SparkSQL官方文档:http://spark.incubator.apache.org/docs/latest/sql-programming-guide.html
相关配置
spark.sql.inMemoryColumnar true
如果设置为 true, 则Spark SQL 会根据数据的Storage.compressed统计信息自动为每一列选择压缩编解码器
spark.sql.inMemoryColumnar 10000
控制柱状缓存的批处理大小。较大的批处理可Storage.batchSize以提高内存利用率和压缩能力, 但在缓存数据时有OutOfMemoryErrors (OOMs)风险
spark.sql.files.maxPartition 134217728
单个分区中的最大字节数 Bytes
spark.sql.broadcastTimeout 300
广播连接中广播等待时间的超时秒数 (以秒为单位)
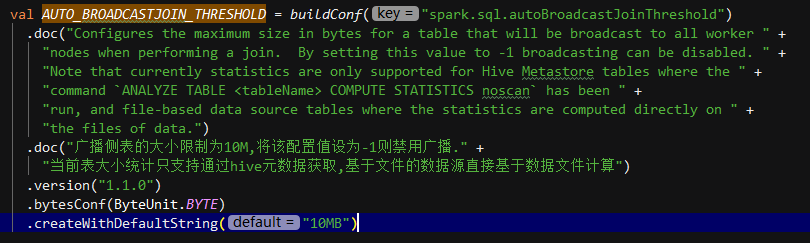
spark.sql.autoBroadcastJoin 10485760
配置在执行连接时将广播给所有工作节点的Threshold (10 MB) 表的最大大小 (以字节为单位)。可以通过将此值设置为-1 来禁用广播
子查询
— Scalar Subquery in WHERE clause.
SELECT * FROM person WHERE age > (SELECT avg(age) FROM person);
+—-+——+—-+
| id|name|age|
+—-+——+—-+
|300|Mike| 80|
+—-+——+—-+
— Correlated Subquery in WHERE clause.
SELECT * FROM person AS parent
WHERE EXISTS (
SELECT 1 FROM person AS child
WHERE parent.id = child.id AND child.age IS NULL );
+—-+——+——+
|id |name|age |
+—-+——+——+
|200|Mary|null|
+—-+——+——+
spark-sql划分job

影响Join效率的几个条件
a.数据集的大小
参与JOIN的数据集的大小会直接影响Join操作的执行效率。同样,也会影响JOIN机制的选择和JOIN的执行效率。
b.JOIN的条件
JOIN的条件会涉及字段之间的逻辑比较。根据JOIN的条件,JOIN可分为两大类:等值连接和非等值连接。等值连接会涉及一个或多个需要同时满足的相等条件。在两个输入数据集的属性之间应用每个等值条件。当使用其他运算符(运算连接符不为=)时,称之为非等值连接。
c.JOIN的类型
在输入数据集的记录之间应用连接条件之后,JOIN类型会影响JOIN操作的结果。主要有以下几种JOIN类型:
- 内连接(Inner Join):仅从输入数据集中输出匹配连接条件的记录。
- 外连接(Outer Join):又分为左外连接、右外连接和全外连接。
- 半连接(Semi Join):left-semi-join时右表只用于过滤左表的数据而不出现在结果集中。
- 反连接(Anti join):left-anti-join时右表只用于过滤左表的数据而不出现在结果集中。
交叉连接(Cross Join):交叉接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
五种jion策略
Shuffle Hash Join
- Broadcast Hash Join
- Sort Merge Join (默认join机制)
- Cartesian Join
- Broadcast Nested Loop Join
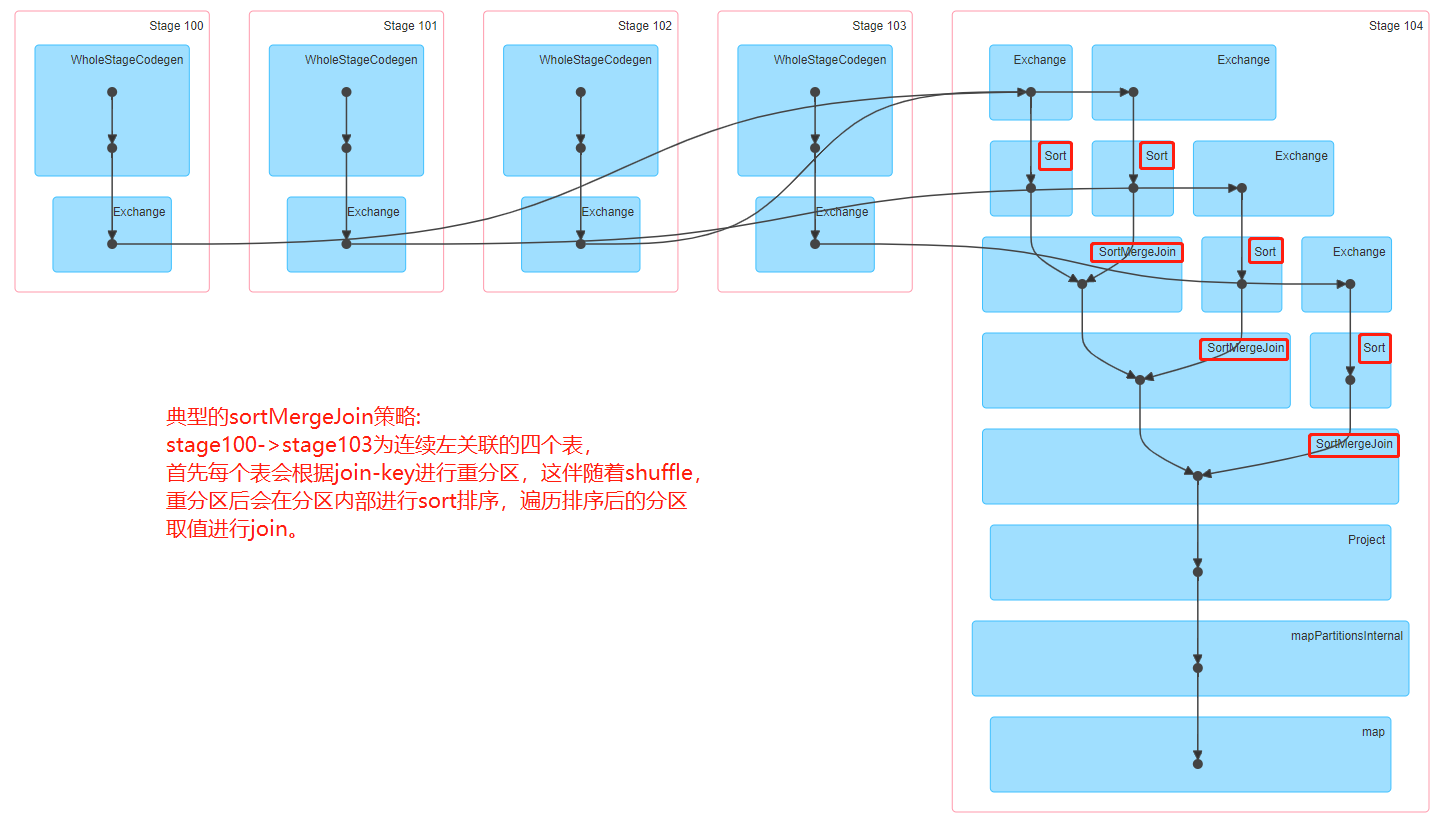
Sort Merge Join:
该JOIN机制是Spark默认的,可以通过参数spark.sql.join.preferSortMergeJoin进行配置,默认是true,即优先使用Sort Merge Join。
一般在两张大表进行JOIN时,使用该方式。Sort Merge Join可以减少集群中的数据传输,该方式不会先加载所有数据的到内存,然后进行
hashjoin,但是在JOIN之前需要对join-key进行排序。
Sort Merge Join主要包括三个阶段:
- Shuffle Phase : 两张大表根据Join key进行Shuffle重分区
- Sort Phase: 每个分区内的数据进行排序
Merge Phase: 对来自不同表的排序好的分区数据进行JOIN,通过遍历元素,连接具有相同Join key值的行来合并数据集
Spark-join策略选取
源码包:spark-sql_2.12
源码:org.apache.spark.sql.execution.SparkStrategy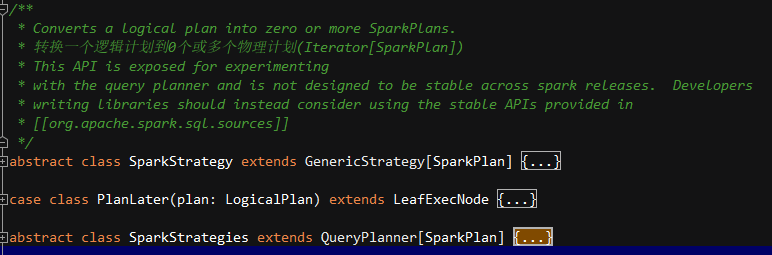
在抽象类SparkStrategies中定义了join、limit、aggregation、window及流式状态管理等多种策略。
