReducer实际就是Reducer
* 但Reducer泛型有四个,TableReducer的泛型是三个,其中在源码中第四个参数已经定好了Mutation
* 而Mutation的子类就是Append,Delete,Put,Increment四种HBase的对象
* @author JShawn 2021/6/18 18:55
*/
public class FruitReducer extends TableReducer<LongWritable, Text, NullWritable> {
@Override
protected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 1. 遍历values
for (Text value : values) {
// 2. 获取每一行数据
String[] fields = value.toString().split("\t");
// 3. 构建Put对象,这里不能提成成员变量,因为Put对象无空参构造,有参构造至少需要RowKey
Put put = new Put(Bytes.toBytes(fields[0]));
// 4. 给Put对象赋值
// 数据: 1001 Apple Red
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(fields[1]));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("color"),Bytes.toBytes(fields[2]));
// 5. 写出
context.write(NullWritable.get(),put);
}
}
}
3.3.1.5 Driver类
package com.jshawn.hbase.mr1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 需求:HDFS-MR-HBASE案例
* Driver类
* @author JShawn 2021/6/18 19:06
*/
public class FruitDriver implements Tool {
private Configuration configuration = null;
@Override
public int run(String[] args) throws Exception {
// 1. 获取Job对象
Job job = Job.getInstance(configuration);
// 2. 设置类路径
job.setJarByClass(FruitDriver.class);
// 3. 设置Mapper和Mapper输出的KV类型
job.setMapperClass(FruitMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
// 4. 设置Reducer类,由于这里Reducer是和HBase打交道的Reducer,所以使用工具类TableMapReduceUtil
// 4.1 设置输出路径(就是Hbase的表名,输出到哪张表),reducer类,job
TableMapReduceUtil.initTableReducerJob(args[1], FruitReducer.class, job);
// 5. 设置输入参数(就是HDFS的文件路径)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//7. 提交任务
boolean result = job.waitForCompletion(true);
return result ? 0 : 1;
}
@Override
public void setConf(Configuration configuration) {
this.configuration = configuration;
}
@Override
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) {
try {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new FruitDriver(), args);
System.exit(run);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.3.1.6 测试
打包上传至/opt/module/hbase,执行如下命令
$ /opt/module/hadoop-2.7.2/bin/yarn jar hbase-learning-1.0-SNAPSHOT.jar com.jshawn.hbase.mr1.FruitDriver /input_fruit/fruit.tsv fruit1运行结果
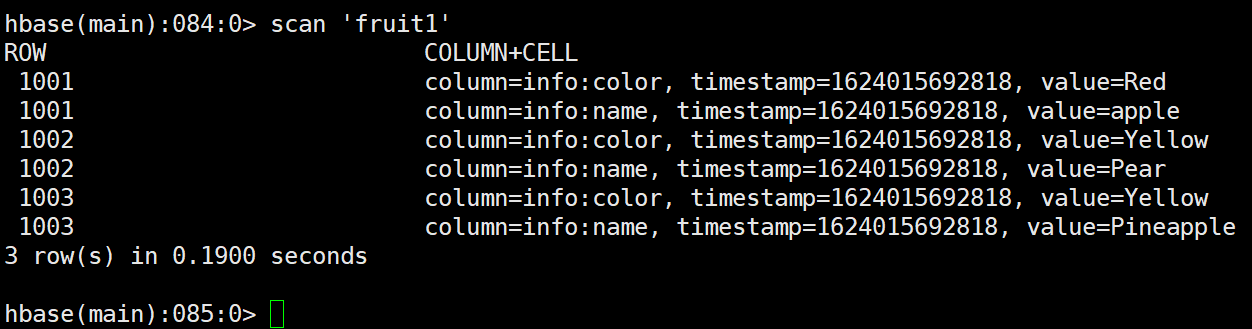
3.3.2 案例二(HBase-HBase)
目标:数据清洗 将 fruit 表中的一部分数据(name列),通过 MR 迁入到 fruit2 表中。
3.3.2.1 源表数据(即案例一结果表)
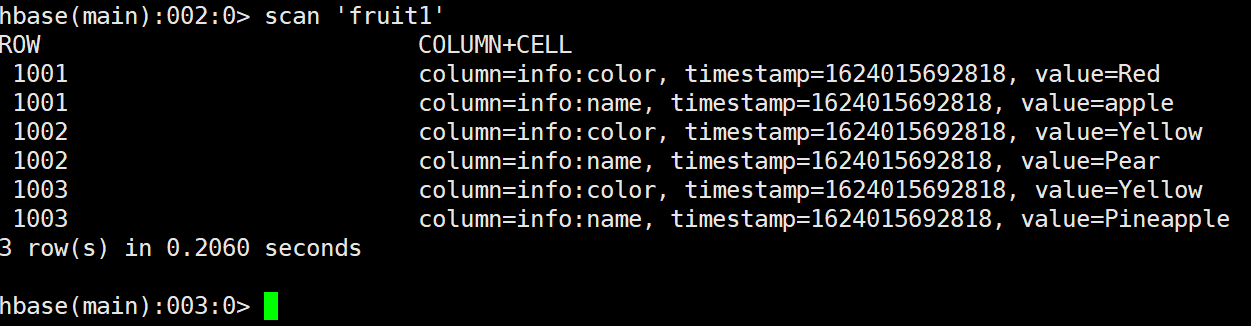
3.3.2.2 创建HBase表
create 'fruit2','info'
3.3.2.3 Mapper类
package com.jshawn.hbase.mr2;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* HBase-HBase
* 需求:HBase一张表的部分数据,提取到HBase另一张表中
* Mapper类:用于读取 源 fruit 表中的数据
* @author JShawn 2021/6/18 20:03
*/
public class Fruit2Mapper extends TableMapper<ImmutableBytesWritable, Put> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
// 1. 将 fruit 的 name 和 color 提取出来,相当于将每一行数据读取出来放入到 Put对象中。
Put put = new Put(key.get());
// 2. 遍历添加column行
for (Cell cell : value.rawCells()) {
// 添加/克隆列族:info
if ("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {
// 添加/克隆列“name”
if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
// 将该列cell加入到put对象中
put.add(cell);
