一.概述
1.正则表达式是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为”元字符”)
2.正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串
3.例如:/^[0-9]+abc$/
(1)为匹配输入字符串的开始位置
(2)[0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个
(3)abc$匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置
4.正则表达式定义:描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等
5.* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
二.普通字符与元字符
1.普通字符:普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号
| 字符 | 描述 |
|---|---|
| [^A-Z] | 匹配以除了A-Z外的所有内容 |
| [A-Z] | 表示匹配A-Z这个区间 |
| . | 匹配所有换行符,回车以外的所有单个字符 |
| \w | 匹配字母数字下划线 等价于[a-zA-Z0-9_] |
| \W | 匹配除字母数字下划线外的内容 |
| \s | 匹配所有空白字符,包括换行 |
| \S | 匹配所有的非空白字符,不包括 |
| \d | 匹配0-9的数字 |
| \D | 匹配除了数字的所有内容 |
| ^ | 匹配字符串开始的字符 |
| $ | 匹配字符串结尾的字符 |
| \b | 匹配一个字符边界 |
| \B | 匹配一个非字符边界 |
| (pattern) | 匹配 pattern 并获取这一匹配 |
2.非打印字符:
| 字符 | 含义 |
|---|---|
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
| \r | 匹配一个回车 |
| | | 指明两项之间的一个选择 |
3.限定符:出现在范围表达式后限制匹配次数
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {n} | 匹配n次 |
| {n,} | 最少匹配n次 |
| {n,m} | n<=匹配次数<=m |
4.选择:
(1)用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔。
(2)() 表示捕获分组,() 会把每个分组里的匹配的值保存起来, 多个匹配值可以通过数字 n 来查看(n 是一个数字,表示第 n 个捕获组的内容)
5.修饰符:写在正则表达式外,指定额外的匹配策略
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 不区分大小写 | 将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别 |
| g | global - 全局匹配 | 查找所有的匹配项 |
| m | multi line - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾 |
| s | 特殊字符圆点 . 中包含换行符 \n | 默认情况下的圆点 . 是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n |
6.匹配举例:
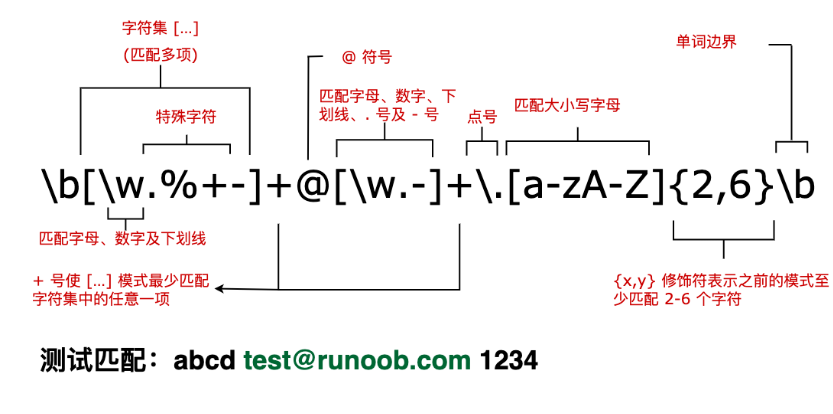
三.优先级
1.正则表达式从左到右进行计算,并遵循优先级顺序
2.相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表说明了各种正则表达式运算符的优先级顺序(降序):
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,”或”操作 字符具有高于替换运算符的优先级,使得”m|food”匹配”m”或”food”。若要匹配”mood”或”food”,请使用括号创建子表达式,从而产生”(m|f)ood”。 |

若有收获,就点个赞吧
0 人点赞