Catalyst在由Optimized Logical Plan生成Physical Plan的过程中,会通过JoinSelection中定义的规则按照顺序对逻辑计划进行模式匹配,从而确定join的最终执行策略,策略的选择会按照执行效率由高到低的优先级排列。
/*** Select the proper physical plan for join based on join strategy hints, the availability of* equi-join keys and the sizes of joining relations. Below are the existing join strategies,* their characteristics and their limitations.** - Broadcast hash join (BHJ):* Only supported for equi-joins, while the join keys do not need to be sortable.* Supported for all join types except full outer joins.* BHJ usually performs faster than the other join algorithms when the broadcast side is* small. However, broadcasting tables is a network-intensive operation and it could cause* OOM or perform badly in some cases, especially when the build/broadcast side is big.* 支持:BHJ只支持等值关联,关联key不需要是可排序的,支持除了全连接外的所有join类型。* 优点:当广播侧比较小时,BHJ通常比别的join算法快。* 缺点:广播表是网络密集的操作,在一些情况下可能导致OOM或其他错误,特别是当构建表(广播表)比较大时。* 常见错误:无可用内存构建广播表(Driver端)或者构建广播表超时* 解决方案:* 1. 增大广播超时时间* 2. 增大广播表内存限制* 3. hint显式选择别的Join策略** - Shuffle hash join:* Only supported for equi-joins, while the join keys do not need to be sortable.* Supported for all join types.* Building hash map from table is a memory-intensive operation and it could cause OOM* when the build side is big.* 支持:SHJ只支持等值关联,关联key不需要是可排序的,支持所有join类型。* 缺点:表构建hashMap是内存密集操作,当构建表侧比较大时可能会导致OOM。** - Shuffle sort merge join (SMJ):* Only supported for equi-joins and the join keys have to be sortable.* Supported for all join types.* 支持:SMJ只支持等值关联,关联key必须是可排序的,支持所有join类型,spark的默认join策略。* 缺点:排序是很耗时的。** - Broadcast nested loop join (BNLJ):* Supports both equi-joins and non-equi-joins.* Supports all the join types, but the implementation is optimized for:* 1) broadcasting the left side in a right outer join;* 2) broadcasting the right side in a left outer, left semi, left anti or existence join;* 3) broadcasting either side in an inner-like join.* For other cases, we need to scan the data multiple times, which can be rather slow.* 支持:BNLJ支持等值关联及不等值关联,支持所有join类型但对应不同优化。* 1) 在右外连接时广播左侧;* 2) 在左外、左半、左反及存在join时广播右侧;* 3) 在内连接时两侧都广播* 4) 对于其他情况,需要多次扫描表数据,会比较慢。** - Shuffle-and-replicate nested loop join (a.k.a. cartesian product join):* Supports both equi-joins and non-equi-joins.* Supports only inner like joins.* 支持:SARNLJ支持等值关联及不等值关联,只支持内连接*/