}
}
}
// 3. 写出
context.write(key,put);
}
}
3.3.2.4 Reducer类
package com.jshawn.hbase.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
/**
* HBase-HBase
* Reducer类:用于将读取到的 fruit 表中的数据写入到 fruit2 表中
* @author JShawn 2021/6/18 22:04
*/
public class Fruit2Reducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//读出来的每一行数据写入到 fruit2 表中
for(Put put: values){
context.write(NullWritable.get(), put);
}
}
}
3.3.2.5 Driver类
package com.jshawn.hbase.mr2;
import com.jshawn.hbase.mr1.FruitReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* Driver类:用于组装job信息
*
* @author JShawn 2021/6/18 22:07
*/
public class Fruit2Driver implements Tool {
private Configuration configuration = null;
@Override
public int run(String[] strings) throws Exception {
// 1. 获取configuration
Configuration configuration = this.getConf();
// 2. 创建Job对象
Job job = Job.getInstance(configuration, this.getClass().getSimpleName());
// 3. 配置job
job.setJarByClass(Fruit2Driver.class);
// 4. 可选,配置scan
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setCaching(50);
// 5. 设置Mapper,注意导入的是MapReduce包下的,不是mapred包下的,后者是老版本
TableMapReduceUtil.initTableMapperJob(
"fruit", // 设置输入源的表名
scan, // 设置scan扫描控制器(过滤,缓存等等)
Fruit2Mapper.class, // 设置Mapper类
ImmutableBytesWritable.class, // 设置mapper输出key类型
Put.class, // 设置mapper输出value类型
job // 设置给哪个job
);
// 6. 设置Reducer,
TableMapReduceUtil.initTableReducerJob(
"fruit2",
Fruit2Reducer.class,
job
);
// 7. 可选,设置Reducer数量,最少1个
job.setNumReduceTasks(1);
// 8. 执行
boolean result = job.waitForCompletion(true);
return result ? 0 : 1;
}
@Override
public void setConf(Configuration configuration) {
this.configuration = configuration;
}
@Override
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) {
// 环境运行
// Configuration configuration = new Configuration();
// 本地运行,默认create()方法中会读取本地hbase-site.xml文件获取环境信息用于程序的执行,因此本地必须从环境拉取hbase-site.xml文件
Configuration configuration = HBaseConfiguration.create();
try {
int status = ToolRunner.run(configuration, new Fruit2Driver(), args);
System.exit(status);
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.3.2.7 本地hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<!-- 指定hbase数据在hadoop中存储目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop101:9000/HBase</value>
</property>
<!-- 分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动,之前版本没有.port,默认端口为 60000 -->
<!-- master端口号16000;还可以配置webUI端口号,默认是16010 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- zk地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop101,hadoop102,hadoop103</value>
</property>
<!-- zk的功能目录,zk在磁盘上数据存储的目录 version 2 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/zkData</value>
</property>
<!-- 连接zk的超时时间 -->
<property>
<name>zookeeper.session.timeout</name>
<value>1200000</value>
</property>
<!-- client端与zk发送心跳的时间间隔,线上配置:6000(6s),默认值:6000 -->
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>6000</value>
</property>
</configuration>
3.3.2.8 测试

4. 整合Hive
4.1 HBase 与 Hive 的对比
| 描述 | 用途 | 存储 | 特点 | |
|---|---|---|---|---|