相关配置参数解释: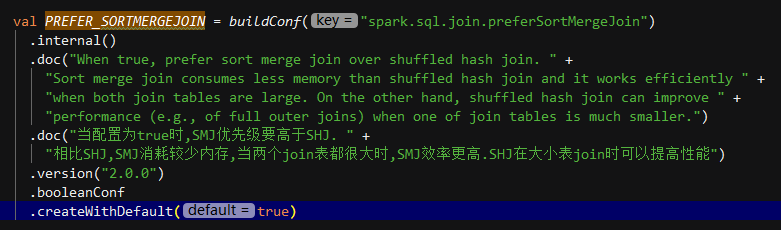
Spark-过滤谓词下推
源码包:spark-sql_2.12
源码:org.apache.spark.sql.sources.Filter
Spark读取文件计算分区
源码包:Spark_sql-2.12
源码位置: org.apache.spark.sql.execution.DataSourceScanExecceScanExecDataSourceScanExecDataSourceScanExecn
在Spark读取Hive分区表,隶属leafNode类型物理算子树中的FileSourceScanExec(继承自DataSourceScanExec)通过调用createReadRDD创建RDD。
首先,会根据一些指标获取最大文件切分大小(FilePartition.maxSplitBytes),此时日志中会有文件大小输出,得到切分大小后会,会根据文件大小划分分区(在文件类型可拆分的前提下,通过调用PartitionedFileUtil.splitFiles)。
/*** Create an RDD for non-bucketed reads.* The bucketed variant of this function is [[createBucketedReadRDD]].** @param readFile a function to read each (part of a) file.* @param selectedPartitions Hive-style partition that are part of the read.* @param fsRelation [[HadoopFsRelation]] associated with the read.*/private def createReadRDD(readFile: (PartitionedFile) => Iterator[InternalRow],selectedPartitions: Array[PartitionDirectory],fsRelation: HadoopFsRelation): RDD[InternalRow] = {val openCostInBytes = fsRelation.sparkSession.sessionState.conf.filesOpenCostInBytesval maxSplitBytes =FilePartition.maxSplitBytes(fsRelation.sparkSession, selectedPartitions)logInfo(s"Planning scan with bin packing, max size: $maxSplitBytes bytes, " +s"open cost is considered as scanning $openCostInBytes bytes.")// Filter files with bucket pruning if possibleval bucketingEnabled = fsRelation.sparkSession.sessionState.conf.bucketingEnabledval shouldProcess: Path => Boolean = optionalBucketSet match {case Some(bucketSet) if bucketingEnabled =>// Do not prune the file if bucket file name is invalidfilePath => BucketingUtils.getBucketId(filePath.getName).forall(bucketSet.get)case _ =>_ => true}val splitFiles = selectedPartitions.flatMap { partition =>partition.files.flatMap { file =>// getPath() is very expensive so we only want to call it once in this block:val filePath = file.getPathif (shouldProcess(filePath)) {val isSplitable = relation.fileFormat.isSplitable(relation.sparkSession, relation.options, filePath)PartitionedFileUtil.splitFiles(sparkSession = relation.sparkSession,file = file,filePath = filePath,isSplitable = isSplitable,maxSplitBytes = maxSplitBytes,partitionValues = partition.values)} else {Seq.empty}}}.sortBy(_.length)(implicitly[Ordering[Long]].reverse)val partitions =FilePartition.getFilePartitions(relation.sparkSession, splitFiles, maxSplitBytes)new FileScanRDD(fsRelation.sparkSession, readFile, partitions)}
def maxSplitBytes(sparkSession: SparkSession,selectedPartitions: Seq[PartitionDirectory]): Long = {val defaultMaxSplitBytes = sparkSession.sessionState.conf.filesMaxPartitionBytes //default:128Mval openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes //default:4Mval minPartitionNum = sparkSession.sessionState.conf.filesMinPartitionNum //filesMinPartitionNum-default:200.getOrElse(sparkSession.leafNodeDefaultParallelism) // leafNodeDefaultParallelism-default:取决于叶子节点分区数or默认分区200val totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sum // 获取文件总大小val bytesPerCore = totalBytes / minPartitionNum //计算平均每个分区大小//min(128M,max(4M,平均每个分区大小))//如果小文件过多,导致分区大小小于4M,则分区都为4M进行划分,即spark读取文件切分时每个分区数据至少4MMath.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
def splitFiles(sparkSession: SparkSession,file: FileStatus,filePath: Path,isSplitable: Boolean,maxSplitBytes: Long,partitionValues: InternalRow): Seq[PartitionedFile] = {if (isSplitable) {//当文件可切分时,根据maxSplitBytes和文件总大小切分(0L until file.getLen by maxSplitBytes).map { offset =>val remaining = file.getLen - offset//获取当前拆分大小val size = if (remaining > maxSplitBytes) maxSplitBytes else remainingval hosts = getBlockHosts(getBlockLocations(file), offset, size)PartitionedFile(partitionValues, filePath.toUri.toString, offset, size, hosts)}} else {//当文件不可切分时,一个文件就是一个分区Seq(getPartitionedFile(file, filePath, partitionValues))}}
以读取data_warehouse.dwd_tj_all_di中的一个分区数据为例,(dt=’2022-03-10’,serviceid=’POST_TEXT’,
organization=’0GuW3nQveKvRo3MwtvhA’),该分区中195个文件,平均文件大小10K。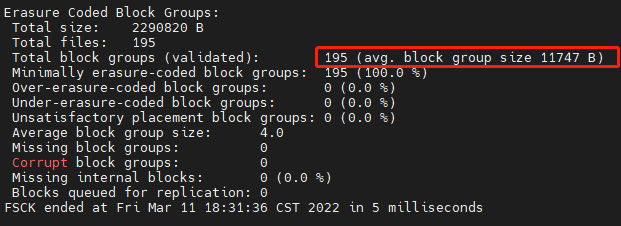
driver端日志输出:createReadRDD方法中的日志打印,计算出最大切分大小为134217728Bytes(128M),打开文件代价是4194304Bytes(4M)。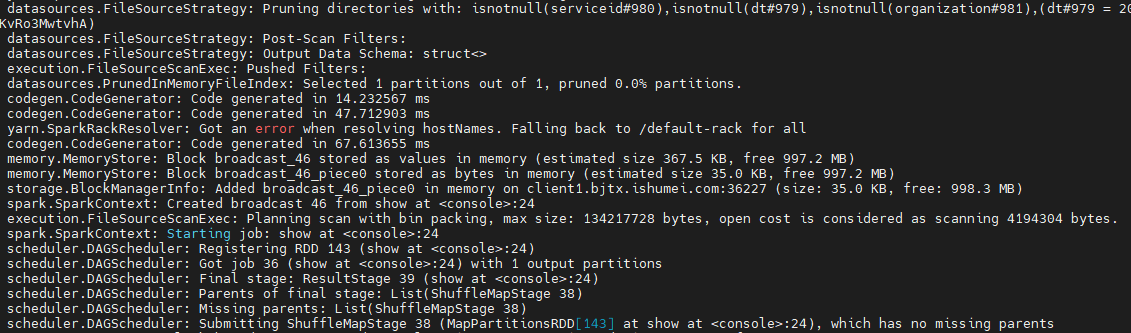
Spark-SQL解析整个执行流程实例
还是以天净事实表一个分区为例,该分区中195个文件,分区总大小2.2M,平均文件大小10K,文件格式为gz压缩的parquet。
执行查询:select risklevel,count(1) num from data_warehouse.dwd_tj_all_di where dt = ‘2022-03-10’ and serviceid=’POST_TEXT’ and organization = ‘0GuW3nQveKvRo3MwtvhA’ group by risklevel
spark-ui: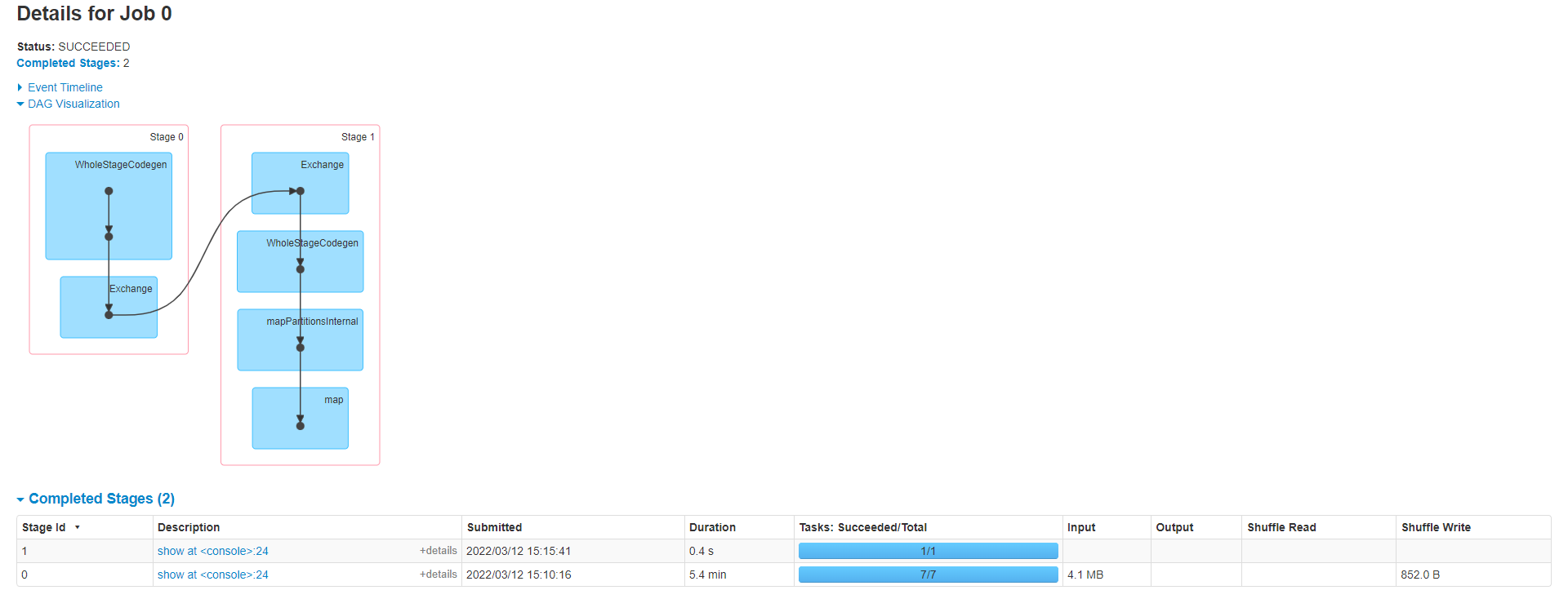
提出问题:
由于groupBy算子的存在,导致shuffle,并划分为两个stage。可以看出数据源输入为7个分区,spark是如何读取hive分区表并且确认分区数的呢?