| Hive | 数据仓库 Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以方便使用 HQL 去管理查询。 |
用于数据分析、清洗 Hive 适用于离线的数据分析和清洗,延迟较高。 |
基于 HDFS、MapReduce Hive 存储的数据依旧在 DataNode上,编写的 HQL 语句终将是转换为 MapReduce 代码执行。 |
|
| HBase | 数据库 是一种面向列族存储的非关系型数据库。 |
用于存储结构化和非结构化的数据 适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN 等操作。 |
基于 HDFS 数据持久化存储的体现形式是 HFile,存放于 DataNode 中,被 ResionServer 以 region 的形式进行管理。 |
延迟较低,接入在线业务使用 |
4.2 HBase 与 Hive 集成使用
注意:HBase 与 Hive 的集成在最新的两个版本中无法兼容。所以,只能重新编译:
hive-hbase-handler-1.2.2.jar,如果公司使用的是CDH等,则不用考虑兼容性问题,这里提供已兼容编译好的jar hive-hbase-handler-1.2.1.jar
4.2.1 环境准备
因为会在操作 Hive 的同时对 HBase 也会产生影响,所以 Hive 需要持有操作HBase 的 Jar,那么需要拷贝 Hive 所依赖的 Jar 包(或者使用软连接的形式)。
# 1. 首先保证/etc/profile中的Hive和Hbase环境变量已配
# HBASE
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
# HIVE
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
# 2. 做软链接(或者拷贝jar包)让hive可以操作hbase
ln -s $HBASE_HOME/lib/hbase-common-1.3.1.jar $HIVE_HOME/lib/hbase-common-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar $HIVE_HOME/lib/hbase-server-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-client-1.3.1.jar $HIVE_HOME/lib/hbase-client-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar $HIVE_HOME/lib/hbase-protocol-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-it-1.3.1.jar $HIVE_HOME/lib/hbase-it-1.3.1.jar
ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.3.1.jar
- 同时在
hive-site.xml中增加 zookeeper 的属性<!--集成HBase需要增加zookeeper的信息--> <property> <name>hive.zookeeper.quorum</name> <value>hadoop101,hadoop102,hadoop103</value> <description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> <description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property>4.2.2 案例一
```sql — 1. 在Hive中创建表同时关联HBase,完成之后,可以分别进入 Hive 和 HBase 查看,都生成了对应的表 CREATE TABLE hive_hbase_emp_table( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) STORED BY ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’ WITH SERDEPROPERTIES (“hbase.columns.mapping” = “:key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno”) TBLPROPERTIES (“hbase.table.name” = “hbase_emp_table”);
— 2.在 Hive 中创建临时中间表,用于 load 文件中的数据,不能将数据直接 load 进 Hive 所关联 HBase 的那张表中,因为load实际是put操作,需要走MR才行 CREATE TABLE emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) row format delimited fields terminated by ‘\t’;
— 3. 向 Hive 中间表中 load 数据 hive> load data local inpath ‘/opt/module/hive/data/emp.txt’ into table emp;
— 4. 通过 insert 命令将中间表中的数据导入到 Hive 关联 Hbase 的那张表中 hive> insert into table hive_hbase_emp_table select * from emp;
— 5. 查看 Hive 以及关联的 HBase 表中是否已经成功的同步插入了数据 hive> select * from hive_hbase_emp_table; Hbase> scan ‘hbase_emp_table’
<a name="GTgmp"></a>
### 4.2.3 案例二
> 案例一是同时建表,而现在是在HBase中已经有表了,需要在Hive中创建一张表去关联HBase中那张表
> 在 HBase 中已经存储了某一张表 hbase_emp_table,然后在 Hive 中创建一个外部表来关联 HBase 中的 hbase_emp_table 这张表,使之可以借助 Hive 来分析 HBase 这张表中的数据。
```sql
-- 1. 使用EXTERNAL关键字创建外部表关联
CREATE EXTERNAL TABLE relevance_hbase_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
-- 2. 关联后就可以使用 Hive 函数进行一些分析操作了
hive (default)> select * from relevance_hbase_emp;

若有收获,就点个赞吧
0 人点赞