源码解析:
当用户调用spark.sql(“查询语句”)时,首先会解析用户提交的SQL语句,经过SparkSQLParser的语法解析、SparkSQLLexer的词法解析、AST-Builder,最终构建成一个AST(抽象语法算子树),这个算子树就是未解析的逻辑算子树(UnresolvedLogicalPlan),经过ofRows的封装返回DF给用户。当前整个逻辑计划和物理计划已经构建完毕,但是只有当用户针对DF有action算子的操作时,才会触发后续逻辑计划和物理计划的执行。
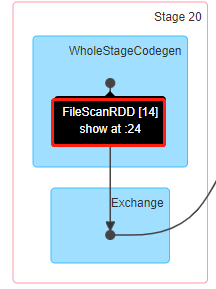
现在,我们切入到DAG进行分析,数据源读入是属于物理计划类型(LeafExecNode)中的一种DataSourceScanExec(特质),不同的类型读取都继承该特质并实现自己的方法,其中该任务提交是由FileSourceScanExec的实现执行读取生成FileScanRDD。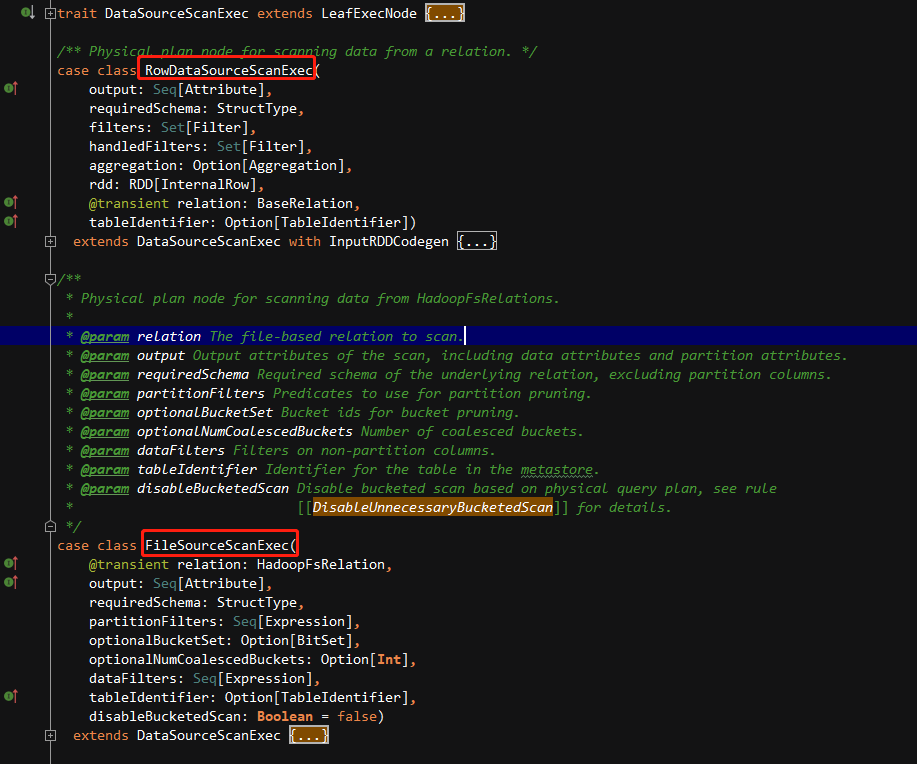
这里,我们匹配到FileSourceScanExec看下如何生成RDD。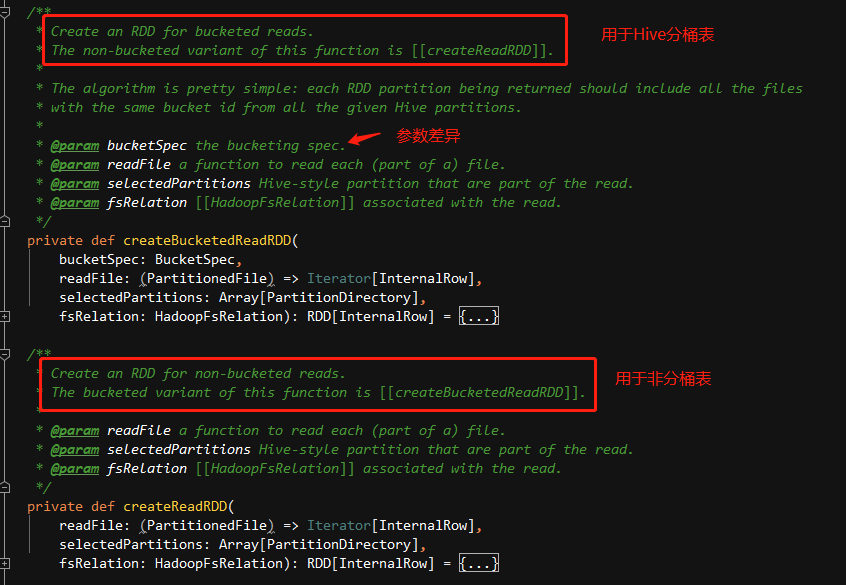
Hive分桶与分区相当于数据的分布与分区,数据分区是物理意义上的数据组合(目录分割),数据分布则一般是针对分区内数据的聚集情况的描述。
当前,我们的数仓设计未涉及到分桶表,我们从createReadRDD切入来看。
首先,createReadRDD方法内会根据一些指标获取最大文件块切分大小(FilePartition.maxSplitBytes),此时日志中会有文件大小输出,得到切分大小后会,会根据文件块大小划分分区(在文件类型可拆分的前提下,通过调用PartitionedFileUtil.splitFiles)。
def maxSplitBytes(sparkSession: SparkSession,selectedPartitions: Seq[PartitionDirectory]): Long = {val defaultMaxSplitBytes = sparkSession.sessionState.conf.filesMaxPartitionBytes //default:128Mval openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes //default:4Mval minPartitionNum = sparkSession.sessionState.conf.filesMinPartitionNum //filesMinPartitionNum-default:2(取决于当前SPARK进程总核数).getOrElse(sparkSession.leafNodeDefaultParallelism) // leafNodeDefaultParallelism-default:取决于叶子节点分区数or默认分区2val totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sum // 获取文件总大小(当前文件长度+打开文件代价估值)val bytesPerCore = totalBytes / minPartitionNum //计算平均每个分区大小//min(128M,max(4M,平均每个分区大小))//如果小文件过多,导致分区大小小于4M,则分区都为4M进行划分,即spark读取文件切分时每个分区数据至少4MMath.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
maxSplitBytes的实现方式跟几个重要的参数有关: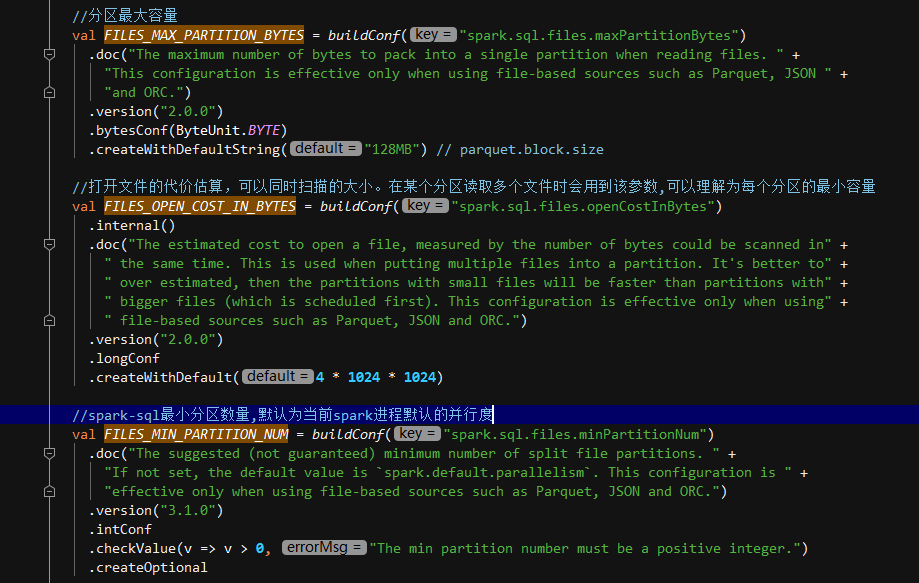

当并行度为2时,计算maxSplitBytes:
Math.min(128M, Math.max(4M, (文件总长度+文件个数*4M)/并行度))
Math.min(128M, Math.max(4M, 782M/2))
最终结果为128M

当并行度为100(executor-cores为100)时,计算maxSplitBytes:
Math.min(128M, Math.max(4M, (文件总长度+文件个数*4M)/并行度))
Math.min(128M, Math.max(4M, 782M/100))
最终结果为7.82M
下面看文件如何根据maxSplitBytes进行切分(当前文件类型可拆分前提下):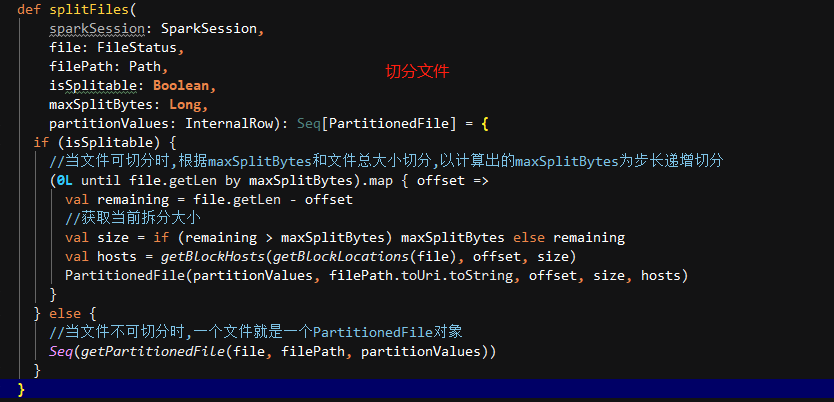
我们之前得到maxSplitBytes为128M,由于我们分区中为195个小文件块,都远小于128M,所以我们会得到一个包含195个partitionedFile对象的集合,然后会根据FilePartition.getFilePartitions()方法进行分区,并根据分区数据构建最终的FileScanRDD。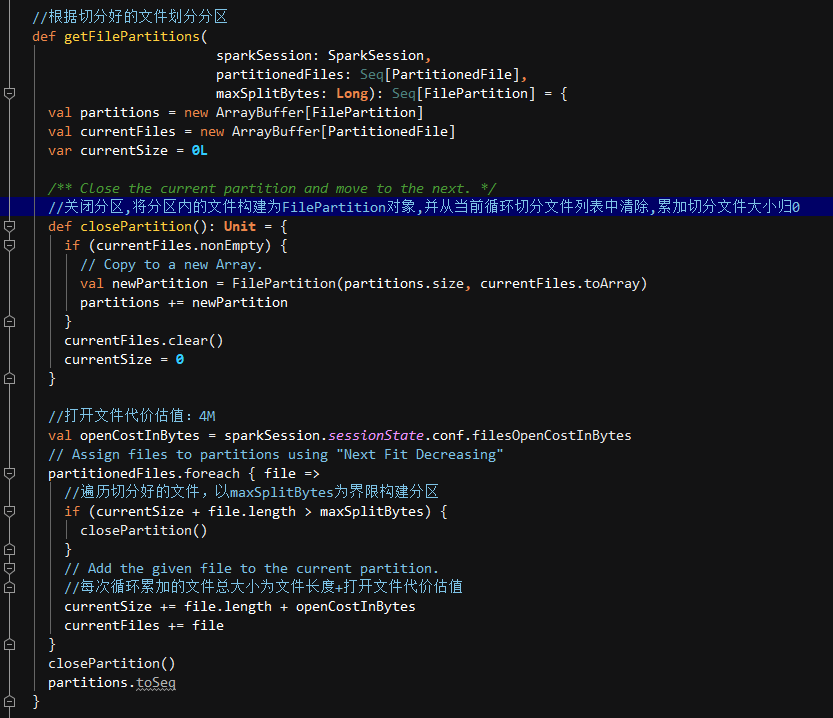
getFilePartitions会根据之前切分好的文件块集合进行分区,以maxSplitBytes为界限,循环累加文件块大小进行分区。因为之前我们切分后为195个partitionedFile对象的集合,虽然我们的数据本身很小,但是每个文件都需要累加上打开文件所需的预估内存代价,所以分区应该为:
每次累加当前文件大小(平均文件大小为10K)+打开文件估值(4M)≈ 4M
由于每个分区为128M的限制,所以需要构建六个完整分区(一个完整分区为32次循环,128/4=32)及一个残留分区(195个文件-32个文件*6个完整分区=3个残留文件),即总共构建了7个分区。
验证分区数量:
由于groupby导致shuffle,会使得spark使用默认并行度200,因为我们去掉groupby进行源数据的验证。

最后一个分区下刚好有三个文件。
以上是基于默认并行度为2时的分析,那么我们设置为100会是多少分区呢?
之前我们算出了,并行度为100下的maxSplitSize约为7.82M,也就是分区限制为7.82M,我们底层文件切分后依然是195个小文件,因为文件本身太小,我们还按照每个文件4M来计算,那么两个文件就会构建一个分区,195/2=97个完整分区及一个残留分区,残留分区只有一个文件。总分区数应该为98.
验证分区数量:
最后一个分区下刚好是一个文件:
总结:
数据文件切分文件块之后,将一个或多个文件块划分到一个分区中。过程从初始化一个空分区开始,然后对每个文件块进行迭代计算。
注意:
数据块总大小为块实际大小与 openCostInBytes额外开销的总和。
当hive数据为Parquet时,读取时匹配对应DataSource策略返回FileScanRDD,当Hive数据为text时,匹配Hive的DataSource策略,对应TableReader读取方式,返回的是HadoopRDD(其分区数对应其hdfs文件的block数)。
Spark读取分区数据时的体现
在spark读取hive分区或者Hdfs文件涉及分区时,当遇到执行算子时,会看到数据源读取有时涉及到分区扫描的stage。
Spark的一次查询过程可以简单抽象为 planning 阶段和 execution 阶段,在new一个新的Spark Session 中第一次查询某数据的过程称为冷启动,在这种情况下 planning 的耗时可能会比 execution 更长。Spark 读取数据冷启动时,会从文件系统中获取文件的一些元数据信息(location,size.)用于优化,如果一个目录下的文件过多,就会比较耗时,该逻辑在 InMemoryFileIndex 中实现。后续再次多次查询则会在 FileStatusCache 中进行查询,planning 阶段性能会大幅提升。
当前Spark的InMemoryFileIndex实现:
- 将表分区元数据信息缓存到 catalog 中,例如 (hive metastore),因此可以在 PruneFileSourcePartitions 规则中提前进行分区发现,catalyse optimeizer 会在逻辑计划中对分区进行修剪,避免读取到不需要的分区文件信息。
- 文件统计可以在计划期间内增量的,部分的缓存,而不是全部预先加载。Spark需要知道文件的大小以便在执行物理计划时将它们划分为读取任务。通过共享一个固定大小的250MB缓存(可配置),而不是将所有表文件统计信息缓存到内存中,在减少内存错误风险的情况下显著加快重复查询的速度。
文件元数据读取方式及元数据缓存管理:
- 读取数据时会先判断分区的数量,如果分区数量小于等于spark.sql.sources.parallelPartitionDiscovery.threshold (默认32),则使用 driver 循环读取文件元数据,如果分区数量大于该值,则会启动一个 spark job,分布式的处理元数据信息(每个分区下的文件使用一个task进行处理)
- 分区数量很多意味着 Listing leaf files task 的任务会很多,分区里的文件数量多意味着每个 task 的负载高,使用 FileStatusCache 缓存文件状态,默认的缓存 spark.sql.hive.filesourcePartitionFileCacheSize 为 250MB。
当执行spark.sql(“select * from data_warehouse.mid_crm_user_field_detail_di where dt >= ‘2022-01-27’ and dt <= ‘2022-03-10’”).show(false) 时,此时需要扫描32个分区,没有超过阈值,则直接在driver端执行分区发现,因此DAG中只有一个show触发的job。
当执行spark.sql(“select * from datawarehouse.mid_crm_user_field_detail_di where dt >= ‘2022-01-26’ and dt <= ‘2022-03-10’”).show(false) 时,此时需要扫描33个分区,超过了32的阈值,则需要额外启动一个名为_listLeafFiles的分布式job执行分区发现,因此DAG中有一个名为Listing leaf files and directories的job和一个show的job。
分区发现相关参数配置: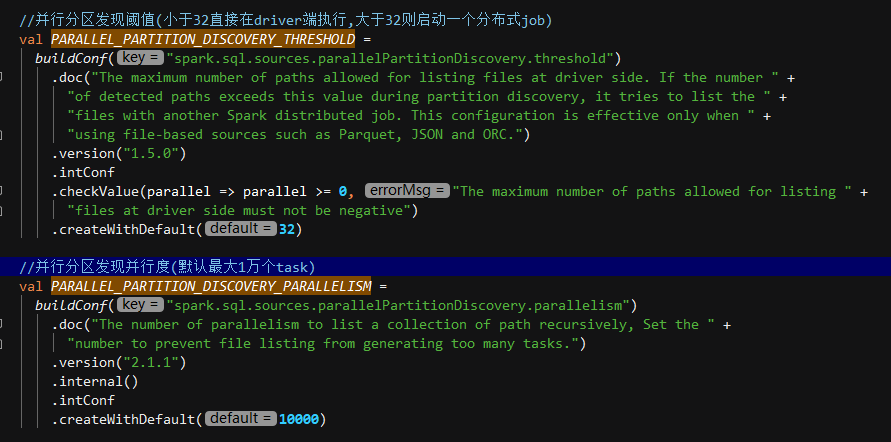
相关源码: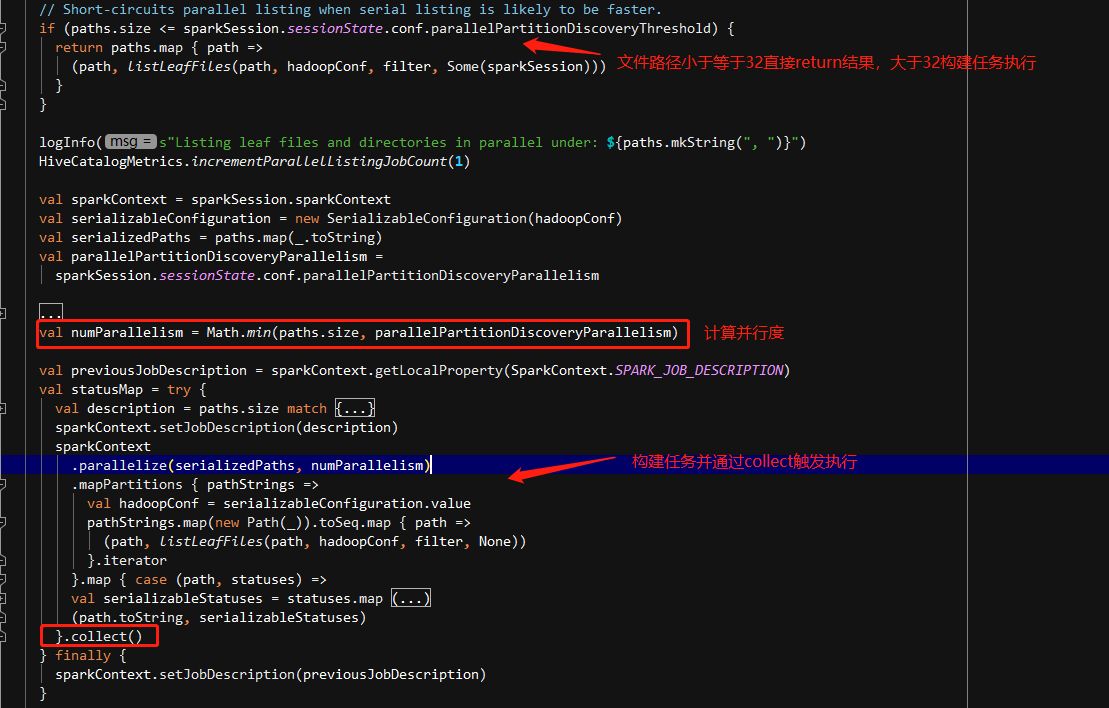
Listing leaf files task 的数量计算公式为:
val numParallelism = Math.min(paths.size, parallelPartitionDiscoveryParallelism)
其中,paths.size 为需要读取的分区数量,parallelPartitionDiscoveryParallelism 由参数 spark.sql.sources.parallelPartitionDiscovery.parallelism 控制,默认为10000,目的是防止 task 过多,但从生产任务上观察发现大多数 get status task 完成的时间都是毫秒级,可以考虑把这个值调低,减少任务启动关闭的开销,或者直接修改源码将 paths.size 按一定比例调低,例如 paths.size/2
SparkSQL常用操作
官网文档:https://spark.apache.org/docs/3.1.2/sql-ref-syntax-qry-select.html
注: 该文档基于Spark3.1.2
- 查看执行计划
一般查看SQL执行计划使用explain语句即可,但是explain默认输出优化后(其实就是next选取)最后阶段的物理计划。
在SQL中:
spark.sql(“explain select …”).show(false)
在DF中:
spark.sql(“select …”).explain
如果想查看全阶段执行计划(从解析的逻辑计划到优化后的物理计划),则需要选择不用的explain模式,explain支持四种模式:
EXPLAIN [ EXTENDED | CODEGEN | COST | FORMATTED ] statement
EXTENDED:
生成解析的逻辑计划、分析的逻辑计划、优化的逻辑计划和物理计划。已解析逻辑计划是从查询中提取的未解析计划。分析的逻辑计划转换将 unresolvedAttribute 和 unresolvedRelation 转换为完全类型化的对象。优化后的逻辑计划通过一组优化规则进行变换,形成物理计划。
CODEGEN(钨丝计划的一项重要优化,优化了火山模型带来的虚函数的调用代价):
为语句生成的代码和物理计划。
COST:
如果计划节点统计信息可用,则生成逻辑计划和统计信息。
FORMATTED:
生成两个部分:物理计划大纲和节点详细信息。
Spark2.4看不了FORMATTED哇
Spark-Shuffle过程详解

若有收获,就点个赞吧
0 人点赞
